Автор: Денис Аветисян
Новый подход позволяет моделям искусственного интеллекта ориентироваться в пространстве, понимая не только визуальную информацию, но и текстовые инструкции.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"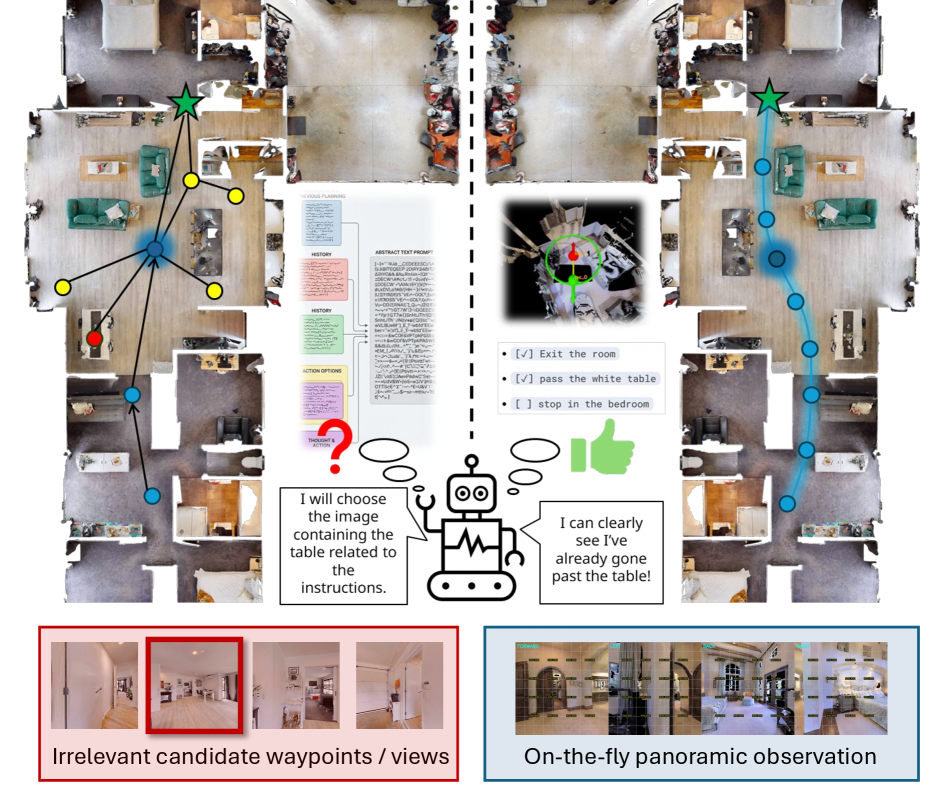
Предложена структура GTA, отделяющая пространственное и семантическое рассуждение для навигации с использованием мультимодальных больших языковых моделей и представления мира в виде интерактивной метрической модели.
Несмотря на успехи мультимодальных больших языковых моделей (MLLM), их применение в задачах навигации по визуальным и языковым инструкциям часто ограничивается тесной связью между восприятием и планированием. В работе ‘One Agent to Guide Them All: Empowering MLLMs for Vision-and-Language Navigation via Explicit World Representation’ предложен новый подход, разделяющий низкоуровневую оценку пространственного состояния и высокоуровневое семантическое планирование. Ключевым элементом является интерактивное метрическое представление мира, позволяющее MLLM взаимодействовать с окружающей средой и рассуждать о ней, а также применение контрфактического рассуждения для повышения качества принимаемых решений. Возможно ли создание действительно универсального агента, способного к адаптивной навигации в различных реальных условиях, используя предложенный фреймворк?
