Автор: Денис Аветисян
Новая платформа AIR-VLA объединяет возможности компьютерного зрения, обработки естественного языка и управления роботами для выполнения сложных задач в воздухе.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Представлен AIR-VLA — первый эталонный набор данных и система оценки для моделей «Видение-Язык-Действие» в области воздушной манипуляции.
Несмотря на значительные успехи моделей «Зрение-Язык-Действие» (VLA) в наземной робототехнике, их применение к системам воздушной манипуляции остается малоизученной областью. В данной работе представлена платформа ‘AIR-VLA: Vision-Language-Action Systems for Aerial Manipulation’, включающая в себя физически-реалистичную симуляцию и многомодальный набор данных из 3000 телеуправляемых демонстраций, предназначенный для оценки и разработки VLA-моделей в задачах воздушной манипуляции. Проведенные эксперименты подтверждают принципиальную возможность переноса парадигм VLA на воздушные системы, выявляя при этом их сильные и слабые стороны в контексте управления дроном и манипулятором. Сможем ли мы создать универсальных воздушных роботов, способных к сложным задачам манипуляции и планирования на основе понимания естественного языка?
Трудности Воплощения Интеллекта: Почему Роботы Застревают
Традиционная робототехника сталкивается с серьезными трудностями при решении сложных задач в реальном мире, требующих гибкого и долгосрочного планирования. В отличие от заранее запрограммированных действий в контролируемых условиях, большинство повседневных ситуаций характеризуются непредсказуемостью и необходимостью адаптации к меняющимся обстоятельствам. Существующие алгоритмы часто не способны эффективно строить последовательность действий, охватывающую длительный период времени, учитывая множество потенциальных препятствий и неопределенностей. Это особенно заметно в задачах, требующих манипулирования объектами, навигации в сложных средах или взаимодействия с людьми, где необходима не только точная координация движений, но и способность предвидеть последствия своих действий и корректировать планы в режиме реального времени. Преодоление этих ограничений требует разработки новых подходов к планированию, основанных на принципах обучения с подкреплением, вероятностного моделирования и способности к абстракции.
Современные роботизированные системы часто сталкиваются с трудностями при объединении восприятия окружающей среды, понимания естественного языка и осуществления действий в динамичных трехмерных пространствах. Несмотря на успехи в каждой из этих областей по отдельности, их эффективная интеграция остается сложной задачей. Роботы зачастую не способны полноценно интерпретировать словесные инструкции в контексте визуальной информации, а также адаптировать свои действия к изменяющимся условиям. Это приводит к тому, что даже относительно простые задачи, требующие гибкости и понимания контекста, оказываются недоступными для автономного выполнения. Успешное решение этой проблемы требует разработки новых алгоритмов и архитектур, способных обеспечить бесшовную интеграцию различных модальностей информации и эффективное планирование действий в сложных, непредсказуемых средах.
Для успешного выполнения задач, связанных с манипулированием объектами в загроможденном пространстве, роботам необходимы развитые способности к трехмерному пространственному мышлению. Это подразумевает не просто распознавание объектов, но и понимание их взаимного расположения, прогнозирование изменений в окружающей среде и планирование траекторий движения, позволяющих избегать столкновений и эффективно достигать целей. Сложность заключается в том, что реальный мир непредсказуем: объекты могут быть частично скрыты, освещение меняется, а неожиданные препятствия возникают постоянно. Поэтому робот должен уметь строить и поддерживать внутреннюю трехмерную модель окружения, используя данные с различных сенсоров, и динамически адаптировать свои планы в ответ на изменения. Разработка алгоритмов, способных к такому комплексному пространственному анализу и планированию, является ключевой задачей для создания действительно автономных и эффективных роботов-манипуляторов.
