Автор: Денис Аветисян
Новая система STITCH моделирует контекстуальные намерения, позволяя агентам эффективно использовать память для решения сложных задач, требующих последовательного планирования.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"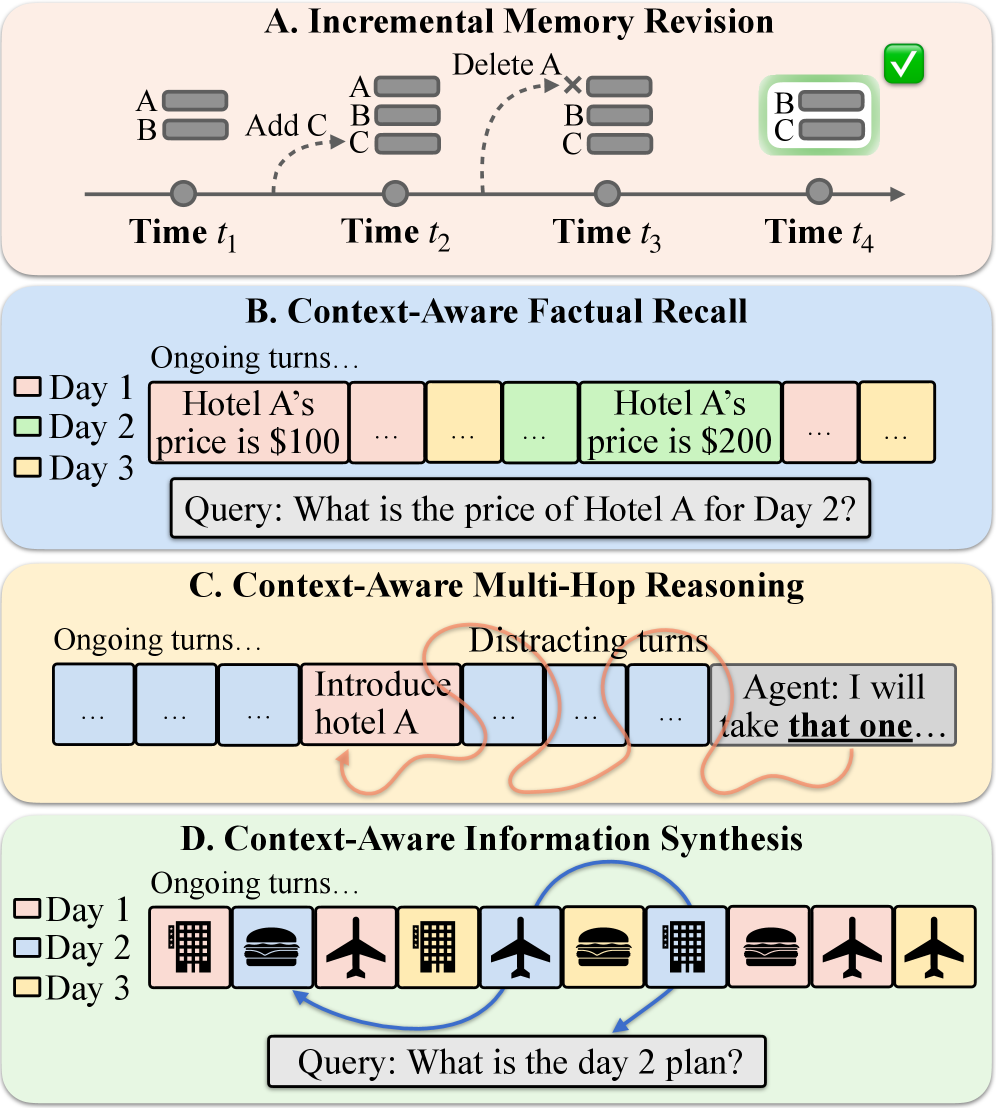
Представлена система STITCH и эталонный набор данных CAME-Bench для оценки контекстно-зависимой памяти агентов.
