Автор: Денис Аветисян
Новое исследование показывает, что «зацикливание» нейронных сетей может улучшить их способность соотносить внутренние представления с языковыми выводами, но ценой снижения ясности этих представлений.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"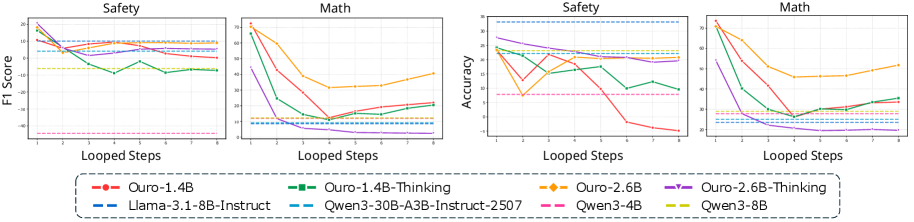
Работа посвящена анализу «зацикленных» трансформеров и выявлению ограничений самопроверки и интерпретации внутренних представлений.
Несмотря на впечатляющие успехи больших языковых моделей, сохраняется разрыв между их внутренними знаниями и фактическими лингвистическими результатами. В данной работе, озаглавленной ‘Loop as a Bridge: Can Looped Transformers Truly Link Representation Space and Natural Language Outputs?’, исследованы Looped Transformers (LT) — архитектуры, увеличивающие вычислительную глубину за счет итеративного повторения слоев — и их способность к “самоанализу”. Эксперименты показали, что увеличение числа итераций действительно сужает этот разрыв, однако это улучшение частично связано с ухудшением качества внутренних представлений, а доступ к ним ограничен последней итерацией. Способны ли Looped Transformers в полной мере реализовать потенциал масштабирования вычислительной глубины и обеспечить истинное связывание пространства представлений с естественным языком?
Пределы Масштаба: Рассуждения в Больших Языковых Моделях
Несмотря на впечатляющие достижения больших языковых моделей в различных областях, их способность к логическому мышлению остается хрупкой и часто дает сбой при решении сложных задач. Увеличение масштаба моделей, то есть наращивание числа параметров, не гарантирует более глубокого понимания или надежности вывода. Исследования показывают, что даже самые крупные модели могут допускать грубые ошибки в рассуждениях, требующих многоступенчатого анализа или применения здравого смысла. Это указывает на фундаментальное ограничение подхода, основанного исключительно на масштабировании, и необходимость разработки новых архитектур и методов обучения, которые бы улучшили способность моделей к надежному и эффективному логическому мышлению, а не просто увеличивали их размер.
Традиционные подходы к улучшению языковых моделей, основанные на увеличении количества параметров, зачастую оказываются затратными и не всегда приводят к более глубокому пониманию. Хотя наращивание параметров и позволяет моделям запоминать больше информации и демонстрировать впечатляющие результаты на поверхностных задачах, это не гарантирует развития способности к логическому мышлению или решению сложных проблем. Исследования показывают, что увеличение масштаба модели не всегда приводит к пропорциональному улучшению в способности к обобщению и применению знаний в новых, незнакомых ситуациях. Вместо простого увеличения размера, необходимы инновационные архитектуры, которые эффективно используют имеющиеся ресурсы и позволяют моделям строить более сложные и надежные модели мира, что, в конечном итоге, и является ключом к истинному пониманию.
Несмотря на впечатляющие успехи больших языковых моделей, их способность к рассуждениям остается хрупкой и часто дает сбой при решении сложных задач. Этот фундаментальный предел указывает на необходимость разработки архитектур, которые повышают эффективность рассуждений, а не просто полагаются на увеличение масштаба. Вместо бесконечного наращивания параметров, исследователи все чаще обращают внимание на новые подходы, направленные на оптимизацию внутренних механизмов обработки информации. Такие архитектуры могут включать в себя более эффективные алгоритмы поиска, улучшенные методы представления знаний и более тесную интеграцию с внешними инструментами, позволяющими модели проверять свои выводы и избегать логических ошибок. В конечном итоге, ключ к созданию действительно разумных систем лежит не в увеличении размера, а в совершенствовании способности к рациональному мышлению.