Иллюзия Понимания: Вызовы Ориентации в Пространстве
Традиционные модели навигации, основанные на обработке изображений и языка, зачастую испытывают трудности при выполнении сложных, многошаговых инструкций. Суть проблемы заключается в том, что алгоритмы сталкиваются с необходимостью последовательного понимания и применения нескольких указаний, каждое из которых зависит от предыдущего и текущего визуального контекста. Неспособность адекватно интерпретировать взаимосвязи между инструкциями и визуальной информацией приводит к ошибкам в планировании маршрута и, как следствие, к неудачам в достижении конечной цели. Например, фраза “Поверните налево после второго стола, а затем пройдите прямо до красной двери” требует от модели не только распознавания объектов (“стол”, “дверь”), но и запоминания последовательности действий и их взаимосвязи с окружающей средой. Подобные задачи демонстрируют ограничения существующих подходов и подчеркивают потребность в более совершенных методах обработки и понимания сложных инструкций для обеспечения надежной и эффективной навигации.
Исследования показывают, что простое увеличение числа параметров в моделях искусственного интеллекта, занимающихся навигацией и пониманием языка, не приводит к существенному улучшению их способности к надежному восприятию окружающего мира. Несмотря на впечатляющий прогресс в области машинного обучения, модели часто сталкиваются с трудностями при интерпретации неоднозначных инструкций или адаптации к непредсказуемым условиям реальной среды. Увеличение масштаба, хотя и способствует улучшению некоторых аспектов производительности, не решает фундаментальную проблему — необходимость глубокого понимания пространственных отношений и семантического контекста, что требует принципиально новых подходов к архитектуре и обучению моделей. Простое наращивание вычислительных ресурсов не компенсирует недостаток качественного представления знаний о мире и способности к логическому выводу.
Существующие подходы к навигации, основанные на анализе визуальной информации и языка, часто демонстрируют неустойчивость при столкновении с неоднозначными формулировками инструкций или непредвиденными изменениями в окружающей среде. Эта проблема обусловлена тем, что модели, как правило, полагаются на заученные шаблоны и испытывают трудности с адаптацией к новым, нестандартным ситуациям. Неспособность адекватно интерпретировать нечёткие указания или учитывать неожиданные препятствия приводит к ошибкам в навигации и снижает эффективность систем. Таким образом, для достижения надежной и гибкой навигации в реальном мире необходим принципиально новый подход, который позволит моделям понимать язык более контекстуально и реагировать на изменения окружающей среды с большей степенью адаптивности и устойчивости.
Разделение Ответственности: Новый Дизайн для Эффективности
Предлагаемый нами подход к разделению пространственного и семантического рассуждений заключается в организации системы таким образом, чтобы эти два типа обработки информации выполнялись независимо друг от друга. Такое разделение позволяет оптимизировать каждый компонент — пространственный и семантический — отдельно, что приводит к повышению общей эффективности системы. В частности, независимая оптимизация способствует улучшению обобщающей способности модели, позволяя ей лучше адаптироваться к новым, ранее не встречавшимся данным и сценариям. Разделение позволяет избежать интерференции между процессами, что особенно важно в сложных задачах, требующих точного понимания как окружающей среды, так и целей действия.
В отличие от тесно связанных (tightly coupled) архитектур, где пространственное и семантическое восприятие обрабатываются совместно, что приводит к взаимным помехам и снижению эффективности, предлагаемый подход разделяет эти два процесса. В тесно связанных системах, изменения в одной области обработки неизбежно влияют на другую, затрудняя оптимизацию каждого компонента по отдельности. Это особенно заметно при решении задач, требующих как понимания языка, так и навигации в пространстве, где ошибки в семантической интерпретации могут приводить к неправильным траекториям, и наоборот. Разделение позволяет оптимизировать каждый модуль независимо, повышая общую производительность и обобщающую способность системы.
