Автор: Денис Аветисян
Исследователи разработали инновационную систему, использующую принципы функциональной модульности мозга для более точного распознавания невысказанной речи на основе данных электроэнцефалограммы.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"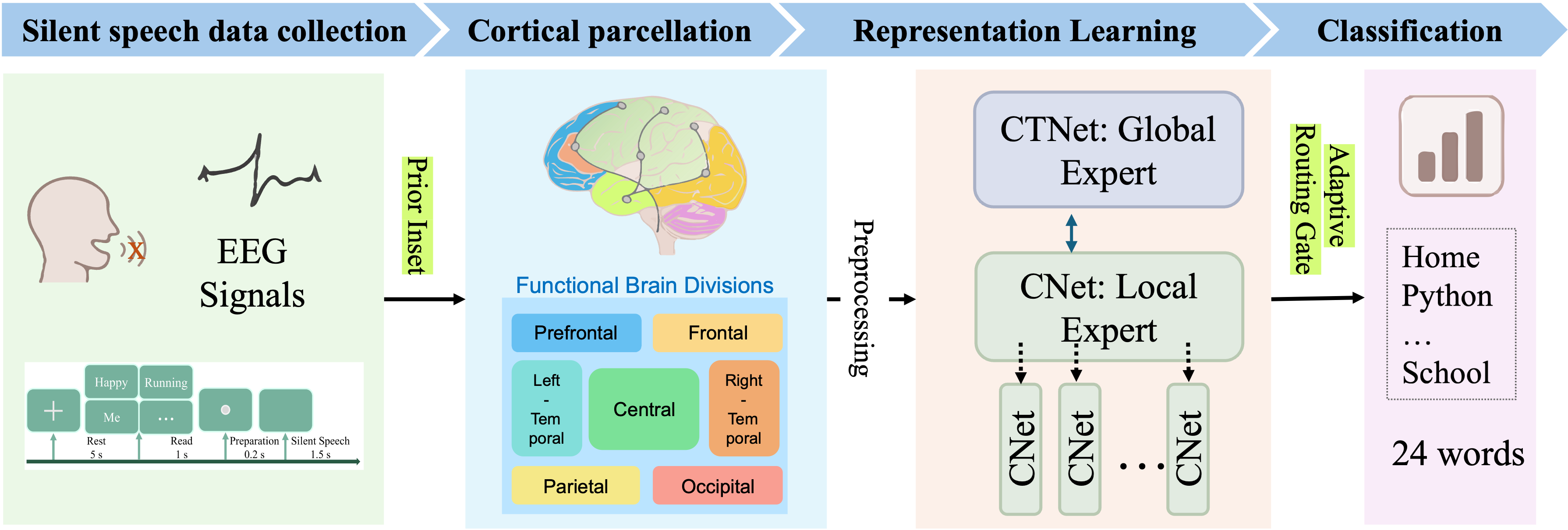
Представленная архитектура BrainStack, основанная на Mixture-of-Experts, позволяет значительно улучшить точность декодирования речи по ЭЭГ, моделируя специализированные области мозга.
Декодирование лингвистической информации из электроэнцефалограммы (ЭЭГ) остается сложной задачей из-за распределенной и нелинейной организации мозга. В данной работе представлена модель ‘BrainStack: Neuro-MoE with Functionally Guided Expert Routing for EEG-Based Language Decoding’, использующая архитектуру Mixture-of-Experts (MoE) с функционально-ориентированной маршрутизацией для моделирования модульной функциональной архитектуры мозга. Предложенный подход демонстрирует превосходство над современными моделями в задачах декодирования безмолвной речи, благодаря адаптивному объединению экспертов и использованию принципов нейроанатомии. Какие перспективы открывает унификация нейробиологических принципов и адаптивной маршрутизации экспертов для создания масштабируемых и интерпретируемых систем декодирования мозговой активности?