Несмотря на значительные успехи в области больших языковых моделей, обеспечение надежного долгосрочного планирования и рассуждений остается сложной задачей. В работе ‘Grounding Agent Memory in Contextual Intent’ предложена система STITCH, использующая структурированное отслеживание намерений для улучшения извлечения релевантной информации из истории взаимодействий агента. Ключевым нововведением является индексация памяти на основе контекстуального намерения, что позволяет эффективно отфильтровывать шум и повышать точность рассуждений в динамичных сценариях. Сможет ли подобный подход открыть путь к созданию более интеллектуальных и надежных агентов, способных к эффективному взаимодействию в сложных, долгосрочных задачах?
Элегантность Долгосрочного Рассуждения
Традиционные языковые модели демонстрируют существенные трудности в поддержании связности и согласованности при продолжительных взаимодействиях, что ограничивает их способность к полноценному рассуждению. По мере увеличения длины диалога или последовательности задач, модели склонны к потере информации из начальных этапов, приводя к непоследовательным ответам и ошибкам в логических выводах. Это связано с архитектурными ограничениями, в частности, с механизмом внимания, который испытывает сложности при обработке длинных последовательностей. В результате, способность модели к построению сложных аргументов, планированию действий на несколько шагов вперёд и эффективному решению многоэтапных задач значительно снижается, что препятствует созданию действительно интеллектуальных систем.
Эффективное долгосрочное рассуждение требует от систем способности интегрировать информацию на протяжении множества шагов, что представляет собой значительную проблему для современных архитектур, основанных на трансформерах. Традиционные модели, хоть и демонстрируют впечатляющие результаты в обработке коротких последовательностей, испытывают трудности с поддержанием когерентности и актуальности информации при увеличении длины контекста. Это связано с экспоненциальным ростом вычислительных затрат и сложностью удержания всех релевантных деталей в ограниченном «окне внимания». В результате, модели могут «забывать» важные факты, допускать логические ошибки или терять нить рассуждений при решении сложных задач, требующих последовательного анализа и синтеза информации на протяжении многих этапов.
Решение проблемы поддержания целостности информации на протяжении длительных взаимодействий имеет решающее значение для широкого спектра приложений, требующих сложного и многоэтапного диалога. Способность системы последовательно отслеживать и интегрировать информацию в течение множества ходов необходима для выполнения задач, выходящих за рамки простых вопросов и ответов — например, для помощи в планировании сложных проектов, написания развернутых текстов или ведения переговоров. Эффективное долгосрочное рассуждение позволит создавать интеллектуальных помощников, способных не просто реагировать на текущий запрос, а активно участвовать в решении проблемы, запоминая предыдущие шаги и адаптируя стратегию в соответствии с меняющейся ситуацией, что открывает новые горизонты для автоматизации и взаимодействия человека с машиной.
STITCH: Моделирование Намерений для Эффективной Памяти
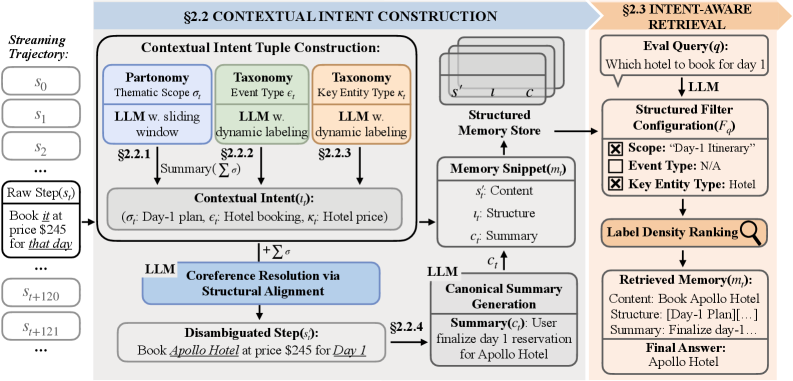
STITCH представляет собой агентурную систему памяти, предназначенную для моделирования скрытых намерений пользователя в онлайн-среде. В отличие от традиционных систем, STITCH не просто хранит информацию, но и активно анализирует текущий контекст взаимодействия, чтобы определить, какие данные наиболее релевантны для достижения поставленной цели. Это позволяет системе эффективно фильтровать входящий поток информации, отсеивая нерелевантные данные и сосредотачиваясь на тех, которые непосредственно способствуют выполнению задачи. В результате достигается более эффективный поиск и извлечение необходимой информации, повышая общую производительность и удобство использования системы для пользователя.
