Автор: Денис Аветисян
Новое исследование раскрывает, как модели искусственного интеллекта объединяют зрительную и языковую информацию, чтобы создавать осмысленные описания изображений.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"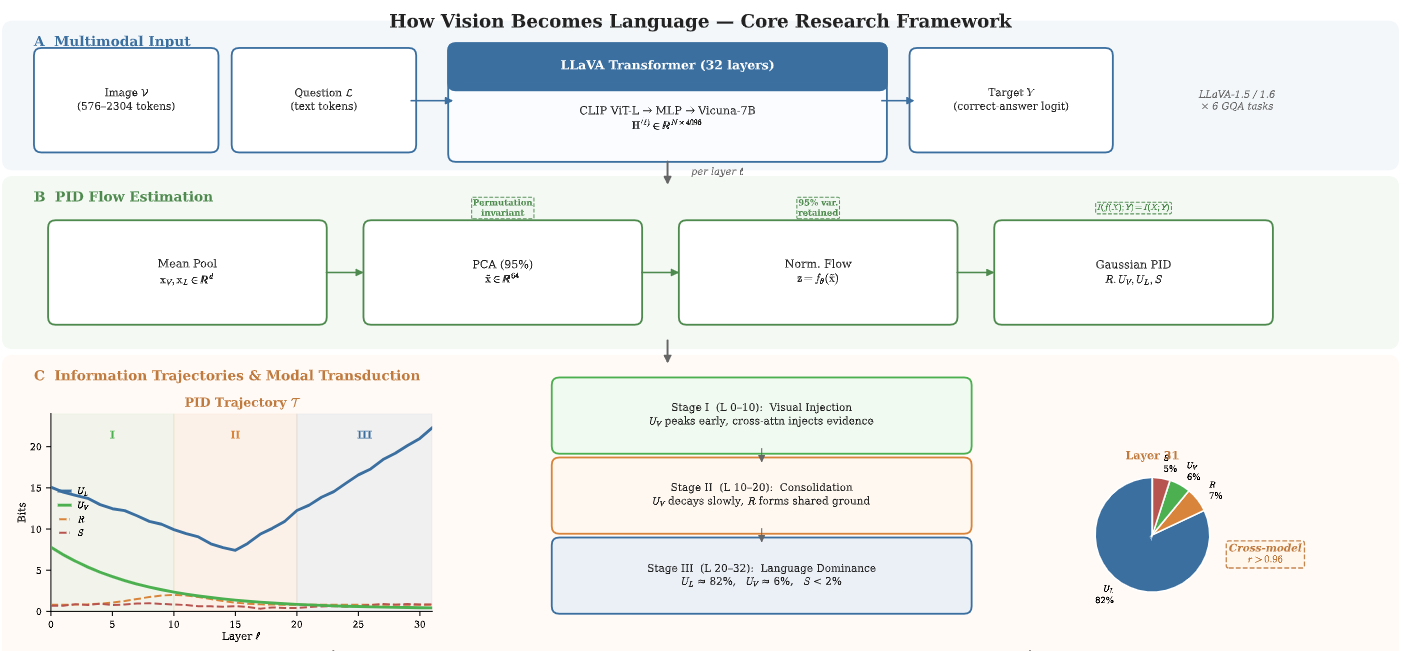
Предложен метод декомпозиции информационных потоков в мультимодальных больших языковых моделях, выявивший закономерность ‘модальной трансдукции’, при которой визуальная информация ассимилируется языковыми представлениями.
Несмотря на успехи мультимодальных больших языковых моделей, остается неясным, каким образом визуальная информация преобразуется в лингвистическое представление в процессе ответа на вопросы. В работе ‘How Vision Becomes Language: A Layer-wise Information-Theoretic Analysis of Multimodal Reasoning’ предложен метод, основанный на разложении частичной информации (PID), для анализа трансформации визуальных и лингвистических данных на каждом слое модели. Результаты показывают, что визуальная информация преимущественно абсорбируется в лингвистические представления по мере углубления в сеть, в то время как синергия между модальностями остается ограниченной. Какие архитектурные ограничения препятствуют более эффективному слиянию визуальной и лингвистической информации и как их можно преодолеть для создания более интеллектуальных мультимодальных систем?