Несмотря на значительный прогресс в области робототехники, существующие ограничения в интеграции восприятия, языка и действий продолжают сдерживать возможности роботов к автономной деятельности. Без существенных прорывов в трехмерном пространственном мышлении и долгосрочном планировании, роботы остаются неспособными эффективно функционировать в сложных, динамичных средах и решать нетривиальные задачи, требующие адаптивности и гибкости. Ограниченность в этих ключевых областях препятствует широкому применению роботов в реальном мире, лишая их потенциала для самостоятельного выполнения задач, выходящих за рамки заранее запрограммированных сценариев и требующих импровизации в непредсказуемых условиях.
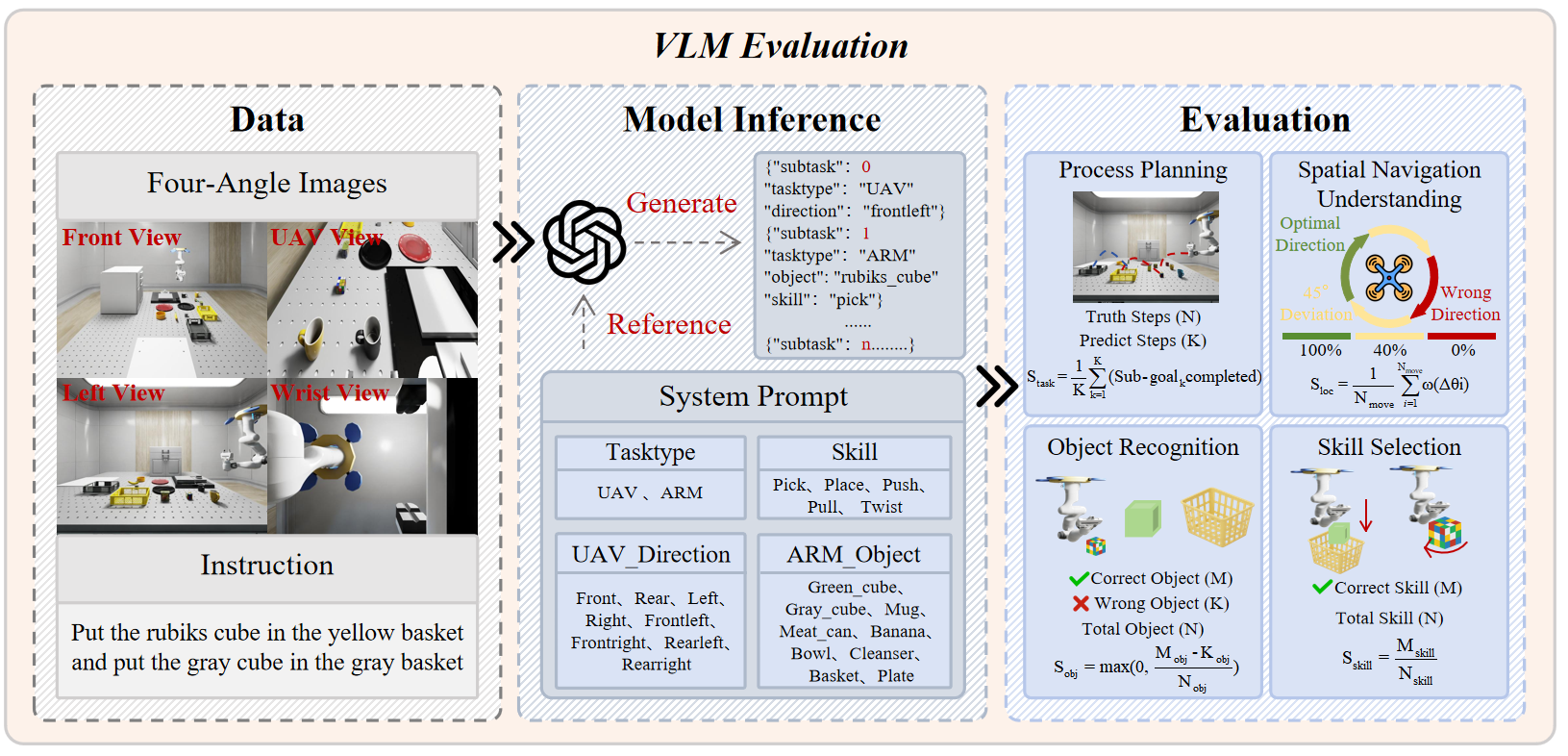
Видение, Язык и Действие: Новая Парадигма Управления
Модели «Видение-Язык-Действие» представляют собой унифицированную архитектуру, объединяющую обработку визуальной информации, понимание естественного языка и управление робототехническими системами. В рамках данной парадигмы, визуальные данные, полученные с помощью камер или других сенсоров, обрабатываются совместно с лингвистическими инструкциями, заданными на естественном языке. Этот объединенный подход позволяет модели не только интерпретировать команды, но и преобразовывать их в последовательность управляющих сигналов для манипуляторов и других исполнительных механизмов робота. Ключевым аспектом является создание единого пространства представлений, где визуальные признаки и семантические значения слов взаимосвязаны, что обеспечивает более эффективное и гибкое управление роботом в сложных условиях.