Система STITCH явно моделирует контекстное намерение пользователя, состоящее из трех ключевых компонентов: тематической области (Thematic Scope), типа события (Event Type) и типов ключевых сущностей (Key Entity Types). Тематическая область определяет общую предметную сферу интереса, тип события — конкретное происходящее действие, а типы ключевых сущностей — конкретные объекты или понятия, важные для данного контекста. Комбинируя эти три элемента, STITCH формирует представление о текущей цели пользователя и использует его для фильтрации и извлечения релевантной информации, игнорируя данные, не соответствующие текущему намерению. Это позволяет системе более эффективно управлять памятью и предоставлять пользователю только ту информацию, которая необходима для решения текущей задачи.
Система STITCH расширяет функциональность существующих систем структурированной и графовой памяти, вводя механизм приоритизации и извлечения информации на основе её соответствия текущей задаче. В отличие от традиционных подходов, где информация извлекается по ключевым словам или связям, STITCH оценивает релевантность данных, сопоставляя их с явно представленным контекстуальным намерением пользователя. Это позволяет системе отфильтровывать нерелевантную информацию и повышать эффективность поиска, фокусируясь на данных, которые наиболее вероятно будут полезны для достижения текущей цели. В результате, STITCH обеспечивает более точное и контекстно-зависимое извлечение информации по сравнению с системами, не учитывающими намерения пользователя.
CAME-Bench: Новый Стандарт Оценки Контекстно-Зависимого Поиска
Для подтверждения эффективности STITCH была разработана новая методика оценки — CAME-Bench. CAME-Bench представляет собой набор данных, специально предназначенный для оценки систем контекстно-зависимого поиска в длинных, ориентированных на достижение целей траекториях взаимодействия. Особенностью CAME-Bench является акцент на оценке способности систем поддерживать когерентность и выявлять релевантную информацию в условиях чередующихся целей и значительного объема истории взаимодействий. Это позволяет более точно оценить производительность систем в сложных, реалистичных сценариях, где важна не только точность поиска, но и способность учитывать контекст и историю.
В основе CAME-Bench лежит анализ траекторий (Trajectory Analysis), представляющий собой методологию оценки способности систем поддерживать когерентность и точно идентифицировать релевантную информацию в длинных последовательностях действий, включающих чередующиеся цели и значительный объем предшествующей истории. Этот анализ измеряет, насколько эффективно система отслеживает текущую цель, сохраняя при этом доступ к необходимому контексту из предыдущих шагов, что критически важно для поддержания последовательности и точности ответов в сложных, многошаговых сценариях. Оценка проводится путем анализа способности системы извлекать информацию, необходимую для решения текущей задачи, из всей доступной траектории, учитывая как недавние, так и более отдаленные действия и цели.