Расшифровка безмолвия: вызовы нейролингвистики
Прямое декодирование речи из мозговой активности, известное как «молчаливая речь», представляет собой сложную задачу, обусловленную фундаментальной сложностью и изменчивостью нейронных сигналов. Нейронные сети, отражающие речевые процессы, не являются статичными, а постоянно меняются в зависимости от индивидуальных особенностей мозга, когнитивного состояния и даже мельчайших нюансов произносимых или воображаемых слов. Эта внутренняя изменчивость, в сочетании с шумом, присущим электроэнцефалографии (ЭЭГ), делает точное извлечение лингвистической информации из мозговых волн исключительно трудной задачей. Различия в анатомии мозга, скорости обработки информации и личных языковых привычках создают уникальные «подписи» для каждого человека, что требует разработки адаптивных алгоритмов, способных учитывать эту индивидуальную вариабельность и эффективно отфильтровывать посторонние помехи, прежде чем можно будет надежно восстановить задуманные слова или фразы.
Традиционные методы анализа электроэнцефалограммы (ЭЭГ) сталкиваются с существенными трудностями при расшифровке речи, поскольку нейронные сигналы, отражающие даже самые простые речевые акты, характеризуются высокой сложностью и изменчивостью во времени. Существующие алгоритмы зачастую не способны уловить тонкие временные закономерности, присущие речевому сигналу, что приводит к снижению точности декодирования. Несмотря на значительные достижения в области обработки сигналов, захват быстро меняющихся паттернов нейронной активности, формирующих речь, остается сложной задачей, требующей разработки более совершенных подходов к анализу временных рядов и извлечению релевантной информации из шума, свойственного ЭЭГ-данным. Неспособность адекватно учитывать динамику речевых сигналов ограничивает возможности создания систем, способных точно и надежно преобразовывать нейронную активность в понятные речевые конструкции.