Деконструкция Мультимодальной Информации
Многомодальные модели, такие как LLaVA, демонстрируют впечатляющую способность к комплексному пониманию данных, объединяя визуальную и лингвистическую информацию. Однако, несмотря на эти успехи, эффективное исследование внутренних механизмов обработки данных в этих моделях остается сложной задачей. Процесс деконструкции информационных потоков внутри таких систем затруднен сложностью архитектуры и взаимодействием различных слоев нейронной сети. Понимание того, как визуальные признаки преобразуются и интегрируются с текстовыми данными, требует разработки новых методов анализа, позволяющих проследить путь информации от входных данных до конечного результата. Отсутствие прозрачности в этом процессе препятствует целенаправленной оптимизации моделей и ограничивает возможности интерпретации принимаемых ими решений.
Понимание взаимодействия визуальной и лингвистической информации является ключевым фактором в создании по-настоящему интеллектуальных систем. Исследования показывают, что способность объединять данные, полученные из различных источников — изображений и текста — позволяет моделям формировать более полное и контекстуально-обоснованное представление об окружающем мире. Вместо обработки каждой модальности изолированно, современные системы стремятся к выявлению сложных взаимосвязей между визуальными особенностями и языковыми конструкциями, что позволяет, например, не просто распознать объект на изображении, но и понять его роль в общей картине и описать ее с использованием естественного языка. Успех в этой области напрямую связан с развитием алгоритмов, способных эффективно интегрировать разнородные данные и извлекать из них значимые закономерности, открывая путь к созданию систем, способных к более глубокому и осмысленному взаимодействию с реальностью.
Современные подходы к анализу многомодальных моделей, таких как LLaVA, зачастую рассматривают внутренние процессы как непрозрачный “черный ящик”. Это затрудняет понимание того, как визуальная и лингвистическая информация взаимодействует друг с другом для формирования ответов. Отсутствие прозрачности не позволяет целенаправленно улучшать отдельные компоненты модели или выявлять потенциальные ошибки и предвзятости. В результате, прогресс в создании действительно интеллектуальных систем, способных к комплексному анализу и интерпретации данных, замедляется, поскольку исследователям сложно понять, какие именно факторы влияют на принятие решений моделью и как эти факторы можно оптимизировать.
Метод PID: Разложение Информации
Для количественной оценки уникальной и общей информации, вносимой каждой модальностью, был использован метод частичного разложения информации (Partial Information Decomposition, PID). PID позволяет выделить компоненты информации, специфичные для каждой модальности, а также общие компоненты, возникающие при их взаимодействии. В рамках данного подхода, информация от каждой модальности рассматривается не как единое целое, а как набор независимых переменных, что позволяет точно определить вклад каждой модальности в общее информационное содержание. Этот метод отличается от традиционных подходов, основанных на корреляции, поскольку позволяет оценить не просто взаимосвязь между модальностями, а их фактический вклад в формирование представления.
Метод PID Flow представляет собой комбинацию понижения размерности, использующую метод главных компонент (PCA), и нормализующего потока (Normalizing Flow). Это позволяет оценивать компоненты информации — уникальные и общие — в высокоразмерных нейронных представлениях. PCA применяется для начального снижения размерности данных, уменьшая вычислительную сложность. После этого, нормализующий поток, представляющий собой серию обратимых преобразований, позволяет моделировать сложное распределение данных и эффективно вычислять компоненты информации, определяемые принципами Разложения Частичной Информации (PID). Такой подход особенно важен при анализе данных, полученных из нейронных сетей, где размерность представлений может быть очень высокой.
