Автор: Денис Аветисян
Новая архитектура DreamID-Omni позволяет бесшовно генерировать, редактировать и анимировать аудио-видео контент, ориентированный на конкретных людей и их уникальные характеристики.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"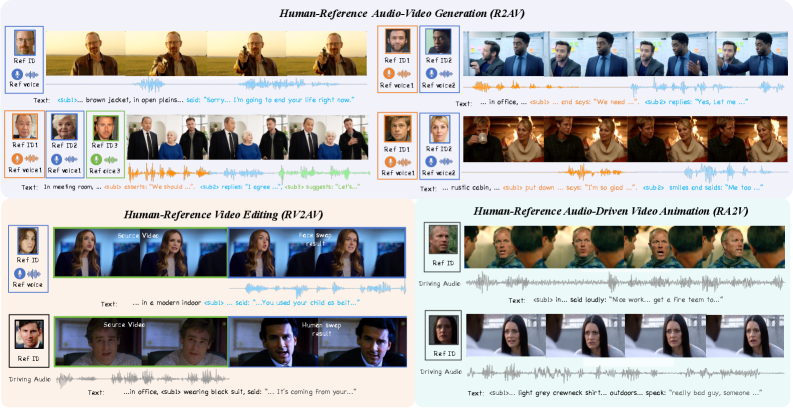
Представлен унифицированный фреймворк DreamID-Omni, использующий симметричный условный диффузионный трансформер для управления генерацией аудио-видео, обеспечивающий согласованность идентичности и эффективно работающий в многопользовательских сценариях.
Несмотря на значительный прогресс в генерации аудио- и видеоконтента, объединение различных задач, таких как референсно-зависимая генерация, редактирование и анимация, остаётся сложной проблемой. В данной работе представлена система ‘DreamID-Omni: Unified Framework for Controllable Human-Centric Audio-Video Generation’ — унифицированная платформа, использующая \mathcal{S}-симметричный условный диффузионный трансформер для бесшовной интеграции этих задач и решения проблемы идентификации и согласованности голоса в мультиперсонажных сценариях. Предложенная стратегия двойного разделения, включающая синхронизированный RoPE и структурированные подписи, позволяет добиться высокой степени контроля над атрибутами и личностями. Не откроет ли это путь к созданию более реалистичного и управляемого мультимедийного контента, превосходящего существующие коммерческие решения?
Неизбежный Хаос: Проблема Сохранения Личности в Генеративном ИИ
Современные системы генерации аудио- и видеоматериалов часто сталкиваются с проблемой сохранения последовательной идентичности объекта на протяжении всего генерируемого контента. Несмотря на впечатляющие успехи в реалистичности и детализации, возникают заметные прерывы и несоответствия во внешности или голосе, что нарушает эффект погружения. Эта непоследовательность особенно заметна при создании продолжительных видеороликов или при генерации контента, включающего несколько персонажей, где поддержание уникальности каждого из них является критически важным. Причина кроется в сложности моделирования тонких нюансов, определяющих индивидуальность, и в тенденции алгоритмов смешивать характеристики идентичности с другими параметрами, такими как эмоциональное состояние или манера речи, что приводит к нежелательным изменениям и искажениям на протяжении всего видеоряда или аудиозаписи.
Основная сложность в создании стабильной личности в генеративных моделях аудио и видео заключается в том, что в латентных представлениях характеристики голоса, такие как тембр, и эмоциональная окраска речи, часто неразрывно связаны с идентификацией говорящего. Это приводит к тому, что при изменении выразительности или интонации модели, происходит и изменение воспринимаемой личности. Исследователи стремятся разделить эти факторы, чтобы модель могла генерировать речь с различными эмоциями и стилями, сохраняя при этом узнаваемый голос конкретного человека. Разделение этих переплетенных характеристик требует разработки сложных алгоритмов, способных выделять и контролировать каждый аспект отдельно, что является ключевым шагом к созданию реалистичных и последовательных персонажей в цифровом мире.