Для эффективной обработки высокоразмерных и зашумленных данных электроэнцефалограммы (ЭЭГ) при декодировании речи из мозговой активности требуется разработка инновационных архитектур глубокого обучения. Существующие модели часто сталкиваются с трудностями при извлечении значимой информации из сложного нейронного сигнала, поскольку традиционные подходы не всегда способны уловить тонкие временные закономерности, характерные для речи. Поэтому исследователи активно изучают новые методы, включая использование сверточных нейронных сетей (CNN) для извлечения пространственных признаков и рекуррентных нейронных сетей (RNN) для моделирования временной динамики. Особое внимание уделяется разработке архитектур, способных эффективно снижать размерность данных и выделять наиболее релевантные признаки, что позволяет значительно повысить точность декодирования и приблизить возможность создания интерфейсов «мозг-компьютер», способных преобразовывать мысли в слова.
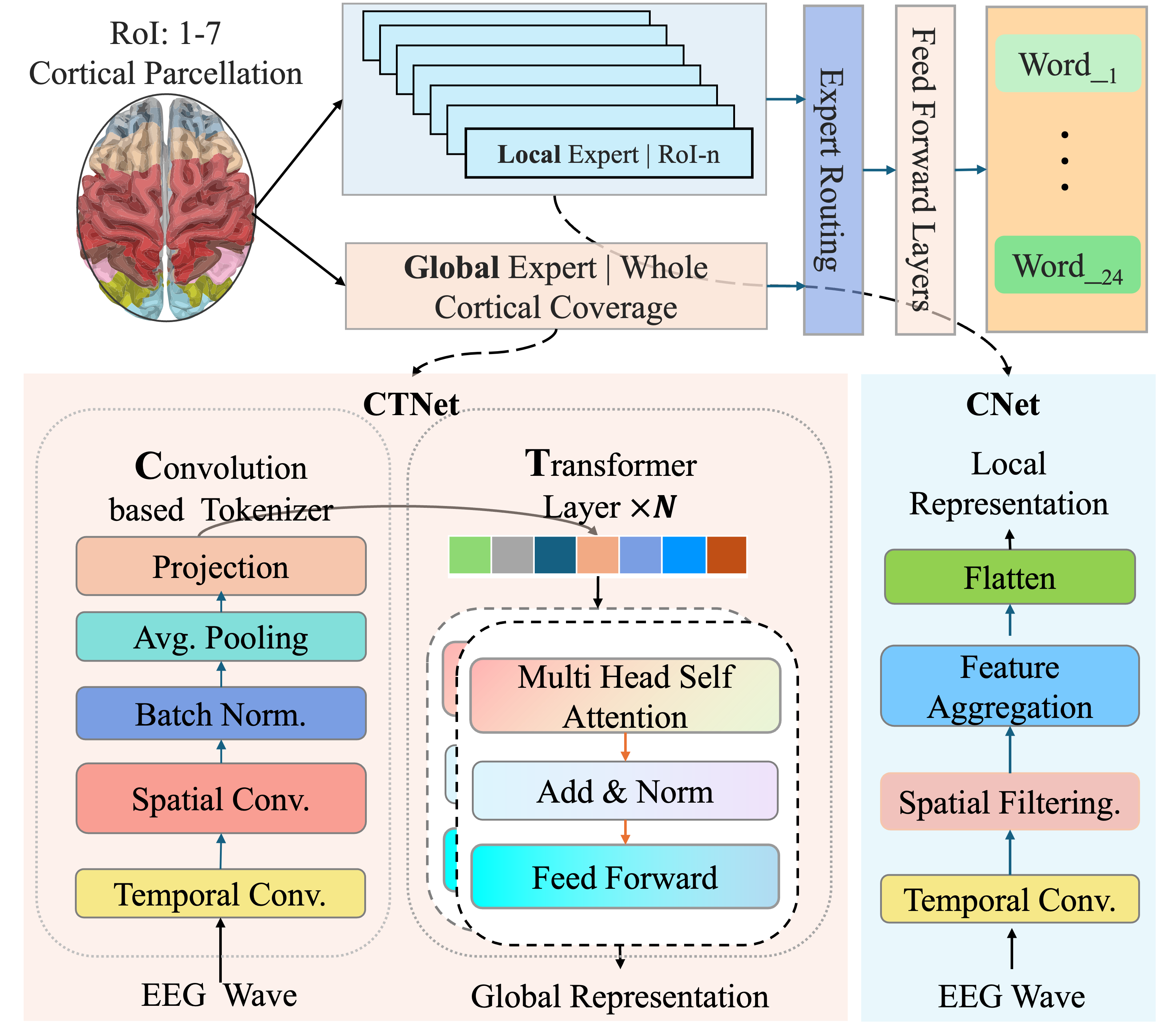
BrainStack: Нейро-вдохновлённая смесь экспертов
BrainStack представляет собой Neuro-MoE (нейронную смесь экспертов) архитектуру, разработанную для повышения эффективности декодирования беззвучной речи. В основе подхода лежит функциональное разделение задач между различными экспертами, что позволяет моделировать сигналы, поступающие из разных источников, с большей точностью. Использование смеси экспертов позволяет динамически выбирать и комбинировать специализированные модели для каждого конкретного входного сигнала, улучшая общую производительность системы декодирования беззвучной речи по сравнению с традиционными подходами.
Архитектура BrainStack опирается на принцип функциональной модульности коры головного мозга, где различные области специализируются на обработке определенных типов сигналов. В рамках BrainStack это реализуется посредством «Региональных Экспертов», каждый из которых предназначен для моделирования данных, поступающих из конкретной области сенсорного ввода. Такой подход позволяет системе эффективно обрабатывать и извлекать информацию, специфичную для каждого региона, что повышает общую производительность в задачах декодирования беззвучной речи. Каждый Региональный Эксперт обучается на данных, соответствующих определенному участку сенсорного пространства, что обеспечивает высокую степень специализации и, как следствие, более точное представление локальных характеристик сигнала.
