Автор: Денис Аветисян
Исследователи представили новый подход к навигации, позволяющий агентам самостоятельно прокладывать путь от открытого пространства до конечной точки внутри помещения, опираясь исключительно на визуальную информацию и текстовые указания.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Работа посвящена задаче и фреймворку для навигации в условиях перехода из внешней среды во внутреннюю, с использованием синтеза видео на основе траекторий и масштабного нового набора данных.
Несмотря на значительный прогресс в области воплощенной навигации, большинство существующих подходов ограничено либо внутренней, либо внешней средой, и часто требует доступа к точным координатным системам. В данной работе, озаглавленной ‘Bridging the Indoor-Outdoor Gap: Vision-Centric Instruction-Guided Embodied Navigation for the Last Meters’, предложена новая задача и фреймворк для навигации извне внутрь без использования предварительных знаний, позволяющая агентам ориентироваться в помещениях, используя только визуальные данные и инструкции. Ключевым вкладом является разработка визуально-ориентированной системы навигации и сопутствующего крупномасштабного набора данных, сгенерированного с применением синтеза видео, зависящего от траектории. Какие перспективы открывает предложенный подход для создания более гибких и автономных систем навигации в реальных условиях?
Навигация в Реальном Мире: Вызов Воплощенного Искусственного Интеллекта
Традиционные системы автономной навигации, используемые в робототехнике и беспилотных транспортных средствах, часто опираются на заранее созданные карты и сигналы глобальной системы позиционирования (GPS). Однако, эта зависимость существенно ограничивает их эффективность в реальных, динамично меняющихся условиях. Например, в городской среде, где GPS-сигнал может быть заблокирован зданиями или подвержен помехам, а карты быстро устаревают из-за строительства и ремонтных работ, такие системы демонстрируют значительные затруднения. Более того, полагаясь на статические карты, они не способны эффективно реагировать на неожиданные препятствия, такие как временно припаркованные автомобили или пешеходы, что делает их непригодными для полноценной работы в сложных и непредсказуемых ситуациях реального мира. Разработка методов навигации, не требующих предварительной информации об окружающей среде, становится ключевой задачей для создания действительно автономных и адаптивных систем.
Переход между открытыми и закрытыми пространствами, так называемая «out-to-in» навигация, представляет собой сложную проблему для искусственного интеллекта. В отличие от навигации в контролируемых средах или при использовании предварительно созданных карт, переход из внешней среды, где доступен сигнал GPS и широкие ориентиры, во внутреннее пространство, где эти возможности ограничены или отсутствуют, требует от агента принципиально иного подхода. Необходимо учитывать резкие изменения в визуальной информации, отсутствие глобальной системы координат и необходимость полагаться на локальные сенсорные данные для построения карты окружающего пространства и планирования маршрута. Успешная реализация такой навигации требует от ИИ-агентов способности к адаптации, обучению в режиме реального времени и эффективной интеграции различных сенсорных модальностей, что делает ее важным этапом на пути к созданию действительно автономных и универсальных роботов.
В условиях возрастающей потребности в надежных и адаптируемых системах навигации, всё большее внимание привлекают методы, не требующие предварительных знаний об окружающей среде. Традиционные подходы, полагающиеся на заранее созданные карты и GPS-координаты, оказываются уязвимыми в динамичных, непредсказуемых условиях реального мира. Поэтому развивается направление так называемой “навигации без априорных знаний” — принципиально новый подход, где искусственный интеллект самостоятельно осваивает пространство, ориентируясь исключительно на текущие сенсорные данные. Такие системы способны к самообучению и адаптации к изменяющейся обстановке, что делает их особенно перспективными для применения в робототехнике, автономном транспорте и других областях, где требуется надежная и гибкая навигация в сложных условиях.