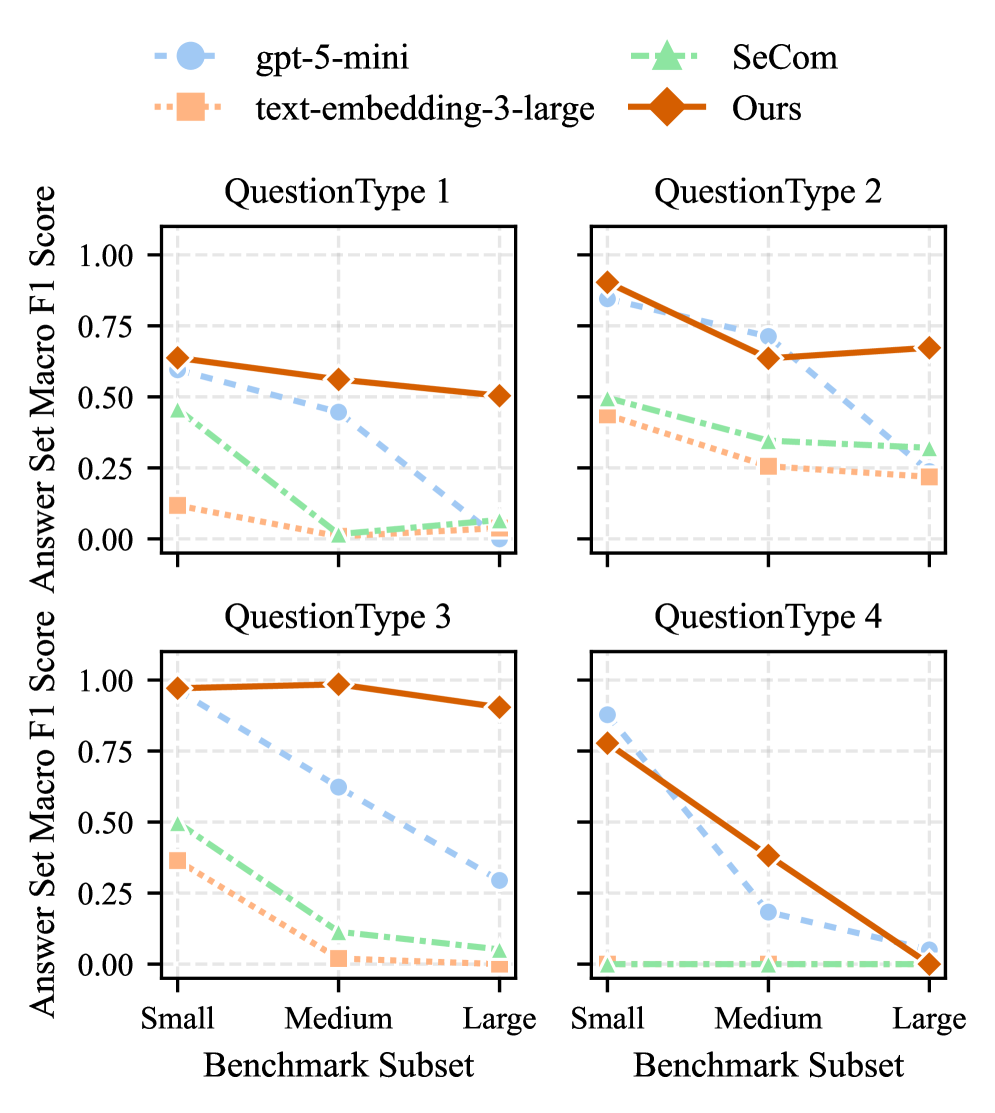
При оценке на базе CAME-Bench, система STITCH продемонстрировала значительное улучшение производительности в задачах, требующих долгосрочного планирования и рассуждений. На большом наборе данных CAME-Bench, STITCH достиг показателя F1 в 0.478, что на 11.6% выше, чем у лучшего базового метода (относительное улучшение) и на 35.6% абсолютное улучшение. Данные результаты подтверждают эффективность STITCH в сценариях, где необходимо учитывать длительную историю взаимодействий и последовательность целей.