Глобальный эксперт в архитектуре BrainStack выполняет функцию интеграции информации, поступающей от региональных экспертов, моделирующих сигналы из различных областей. Этот процесс позволяет улавливать долгосрочные зависимости, критически важные для контекстуального понимания речевого сигнала. В отличие от региональных экспертов, специализирующихся на локальных признаках, глобальный эксперт оценивает взаимодействие между различными областями, что необходимо для разрешения неоднозначностей и построения целостного представления о произносимой речи. Такой подход позволяет моделировать более сложные речевые паттерны и улучшать точность декодирования беззвучной речи.
Иерархическая дистилляция: Направляя экспертизу
Для эффективной тренировки архитектуры BrainStack используется иерархическая дистилляция — метод передачи семантического руководства от Глобального Эксперта к Региональным Экспертам. Данный подход позволяет оптимизировать процесс обучения, передавая знания, полученные Глобальным Экспертом при анализе всей входной информации, к более специализированным Региональным Экспертам, отвечающим за обработку отдельных частей данных. Это обеспечивает не только повышение точности модели, но и улучшает её способность к обобщению и адаптации к новым данным, поскольку региональные эксперты получают дополнительное контекстное понимание от глобального уровня.
Для обеспечения согласованного и когерентного декодирования в процессе иерархической дистилляции используется метрика KL-дивергенции. KL-дивергенция D_{KL}(P||Q) измеряет разницу между вероятностными распределениями, генерируемыми глобальным экспертом (P) и региональными экспертами (Q). Минимизация KL-дивергенции заставляет распределения региональных экспертов приближаться к распределению глобального эксперта, тем самым передавая семантическую информацию и гарантируя, что региональные эксперты генерируют декодированные данные, соответствующие общей стратегии глобального эксперта. Этот процесс обеспечивает более стабильное и предсказуемое поведение модели, повышая точность и эффективность.
Для повышения точности и эффективности модели используется априорная анатомическая информация. В процессе обучения система интегрирует знания о структуре и взаимосвязях анатомических областей, что позволяет корректировать выходные данные региональных экспертов и приводить их в соответствие с ожидаемыми анатомическими ограничениями. Это достигается путем включения анатомических признаков в функцию потерь, что обеспечивает более стабильное и достоверное декодирование, особенно в сложных или неоднозначных ситуациях. Использование априорных знаний снижает потребность в большом объеме размеченных данных и ускоряет процесс обучения.
Валидация и результаты: Декодирование с высокой точностью
Фреймворк BrainStack продемонстрировал превосходные результаты на наборе данных SS-EEG, представляющем собой крупномасштабную коллекцию ЭЭГ-записей, полученных в процессе «тихой речи» (silent speech). Средняя точность декодирования на данном наборе данных составила 41.87%. Набор данных SS-EEG включает записи электроэнцефалограммы, полученные во время попыток испытуемых произносить слова или фразы без фактической артикуляции, что позволяет исследовать нейронные корреляты речевого планирования и декодировать предполагаемые речевые сигналы.