BridgeNavDataset: Основа для Исследований Воплощенной Навигации
Набор данных BridgeNavDataset представляет собой крупномасштабную, реалистичную среду, предназначенную для обучения и оценки агентов, выполняющих воплощенную навигацию. Он включает в себя более 5000 уникальных траекторий, охватывающих разнообразные внутренние пространства, смоделированные с использованием высококачественных текстур и реалистичного освещения. Размер набора данных превышает 200 часов видео, что позволяет проводить обучение и валидацию сложных алгоритмов навигации. Реалистичность среды обеспечивается использованием детализированных 3D-моделей и физически корректного рендеринга, что позволяет агентам приобретать навыки, применимые к реальным условиям.
Набор данных BridgeNavDataset использует метод генерации видео, обусловленный траекторией, для создания разнообразных визуальных сценариев, основанных на запланированных маршрутах. Этот процесс позволяет агентам воспринимать различные визуальные изменения, возникающие в процессе навигации, и повышает их способность предвидеть будущие изменения в окружающей среде. Генерация видео осуществляется на основе заданных траекторий, что позволяет создавать реалистичные последовательности изображений, отражающие динамику движения агента и изменения в визуальном окружении. Такой подход позволяет тренировать агентов в условиях, максимально приближенных к реальным, и улучшает их способность к адаптации и эффективной навигации в сложных средах.
Процесс генерации видео в BridgeNavDataset опирается на алгоритм A для планирования траекторий, обеспечивая создание эталонных путей движения. A используется для определения оптимального маршрута между начальной и конечной точками в виртуальной среде. Для рендеринга глобальных признаков в виде облаков точек применяется MoGe-v2, что позволяет агентам ориентироваться в пространстве и воспринимать окружение, используя информацию о геометрии и структуре сцены. Комбинация A* и MoGe-v2 обеспечивает создание реалистичных и информативных визуальных данных для обучения и оценки агентов автономной навигации.
Набор данных BridgeNavDataset ориентирован на задачу навигации без предварительных знаний об окружающей среде, что представляет собой значительный шаг вперед в области автономных исследований. В отличие от существующих наборов данных, часто полагающихся на предварительно созданные карты или семантические аннотации, BridgeNavDataset требует от агентов самостоятельного изучения и построения представления об окружении исключительно на основе визуальных данных и данных датчиков. Это позволяет оценить и развить способности агентов к адаптации и обобщению в неизвестных и динамичных средах, приближая их к реальным условиям эксплуатации и расширяя возможности автономной навигации в сложных сценариях.
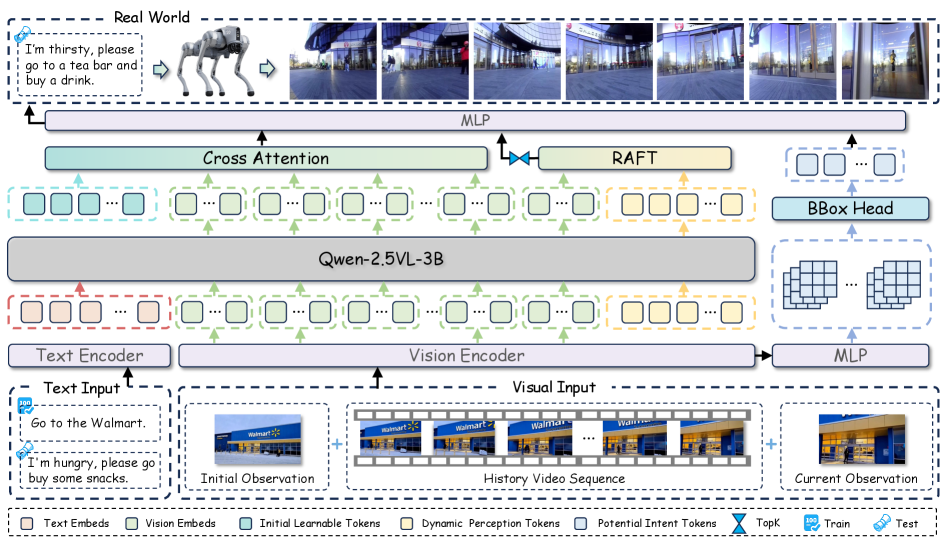
BridgeNav: Архитектура для Навигации без Априорных Знаний
BridgeNav представляет собой новую структуру навигации, разработанную по принципу “извне внутрь”, где визуальная информация является ключевым элементом управления агентом. В отличие от традиционных подходов, ориентированных на построение глобальной карты или планирование траектории, BridgeNav фокусируется на непосредственной интерпретации визуальных данных для определения следующего шага. Это позволяет агенту ориентироваться в неизвестных средах, не требуя предварительного картирования или знания о структуре помещения. Навигация осуществляется путем анализа изображений, поступающих от сенсоров, и использования извлеченных визуальных признаков для принятия решений о перемещении.
