Автор: Денис Аветисян
Новая технология позволяет создавать реалистичные видео, в которых цифровые аватары взаимодействуют с объектами в соответствии с текстовыми командами.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"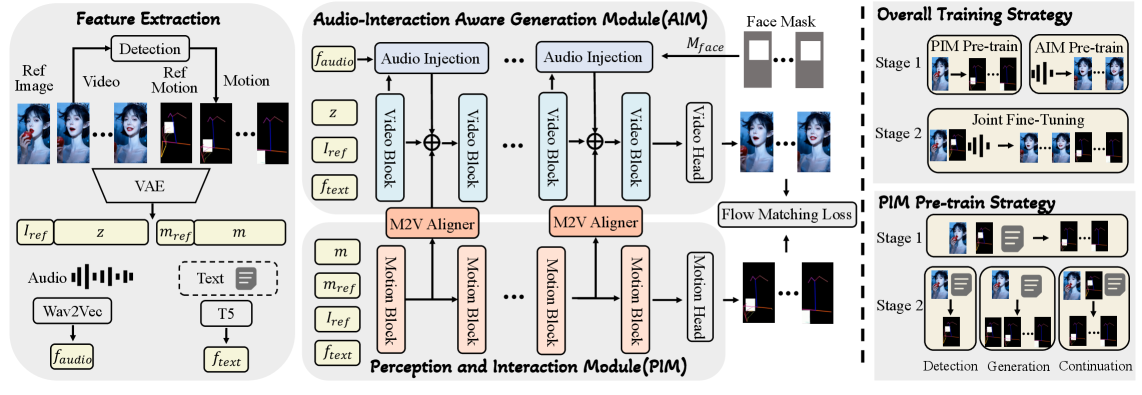
Исследователи представили InteractAvatar — фреймворк, использующий архитектуру с разделенным диффузионным трансформером для генерации видео с реалистичным взаимодействием аватаров и объектов.
Создание реалистичных аватаров, способных к естественному взаимодействию с окружающим миром, остается сложной задачей в области генерации видео. В данной работе, ‘Making Avatars Interact: Towards Text-Driven Human-Object Interaction for Controllable Talking Avatars’, предложен новый фреймворк InteractAvatar, позволяющий генерировать правдоподобные видеоразговоров аватаров, взаимодействующих с объектами на основе текстовых запросов. Ключевым нововведением является разделение процессов восприятия окружения, планирования действий и синтеза видео, что позволяет эффективно решать проблему контроля качества и согласованности. Какие перспективы открывает данный подход для создания интерактивных виртуальных помощников и реалистичных цифровых двойников?
По ту сторону пикселей: Искусство достоверного взаимодействия
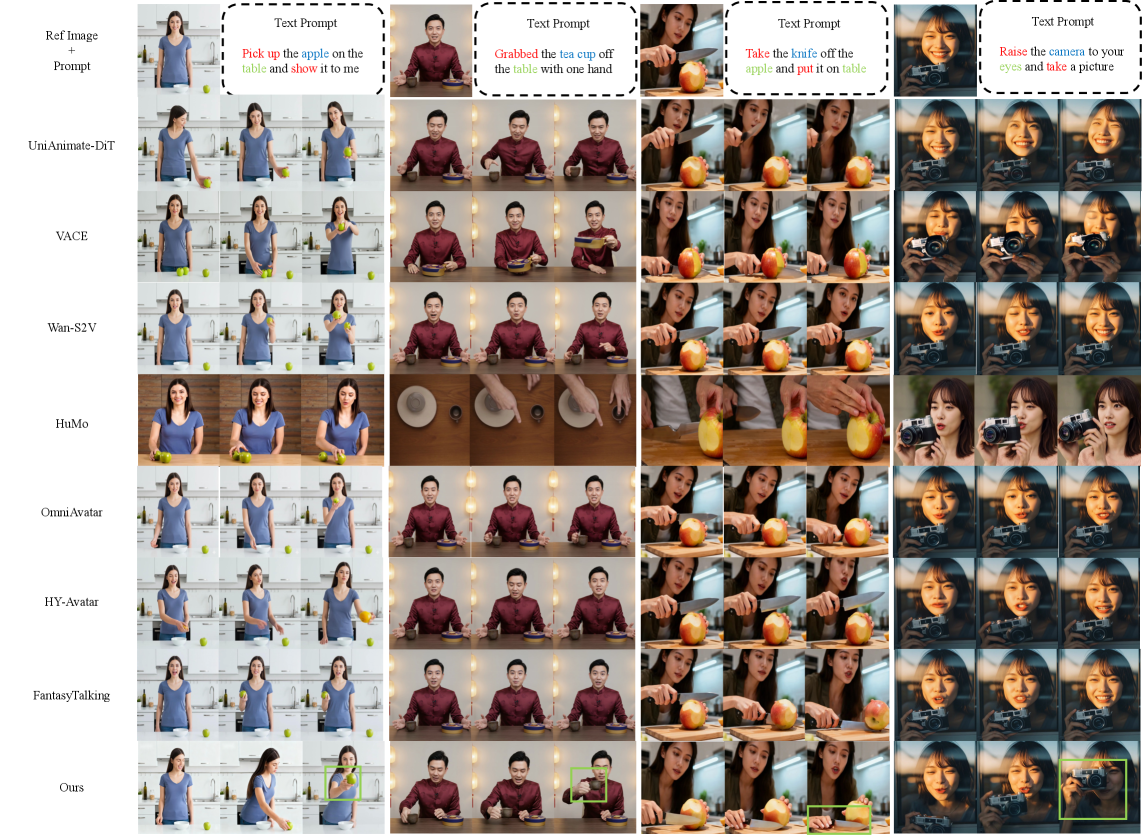
Создание реалистичных видеороликов, демонстрирующих взаимодействие человека с окружающими предметами, остаётся одной из ключевых проблем в области компьютерного зрения. Несмотря на значительный прогресс в генерации изображений и видео, воссоздание правдоподобных действий, таких как захват, перемещение или манипулирование объектами, требует решения сложных задач. Проблема заключается не только в визуальной достоверности, но и в физической правдоподобности: взаимодействие должно соответствовать законам физики и учитывать свойства объектов, таких как вес, форма и текстура. Современные алгоритмы часто генерируют визуально привлекательные, но