Автор: Денис Аветисян
Представлен TacUMI — устройство и алгоритм, позволяющие роботам эффективно обучаться манипулированию предметами, наблюдая за действиями человека.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"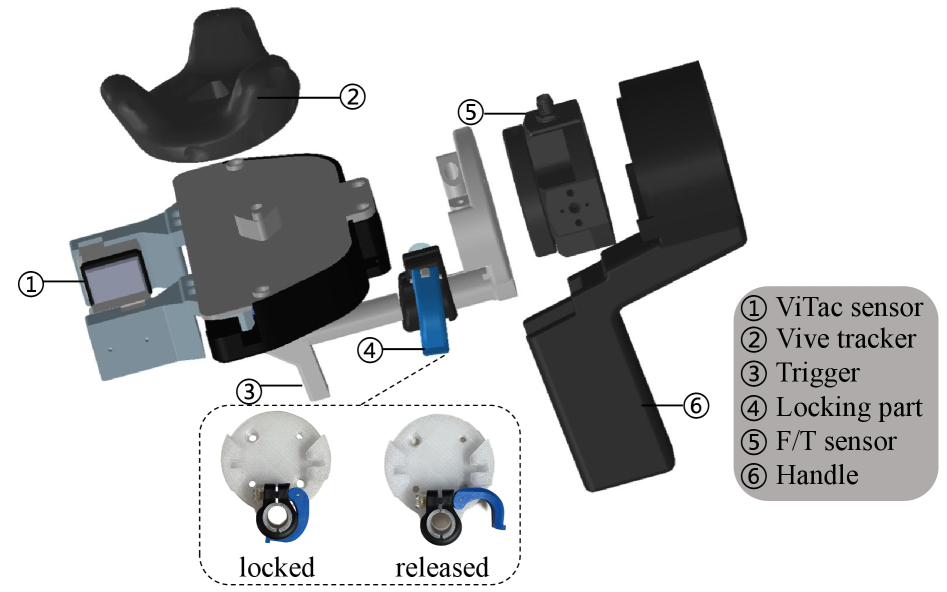
Разработан универсальный мультимодальный интерфейс для сбора данных и обучения роботов выполнению задач, требующих контакта с объектами и длительных последовательностей действий.
Декомпозиция сложных манипуляционных задач остается сложной проблемой, особенно при наличии интенсивного физического контакта. В данной работе представлена система TacUMI («Multi-Modal Universal Manipulation Interface for Contact-Rich Tasks») — портативное устройство для сбора многомодальных данных, включающее тактильные, силоизмерительные и позиционные сенсоры. Показано, что интеграция этих модальностей позволяет эффективно сегментировать демонстрации манипуляций, достигая точности более 90% на примере монтажа кабелей. Сможет ли TacUMI стать основой для создания более гибких и обучаемых робототехнических систем, способных к сложным взаимодействиям с окружающим миром?
Трудности долгосрочного манипулирования: почему роботы забывают, что делали вчера
Традиционные методы обучения роботов часто сталкиваются с трудностями при выполнении задач, требующих последовательности действий. Обучение, основанное на ограниченном количестве демонстраций, как правило, не позволяет роботу адаптироваться к незначительным изменениям в окружающей среде или к новым, не предусмотренным сценариям. Это связано с тем, что робот запоминает конкретные траектории и действия, а не приобретает глубокое понимание принципов, лежащих в основе задачи. В результате, даже небольшие отклонения от первоначальных условий могут привести к ошибкам и срыву выполнения. Неспособность к обобщению является серьезным препятствием для создания действительно автономных роботов, способных выполнять сложные, многоэтапные задачи в реальном мире.
Успешное выполнение сложных задач роботом требует не просто распознавания объектов, но и глубокого понимания динамики контакта между манипулятором и окружающей средой. Точное определение положения и ориентации (позы) робота на протяжении всего процесса манипулирования — критически важный аспект, поскольку даже незначительные отклонения в позе могут привести к сбоям в выполнении задачи, особенно при взаимодействии с хрупкими или деликатными объектами. Для достижения стабильности и точности необходимо учитывать силы, возникающие при контакте, предсказывать реакцию объектов на действия робота и непрерывно корректировать траекторию движения на основе получаемой сенсорной информации. Именно поэтому современные исследования направлены на разработку алгоритмов, способных моделировать и контролировать контактные взаимодействия, а также обеспечивать высокую точность оценки позы робота даже в условиях неопределенности и помех.