Данный конвейер позволяет выйти за рамки простой корреляции между визуальными и лингвистическими данными, предоставляя возможность выявить причинно-следственный вклад каждого модального источника в формирующиеся нейронные представления. Вместо определения лишь статистической зависимости, метод позволяет установить, какая часть информации, закодированной в нейронной активности, уникальным образом обусловлена визуальным стимулом, а какая — лингвистическим, и какая — их совместным влиянием. Это достигается за счет использования методов разложения информации, которые отделяют общую и уникальную информацию, в отличие от традиционных подходов, основанных на корреляционном анализе, которые не позволяют сделать подобные выводы о причинности.
Динамика Информационного Потока: Модальная Трансдукция
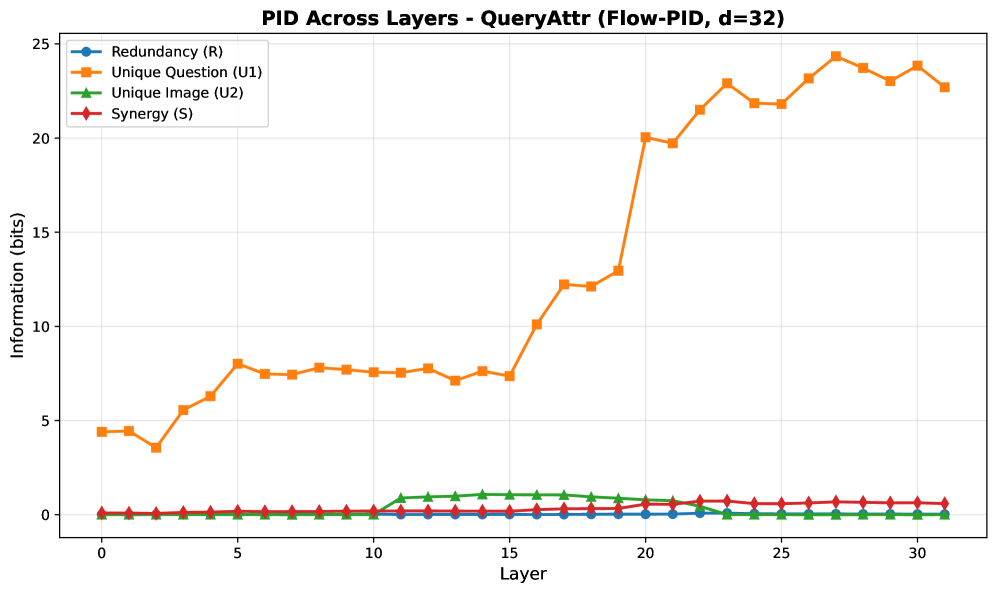
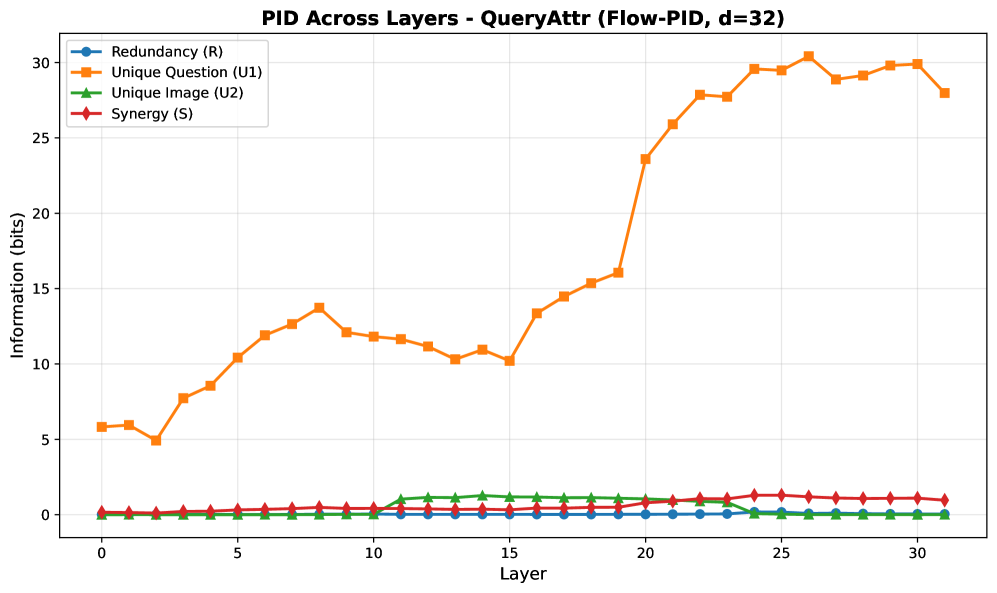
Анализ динамики распространения информации выявил закономерность, получившую название ‘Модальной Трансдукции’. Согласно полученным данным, информация, поступающая исключительно из визуального канала, демонстрирует пик активности на ранних этапах обработки и последующее быстрое затухание. В то же время, информация, поступающая исключительно из лингвистического канала, напротив, проявляет нарастающую активность с течением времени, достигая максимальных значений на более поздних этапах обработки данных. Данная динамика указывает на разную временную характеристику обработки информации, поступающей по различным модальностям.