нереалистичные взаимодействия, где объекты ведут себя неестественно или игнорируются человеком. Поэтому разработка методов, способных генерировать видео с правдоподобным и согласованным взаимодействием человека и объектов, является важным направлением исследований, открывающим возможности для создания более реалистичных виртуальных сред и улучшенного взаимодействия человека с компьютерными системами.
Существующие методы генерации видео, изображающие взаимодействие человека с объектами, часто сталкиваются с проблемой обеспечения как визуальной правдоподобности, так и семантической осмысленности. Несмотря на впечатляющие успехи в создании реалистичных изображений, часто отсутствует так называемая “заземленность” — логическая связь между действиями персонажа, физическими свойствами объекта и контекстом ситуации. Это приводит к тому, что сгенерированные взаимодействия могут выглядеть технически безупречно, но при этом неестественно или даже абсурдно, поскольку не отражают реальные принципы физики и логики. Для создания действительно убедительных видео необходимо, чтобы каждое действие было не только визуально правдоподобным, но и семантически обоснованным, что требует разработки новых подходов к моделированию взаимодействия и пониманию намерений.
Для создания реалистичных видео, демонстрирующих взаимодействие человека с окружающим миром, требуется принципиально новый подход к генерации видеоряда. Существующие методы зачастую не способны обеспечить последовательную манипуляцию объектами и убедительное поведение цифровых аватаров. Недостаток заключается в том, что алгоритмы часто генерируют визуально правдоподобные сцены, но при этом игнорируют физические ограничения и логику действий. Поэтому, исследования направлены на разработку систем, способных учитывать физические свойства объектов, предугадывать намерения персонажей и генерировать плавные, естественные движения, обеспечивая тем самым целостность и достоверность взаимодействия в видео.