Существующие методы генерации аудио и видео часто сталкиваются с проблемой «путаницы говорящих», особенно в ситуациях с несколькими участниками. Анализ показывает, что алгоритмы испытывают трудности в поддержании стабильной идентичности каждого говорящего на протяжении всей последовательности, что приводит к заметным несоответствиям и неестественности. В частности, при одновременном участии нескольких людей, системы часто смешивают или путают характеристики голоса и внешности, что проявляется в непоследовательном визуальном и акустическом представлении. Это происходит изза сложности разделения индивидуальных черт от общих элементов выражения и тембра, что затрудняет точное воспроизведение идентичности каждого говорящего в динамичной среде. Дальнейшие исследования направлены на разработку более совершенных алгоритмов, способных эффективно разделять и сохранять уникальные характеристики каждого участника, обеспечивая реалистичность и согласованность генерируемого контента.

DreamID-Omni: Разобщение для Контроля над Личностью
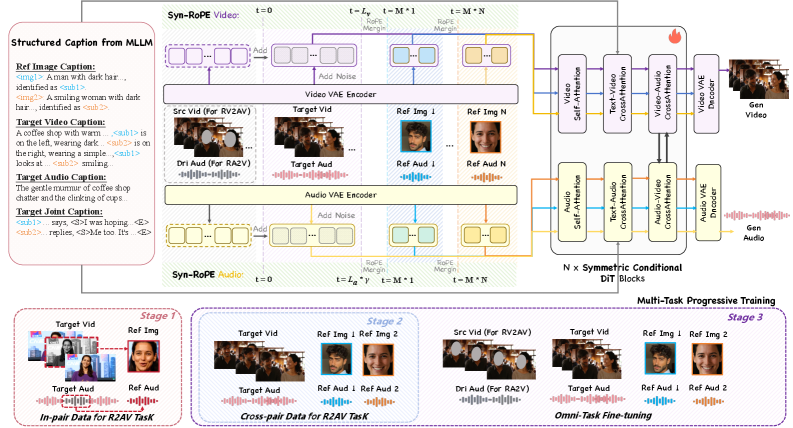
Архитектура DreamID-Omni использует симметричную условную модель DiT (Diffusion Transformer), что позволяет объединять различные управляющие сигналы в едином латентном пространстве. Данный подход предполагает использование как диффузионных моделей для генерации, так и трансформеров для обработки и интеграции условных данных. Симметричная конструкция обеспечивает эффективное кодирование и декодирование информации, а условность позволяет контролировать процесс генерации посредством различных входных параметров, таких как идентификатор, тембр и экспрессия. Использование единого латентного пространства упрощает управление и обеспечивает согласованность генерируемого контента при изменении управляющих сигналов.
В основе DreamID-Omni лежит метод двойного разобщения (Dual-Level Disentanglement), позволяющий разделять параметры голоса на три независимые составляющие: идентичность, тембр и экспрессию. Разделение осуществляется для обеспечения точного контроля над каждой характеристикой. Идентичность относится к уникальным характеристикам голоса, позволяющим распознать конкретного говорящего. Тембр описывает качество звука, определяемое акустическими свойствами. Экспрессия охватывает эмоциональную окраску речи, включая интонацию и динамику. Независимое управление этими параметрами позволяет синтезировать речь с заданными характеристиками, сохраняя при этом узнаваемость голоса.
Для обеспечения консистентного представления идентичности в DreamID-Omni используется подход, основанный на структурированных подписях и вращающихся позиционных вложениях (Syn-RoPE). Структурированные подписи позволяют четко разграничить различные аспекты входных данных, выделяя характеристики, определяющие идентичность. Syn-RoPE, в свою очередь, обеспечивает эффективное кодирование позиционной информации, сохраняя стабильность представления идентичности при изменении длины последовательности или при обработке различных входных данных. Это позволяет модели сохранять узнаваемость и консистентность идентичности даже при изменении других параметров, таких как тембр или экспрессия.