В ходе анализа было выявлено, что синергетическая информация — данные, доступные только при одновременной обработке обоих модальностей (зрения и языка) — часто сохранялась доминирующей на протяжении всей нейронной сети, что подтверждает концепцию «Устойчивой Синергии». Это указывает на то, что модели эффективно интегрируют информацию из разных источников, а не просто суммируют отдельные вклады. В отличие от моделей, демонстрирующих доминирование избыточной информации, устойчивая синергия предполагает более эффективное использование информации, поскольку она опирается на уникальные аспекты каждой модальности в сочетании с данными, возникающими только при их взаимодействии.
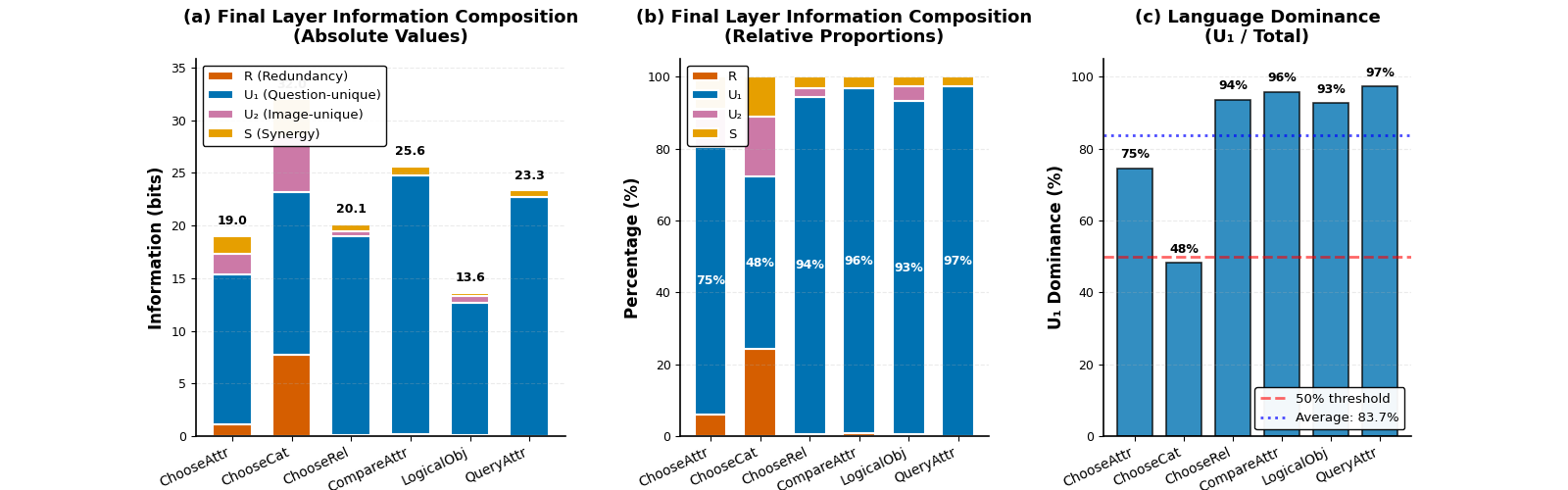
Количественный анализ продемонстрировал, что информация, уникальная для языкового канала, составляет приблизительно 82% от общего объема прогностической информации на финальном слое нейронной сети. Вклад информации, поступающей исключительно из зрительного канала, ограничен и составляет лишь около 6%. Доля синергетической информации, возникающей при комбинировании обоих каналов, остается ниже 2%. Данные показатели указывают на преобладающую роль языковой модальности в формировании прогностических представлений на заключительном этапе обработки информации.