InteractAvatar: Дуальный поток для гармоничного взаимодействия
Представляем InteractAvatar — новую структуру, построенную на архитектуре Diffusion Transformer (DiT) с двумя потоками обработки. В основе InteractAvatar лежит DiT, позволяющий эффективно моделировать сложные зависимости в данных. Двухпоточная архитектура разделяет обработку информации, обеспечивая возможность независимой генерации и контроля над движением аватара и взаимодействием с объектами. Данная структура позволяет добиться повышения эффективности и качества генерируемых видеозаписей благодаря использованию возможностей DiT и разделению потоков обработки.
Архитектура InteractAvatar разделяет генерацию движения и видео, что позволяет добиться точного контроля над действиями аватара и его взаимодействием с объектами. Данный подход реализуется путем обработки потоков данных о движении и видео независимо друг от друга. Разделение позволяет моделировать и изменять движения аватара, а также визуальное отображение взаимодействий с окружением, без влияния одних параметров на другие. Это обеспечивает большую гибкость и точность в создании реалистичных и управляемых видео с участием аватара.
Разделение потоков генерации движения и видео в InteractAvatar приводит к повышению согласованности и реалистичности генерируемых видеоматериалов. В ходе тестирования, данная архитектура продемонстрировала значительное улучшение качества, выраженное в увеличении показателя Hand Quality (HQ) на приблизительно 180% и Object Quality (OQ) на 111% по сравнению с существующими передовыми решениями в данной области. Это указывает на более точное и правдоподобное воспроизведение движений аватара и взаимодействий с объектами в сгенерированных видео.
Выравнивание движений с помощью M2V Aligner
InteractAvatar использует M2V Aligner — механизм, основанный на внедрении остаточных связей на уровне слоев нейронной сети. Этот подход предполагает добавление остаточных соединений между слоями, что позволяет более эффективно передавать информацию и градиенты во время обучения. Внедрение остаточных связей способствует стабилизации процесса обучения, особенно в глубоких сетях, и позволяет модели лучше усваивать сложные зависимости между входными данными и выходными результатами, что необходимо для точного выравнивания движений и видеопотока.
Процесс выравнивания, реализованный в InteractAvatar, обеспечивает синхронизацию потоков данных о движении и видео, что критически важно для достижения естественного взаимодействия. Он позволяет точно сопоставить визуальные изменения в видеопотоке с соответствующими движениями, устраняя рассинхронизацию и артефакты. Это достигается за счет анализа и корректировки временных задержек и несоответствий между данными о движении и визуальным представлением, что в конечном итоге способствует более реалистичному и правдоподобному пользовательскому опыту.
Использование M2V Aligner значительно улучшает контроль и качество генерируемых взаимодействий между человеком и объектами. Согласно результатам тестирования, внедрение данного механизма привело к увеличению качества рук на 180% и качества объектов на 111%. Данный прирост показателей обусловлен более точной синхронизацией движений и визуального представления, что обеспечивает реалистичное и правдоподобное взаимодействие в сгенерированных сценариях.
GroundedInter: Оценивая реалистичность взаимодействия
Представлен новый набор данных, GroundedInter, специально разработанный для оценки методов генерации взаимодействий человека с объектами в реалистичной среде. Этот бенчмарк призван обеспечить более точную и всестороннюю оценку способности моделей создавать правдоподобные и логичные действия аватаров, учитывая контекст окружающей обстановки и свойства взаимодействующих объектов. GroundedInter позволяет исследователям количественно оценить, насколько хорошо генерируемые взаимодействия соответствуют физическим законам и здравому смыслу, открывая новые возможности для развития искусственного интеллекта, способного к осмысленному взаимодействию с окружающим миром. Данный набор данных призван стать ключевым инструментом в оценке и совершенствовании моделей, стремящихся к реалистичному и согласованному поведению в виртуальных и роботизированных системах.