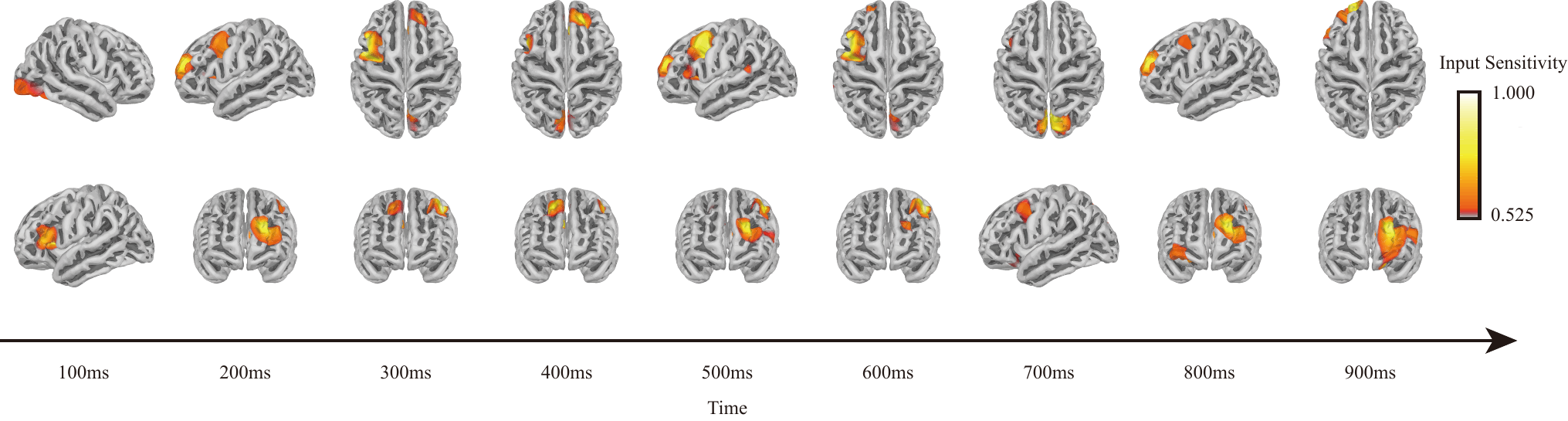
В основе BrainStack лежит механизм кросс-региональной интеграции, который объединяет информацию, полученную из различных областей коры головного мозга. Этот подход позволяет системе учитывать взаимосвязи между активностью в разных областях, что значительно повышает точность декодирования беззвучной речи. В отличие от традиционных методов, анализирующих активность только в отдельных областях, BrainStack использует информацию из нескольких корковых регионов одновременно, обеспечивая более полное и точное представление о намерениях говорящего. Данный метод позволяет учитывать пространственное распределение нейронной активности, что особенно важно для декодирования сложных речевых паттернов.
В ходе валидации на наборе данных SS-EEG, BrainStack продемонстрировал превосходство над всеми базовыми моделями, достигнув улучшения точности в 12.37% по сравнению с наиболее эффективной базовой моделью TCNet, которая показала результат в 29.50%. Таким образом, BrainStack достиг абсолютной точности в 41.87%, что подтверждает значительное повышение эффективности декодирования беззвучной речи по сравнению с существующими подходами.
Использование BrainStack предварительного обучения на больших объемах данных и методов самообучения значительно повышает обобщающую способность и устойчивость системы к различным условиям. В ходе тестирования на субъекте S01 была достигнута пиковая точность декодирования немого произношения на уровне 88.05%, что демонстрирует эффективность применяемых методов в улучшении результатов распознавания для отдельных пользователей.
За пределами декодирования: К нейро-вдохновлённому ИИ
BrainStack представляет собой важный шаг на пути к созданию искусственного интеллекта, более приближенного к биологическим принципам работы мозга и отличающегося повышенной эффективностью. В отличие от традиционных моделей, часто требующих огромного количества параметров, BrainStack демонстрирует сопоставимую производительность, используя значительно меньший их объем — всего 1.06 миллиона. Такой подход, вдохновленный иерархической организацией нейронных сетей мозга, позволяет не только снизить вычислительные затраты, но и повысить устойчивость и адаптивность системы. Разработчики полагают, что данная архитектура открывает новые возможности для создания ИИ, способного к более гибкому обучению и решению сложных задач, приближая нас к созданию действительно интеллектуальных машин.
Архитектура BrainStack представляет собой значительный прорыв в области создания более реалистичных и эффективных языковых моделей, вдохновлённых принципами работы мозга. В её основе лежит иерархический подход к обучению, имитирующий последовательную обработку информации в нейронных сетях. Данный подход позволяет модели извлекать абстракции различного уровня, начиная от простых признаков и заканчивая сложными семантическими понятиями. В отличие от традиционных моделей, которые часто полагаются на огромные объёмы данных и вычислительных ресурсов, BrainStack демонстрирует способность к эффективному обучению и высокой производительности при значительно меньшем количестве параметров. Это достигается за счёт использования биоморфных принципов организации и обучения, что открывает новые перспективы для создания более адаптивных, устойчивых и энергоэффективных систем искусственного интеллекта, способных к более глубокому пониманию и генерации естественного языка.