В некоторых исследованных моделях наблюдалась тенденция к “доминирующей конвергенции избыточности”, при которой информация, общая для обеих модальностей (зрение и язык), преобладала над уникальными вкладами каждой из них. Это проявлялось в том, что большая часть информационного потока в поздних слоях сети представляла собой повторение данных, уже присутствующих в обеих входных модальностях, а не новую или специфическую информацию, предоставляемую каждой модальностью по отдельности. Такая ситуация указывает на потенциальную неэффективность архитектуры, поскольку модель фокусируется на обработке уже известной информации вместо извлечения и использования уникальных сигналов, что может ограничивать ее способность к более сложным рассуждениям и прогнозированию.
Причинно-следственные Связи: Вмешательства и Поведение Модели
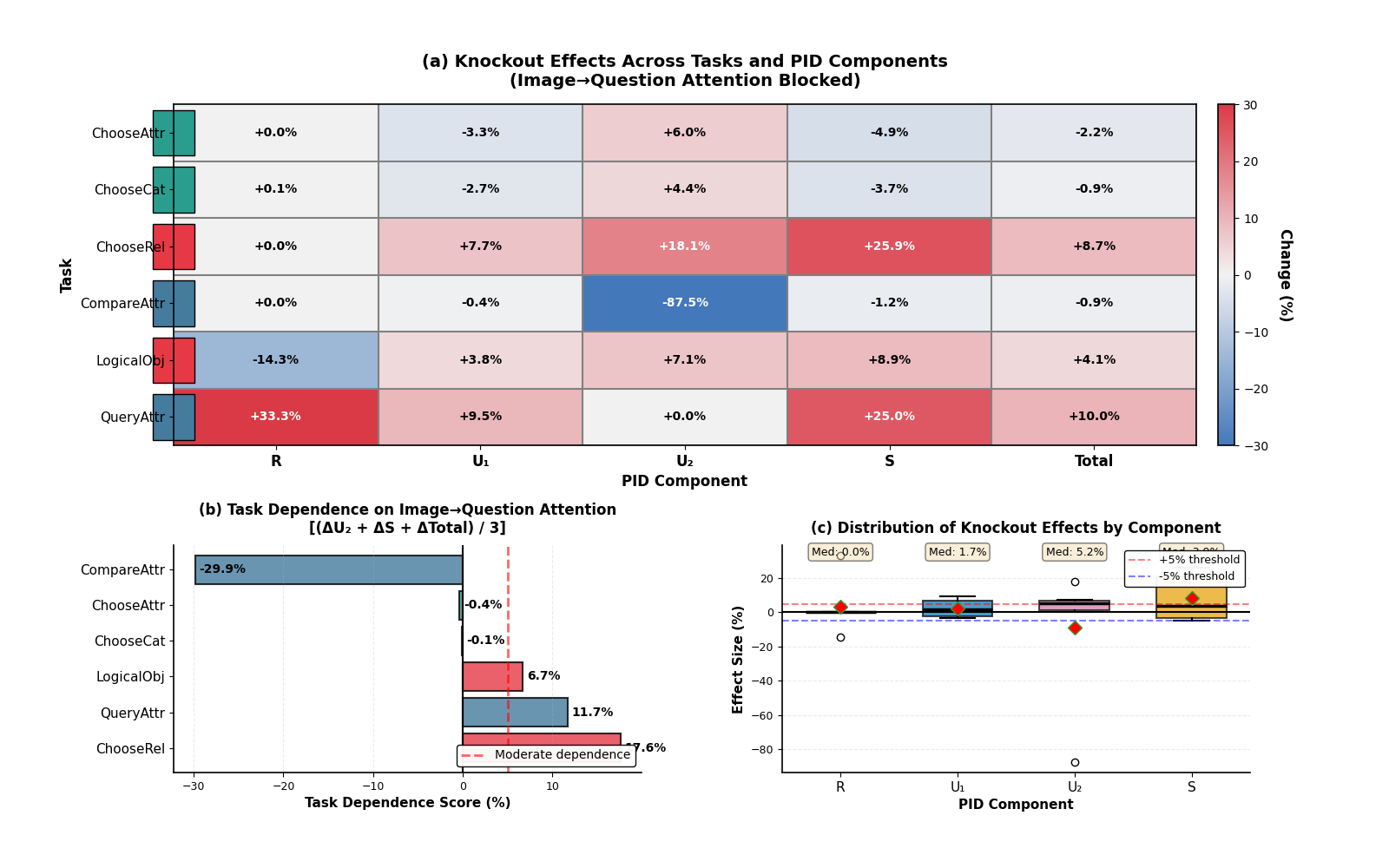
Для оценки влияния визуального ввода на ответы модели, был применен метод “Attention Knockout”, позволяющий выборочно блокировать пути внимания от изображения к вопросу. Данная интервенция заключалась в искусственном обнулении весов внимания, отвечающих за связь между визуальными признаками и последующей обработкой вопроса. Процедура проводилась на различных задачах, требующих сопоставления визуальной информации с текстовым запросом, что позволило количественно оценить вклад визуального потока в процесс генерации ответа. Результаты анализа показали, что блокировка указанных путей внимания приводит к существенному снижению производительности модели в определенных сценариях.
Экспериментальное блокирование путей внимания от изображения к вопросу (“Attention Knockout”) привело к значительному снижению производительности модели на определенных задачах визуального вопрошания. В частности, наблюдалось ухудшение ответов на вопросы, требующие анализа визуальной информации, подтверждая, что визуальный ввод является критически важным для корректной работы модели. Уменьшение производительности после вмешательства указывает на то, что эти пути внимания не просто коррелируют с успехом, а непосредственно влияют на способность модели отвечать на вопросы, основанные на визуальном контенте.