Точность Разрешения Сущностей: Ключ к Надежному Извлечению Информации
Ключевым фактором эффективности системы STITCH является точная идентификация сущностей, оцениваемая показателем «Recall разрешения сущностей». Этот показатель отражает способность системы правильно связывать различные упоминания одной и той же сущности на протяжении всего анализируемого текста или траектории. Высокая точность разрешения сущностей критически важна, поскольку позволяет системе понимать контекст и связи между элементами информации, избегая путаницы и обеспечивая корректное извлечение и обработку данных. Без надежной идентификации сущностей, система рискует интерпретировать различные упоминания одного и того же объекта как отдельные, что может привести к неверным выводам и снижению общей производительности.
Внедрение методов промптинга на основе больших языковых моделей (LLM) в системы STITCH и CAME-Bench значительно повышает точность извлечения информации и глубину понимания контекста. Этот подход позволяет системам более эффективно интерпретировать запросы пользователей и находить релевантные данные, используя возможности LLM для уточнения смысла и выявления скрытых связей. В результате, системы способны предоставлять более точные и полные ответы, а также лучше адаптироваться к различным формулировкам запросов и нюансам языка, что открывает новые возможности для создания интеллектуальных систем, способных к более естественному и продуктивному взаимодействию с пользователем.
Система STITCH демонстрирует впечатляющую точность разрешения сущностей, достигая показателя Entity Resolution Recall более 80% и Macro-Averaged F1 Score в 0.426 на среднем бенчмарке CAME-Bench. Этот результат превосходит показатели лучшей базовой модели на 11.6% относительно, что свидетельствует о значительном прогрессе в способности системы корректно связывать упоминания одних и тех же сущностей в рамках заданного контекста. Повышенная точность разрешения сущностей открывает новые возможности для надежного и эффективного ‘Retrieval-Augmented Generation’, позволяя создавать более естественные и информативные взаимодействия, поскольку система способна более точно извлекать и использовать релевантную информацию.
Исследование демонстрирует, что эффективная система агентской памяти требует не просто хранения информации, но и понимания контекста, в котором она была получена. Как отмечал Пол Эрдёш: «Математика — это искусство находить закономерности, которые скрыты от глаз». Аналогично, STITCH, представленная в данной работе, выявляет скрытые закономерности в последовательности взаимодействий агента, моделируя его намерение и, тем самым, улучшая долгосрочное рассуждение. Особое внимание к моделированию контекстуального намерения является ключевым элементом, позволяющим системе адаптироваться к меняющимся условиям и эффективно использовать накопленные знания, что согласуется с принципом, согласно которому структура определяет поведение системы.
Куда Дальше?
Представленная работа, безусловно, демонстрирует важность моделирования контекстуальных намерений для агентов, работающих с памятью. Однако, не стоит обольщаться кажущимся прогрессом. Если система опирается на «костыли» для достижения результатов, это лишь указывает на то, что мы переусложнили её. Создание сложной архитектуры без глубокого понимания лежащих в её основе принципов — путь к иллюзии контроля. Новый бенчмарк, CAME-Bench, — это, конечно, шаг вперед, но метрики сами по себе не гарантируют истинного интеллекта.
Настоящая проблема заключается не в увеличении объема памяти, а в её осмысленном использовании. Модульность без понимания контекста — это лишь разделение ответственности, но не решение. Будущие исследования должны сосредоточиться на разработке более элегантных систем, способных к адаптации и обобщению, а не на простом накоплении знаний. Важно помнить: структура определяет поведение, и пока мы не поймем, как формируется эта структура, долгосрочное планирование останется проблемой.
Очевидно, что необходимо отойти от представления о памяти как о статичном хранилище данных. Истинный интеллект требует динамической, самоорганизующейся памяти, способной к обучению и эволюции. Следующим шагом, вероятно, станет исследование связей между контекстуальным пониманием, причинно-следственными связями и способностью к абстракции. Иначе, все наши усилия будут похожи на строительство дворца на песке.
Оригинал статьи: https://arxiv.org/pdf/2601.10702.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- Российский рынок в 2025: Инвестиции, Экспорт и Новые Возможности (27.02.2026 15:32)
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
2026-01-18 13:58