Фреймворк ‘Guide Them All’ (GTA) использует принцип разделения пространственного и семантического рассуждений для достижения возможностей навигации по визуальным инструкциям (VLN) в условиях нулевой обучаемости. В отличие от традиционных подходов, требующих специализированного обучения для каждой новой среды или задачи, GTA позволяет модели выполнять навигацию, опираясь исключительно на общую способность к разделению и независимому анализу визуальной информации и семантических инструкций. Это достигается за счет архитектуры, которая обрабатывает пространственные данные и семантические указания параллельно, избегая интерференции и позволяя модели обобщать знания, полученные в различных средах, без необходимости тонкой настройки для конкретной задачи. Таким образом, GTA демонстрирует способность к выполнению навигации в ранее невиданных окружениях, используя только визуальные входные данные и текстовые инструкции.

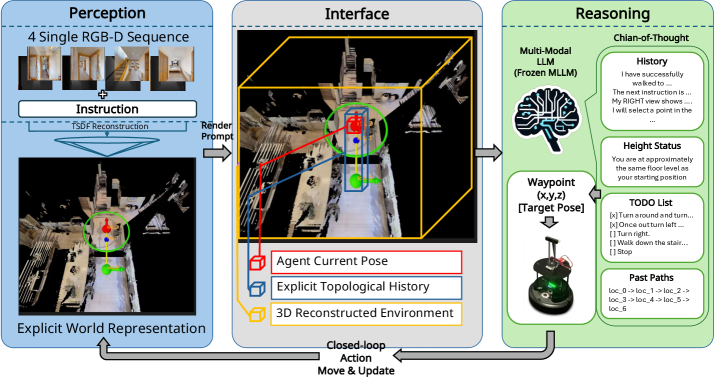
Построение Модели Мира: Интерактивное Представление
GTA использует интерактивное метрическое представление мира, созданное путем объединения топологического графа и усеченного поля знаковых расстояний. Топологический граф моделирует связность пространства, определяя основные узлы и пути между ними, что позволяет агенту ориентироваться в общей структуре окружения. Усеченное поле знаковых расстояний, в свою очередь, предоставляет точную информацию о расстоянии до препятствий и других объектов, позволяя агенту рассчитывать оптимальные траектории и избегать столкновений. Комбинирование этих двух подходов обеспечивает как глобальное понимание пространства, так и локальную точность позиционирования, что необходимо для эффективного планирования пути и навигации.
Сочетание топологического графа и усеченного поля знаковых расстояний позволяет агенту одновременно рассуждать о проходимом пространстве и точных координатах. Топологический граф обеспечивает понимание общей структуры окружения и связей между локациями, в то время как поле знаковых расстояний предоставляет информацию о расстоянии до препятствий и свободных участков пути. Это комбинированное представление позволяет агенту эффективно планировать маршруты, обходя препятствия и достигая заданных целей даже в сложных и динамично меняющихся условиях. Обеспечение надежного планирования пути и обхода препятствий является критически важным для успешной навигации агента в виртуальной среде.
Для повышения способности агента предвидеть и реагировать на изменения в окружающей среде используется механизм контрфактического рассуждения, направляемый процедурными схемами рассуждений (Procedural Reasoning Blueprints). Этот подход позволяет агенту моделировать альтернативные сценарии развития событий и выбирать оптимальные действия на их основе. В результате применения данного метода на тестовом наборе данных R2R-CE зафиксировано увеличение показателя Oracle Success Rate (OSR) на 8.4%, что свидетельствует о повышении эффективности навигации и выполнения задач в динамической среде.

Подтверждение Эффективности и Реальное Влияние
Исследования, проведенные в симуляторе Habitat с использованием эталонов R2R-CE и RxR-CE, продемонстрировали впечатляющую эффективность разработанной системы GTA. Достигнута передовая результативность в 48.8% на R2R-CE, что свидетельствует о высокой точности навигации и понимания инструкций. При этом, GTA значительно превзошла предыдущие лучшие решения в тесте RxR-CE, показав результат в 42.2%, что подтверждает ее превосходство в более сложных сценариях взаимодействия с окружающей средой и выполнении поставленных задач. Эти показатели подчеркивают потенциал системы для создания интеллектуальных агентов, способных эффективно ориентироваться и действовать в реалистичных виртуальных пространствах.