В основе BridgeNav лежит использование Vision Transformer (ViT) для кодирования визуальной информации. ViT разбивает входное изображение на последовательность патчей, которые затем обрабатываются как токены, аналогично обработке текста в моделях обработки естественного языка. Это позволяет извлекать иерархические признаки из изображения, улавливая как локальные детали, так и глобальный контекст. Полученные признаки служат входными данными для последующих модулей навигационной системы, обеспечивая эффективное представление визуальной среды для планирования маршрута и принятия решений.
Модуль латентного намерения (Latent Intention Module) в BridgeNav предназначен для динамической фокусировки внимания на релевантных областях изображения в процессе навигации. Он анализирует визуальные данные, определяя наиболее значимые регионы, соответствующие текущей инструкции и целям агента. Этот механизм позволяет системе эффективно отфильтровывать несущественную информацию и концентрироваться на ключевых визуальных подсказках, необходимых для успешной навигации. В отличие от подходов, обрабатывающих изображение целиком, модуль латентного намерения позволяет снизить вычислительную нагрузку и повысить точность определения оптимального маршрута, акцентируя внимание на областях, непосредственно связанных с заданным направлением движения.
В основе понимания инструкций в BridgeNav лежит мощная мультимодальная большая языковая модель Qwen2.5-VL-3B. В ходе тестирования, использование данной модели позволило достичь показателя успешности в 80.1% на дистанции 0.1 метра. Данный результат значительно превосходит показатели, демонстрируемые существующими методами навигации, в частности, системой OmniNav. Эффективность Qwen2.5-VL-3B обусловлена её способностью к комплексному анализу визуальной информации и текстовых инструкций, что обеспечивает более точное и надежное выполнение задач навигации.

Предвосхищение Окружающего Мира: Динамическое Восприятие с Оптическим Потоком
В основе системы BridgeNav лежит модуль динамического восприятия, использующий оптический поток для прогнозирования будущих визуальных наблюдений, основываясь на движении агента. Этот подход позволяет не просто реагировать на текущую обстановку, но и предвидеть изменения в окружающей среде, что критически важно для эффективной навигации. Оценивая смещение пикселей на последовательных изображениях — то есть, оптический поток — система выстраивает модель будущего визуального поля, позволяя агенту заблаговременно планировать свои действия и избегать потенциальных препятствий. Такая проактивная стратегия существенно повышает надежность и скорость перемещения в динамичных условиях, открывая новые возможности для создания автономных систем, способных к адаптации и эффективному взаимодействию с реальным миром.
Для оценки оптического потока, необходимого для предсказания будущих визуальных наблюдений, система BridgeNav использует алгоритм RAFT — высокоэффективное решение, позволяющее с минимальными вычислительными затратами определять смещения пикселей между последовательными кадрами. RAFT отличается легкостью и скоростью работы, что критически важно для приложений реального времени, таких как автономная навигация. Этот алгоритм позволяет агенту быстро и точно оценивать движение объектов в окружающей среде, создавая карту оптического потока, которая служит основой для предсказания будущих визуальных изменений и, как следствие, повышения эффективности навигации в динамичных условиях.