Существующие методы отслеживания положения и ориентации робота, такие как SLAM (Simultaneous Localization and Mapping), сталкиваются с проблемой накопления погрешности (дрифта) при длительной работе. Этот дрифт возникает из-за постепенного суммирования небольших ошибок в измерениях и вычислениях, что приводит к искажению представления робота о своем местоположении и ориентации в пространстве. В контексте задач, требующих выполнения последовательности действий на протяжении длительного времени, даже небольшое отклонение в оценке положения может привести к существенным ошибкам и неудаче всей операции. Поэтому, для достижения надежной манипуляции в долгосрочной перспективе, необходимы новые подходы к отслеживанию положения, способные минимизировать накопление погрешности и поддерживать высокую точность на протяжении всего процесса выполнения задачи.
Для решения задач манипулирования на больших временных горизонтах недостаточно полагаться исключительно на визуальную информацию. Успешное выполнение сложных действий требует глубокого понимания тактильных ощущений, силы, а также проприоцепции — ощущения положения и движения собственного тела робота. Использование мультисенсорных систем, включающих тактильные датчики, датчики силы и момента, инерциальные измерительные блоки, позволяет компенсировать недостатки визуального восприятия, особенно в условиях недостаточной освещенности или при частичной окклюзии объектов. Такой подход обеспечивает более надежную оценку состояния окружающей среды и позволяет роботу адаптироваться к непредвиденным изменениям, значительно повышая устойчивость и точность манипуляций на протяжении длительных периодов времени. Более того, интеграция различных сенсорных модальностей позволяет создать более полную и детализированную картину происходящего, что критически важно для принятия обоснованных решений и выполнения сложных задач.
TacUMI: платформа для сбора данных, где важны не только картинки
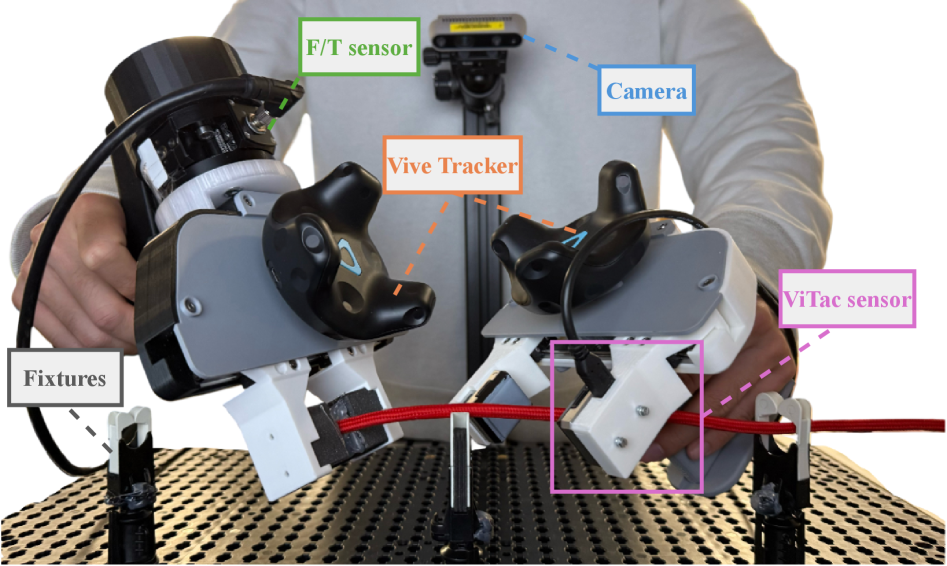
Платформа TacUMI развивает концепцию Универсального Интерфейса Манипуляций (UMI) путем интеграции тактильных датчиков и датчиков силы/момента. В отличие от UMI, ориентированного преимущественно на визуальную обратную связь, TacUMI дополняет её данными, получаемыми от тактильных сенсоров, таких как GelSight Mini, и датчиков измерения силы и момента. Такая комбинация позволяет собирать информацию о силах взаимодействия и положении робота в пространстве, что расширяет возможности системы и повышает точность манипуляций. Базовый функционал UMI остается основой, а добавленные датчики предоставляют более детальную и комплексную картину процесса взаимодействия.
