Автор: Денис Аветисян
Новое исследование показывает, что способность языковых моделей к семантической абстракции тесно связана с тем, как они отражают активность человеческого мозга.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"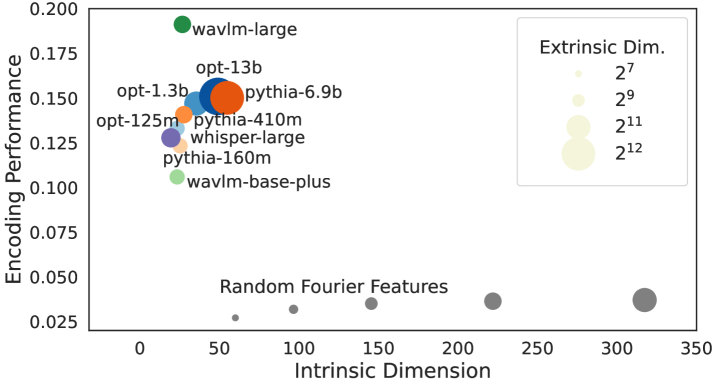
Внутренняя размерность промежуточных слоев языковых и речевых моделей коррелирует с их способностью предсказывать нейронные реакции мозга на семантическую информацию.
Неочевидно, почему промежуточные представления в языковых и речевых моделях столь эффективно предсказывают активность мозга при восприятии речи и текста. В работе, озаглавленной ‘Abstraction Induces the Brain Alignment of Language and Speech Models’, исследователи показали, что соответствие между моделями и мозгом обусловлено не предсказанием следующего слова, а абстракцией семантического содержания. В частности, установлено, что способность моделей к формированию высокоуровневых лингвистических признаков, измеряемая внутренней размерностью слоев, тесно связана с их способностью предсказывать сигналы фМРТ и ЭКоГ. Может ли семантическая насыщенность, отражающаяся в высокой внутренней размерности, служить универсальным принципом для сопоставления моделей искусственного интеллекта и нейронных сетей мозга?
Преодолевая Разрыв: От Искусственного Интеллекта к Вдохновленным Мозгом Вычислениям
Современные модели искусственного интеллекта, демонстрирующие впечатляющие возможности в решении узкоспециализированных задач, зачастую уступают человеческому мозгу в эффективности и адаптивности. В отличие от мозга, способного к обучению на небольшом объеме данных и быстрому переключению между различными типами задач, современные алгоритмы требуют огромных массивов информации и значительных вычислительных ресурсов. Эта разница обусловлена принципиальными отличиями в архитектуре и принципах работы: мозг функционирует как сложная, энергоэффективная сеть взаимосвязанных нейронов, в то время как большинство современных ИИ-систем основаны на последовательной обработке данных, что ограничивает их способность к параллельным вычислениям и обобщению знаний. В результате, даже самые мощные алгоритмы могут столкнуться с трудностями при решении задач, требующих интуиции, креативности или адаптации к новым, непредсказуемым условиям.
Понимание принципов обработки информации в мозге является ключевым фактором для создания более надежных и универсальных систем искусственного интеллекта. Современные алгоритмы машинного обучения, несмотря на впечатляющие успехи в решении узкоспециализированных задач, часто демонстрируют хрупкость и неспособность к обобщению знаний в новых, незнакомых ситуациях. В отличие от них, человеческий мозг обладает удивительной способностью адаптироваться, обучаться на небольшом объеме данных и эффективно функционировать в условиях неопределенности. Изучение нейронных сетей, синаптической пластичности и механизмов кодирования информации в мозге позволяет ученым разрабатывать принципиально новые подходы к созданию искусственного интеллекта, имитирующие биологические системы и обладающие повышенной устойчивостью к шумам и помехам. В конечном итоге, глубокое понимание работы мозга не только расширит границы возможностей искусственного интеллекта, но и позволит создать системы, способные к творческому мышлению и решению сложных проблем, приближая нас к созданию действительно разумных машин.
Декодирование Нейронных Сигналов с Помощью Вычислительных Моделей
Для установления связи между искусственным интеллектом и нейронаукой используются вычислительные модели, в частности, языковые и речевые модели, для симуляции активности мозга. Эти модели позволяют создавать абстрактные представления информации, аналогичные тем, которые предположительно используются в нейронных сетях. Используя данные, полученные из больших языковых корпусов и речевых данных, модели способны воспроизводить паттерны активности, наблюдаемые в различных областях мозга при обработке аналогичной информации. Такой подход позволяет исследовать, как информация кодируется и представляется в мозге, а также проверять гипотезы о нейронных механизмах, лежащих в основе когнитивных процессов.