Агент BridgeNav демонстрирует повышенную эффективность навигации в динамических средах благодаря способности предвидеть изменения визуальной картины. Используя информацию об оптическом потоке, система способна прогнозировать будущие наблюдения, что позволяет оперативно реагировать на возникающие препятствия и перемещающиеся объекты. В результате, агент не просто адаптируется к изменениям, но и предвосхищает их, что приводит к значительному улучшению общей эффективности навигации — на 31.0% по сравнению с системой OmniNav. Такая проактивная стратегия позволяет агенту более плавно и быстро преодолевать сложные маршруты, повышая его автономность и применимость в реальных условиях.
Разработанная система демонстрирует значительный прогресс в создании по-настоящему автономных агентов, способных ориентироваться в реальном мире. Достигнутая успешность навигации, достигающая 49.2% на расстоянии 0.2 метра и 23.7% на 0.3 метра, подтверждает эффективность подхода к предсказанию изменений в окружающей среде. Этот результат свидетельствует о потенциале технологии для использования в широком спектре приложений, требующих надежной и адаптивной навигации в динамичных условиях, и открывает новые возможности для развития робототехники и автономных систем.

Исследование, представленное в данной работе, подчеркивает важность создания агентов, способных к автономной навигации в сложных, ранее неизвестных средах. Подобный подход требует от алгоритма не просто «работать на тестах», но и демонстрировать устойчивость к изменениям и неопределенности. Как заметил Эндрю Ын: «Искусственный интеллект — это не просто создание умных машин, а понимание фундаментальных принципов обучения». Пусть N стремится к бесконечности — что останется устойчивым? В данном контексте, устойчивость заключается в способности агента обобщать знания, полученные из данных, и применять их к новым ситуациям, преодолевая разрыв между внешним и внутренним пространством, что особенно важно для задач, связанных с визуальной навигацией и следованием инструкциям. Создание таких систем требует математической чистоты и доказательства корректности алгоритмов.
Куда же дальше?
Представленная работа, безусловно, демонстрирует определенный прогресс в области воплощенной навигации. Однако, не стоит забывать о фундаментальной проблеме: способность агента ориентироваться в незнакомой среде, опираясь исключительно на визуальные данные и лингвистические инструкции, остается хрупкой. Воспроизведение «естественного» поведения — это лишь иллюзия, пока алгоритм не способен доказать свою устойчивость к малейшим отклонениям в входных данных. Простота генерации данных, хоть и впечатляет, не гарантирует их репрезентативности и не избавляет от необходимости критического анализа.
Настоящим вызовом представляется не столько увеличение масштаба наборов данных или усложнение архитектур моделей, сколько разработка формальных методов верификации. Необходимо создать алгоритмы, которые не просто «работают на тестах», но и обладают математически доказуемой корректностью. Иначе, мы рискуем построить впечатляющую, но в конечном итоге ненадежную систему. Особенно остро стоит вопрос о генерализации — насколько хорошо агент сможет адаптироваться к условиям, принципиально отличающимся от тех, на которых он обучался?
Будущие исследования должны сосредоточиться на интеграции формальной логики и вероятностных моделей. Необходимо стремиться к созданию алгоритмов, которые способны не только предсказывать траектории, но и обосновывать свои решения. В конечном счете, истинный прогресс в области воплощенной навигации будет достигнут лишь тогда, когда мы сможем построить системы, которые не просто имитируют разум, но и обладают им.
Оригинал статьи: https://arxiv.org/pdf/2602.06427.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Макросъемка
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Российский рынок: между ставкой ЦБ, геополитикой и отчетами компаний (25.03.2026 17:32)
- От фотографий к фильмам: полное руководство по переходу на видеосъемку
- Три простых изменения в светлой комнате, чтобы создать свой объект съемки.
- Motorola Edge 30 Pro ОБЗОР: скоростная съёмка видео, скоростная зарядка, беспроводная зарядка
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
2026-02-09 11:15