Методы, такие как группировка действий (Action Chunking), повышают эффективность моделей «Зрение-Язык-Действие» за счет прогнозирования последовательностей действий. Вместо планирования каждого отдельного шага, модель обучается предсказывать логические блоки действий, что значительно сокращает время вычислений и потребление ресурсов. Это особенно важно при выполнении сложных задач, требующих множества последовательных операций, поскольку позволяет модели сосредоточиться на высокоуровневом планировании, а детали реализации отдельных действий генерируются автоматически. Группировка действий снижает размер пространства поиска оптимального решения, что приводит к более быстрой и надежной работе робота в реальных условиях.
Методы диффузионной политики и связанные с ними подходы обеспечивают генерацию разнообразных и эффективных планов действий для роботов. В отличие от традиционных методов обучения с подкреплением, которые стремятся к определенной оптимальной политике, диффузионная политика формулирует задачу как процесс диффузии, позволяя генерировать множество правдоподобных траекторий действий из небольшого числа демонстраций. Этот подход использует вероятностные модели для моделирования распределения успешных действий и, таким образом, позволяет роботу адаптироваться к различным ситуациям и выполнять задачи, даже если они не были явно запрограммированы. В основе лежит процесс, аналогичный диффузии в физике, где шум постепенно добавляется к данным, а затем удаляется для генерации новых, но похожих данных, что обеспечивает высокую гибкость и устойчивость к изменениям в окружающей среде.
Модели «Зрение-Язык-Действие» играют ключевую роль в создании роботов, способных понимать и выполнять инструкции, сформулированные на естественном языке. В отличие от традиционных систем, требующих точного программирования каждого шага, эти модели используют обработку естественного языка (NLP) для анализа смысла запроса пользователя. Затем, на основе визуальной информации, полученной с камер и других сенсоров, и лингвистического понимания, модели генерируют последовательность координаций действий, необходимых для выполнения задачи. Это позволяет роботам адаптироваться к изменяющимся условиям и выполнять сложные манипуляции, не требуя предварительного программирования для каждого конкретного сценария. Эффективность данной парадигмы заключается в унификации процесса от восприятия до исполнения, что существенно расширяет возможности автоматизации в различных областях.