Для сопоставления высокоразмерных представлений, генерируемых вычислительными моделями (такими как языковые и речевые модели), с активностью мозга используется линейное преобразование. Данный метод позволяет установить соответствие между векторами признаков, полученными из модели, и сигналами, зарегистрированными с помощью функциональной магнитно-резонансной томографии (фМРТ) и электрокортикографии (ЭКоГ). Линейное преобразование, по сути, представляет собой матричное умножение, которое проецирует векторы из пространства признаков модели в пространство данных нейровизуализации, обеспечивая возможность количественной оценки степени соответствия между моделью и наблюдаемой активностью мозга. Выбор линейного преобразования обусловлен его вычислительной эффективностью и способностью выявлять наиболее значимые связи между признаками модели и нейронными сигналами.
Для оценки соответствия между представлениями, сформированными вычислительными моделями, и наблюдаемой активностью мозга, используется метрика, обозначаемая как «Производительность Кодирования» (Encoding Performance). Измерения, полученные с помощью функциональной магнитно-резонансной томографии (фМРТ) и электрокортикографии (ЭКоГ), демонстрируют корреляцию до 0.73 для фМРТ и 0.63 для ЭКоГ между размерностью внутренних представлений (Intrinsic Dimension, IdI_d) слоев моделей и точностью предсказания активности в хорошо предсказуемых вокселях/электродах. Это указывает на то, что сложность внутренних представлений модели связана с тем, насколько точно она может моделировать нейронную активность.
Раскрывая Смысл через Предсказательные Механизмы
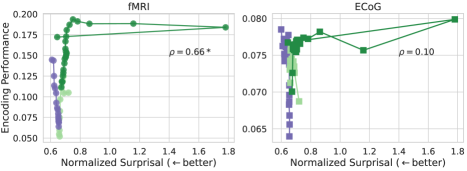
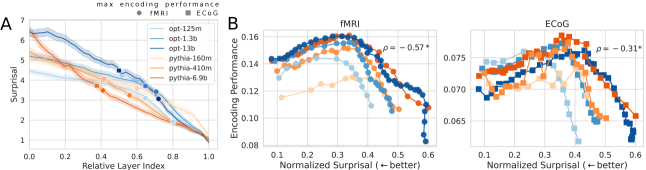
В основе нашего подхода лежит концепция предсказания следующего токена в языковых моделях и сопутствующий принцип удивительности (Surprisal). Удивительность, измеряемая как отрицательный логарифм вероятности предсказанного токена, служит показателем информативности данного токена относительно контекста. Используя эту метрику, мы оцениваем, как модели обрабатывают информацию, определяя, какие элементы в последовательности вызывают наибольшее удивление и, следовательно, несут наибольшую смысловую нагрузку. Чем выше значение Surprisal, тем менее предсказуем токен в данном контексте, и тем больше внимания он может потребовать для обработки.
Принципы предсказательного кодирования в мозге предполагают, что обучение происходит посредством минимизации ошибок предсказания. Мозг постоянно генерирует модели окружающего мира и сравнивает их с поступающими сенсорными данными. Разница между предсказанием и реальностью формирует “ошибку предсказания”, которая используется для обновления внутренней модели и повышения точности будущих предсказаний. Этот процесс иерархичен: более высокие уровни мозга генерируют абстрактные предсказания, которые передаются вниз по иерархии, а нижние уровни передают информацию об ошибках предсказания вверх, формируя петлю обратной связи. Минимизация этих ошибок является ключевым механизмом обучения и адаптации.
Для исследования предсказательных связей были использованы модели Pythia, OPT, WavLM и Whisper, анализ которых был расширен применением Random Fourier Features. Полученные результаты демонстрируют положительную корреляцию между производительностью кодирования и величиной удивления (Surprisal). Это указывает на то, что представления, хорошо предсказывающие следующий токен, не обязательно более тесно связаны с активностью мозга, что позволяет предположить наличие иных факторов, влияющих на нейронные процессы, связанные с обработкой информации.