Платформа TacUMI обеспечивает комплексное представление о взаимодействии робота с окружающей средой путем объединения данных от различных сенсоров. Тактильные сенсоры, такие как GelSight Mini, предоставляют информацию о контактном давлении и форме поверхности, с которой взаимодействует робот. Датчики силы и момента (F/T sensors) измеряют силы и моменты, приложенные к манипулятору, что позволяет оценить усилия, необходимые для выполнения задачи. Шестиградусная система отслеживания положения (Vive Tracker) обеспечивает точное определение положения и ориентации манипулятора в пространстве. Совместное использование этих данных позволяет получить полную картину взаимодействия робота с объектами, необходимую для обучения алгоритмов управления и планирования движений.
Платформа TacUMI предоставляет возможность сбора высококачественных данных, необходимых для обучения алгоритмов робототехники, расширяя возможности обучения за счет использования информации, отличной от исключительно визуальной. Традиционно, обучение роботов часто опирается на обработку изображений, что ограничивает их способность адаптироваться к сложным и неопределенным условиям. TacUMI, интегрируя данные от тактильных датчиков, датчиков силы/момента и систем отслеживания положения, позволяет роботам воспринимать взаимодействие с окружающей средой более полно, что существенно улучшает качество обучения и позволяет создавать более надежные и адаптивные системы. Это особенно важно для задач, требующих точного управления силой и тактильной обратной связи, таких как сборка, манипулирование деликатными объектами и взаимодействие с человеком.
При использовании платформы TacUMI время выполнения задачи по монтажу кабеля составило 1 минуту 10 секунд. Это представляет собой значительное улучшение по сравнению с 4 минутами, необходимыми при телеоперационном управлении. Данное сокращение времени свидетельствует об эффективности использования мультимодальных данных, собранных TacUMI, для обучения алгоритмов управления роботом и повышения автономности выполнения сложных манипуляционных задач.
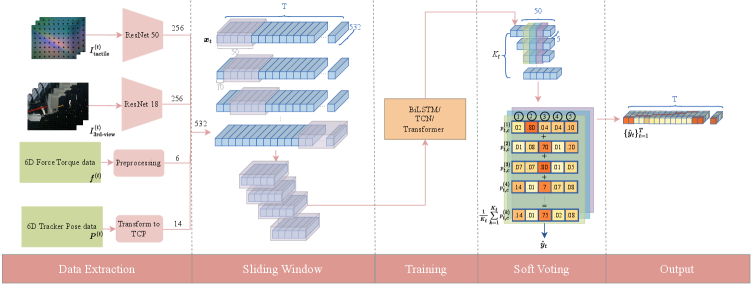
Сегментация навыков: как робот учится разбирать задачу на части
Сегментация событий является ключевым методом декомпозиции непрерывных демонстраций на отдельные сегменты навыков, что позволяет реализовать модульное обучение. Этот подход предполагает разделение сложной задачи на более простые, управляемые подзадачи, каждая из которых соответствует определенному навыку или этапу выполнения. Разбиение непрерывного потока данных на дискретные сегменты позволяет системе изучать и повторно использовать отдельные навыки, упрощая процесс обучения и повышая эффективность. Использование сегментированных данных также способствует улучшению обобщающей способности модели, позволяя ей адаптироваться к новым ситуациям и выполнять более сложные задачи.