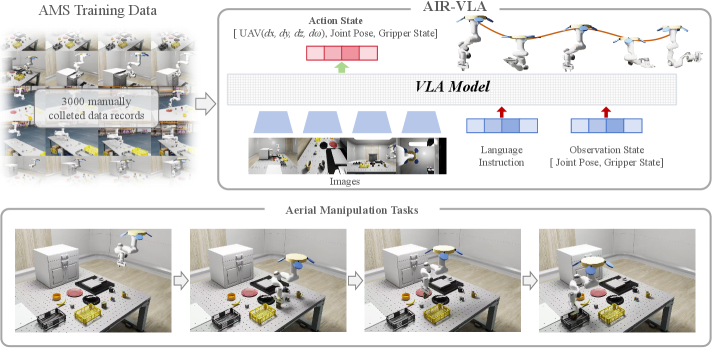
AIR-VLA: Преодолевая Разрыв Между Симуляцией и Реальностью
Платформа NVIDIA Isaac Sim предоставляет возможности для создания высокоточных симуляций, использующих формат Universal Scene Description (USD) для интеграции и управления цифровыми активами. USD обеспечивает модульную структуру, позволяющую эффективно описывать сложные сцены и объекты, что упрощает процесс создания реалистичных симуляций. Интеграция USD позволяет использовать широкий спектр 3D-моделей и материалов, а также обеспечивает масштабируемость и повторное использование ресурсов. Благодаря этому, Isaac Sim позволяет создавать детальные и сложные симуляции, необходимые для разработки и тестирования алгоритмов робототехники и искусственного интеллекта.
Эталонный набор AIR-VLA и оценочная среда предназначены для разработки и тестирования систем воздушной манипуляции в симуляции NVIDIA Isaac Sim. В ходе тестирования, системы демонстрируют успешность выполнения сложных задач на уровне до 85%. Оценка проводится на разнообразном наборе сценариев, включающих в себя захват, перемещение и сборку объектов, что позволяет комплексно оценить производительность и надежность разрабатываемых алгоритмов управления и планирования траекторий.
Для сбора разнообразных данных для обучения используются методы дистанционного управления оператором-человеком, дополненные большими языковыми моделями (LLM) для генерации инструкций. LLM позволяют создавать широкий спектр задач и сценариев, предоставляя оператору-человеку четкие и разнообразные указания для выполнения манипуляций. Этот подход позволяет собирать данные, отражающие сложность реальных условий, и значительно расширяет обучающую выборку, что способствует повышению обобщающей способности моделей и их адаптации к новым, ранее не встречавшимся ситуациям.
Подход, используемый в AIR-VLA, направлен на преодоление разрыва между симуляцией и реальным миром, что повышает переносимость обученных политик на практические сценарии. Достигнутая переносимость подтверждается способностью моделей успешно выполнять задачи в течение среднего времени, равного 475 временным шагам за эпизод. Это свидетельствует о возможности эффективного обучения агентов в симулированной среде NVIDIA Isaac Sim и последующего применения полученных навыков в реальных условиях, что критически важно для развития систем воздушной манипуляции.

Плавность Действий: Flow Matching для Естественного Управления
Модели, такие как π0 и π0.5, используют метод Flow Matching, позволяющий генерировать плавные и естественные последовательности действий. В основе этой техники лежит обучение непрерывному потоку действий, что позволяет преодолеть ограничения, связанные с дискретными пространствами действий, часто встречающимися в робототехнике. Вместо того чтобы выбирать из ограниченного набора команд, модели обучаются предсказывать непрерывные изменения в действиях, создавая более реалистичные и скоординированные движения. Этот подход особенно важен для сложных задач манипулирования, где точность и плавность действий критически важны для успешного выполнения.
Традиционные методы управления роботами часто опираются на дискретные действия — набор отдельных команд, что ограничивает плавность и естественность движений. Однако, модели, использующие метод обучения непрерывному потоку действий, преодолевают эти ограничения. Вместо отдельных команд, они учатся представлять действия как непрерывный процесс, что позволяет генерировать более сложные и скоординированные последовательности. Такой подход значительно улучшает выполнение задач, особенно в ситуациях, требующих высокой точности и адаптивности, поскольку позволяет роботу плавно переходить от одного действия к другому, избегая резких и неестественных движений, что в конечном итоге повышает эффективность и надежность его работы.