Роль Размерности в Нейронном Представлении
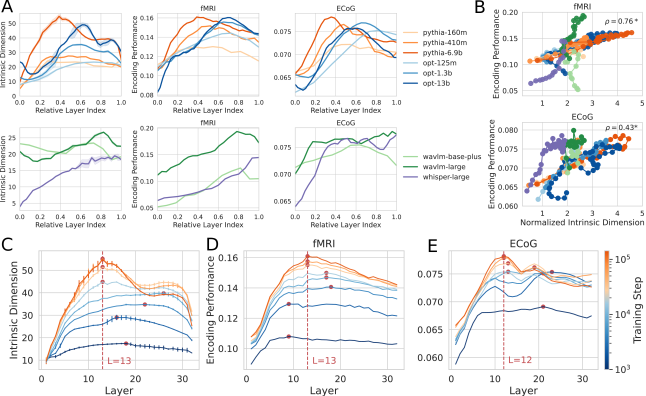
Исследования показали, что внутренняя размерность представлений, формируемых нейронными сетями, тесно связана с качеством кодирования информации. Более высокая внутренняя размерность позволяет модели захватывать более сложные и нюансированные характеристики входных данных, что напрямую влияет на её способность эффективно кодировать и воспроизводить информацию. Установлена корреляция между внутренней размерностью слоев нейронной сети и её производительностью при кодировании — например, в исследованиях с использованием фМРТ и ЭКоГ были получены значения корреляции 0.76 и 0.43 соответственно. Это указывает на то, что способность сети представлять информацию в многомерном пространстве является ключевым фактором, определяющим качество её работы и потенциал к обобщению полученных знаний.
Исследования показывают, что более высокая внутренняя размерность нейронных представлений способна захватывать и кодировать более сложную информацию из входных данных. Этот процесс, по всей видимости, является ключевым фактором, определяющим способность модели к обобщению — то есть, к успешной работе с данными, которые не встречались ей в процессе обучения. Более высокая размерность позволяет сети формировать более детализированные и нюансированные представления, что, в свою очередь, повышает ее устойчивость к шуму и вариациям во входных данных. Таким образом, внутренняя размерность можно рассматривать как меру информационного богатства нейронного представления и, потенциально, индикатор способности системы к адаптации и эффективному решению сложных задач.
Исследование выявило значимую связь между способностью к абстракции смысла и эффективностью представления информации как в искусственных, так и в биологических системах. В частности, анализ данных функциональной магнитно-резонансной томографии (fMRI) показал корреляцию в 0.76 между внутривнутренней размерностью (IdI_d) слоев нейронных сетей и их способностью кодировать информацию. Аналогичная, хотя и менее выраженная, связь (0.43) была обнаружена при анализе данных электрокортикографии (ECoG). Эти результаты указывают на то, что более высокая внутривнутренняя размерность нейронных представлений может отражать способность захватывать и кодировать более сложные и абстрактные аспекты информации, что, в свою очередь, способствует улучшению обобщающей способности и эффективности обработки данных в различных системах.
Исследование демонстрирует, что способность языковых моделей к семантической абстракции играет ключевую роль в их соответствии нейронной активности мозга. Если система держится на костылях, значит, мы переусложнили её. Брайан Керниган однажды заметил: «Простота — это высшая степень утонченности». Это высказывание находит глубокий отклик в данной работе, поскольку она показывает, что именно абстрактное представление, а не просто предсказание следующего токена, обеспечивает согласованность между моделями и мозгом. Модульность без понимания контекста — иллюзия контроля, и данное исследование подчеркивает важность создания моделей, которые действительно понимают смысл, а не просто манипулируют символами.
Куда ведут абстракции?
Представленные данные намекают на то, что согласование между моделями и мозгом возникает не как побочный эффект предсказания следующего токена, а как следствие способности к семантической абстракции. Однако, возникает вопрос: является ли эта абстракция действительно аналогична той, что формируется в нейронных сетях мозга, или это лишь поверхностное сходство, замаскированное метриками репрезентативного сходства? Поиск ответа требует более глубокого анализа внутренней структуры этих абстракций — не просто «что» представлено, но и «как» это представление организовано.
Особое внимание следует уделить исследованию влияния архитектурных решений на формирование этих абстракций. Каждая новая зависимость в модели — это скрытая цена свободы, ограничивающая пространство возможных представлений. Необходимо понимать, какие архитектурные принципы способствуют формированию более «естественных» или «биоморфных» абстракций, способных к более эффективному взаимодействию с человеческим мозгом. Иначе, мы рискуем создать системы, которые хорошо имитируют поведение, но лишены подлинного понимания.
В конечном итоге, истинный прогресс в области neuroAI потребует не просто сопоставления моделей и мозга, но и глубокого понимания принципов, определяющих структуру и поведение как искусственных, так и естественных систем. Ведь элегантный дизайн рождается из простоты и ясности, а хорошая система — это живой организм, где нельзя чинить одну часть, не понимая целого.
Оригинал статьи: https://arxiv.org/pdf/2602.04081.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Макросъемка
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- Обзор вспышки Yongnuo YN500EX
2026-02-06 05:51