IDBench-Omni: Комплексная Оценка в Реальных Условиях
IDBench-Omni представляет собой всесторонний эталонный набор данных, разработанный специально для оценки задач, использующих мультимодальные аудио- и видеоданные. Набор данных включает в себя разнообразные сценарии и условия, что позволяет комплексно оценить производительность моделей в различных аспектах обработки аудиовизуальной информации. Он предназначен для стандартизированной оценки и сравнения алгоритмов, работающих с одновременной обработкой аудио- и видеопотоков, обеспечивая объективную метрику для прогресса в данной области исследований. IDBench-Omni охватывает широкий спектр задач, включая распознавание говорящих, анализ эмоций и понимание контекста, предоставляя исследователям необходимые ресурсы для разработки и тестирования передовых мультимодальных систем.
Для создания обучающего набора данных IDBench-Omni использовался комплекс инструментов автоматизированной обработки. DWPose обеспечил точное определение поз людей на видео, DiariZen — автоматическое разделение аудиопотока на сегменты, соответствующие различным говорящим, CosyVoice — выделение голосов и удаление шумов, а ClearerVoice — улучшение качества звука путем подавления помех и артефактов. Комбинация этих инструментов позволила получить разнообразный и высококачественный набор данных, пригодный для обучения и оценки моделей, работающих с аудио- и видеоданными, и обеспечил высокую точность аннотаций и надежность данных для задач мультимодального анализа.
Для оценки качества результатов в IDBench-Omni используются метрики, включающие WavLM для количественной оценки сходства тембра и Gemini-2.5-Pro, выступающего в роли эксперта для выявления путаницы между дикторами, что позволяет получить как численные, так и качественные данные. В ходе тестирования модель DreamID-Omni продемонстрировала передовые результаты (SOTA) по трем ключевым показателям: AES (оценка качества видео), ViCLIP (сходство текста и видео) и ID-Sim (сходство идентификаторов), подтверждая свою эффективность в задачах анализа аудио-видео данных.
Влияние и Перспективы: Куда Ведет Контроль над Личностью?
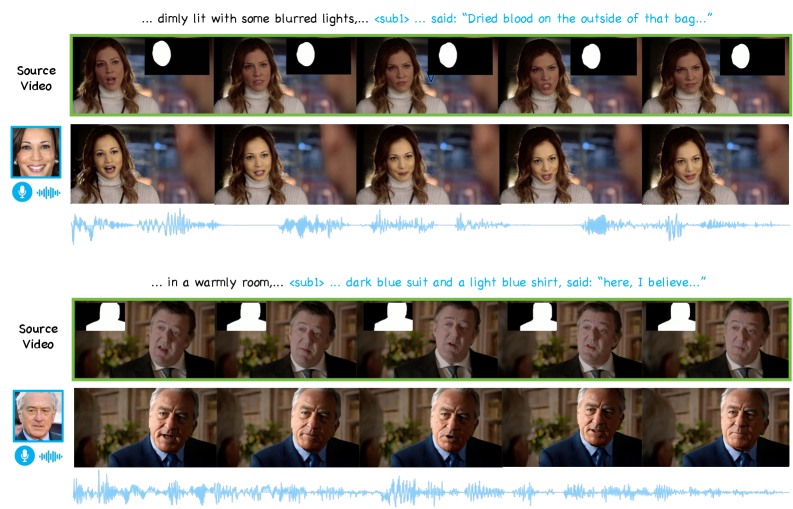
DreamID-Omni представляет собой универсальную платформу, открывающую новые возможности в сфере создания контента. Система способна выполнять задачи, такие как RA2V — анимация видео по заданному аудиосигналу, позволяя оживлять визуальные образы под музыку или речь. Не менее впечатляющим является функционал RV2AV, позволяющий осуществлять редактирование видео с использованием генерации аудио-визуального контента, что значительно расширяет возможности для пост-продакшена и создания динамичных видеороликов. Благодаря своей архитектуре, DreamID-Omni обеспечивает гибкость и эффективность в решении широкого спектра задач, от простых анимаций до сложного видеомонтажа, делая процесс создания контента более доступным и креативным.