Полученные результаты позволяют предположить, что наблюдаемые паттерны потока информации в модели не являются просто корреляционными, а отражают лежащие в основе причинно-следственные механизмы. Вместо пассивного отражения статистических связей между входными данными и выходными ответами, модель демонстрирует способность к активному использованию визуальной информации для формирования ответов на вопросы. Это подтверждается тем, что целенаправленное нарушение определенных путей передачи информации (например, через ‘Attention Knockout’) приводит к предсказуемому снижению производительности, что указывает на то, что эти пути играют функционально значимую роль в процессе принятия решений моделью, а не являются просто сопутствующими статистическими особенностями.
Влияние на Будущее Мультимодального Искусственного Интеллекта
Понимание взаимодействия визуальной и лингвистической информации является ключевым фактором в создании действительно интеллектуальных мультимодальных систем. Исследования показывают, что способность эффективно объединять и интерпретировать данные, поступающие из различных источников, таких как изображения и текст, позволяет моделям достигать более высокого уровня понимания и рассуждения. Вместо обработки каждого типа данных изолированно, современные системы стремятся к синергии, когда визуальные и лингвистические компоненты дополняют и усиливают друг друга. Этот процесс требует не просто сопоставления данных, но и глубокого анализа взаимосвязей, позволяющего моделям извлекать более полную и контекстуально релевантную информацию, что, в конечном итоге, приближает их к человеческому уровню восприятия и понимания окружающего мира.