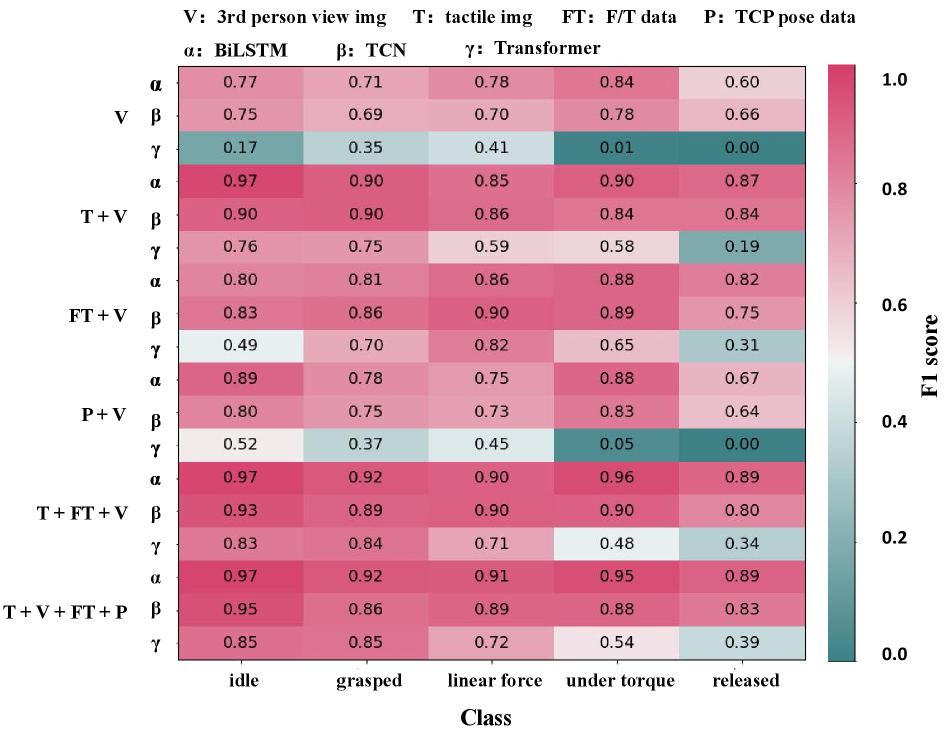
Для точной сегментации событий и выделения отдельных навыков в непрерывных демонстрациях были использованы передовые архитектуры глубокого обучения, включая BiLSTM, Temporal Convolutional Networks (TCN) и Transformer. Экспериментальные данные показали, что модель BiLSTM, использующая полный мультимодальный ввод (данные от различных сенсоров), демонстрирует наивысшую точность на уровне отдельных кадров (Frame-wise Accuracy). Использование BiLSTM позволило добиться более эффективного анализа временных зависимостей в данных, что критически важно для точного определения границ между отдельными навыками в демонстрациях.
Для повышения устойчивости и точности сегментации навыков используется метод «мягкого голосования» (soft voting) с применением перекрывающихся окон. Суть подхода заключается в агрегации предсказаний, полученных для каждого временного шага из нескольких окон, центрированных вокруг этого шага. Вместо выбора единственного предсказания для каждого момента времени, вероятности для всех классов усредняются по всем окнам. Это позволяет сгладить случайные ошибки и повысить надежность определения границ между навыками, особенно в случаях, когда входные данные зашумлены или демонстрируют небольшие вариации во времени выполнения.
Несмотря на высокую общую производительность моделей сегментации действий, класс действия ‘released’ (отпускание/освобождение) показал наименьший показатель F1-меры. Это указывает на сложность точной сегментации действий очень короткой продолжительности. Проблема заключается в том, что кратковременные события сложнее идентифицировать и отделить от окружающего контекста, что приводит к увеличению числа ложноположительных и ложноотрицательных результатов при сегментации, и, следовательно, к снижению F1-меры для данного класса.
К надежному и адаптивному манипулированию: будущее робототехники уже здесь
Комбинация TacUMI и передовых методов сегментации событий открывает новые возможности для обучения роботов сложным задачам, требующим длительного планирования и высокой устойчивости к помехам. Данный подход позволяет роботу не просто следовать заранее заданной программе, но и анализировать последовательность действий, выделяя ключевые этапы и адаптируясь к изменениям в окружающей среде или в самой задаче. Благодаря способности разделять сложные манипуляции на более простые, управляемые сегменты, робот способен не только повысить точность выполнения, но и эффективно использовать накопленный опыт при решении новых, схожих задач, значительно ускоряя процесс обучения и повышая надежность работы в динамичных условиях. Эта интеграция представляет собой значительный шаг к созданию действительно интеллектуальных робототехнических систем, способных к автономной работе и адаптации к непредсказуемым обстоятельствам.
Традиционно, роботы, выполняющие манипуляции с объектами, требовали детального предварительного программирования каждого этапа действия. Однако, представленный подход кардинально меняет эту парадигму, позволяя роботам адаптироваться к изменяющимся условиям окружающей среды и требованиям задачи. Вместо жестко заданных инструкций, робот способен самостоятельно анализировать ситуацию и корректировать свои действия в реальном времени, что особенно важно при работе с непредсказуемыми объектами или в динамичной обстановке. Такая гибкость достигается благодаря способности к обучению на основе опыта и выявлению закономерностей, что значительно повышает надежность и эффективность выполнения задач в различных, часто неидеальных, условиях. Роботы больше не ограничены заранее определенными сценариями, а способны к проактивному реагированию и самостоятельному решению возникающих проблем.