Петли Обратной Связи: Итеративное Улучшение Рассуждений
Трансформеры с обратной связью (Looped Transformers) представляют собой новый подход к построению моделей, позволяющий им многократно пересматривать и уточнять свои внутренние представления. В отличие от стандартных трансформеров, выполняющих обработку данных последовательно, данный подход имитирует итеративные процессы уточнения, характерные для человеческого мышления. Модель, используя обратную связь, повторно обрабатывает информацию, постепенно улучшая качество своих внутренних представлений и, как следствие, повышая точность и обоснованность принимаемых решений. Этот процесс позволяет достичь более глубокого понимания входных данных и более эффективного решения сложных задач без увеличения количества параметров модели.
В архитектуре Looped Transformers повторное использование весов в обратной связи позволяет модели итеративно уточнять свои внутренние представления без увеличения общего числа параметров. Это достигается за счет организации вычислений таким образом, чтобы выходные данные предыдущего шага обрабатывались теми же весами, что и на первом шаге, создавая цикл обратной связи. Фактически, модель многократно применяет одни и те же веса к своим промежуточным результатам, что позволяет ей постепенно улучшать качество своих вычислений и выводить более точные ответы, не увеличивая вычислительную сложность или размер модели.
Для повышения эффективности и производительности архитектур Looped Transformers применяются такие методы, как Duo-causal Attention и LoRA Adapters. Duo-causal Attention позволяет модели учитывать как прошлые, так и будущие контексты при итеративном уточнении представлений, что улучшает качество рассуждений. LoRA Adapters (Low-Rank Adaptation) замораживают предобученные веса модели и обучают лишь небольшое количество низкоранговых матриц, что значительно снижает вычислительные затраты и требования к памяти при адаптации модели к новым задачам, не ухудшая при этом общую производительность. Комбинация этих методов обеспечивает оптимальный баланс между вычислительной сложностью и точностью итеративного уточнения.
Прощупывая Внутренний Мир: Анализ Процесса Рассуждений
Мониторы, основанные на анализе внутренних представлений, в сочетании с методами, такими как линейные зонды (Linear Probes), позволяют исследовать внутренние состояния Looped Transformers и оценивать надежность их процесса рассуждений. Линейные зонды представляют собой обученные модели, предназначенные для прогнозирования конкретных характеристик или решений на основе внутренних представлений модели. Анализируя выходные данные этих зондов, исследователи могут получить представление о том, как модель обрабатывает информацию и формирует свои ответы, выявляя закономерности и зависимости между внутренними представлениями и конечным результатом. Данный подход позволяет оценить, насколько последовательно и обоснованно модель приходит к своим выводам, что критически важно для понимания и улучшения ее способности к логическому мышлению и решению задач.
Оценка понимания модели задачи на промежуточных этапах рассуждений осуществляется посредством обучения специальных “зондов” (probes) предсказывать корректность ответа на основе внутренних представлений модели. Эти зонды обучаются на данных, сопоставляющих внутреннее состояние модели с итоговой правильностью ответа. Высокая точность предсказания зонда указывает на то, что модель сформировала адекватное представление о задаче до генерации ответа, что позволяет количественно оценить степень ее “понимания” на данном этапе рассуждений. Таким образом, точность работы зонда служит метрикой, отражающей, насколько эффективно внутренние представления модели кодируют информацию, необходимую для успешного решения задачи.
В ходе анализа Looped Transformers установлено, что, несмотря на повышение точности языковой самопроверки (language-based self-verification) с увеличением числа итераций цикла, точность линейных зондов (linear probes), используемых для мониторинга внутренних представлений, незначительно снижается. Это указывает на компромисс между способностью модели к самооценке и поддержанием внутренней согласованности ее представлений. Повышение точности самопроверки, вероятно, достигается за счет модификации внутренних представлений, которые, в свою очередь, могут ухудшить их интерпретируемость и соответствие исходным признакам, что и фиксируется снижением точности линейных зондов.
Подтверждение Надёжности: Самопроверка и Устойчивость
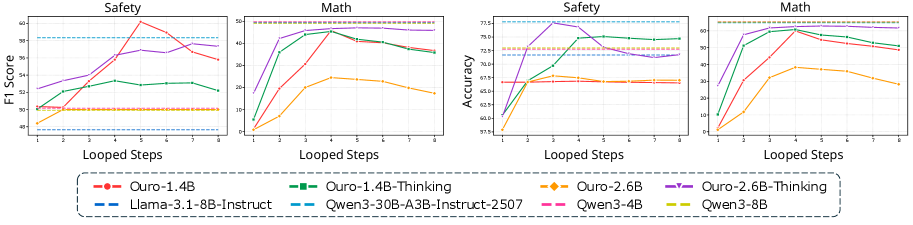
Эффективность Looped Transformers подтверждается применением метода самопроверки (Self-Verification), в рамках которого модель оценивает собственные ответы. Этот процесс позволяет значительно повысить точность результатов. Модель, проходя через несколько итераций, анализирует свою логику и выявляет потенциальные ошибки, что приводит к улучшению качества и надежности решений. Эксперименты показали, что самопроверка особенно эффективна в задачах, требующих сложного рассуждения и высокой степени точности, обеспечивая существенное улучшение показателей по сравнению с традиционными моделями.