Исследование подчеркивает критическую важность синергетической информации при создании интеллектуальных мультимодальных систем. Полученные результаты демонстрируют, что эффективность таких систем напрямую зависит от способности архитектуры максимизировать взаимодействие между различными модальностями данных, например, визуальной и лингвистической. В частности, модели, спроектированные с акцентом на усиление этого синергетического эффекта, показывают значительно более высокие результаты в задачах, требующих комплексной обработки информации. Таким образом, разработка архитектур, способных эффективно интегрировать и использовать взаимодополняющие данные из различных источников, представляется ключевым направлением для дальнейшего развития мультимодального искусственного интеллекта.
Перспективные исследования в области мультимодального искусственного интеллекта должны быть направлены на разработку методов, позволяющих целенаправленно управлять потоком синергетической информации внутри моделей. Вместо пассивного наблюдения за взаимодействием визуальных и лингвистических данных, необходимо создавать архитектуры, активно формирующие и усиливающие взаимосвязь между модальностями. Это предполагает разработку новых механизмов внимания, позволяющих моделям динамически определять, какая информация из каждой модальности наиболее важна для формирования целостного понимания, а также способы эффективной интеграции этой информации на различных уровнях обработки. Подобный подход позволит создавать системы, демонстрирующие не просто совместное использование различных типов данных, а истинное синергетическое взаимодействие, приводящее к качественно новому уровню понимания и генерации информации.
Исследование продемонстрировало удивительную согласованность между моделями LLaVA-1.5 и LLaVA-1.6. Высокие коэффициенты корреляции Пирсона, превышающие 0.98 для ряда компонентов PID (Process Information Distribution), указывают на то, что обе модели обрабатывают визуальную и лингвистическую информацию схожим образом. Особенно примечательно, что точки перегиба в процессе трансдукции модальностей (перехода между визуальным и текстовым представлением) обнаруживаются в пределах одного слоя нейронной сети. Это свидетельствует о том, что ключевые механизмы синергии между модальностями реализованы очень локализованно и стабильно в архитектуре LLaVA, что позволяет предположить высокую эффективность и надежность данной структуры для мультимодального анализа.
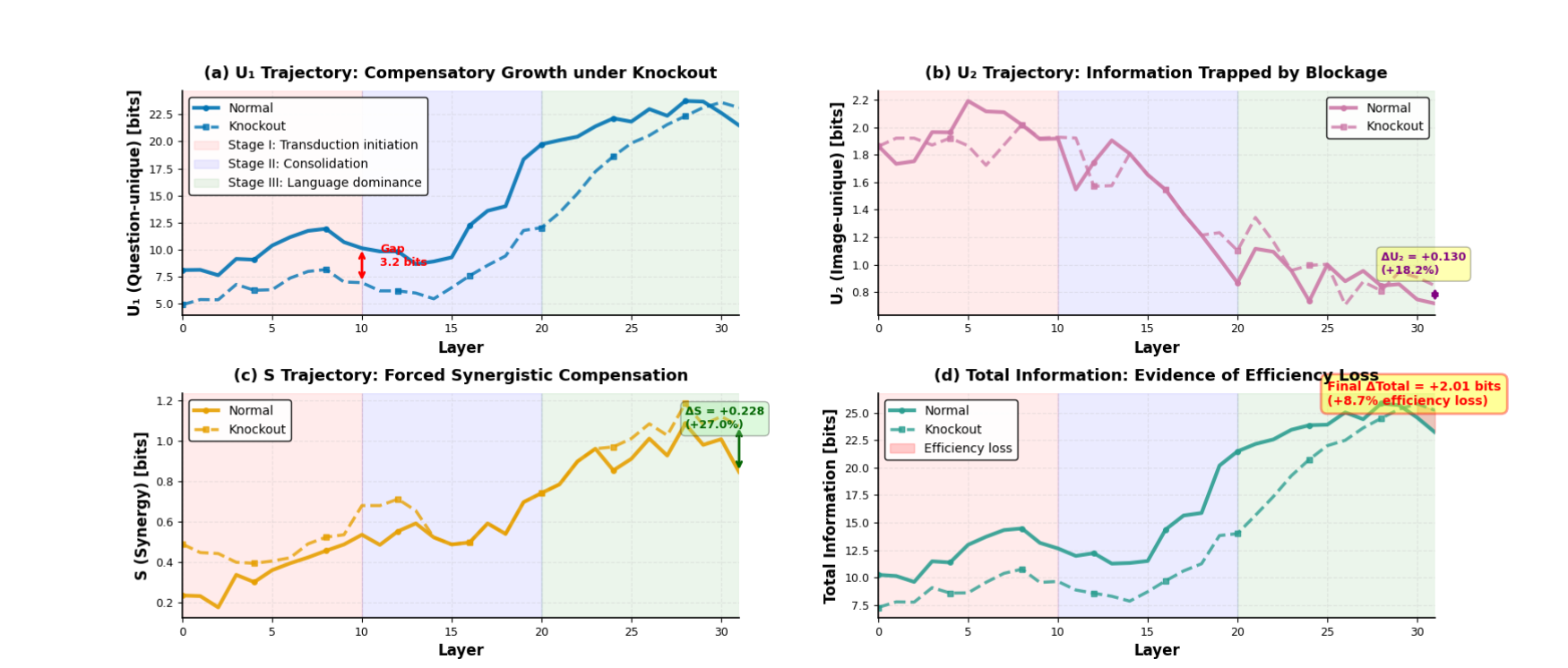