Разработанная система BrainStack демонстрирует впечатляющую эффективность, достигая сопоставимых результатов с моделью LaBraM, при этом используя значительно меньшее количество параметров — всего 1.06 миллиона против 5.80 миллиона у LaBraM. Данное достижение подчеркивает принципиальную возможность создания компактных и производительных искусственных интеллектов, вдохновленных структурой человеческого мозга. Сокращение числа параметров не только снижает вычислительные затраты, но и открывает перспективы для развертывания сложных моделей на устройствах с ограниченными ресурсами, что особенно важно для приложений, требующих обработки данных в реальном времени и интеграции с нейроинтерфейсами.
Дальнейшие исследования BrainStack направлены на расширение возможностей данной архитектуры за счет интеграции с другими методами нейроимиджинга, такими как электроэнцефалография и магнитоэнцефалография. Это позволит получить более полное представление о когнитивных процессах и создать более точные модели работы мозга. Особый интерес представляет потенциал BrainStack для разработки систем интерфейса «мозг-компьютер» реального времени, способных не только декодировать намерения пользователя, но и активно взаимодействовать с нейронной активностью, открывая перспективы для восстановления функций у пациентов с неврологическими нарушениями и создания принципиально новых способов управления устройствами.
Представленная работа демонстрирует стремление к редукции сложности в задачах нейродекодирования. BrainStack, используя архитектуру Mixture-of-Experts, явно моделирует функциональную модульность мозга, что позволяет добиться более эффективного декодирования беззвучной речи на основе ЭЭГ. Этот подход согласуется с принципом, сформулированным Джоном фон Нейманом: «Если система не объясняется в одном предложении, она не понята». В данном случае, ключевая идея — разделение задачи декодирования на экспертные модули, соответствующие различным аспектам языка — является лаконичным и понятным объяснением эффективности предложенного метода. Успех BrainStack подтверждает, что упрощение модели, основанное на нейробиологических принципах, может привести к значительным улучшениям в области нейрокомпьютерных интерфейсов.
Что дальше?
Представленная работа, хотя и демонстрирует эффективность подхода, основанного на функциональной модульности мозга, лишь обозначает границы неизведанного. Успех BrainStack не столько в достигнутом уровне декодирования, сколько в демонстрации необходимости отказа от упрощенных моделей нейронной обработки. Остается нерешенным вопрос о масштабируемости: действительно ли увеличение числа «экспертов» в модели пропорционально улучшает точность, или же наступает момент, когда сложность начинает препятствовать пониманию?
Более глубокое исследование требует перехода от простого моделирования функциональной модульности к пониманию её динамической природы. Мозг — не статичная карта, а постоянно меняющийся ландшафт. Следующим шагом видится разработка моделей, способных учитывать временные зависимости и контекстуальные изменения в нейронной активности. Проще говоря, необходимо научиться понимать не только где происходит обработка информации, но и когда и почему.
В конечном итоге, ценность подобных исследований не в создании идеального интерфейса «мозг-компьютер», а в углублении понимания самого мозга. Отказ от излишней сложности, стремление к ясности — вот истинная цель. И, возможно, когда-нибудь, мы поймем, что самое важное — это не то, что мы добавляем к модели, а то, что из неё удаляем.
Оригинал статьи: https://arxiv.org/pdf/2601.21148.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Как сбросить приложение безопасности Windows, чтобы устранить проблемы в Windows 11 и 10
- Нефть вниз, инфляция под контролем: что ждет российский рынок в апреле? (14.03.2026 04:32)
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Motorola Moto G67 Power ОБЗОР: яркий экран, плавный интерфейс, удобный сенсор отпечатков
- Неважно, на что вы фотографируете!
- HP Omen 16-ap0091ng ОБЗОР
- Лучшие ноутбуки с глянцевым экраном. Что купить в марте 2026.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- vivo Y05 ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, яркий экран
2026-02-02 02:35