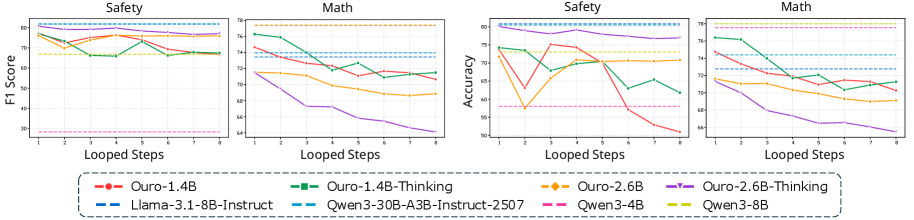
Оценка предложенного подхода на сложных наборах данных, таких как DeepMath и BeaverTails, продемонстрировала его устойчивость к различным задачам. DeepMath включает в себя задачи математического доказательства, требующие логических рассуждений и применения математических теорем. BeaverTails, в свою очередь, представляет собой набор данных, предназначенный для оценки способности моделей к суждениям безопасности и выявлению потенциально опасных ситуаций. Результаты показывают, что модель сохраняет высокую производительность и точность на этих сложных задачах, подтверждая ее надежность и способность к обобщению знаний в различных областях.
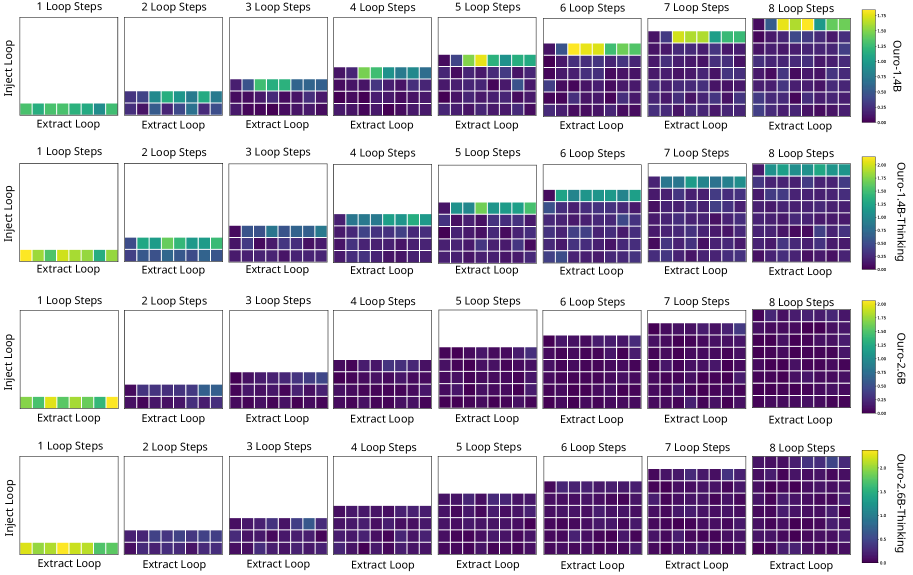
Анализ результатов показывает, что, хотя скорректированная точность обнаружения ошибок возрастает с каждым циклом итерации в Looped Transformers, способность к идентификации концептуальных ошибок ограничивается преимущественно последним циклом. Это указывает на то, что способность модели к самоанализу и осознанию собственных рассуждений остаётся ограниченной, несмотря на повышение точности выявления неверных ответов. Иными словами, модель улучшает свою способность находить что неверно, но не обязательно понимает почему это неверно, что свидетельствует об ограниченности её «интроспективной осознанности».