Разделение сложных задач манипулирования на отдельные, модульные навыки открывает принципиально новые возможности для робототехники. Вместо разработки уникальных программ для каждого конкретного действия, система способна изучать и повторно использовать базовые навыки в различных контекстах. Это значительно ускоряет процесс обучения роботов новым функциям, поскольку не требуется заново программировать каждый этап. Более того, модульность позволяет эффективно переносить приобретенные навыки на схожие задачи, даже если они выполняются в незнакомой среде или с новыми объектами. Такой подход, основанный на повторном использовании и адаптации, значительно повышает эффективность и гибкость роботов, приближая их к способности самостоятельно решать широкий спектр задач.
Точное восприятие и моделирование тонкостей манипулирования позволяет роботам значительно повысить свою точность, эффективность и адаптивность. Исследования показывают, что способность различать мельчайшие изменения в силе, положении и текстуре объектов позволяет роботам не только успешно выполнять запланированные действия, но и оперативно корректировать свои движения в ответ на непредвиденные обстоятельства. Такой подход выходит за рамки жестко запрограммированных последовательностей, позволяя машинам обучаться на собственном опыте и приспосабливаться к разнообразным условиям окружающей среды. В результате, роботы становятся более надежными и универсальными помощниками в сложных и динамичных задачах, будь то сборка электронных компонентов, обслуживание оборудования или даже помощь в хирургических операциях.

Исследование представляет TacUMI — устройство для сбора данных, которое, судя по описанию, должно упростить обучение роботов манипулированию. Но не стоит обольщаться. За каждой «революционной» технологией скрывается гора коммитов технического долга. Авторы утверждают, что их система сегментирует сложные задачи на более простые этапы, что, в теории, должно ускорить процесс обучения. Однако, опыт подсказывает, что «простые» этапы быстро обрастут исключениями и хаками, а документация, как обычно, соврет. Как метко заметил Г.Х. Харди: «Прикладная математика — это искусство обеспечения того, чтобы ложные идеи были полезными». Именно это и есть TacUMI — очередная попытка сделать из сложной системы «когда-то простой bash-скрипт», который, вероятно, потребует постоянной поддержки и доработки.
Что дальше?
Представленное устройство, TacUMI, как и любое другое средство сбора данных, неизбежно станет частью сложной системы, где узкое место найдётся в другом месте. Задача сегментации манипуляций, безусловно, важна, но стоит помнить, что реальный мир не ждёт, пока алгоритм решит, где начинается и заканчивается «полезное» действие. Скорее, он просто накажет за задержку. И это ещё не говоря о вариациях в освещении, текстурах, и неизбежных ошибках сенсоров — тех самых, которые всегда обнаруживаются после релиза.
Очевидно, что следующий этап — попытка обобщения. Но здесь кроется опасность: каждое новое обобщение — это компромисс между точностью и устойчивостью. И, как показывает практика, продлить страдания существующей системы куда проще, чем построить новую, идеально работающую. Стоит задуматься, не превратится ли стремление к универсальности в бесконечную погоню за идеально чистыми данными, которых в принципе не существует.
В конечном итоге, ценность подобных разработок измеряется не столько возможностью имитировать человеческие движения, сколько способностью создавать достаточно надёжные системы, которые можно будет чинить в полевых условиях, используя изоленту и молитвы. И, вероятно, именно эта приземлённость — наиболее реалистичный прогноз развития области.
Оригинал статьи: https://arxiv.org/pdf/2601.14550.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие смартфоны. Что купить в марте 2026.
- Новые смартфоны. Что купить в марте 2026.
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Неважно, на что вы фотографируете!
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Realme 9 ОБЗОР: чёткое изображение, лёгкий, высокая автономность
- Российский рынок: Нефть, геополитика и лидерство «Сбербанка» (11.03.2026 13:32)
- Руководство по Stellaris — Полное прохождение на 100%
- Infinix Note 60 Ultra ОБЗОР: скоростная зарядка, объёмный накопитель, отличная камера
2026-01-22 14:06