Исследование демонстрирует, что визуальная информация в мультимодальных больших языковых моделях не просто суммируется с лингвистической, а преобразуется и абсорбируется ею. Этот процесс, названный ‘модальной трансдукцией’, подчеркивает не слияние, а глубокое взаимодействие между модальностями. Как говорил Дональд Кнут: «Прежде чем оптимизировать код, убедитесь, что он работает». Аналогично, прежде чем говорить о слиянии информации, необходимо понять механизм ее трансформации. Понимание этого процесса — ключевой шаг к интерпретируемости и созданию действительно разумных систем, где каждый элемент вносит четкий и осознанный вклад в общее понимание.
Что дальше?
Представленный анализ, хотя и проливает свет на процесс ‘модальной трансдукции’ в больших мультимодальных языковых моделях, лишь обнажает сложность задачи. Утверждение о том, что визуальная информация поглощается языковым представлением, а не сливается с ним, не является окончательным. Скорее, это приглашение к более глубокому исследованию: что именно ‘теряется’ при этом поглощении? Какие нюансы визуального мира оказываются непереводимыми на язык, и имеет ли эта ‘потеря’ значение для конечной задачи?
Истинное понимание требует не просто отслеживания потока информации, но и оценки её трансформации. Методы частичного разложения информации, безусловно, полезны, но они не способны уловить тонкие изменения в семантическом пространстве. Необходимо разрабатывать инструменты, позволяющие оценивать не только ‘сколько’ информации передается, но и ‘как’ она изменяется в процессе передачи. Система, требующая подробных инструкций для интерпретации результатов, уже проиграла.
Будущие исследования должны сместить акцент с простого обнаружения корреляций между модальностями на построение причинно-следственных моделей. Понимание того, какие визуальные признаки действительно влияют на языковое представление, а какие являются лишь случайным шумом, — вот что действительно имеет значение. Понятность — это вежливость, и в стремлении к искусственному интеллекту, вежливость эта должна быть направлена не только к пользователю, но и к самой природе знания.
Оригинал статьи: https://arxiv.org/pdf/2602.15580.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Неважно, на что вы фотографируете!
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Лучшие смартфоны. Что купить в апреле 2026.
- Что такое ISO в фотоаппарате
- Технологии и вера: новый взгляд на инклюзивный дизайн
- Рекомендации нового поколения: объединяя визуальное и текстовое
- Infinix Note 40 Pro+ выставлен на обзор
2026-02-18 22:31