Автор: Денис Аветисян
Исследователи предлагают инновационный подход к поиску людей по текстовому описанию, делая акцент на причинно-следственных связях и повышении надежности системы в различных условиях.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"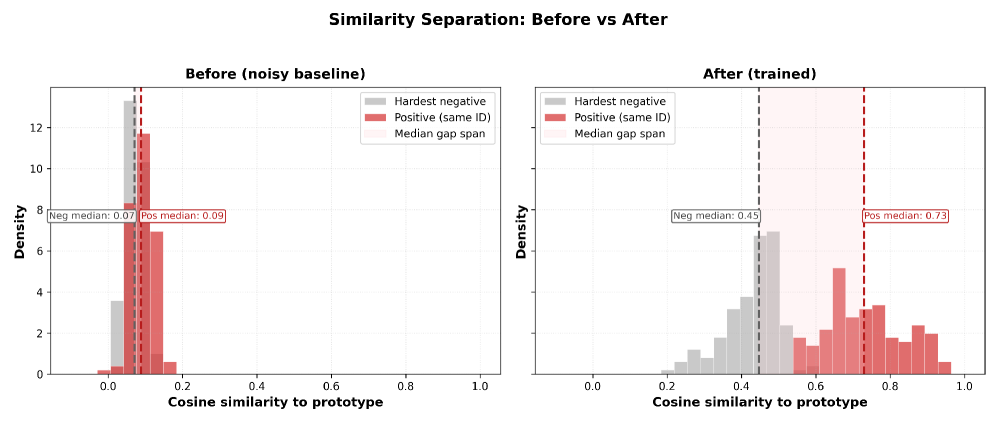
Предложен фреймворк ICON, использующий контрфактическое обучение и нейро-символические априорные знания для решения проблемы смещений в задачах поиска людей по тексту.
Несмотря на успехи современных моделей в задаче поиска людей по текстовому описанию, их устойчивость к изменениям окружения и шумам остается проблематичной. В данной работе, представленной под названием ‘ICON: Invariant Counterfactual Optimization with Neuro-Symbolic Priors for Text-Based Person Search’, предлагается новый подход, направленный на повышение робастности и точности за счет активного вмешательства в процесс обучения и обеспечения семантической причинности. Ключевой особенностью ICON является интеграция каузальных и топологических априорных знаний, что позволяет модели игнорировать нерелевантные факторы и фокусироваться на существенных признаках. Способствует ли предложенный фреймворк переходу от статистической корреляции к обучению инвариантным представлениям и открывает ли новые горизонты в области поиска людей по тексту?
Вызов надежного поиска людей по текстовым запросам
Современные системы поиска людей по текстовому запросу сталкиваются со значительными трудностями при обработке зашумленных или неоднозначных визуальных данных, что приводит к ненадежным результатам. Проблемой является то, что алгоритмы часто полагаются на отдельные, наиболее заметные признаки, такие как цвет одежды или форма лица. В условиях плохого освещения, частичной видимости или наличия большого количества объектов на изображении, эти признаки могут быть неточными или неполными, что существенно снижает эффективность поиска. Неспособность адекватно обрабатывать неидеальные данные приводит к ложным срабатываниям и упущениям, делая текущие системы недостаточно надежными для практического применения в задачах, требующих высокой точности, например, в системах видеонаблюдения или идентификации личности.
Современные системы поиска людей по текстовому описанию часто опираются исключительно на выделение наиболее заметных признаков на изображении. Однако, такая стратегия делает их уязвимыми к изменениям в позе человека или частичной перекрытости объектов. Если ключевые признаки оказываются скрыты, например, из-за другого объекта или изменения угла обзора, система может ошибочно идентифицировать человека или вовсе не найти его. Это особенно актуально в динамичных сценах, где положение и видимость объекта постоянно меняются, что подчеркивает необходимость разработки более устойчивых методов, учитывающих контекст и взаимосвязь между различными элементами изображения, а не только отдельные, «яркие» детали.
Существенным ограничением современных систем поиска людей по тексту является недостаток понимания структурных взаимосвязей между объектами на изображении. Эти системы зачастую оперируют отдельными признаками, не учитывая, как эти признаки взаимодействуют друг с другом и формируют общую картину. Например, система может идентифицировать лицо и предмет одежды, но не понимать, что лицо находится на человеке, что критически важно для точного поиска. Отсутствие способности к анализу пространственных отношений приводит к ошибкам при частичной видимости объектов, изменении позы или сложных сценариях, где взаимосвязи между объектами определяют идентичность и местоположение искомого человека. Разработка методов, способных к построению и анализу графических представлений этих взаимосвязей, представляется ключевым шагом к созданию более надежных и точных систем поиска людей по тексту.
ICON: Нейро-символический каркас для целостного понимания
Фреймворк ICON использует нейро-символические априорные знания для направления процесса поиска соответствий между текстовыми и визуальными признаками. Это достигается путем включения предварительных знаний о структуре и взаимосвязях объектов, что позволяет модели поддерживать топологическую согласованность. В частности, нейро-символические априорные знания помогают установить связи между текстовыми описаниями и соответствующими областями изображения, обеспечивая, чтобы модель учитывала не только явные признаки, но и их пространственные отношения и контекст. Такой подход повышает надежность и точность извлечения информации, особенно в сложных визуальных сценах.