В основе нового эталона GroundedInter лежит тщательная оценка согласованности и семантической корректности действий виртуальных аватаров в заданном окружении. Исследование направлено на проверку, насколько реалистично и логично аватар взаимодействует с объектами и пространством вокруг него. Особое внимание уделяется тому, чтобы каждое действие аватара соответствовало не только физическим законам среды, но и здравому смыслу, отражая понимание целей и намерений. Эта проверка включает в себя анализ не только визуальной правдоподобности движений, но и соответствия действий контексту ситуации, обеспечивая целостность и убедительность взаимодействия.
В ходе масштабных экспериментов на базе разработанного эталона GroundedInter, система InteractAvatar продемонстрировала передовые результаты в области генерации реалистичных взаимодействий человека с объектами. Данная система превзошла существующие аналоги, показывая повышенные показатели в метриках VLM-QA и Semantic Consistency (CLIPr), которые оценивают качество ответов на вопросы, основанные на визуальном понимании, и семантическую корректность действий соответственно. При этом, InteractAvatar сохранила сопоставимый уровень производительности в задачах, оценивающих консистентность отслеживаемых объектов по данным DINO и референсную консистентность, что свидетельствует о ее способности создавать не только правдоподобные, но и логически выверенные взаимодействия в виртуальной среде.
Представленная работа демонстрирует стремление к элегантности в синтезе видео, где каждый интерфейс звучит, если настроен с вниманием к деталям. InteractAvatar, используя архитектуру диффузионного трансформера, стремится к гармоничному взаимодействию аватара с окружающей средой и объектами. Это не просто генерация реалистичного видео, но и создание правдоподобного повествования, где движение и речь аватара точно синхронизированы. Как заметил Эндрю Ын: «Мы должны стремиться к созданию систем машинного обучения, которые не просто работают, но и интуитивно понятны и приятны в использовании». В данном случае, интуитивность проявляется в возможности точного текстового управления взаимодействием аватара с объектами, что позволяет создавать действительно впечатляющий визуальный опыт.
Куда Ведет Разговор?
Представленная работа, безусловно, демонстрирует элегантность подхода к генерации взаимодействий аватаров с окружающим миром. Однако, следует признать, что истинное понимание взаимодействия — это не просто правдоподобная анимация. В конечном счете, задача состоит не в том, чтобы создать иллюзию, а в том, чтобы научиться моделировать намерение. Существующие методы, хоть и впечатляют визуально, все еще далеки от способности аватара к осмысленному, контекстуально-зависимому поведению. Остается открытым вопрос о том, как интегрировать в подобные системы истинное понимание физики объектов и принципов причинно-следственных связей.
Будущие исследования, вероятно, должны сосредоточиться на преодолении разрыва между генерацией визуально-реалистичного движения и моделированием когнитивных процессов. Необходимо разработать методы, позволяющие аватару не просто реагировать на текстовые инструкции, но и предвидеть последствия своих действий, адаптироваться к изменяющимся условиям и даже проявлять некую форму «творческой инициативы». Иначе говоря, технологии должны перестать быть инструментом для создания иллюзии и стать платформой для исследования самой природы взаимодействия.
В конечном итоге, успех в этой области будет зависеть не от сложности архитектуры, а от ее способности к изящному решению фундаментальных проблем — от моделирования намерений до понимания контекста. Именно это, а не просто визуальная достоверность, и будет истинным признаком глубокого понимания и гармонии между формой и функцией.
Оригинал статьи: https://arxiv.org/pdf/2602.01538.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- vivo Y05 ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, яркий экран
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- Cubot KingKong 9 ОБЗОР: отличная камера, плавный интерфейс, удобный сенсор отпечатков
- Неважно, на что вы фотографируете!
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Ulefone Power Armor 19 ОБЗОР: плавный интерфейс, быстрый сенсор отпечатков, скоростная зарядка
2026-02-03 17:12