Первоначальная реализация DreamID-Omni опирается на Ovi для эффективной инициализации, что позволяет значительно ускорить процесс обучения и снизить вычислительные затраты. Для дальнейшей оптимизации производительности была применена методика Multi-Task Progressive Training — последовательное обучение модели на различных, взаимосвязанных задачах. Такой подход позволяет системе не только быстрее осваивать новые навыки, но и улучшать обобщающую способность, что критически важно для создания высококачественного контента.
В ходе исследований, использование структурированного описания позволило добиться крайне низкого уровня путаницы говорящих — всего 0,08. Это представляет собой значительный прогресс по сравнению с существующими базовыми методами, открывая новые возможности для точной синхронизации речи и визуального контента. В дальнейшем планируется расширить функциональность данной системы, применив её к более сложным сценариям и задачам, а также исследовать возможности генерации контента в режиме реального времени, что позволит создавать динамические и интерактивные мультимедийные продукты.
Представленная работа демонстрирует стремление к созданию универсальных систем генерации аудио-визуального контента. Однако, как показывает практика, любая, даже самая элегантная архитектура, со временем обрастает компромиссами и техническим долгом. Дэвид Марр однажды заметил: «Всякое сложное явление можно свести к более простым компонентам, но понимание этих компонентов не обязательно упрощает задачу». В контексте DreamID-Omni, стремление к диспутантации идентичности и контролю над генерацией — это лишь усложнение базовой задачи: правдоподобно воспроизвести реальность. Рано или поздно, продюсер найдёт способ заставить эту систему генерировать что угодно, игнорируя все тонкости disentanglement, и тогда все эти инновации превратятся в очередной набор костылей.
Что дальше?
Представленная работа, как и большинство «прорывных» решений, лишь аккуратно перемещает проблему в другую область. Достижение согласованности личности в аудио-видео генерации, безусловно, впечатляет, но что произойдёт, когда система столкнётся с реальностью? Когда вместо тщательно отобранных датасетов ей предложат видео низкого качества, плохое освещение и непредсказуемое поведение субъектов? Полагать, что Dual-Level Disentanglement решит все проблемы, — наивно. Скорее, это просто ещё один уровень сложности, который придется поддерживать.
Если система стабильно генерирует нелепости, значит, она хотя бы последовательна. Впрочем, конечно, можно продолжать усложнять архитектуру, добавлять новые «диффузионные трансформаторы» и надеяться, что кто-нибудь когда-нибудь разберётся, что здесь вообще происходит. В конце концов, мы не пишем код — мы просто оставляем комментарии будущим археологам. Очевидно, что следующий шаг — это не просто генерация, а контроль над этой генерацией, но это потребует гораздо более глубокого понимания того, как человек воспринимает реальность.
Не стоит забывать, что всё это — лишь инструменты. И инструменты, как известно, рано или поздно ломаются. «Cloud-native» аудио-видео генерация — это просто старые проблемы, упакованные в более дорогую обёртку. Настоящий прогресс требует не новых алгоритмов, а более реалистичного взгляда на ограничения существующих. Возможно, стоит потратить время не на усложнение моделей, а на сбор данных, которые хоть как-то отражают реальный мир.
Оригинал статьи: https://arxiv.org/pdf/2602.12160.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Как самому почистить матрицу. Продолжение.
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Неважно, на что вы фотографируете!
- Российский рынок: между нефтяными ограничениями и банковской стабильностью (26.03.2026 00:32)
- Мозг в действии: Новый мультимодальный датасет для когнитивных исследований
- MSI Katana 17 HX B14WGK ОБЗОР
- Обзор камеры Nikon D4
- Поляризационный фильтр.
- Они на наносекунды отстают от нас — генеральный директор NVIDIA бьет тревогу по поводу роста искусственного интеллекта в Китае и ставит под сомнение стратегию США в отношении чипов.
- Как правильно фотографировать ночью
2026-02-14 07:23