В основе архитектуры ICON лежат принципы целостности и соответствия пространственной компоновке, направленные на предотвращение фокусировки исключительно на наиболее заметных визуальных признаках. Целостность (Holistic Completeness) подразумевает анализ всей сцены, а не только отдельных объектов, что позволяет учитывать контекст и взаимосвязи. Соответствие пространственной компоновке (Spatial Layout Consistency) обеспечивает согласованность между текстовым описанием и геометрическим расположением объектов на изображении. Такой подход позволяет модели более эффективно извлекать информацию и избегать ошибок, возникающих при анализе только доминирующих элементов, обеспечивая более полное и точное понимание сцены.
Принцип “независимости от окружения” является основополагающим для архитектуры ICON, обеспечивая концентрацию модели на самом человеке, а не на окружающих объектах и фоне. Это достигается путем внедрения механизмов, подавляющих влияние посторонних элементов в визуальном и текстовом представлении. Алгоритмы ICON специально разработаны для фильтрации информации, не относящейся к целевому человеку, что повышает точность анализа и снижает вероятность ложных срабатываний, вызванных отвлекающими факторами в изображении или текстовом описании. Таким образом, модель может эффективно выделять и обрабатывать релевантные характеристики человека, независимо от сложности или загроможденности окружающей среды.

Повышение надежности с помощью расширенного выравнивания признаков
Нейро-символическое топологическое выравнивание (Neuro-Symbolic Topological Alignment) представляет собой метод, ограничивающий сопоставление признаков в процессе идентификации личности. Данный подход использует как нейронные сети для извлечения признаков, так и символические правила, определяющие допустимые топологические связи между ними. Ограничение сопоставления признаков предотвращает установление ложных связей между нерелевантными признаками, что повышает точность идентификации, особенно в сложных условиях, например, при частичной окклюзии или низком разрешении изображения. Применение символических правил гарантирует, что сопоставление признаков соответствует априорным знаниям о структуре человеческого тела и пространственным отношениям между его частями, что снижает вероятность ошибочной идентификации.
Метод “Контрфактического Разделения Контекста” (Counterfactual Context Disentanglement) направлен на повышение устойчивости модели к отвлекающим факторам окружения. Он предполагает активное удаление или подавление информации о фоне и нерелевантном контексте из входных данных. Это достигается путем обучения модели различать признаки, относящиеся непосредственно к идентичности человека, и признаки, обусловленные окружающим его окружением. В результате модель вынуждена концентрироваться исключительно на семантике, связанной с конкретным человеком, что повышает точность идентификации в сложных условиях и снижает зависимость от внешних факторов. Технически, это реализуется через модификации функции потерь и архитектуры сети, направленные на минимизацию влияния контекстных признаков на финальное решение.
Метод салиентно-ориентированной семантической регуляризации направлен на повышение устойчивости модели к частичной потере информации о человеке. Данный подход заставляет модель восстанавливать идентификатор человека даже при намеренном маскировании или затенении наиболее заметных признаков (например, лица, частей тела). Это достигается путем введения в процесс обучения регуляризационного штрафа, который побуждает модель генерировать согласованные представления идентичности, основываясь на менее заметных, но семантически значимых признаках, что позволяет эффективно справляться с ситуациями, когда ключевые визуальные ориентиры недоступны или зашумлены.
Смягчение геометрического шума и обеспечение пространственной согласованности
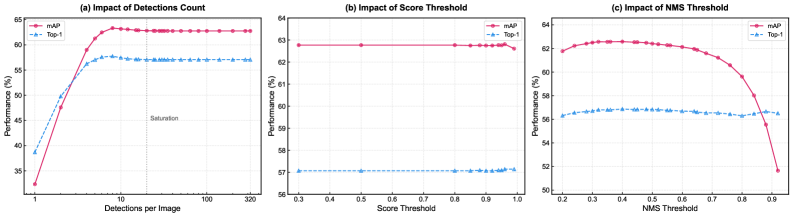
Геометрическая инвариантность в задачах поиска людей по текстовому описанию (TBPS) достигается путем минимизации чувствительности к изменениям местоположения ограничивающих рамок (bounding boxes). Неточности в определении координат ограничивающих рамок являются распространенной причиной ошибок в системах TBPS. Уменьшение зависимости модели от абсолютного положения объектов в кадре позволяет повысить устойчивость к небольшим сдвигам, масштабированию и другим геометрическим искажениям, что, в свою очередь, улучшает общую точность поиска и снижает количество ложных срабатываний.
Метод “Руководствуемое Пространственное Вмешательство” предполагает активное внесение случайных возмущений в координаты ограничивающих рамок (bounding boxes) в процессе обучения модели. Эти возмущения, основанные на заданных правилах, заставляют модель учиться извлекать устойчивые признаки, не зависящие от точного местоположения объектов на изображении. Данная техника позволяет модели стать более робастной к небольшим смещениям и деформациям ограничивающих рамок, что является важным фактором для повышения точности поиска людей по текстовым запросам, особенно в сложных условиях и при наличии ошибок в аннотациях.