В результате применения данной методики наблюдается значительное повышение эффективности и координации движений роботов, что особенно важно при выполнении сложных манипуляционных задач. Модели, использующие Flow Matching, способны генерировать плавные и непрерывные последовательности действий, что позволяет им успешно справляться с задачами, требующими планирования на длительные временные горизонты — в экспериментах продемонстрирована успешная работа на протяжении более 600 временных шагов. Такая способность к генерации скоординированных движений открывает перспективы для создания роботов, способных к автономному выполнению сложных задач в реальных условиях, что подтверждается высокими показателями завершения задач VLA — до 85% при использовании тонкой настройки моделей.
Возможность генерации непрерывных последовательностей действий открывает новые перспективы для долгосрочного планирования и практического применения робототехнических систем. Исследования демонстрируют, что модели, способные создавать плавные и координированные движения, значительно повышают эффективность выполнения сложных манипуляционных задач. В частности, при тонкой настройке, такие модели достигают впечатляющих показателей успешного завершения задач VLA — до 85%, что свидетельствует о значительном прогрессе в области долгосрочного управления роботами и их адаптации к реальным условиям. Эта технология позволяет роботам действовать более естественно и предсказуемо, что критически важно для взаимодействия с окружающей средой и выполнения сложных операций на протяжении длительного времени.
Вновь появляется ощущение дежавю. AIR-VLA, этот бенчмарк для Vision-Language-Action систем в области аэриальной манипуляции, выглядит как очередной способ усложнить то, что когда-то работало и без излишней «эрудиции» искусственного интеллекта. Создатели утверждают, что закрывают пробел в исследованиях, но, вероятно, просто создают новую область для накопления технического долга. Как говорил Давид Гильберт: «В математике нет трамплина; нужно идти шаг за шагом». И здесь, кажется, та же история: очередная попытка взлететь, не построив надёжный фундамент. Этот бенчмарк, возможно, и продвинет область embodied AI, но стоит помнить: даже самые изящные алгоритмы рано или поздно столкнутся с суровой реальностью производственной среды.
Что дальше?
Введение набора данных AIR-VLA, безусловно, снимает один из наиболее острых вопросов в области воздушной манипуляции. Однако, за каждым решенным вопросом неизменно скрывается дюжина новых. Нынешние модели, демонстрирующие успехи на этом наборе данных, не более чем красивые иллюзии, работающие в контролируемой среде. Стоит вывести робота за пределы лаборатории, столкнуться с реальным освещением, случайными помехами и, прости господи, неидеальными объектами, как «интеллект» испаряется быстрее, чем оптимизм на релизе.
Настоящая проблема, как всегда, не в алгоритмах, а в данных. AIR-VLA — это лишь первый шаг. Потребуется терабайты размеченных данных, охватывающих бесконечное разнообразие сценариев и условий, чтобы модели действительно «поняли», что такое манипуляция в трехмерном пространстве. И даже тогда, рано или поздно, кто-нибудь обязательно попытается заставить робота собрать IKEA в темноте, и все начнётся сначала.
Поэтому, вместо того, чтобы праздновать «прорыв», стоит помнить: этот набор данных — не финишная прямая, а лишь очередной релиз, который через полгода станет частью техдолга. Мы не создаём искусственный интеллект — мы просто откладываем неизбежное столкновение теории с жестокой реальностью продакшена.
Оригинал статьи: https://arxiv.org/pdf/2601.21602.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Как сбросить приложение безопасности Windows, чтобы устранить проблемы в Windows 11 и 10
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Шоппинг в Гонконге. Где купить iPhone и iPad.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Простые советы, чтобы немедленно улучшить ваши фотографии.
- Нефть вниз, инфляция под контролем: что ждет российский рынок в апреле? (14.03.2026 04:32)
- Nothing Phone (4a) Pro ОБЗОР: большой аккумулятор, скоростная зарядка, замедленная съёмка видео
- Motorola Moto G67 Power ОБЗОР: яркий экран, плавный интерфейс, удобный сенсор отпечатков
- Виртуальные прогулки учат роботов ориентироваться
- Что такое стабилизатор и для чего он нужен?
2026-01-31 18:32