За Пределами Текущих Границ: К Доверительному ИИ
Архитектура Looped Transformers представляет собой заметный прогресс в создании искусственного интеллекта, отличающегося повышенной эффективностью, надежностью и доверием. В отличие от традиционных трансформеров, требующих огромных вычислительных ресурсов и больших объемов данных для обучения, Looped Transformers используют механизм обратной связи, позволяющий модели многократно анализировать и уточнять свои собственные выводы. Этот итеративный процесс не только снижает потребность в огромных параметрах, но и повышает способность системы к самокоррекции и выявлению собственных ошибок. В результате, такие модели демонстрируют улучшенные результаты в задачах, требующих сложного рассуждения и понимания контекста, а также более устойчивы к неточным или противоречивым данным, что делает их перспективными для применения в критически важных областях, где надежность и предсказуемость являются ключевыми требованиями.
Вместо слепого увеличения количества параметров в искусственных нейронных сетях, современные исследования всё больше внимания уделяют итеративной доработке и анализу внутренних состояний моделей. Такой подход позволяет не просто повысить производительность, но и добиться более глубокого понимания принципов работы ИИ. Анализ внутренних состояний позволяет выявить узкие места в процессе принятия решений и оптимизировать алгоритмы для достижения большей надёжности и обоснованности. Итеративная доработка, в свою очередь, позволяет модели постепенно улучшать свои способности, основываясь на результатах предыдущих итераций, что открывает новые возможности для рассуждений и понимания сложных концепций. Этот сдвиг в парадигме разработки ИИ обещает создание систем, способных не только решать задачи, но и объяснять логику своих действий.
Предстоящие исследования направлены на дальнейшее масштабирование архитектур с обратной связью, что позволит значительно увеличить их вычислительные возможности и способность к решению сложных задач. Параллельно планируется интеграция с другими передовыми методами искусственного интеллекта, такими как обучение с подкреплением и нейро-символические системы, для создания более надежных и интеллектуальных систем. Особое внимание будет уделено разработке механизмов самопроверки и объяснимости, что позволит повысить доверие к решениям, принимаемым искусственным интеллектом, и обеспечить его безопасное применение в критически важных областях, таких как медицина и автономное управление. В конечном итоге, целью является создание ИИ, способного не только эффективно выполнять поставленные задачи, но и демонстрировать признаки истинного понимания и адаптивности.
Исследование Looped Transformers выявляет интересную закономерность: стремление к большей самоверификации через увеличение числа итераций петли может приводить к снижению ясности внутренних представлений. Этот эффект демонстрирует, что глубина вычислений не всегда линейно коррелирует с качеством понимания. Как отмечал Марвин Мински: «Наиболее важное свойство интеллекта — это способность обнаруживать и исправлять собственные ошибки». Подобно тому, как петли в трансформаторах стремятся к самокоррекции, так и интеллект, по мнению Мински, строится на постоянном анализе и улучшении собственных моделей мира. Работа подчеркивает, что для достижения истинной интроспекции необходим не только количественный рост вычислений, но и качественное понимание внутренних механизмов, определяющих эти вычисления.
Куда Ведет Петля?
Исследование, представленное в данной работе, обнажило закономерность, которая, как ни странно, напоминает попытки оптимизации сложной системы за счет увеличения ее внутренней сложности. Увеличение числа итераций в петлевых трансформаторах действительно сужает разрыв между лингвистической верификацией и анализом внутренних представлений, однако это сближение достигается ценой некоторой потери ясности самих представлений. Кажется, что система становится более «убедительной» в своих ответах, но при этом теряет прозрачность внутренних механизмов. Этот компромисс заставляет задуматься о природе «понимания» в контексте языковых моделей.
Очевидным ограничением остается поверхностность интроспекции — доступ к внутреннему состоянию модели остается практически ограниченным последней итерацией петли. Это наводит на мысль, что процесс «мышления» в таких моделях — если это вообще уместное слово — остается в значительной степени непрозрачным, даже для самих «мыслящих». Следующим шагом представляется не просто увеличение числа итераций, а разработка методов «просвечивания» внутренних слоев петли, позволяющих увидеть, как формируются и трансформируются представления на каждом этапе.
В конечном счете, данная работа подтверждает старую истину: увеличение мощности не всегда равносильно углублению понимания. Вместо слепого наращивания вычислительных ресурсов, необходимо сосредоточиться на разработке методов реверс-инжиниринга этих сложных систем, чтобы по-настоящему понять, как они «думают» — или, по крайней мере, как они имитируют этот процесс.
Оригинал статьи: https://arxiv.org/pdf/2601.10242.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- Российский рынок в 2025: Инвестиции, Экспорт и Новые Возможности (27.02.2026 15:32)
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
2026-01-17 21:12