Особенностью разработанной системы GTA является её способность к выполнению задач без предварительного, обширного обучения на специализированных данных. Это достигается благодаря архитектуре, позволяющей эффективно обобщать полученные знания и адаптироваться к новым условиям. В отличие от многих существующих подходов, требующих значительных объёмов размеченных данных для каждой конкретной задачи, GTA демонстрирует высокую производительность, опираясь на уже имеющиеся знания о мире и принципах навигации. Такая “нулевая” обучаемость существенно упрощает процесс внедрения системы в новые среды и позволяет сократить затраты на сбор и разметку данных, открывая возможности для широкого спектра приложений, где получение специализированных обучающих выборок затруднено или невозможно.
Развертывание системы GTA на мобильной роботизированной платформе TurtleBot 4 и беспилотном летательном аппарате демонстрирует ее перспективность для практического применения в реальном мире. В ходе экспериментов обе платформы достигли впечатляющего уровня успешного выполнения задач — 40% для TurtleBot 4 и 42% для дрона — в рамках переноса обучения из симуляции в реальность. Этот результат свидетельствует о способности GTA эффективно адаптироваться к условиям реальной среды, несмотря на неизбежные расхождения между симуляцией и физическим миром, что открывает возможности для широкого спектра применений, включая навигацию в помещениях, инспекцию объектов и автономную доставку.
Исследование демонстрирует, что попытки создать универсальные модели для навигации в визуальном пространстве неизбежно сталкиваются с необходимостью компромисса между семантическим пониманием и точным представлением метрической информации об окружении. В рамках предложенного подхода GTA, авторы стремятся разделить эти аспекты, создавая интерактивную модель мира. Как однажды заметила Грейс Хоппер: «Лучший способ предсказать будущее — это создать его». Эта фраза отражает суть работы — не просто адаптироваться к существующим ограничениям, но и активно формировать архитектуру, позволяющую моделировать мир таким образом, чтобы обеспечить эффективную навигацию, даже в условиях отсутствия предварительного обучения. В конечном итоге, даже самая элегантная теория нуждается в проверке деплоем, и предложенный фреймворк — это попытка построить именно такую надежную, компромиссную основу.
Что дальше?
Представленная работа, безусловно, элегантна в своей попытке разделить пространственный и семантический аспекты навигации. Однако, как показывает опыт, любая абстракция рано или поздно встретится с суровой реальностью продакшена. Идеальная метрическая репрезентация мира — это прекрасно, пока не появится непредсказуемое освещение, отражение в зеркале или просто ошибка в датчиках. Заманчиво говорить о нулевом обучении, но всегда найдется крайний случай, который заставит систему споткнуться.
Перспективы дальнейших исследований, очевидно, лежат в области повышения робастности к неидеальным данным и непредсказуемым ситуациям. Более того, возникает вопрос: а действительно ли необходимо разделять пространственное и семантическое? Возможно, истинная сила кроется в их неразрывном взаимодействии, в нелинейных моделях, способных адаптироваться к хаосу реального мира. Всё, что можно задеплоить — однажды упадёт, и это нужно учитывать.
В конечном итоге, эта работа — ещё один шаг на пути к созданию действительно разумных агентов. Шаг, который, несомненно, красив, но, как и все остальные, обречен на столкновение с неизбежностью. И в этом, пожалуй, и заключается вся прелесть.
Оригинал статьи: https://arxiv.org/pdf/2602.15400.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Неважно, на что вы фотографируете!
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Лучшие смартфоны. Что купить в апреле 2026.
- Технологии и вера: новый взгляд на инклюзивный дизайн
- Рекомендации нового поколения: объединяя визуальное и текстовое
- Что такое ISO в фотоаппарате
- Российский рынок: Резервы тают, инвестиции растут, прибыли падают: что ждет инвесторов? (02.04.2026 16:32)
2026-02-19 00:10