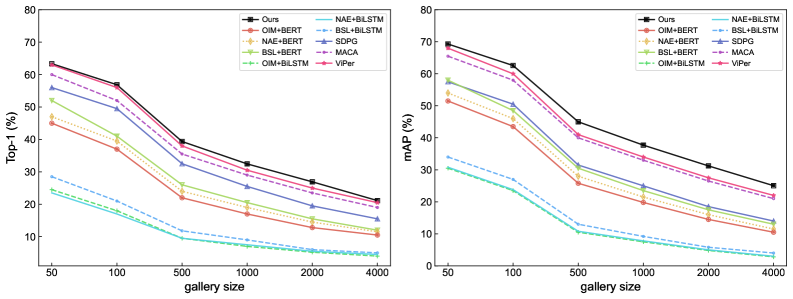
Модель ICON демонстрирует высокую точность в задачах поиска людей по текстовому описанию, достигая среднего значения точности (mAP) в 64.17 на датасете CUHK-SYSU-TBPS и 22.49 на PRW-TBPS. Данные результаты свидетельствуют о значительном улучшении производительности по сравнению с существующими методами и устанавливают новый стандарт надежности в области поиска людей по текстовым запросам, благодаря одновременному решению как семантических, так и геометрических задач.
Перспективы развития: к интеллектуальному визуальному поиску
Принципы, лежащие в основе ICON — целостное понимание и нейро-символические рассуждения — обладают значительным потенциалом для применения в более широком спектре задач компьютерного зрения. Помимо поиска по изображениям, эти подходы могут быть успешно интегрированы в системы распознавания объектов и анализа сцен. Вместо фокусировки на отдельных признаках, ICON стремится к комплексному пониманию визуальной информации, что позволяет достигать более точных и надежных результатов в задачах, требующих интерпретации контекста и взаимосвязей между объектами. Такой подход открывает перспективы для создания интеллектуальных систем, способных не просто идентифицировать элементы на изображении, но и понимать их значение и роль в общей картине.
Интеграция ICON с большими языковыми моделями открывает перспективы для принципиально нового уровня взаимодействия человека и компьютера в сфере визуального поиска. Вместо традиционных запросов, основанных на ключевых словах или характеристиках, система сможет понимать сложные, сформулированные естественным языком вопросы о визуальном контенте. Например, запрос вроде «Найди фотографии людей, играющих в футбол на закате» будет обработан не как набор отдельных параметров, а как целостное описание желаемой сцены. Такой подход позволит пользователям взаимодействовать с визуальными данными интуитивно и эффективно, получая результаты, соответствующие их намерениям, а не только буквальному тексту запроса. Возможность понимания контекста и нюансов языка значительно расширяет функциональность систем визуального поиска, делая их более доступными и полезными для широкого круга пользователей.
Разработанная система ICON демонстрирует значительный прогресс в области визуального поиска, превосходя существующие модели, такие как ViPer, на ключевых датасетах CUHK-SYSU-TBPS (на 3.46 единиц mAP) и PRW-TBPS (на 0.93 единиц mAP). Этот результат свидетельствует о переходе от традиционных методов, основанных на простом сопоставлении признаков, к более сложным системам, способным к глубинному пониманию визуальной информации. Вместо того, чтобы просто находить объекты, похожие по внешним характеристикам, ICON анализирует сцену комплексно, что позволяет ей «понимать» контекст и взаимосвязи между объектами, открывая путь к созданию поисковых систем, способных к действительно интеллектуальному анализу визуального мира.
Представленная работа демонстрирует стремление к устранению избыточности в процессе поиска людей по текстовому описанию. Подход ICON, активно вмешиваясь в обучение, акцентирует внимание на причинно-следственных связях и нивелирует влияние предвзятостей, будь то геометрические, экологические или семантические. Этот метод, направленный на повышение надёжности и точности, воплощает философию, близкую к представлениям о ясности как милосердии. Как однажды заметил Пауль Эрдеш: «Математика — это искусство не думать». В данном исследовании, подобно математике, простота и элегантность достигаются путём удаления ненужных элементов, фокусируясь на сути семантического соответствия и причинности.
Что дальше?
Представленная работа, при всей своей направленности на устранение нежелательных смещений, лишь обозначает границы проблемы. Истинная причинность в текстах — иллюзия, тщательно конструируемая языком. Попытки вмешаться в процесс обучения, чтобы навязать «семантическую причинность», — это, по сути, наведение порядка в искусственном хаосе. Вопрос в том, не создаёт ли это новая, более изощрённая форма смещения, невидимая для текущих метрик.
Будущие исследования должны сместить фокус с поиска «правильных» ответов на понимание природы ошибок. Необходимо разработать инструменты, способные не просто выявлять смещения, но и оценивать их влияние на различные сценарии применения. Важнее не «устранить» смещение, а научиться предсказывать его проявление и учитывать в процессе принятия решений.
Очевидно, что простая интервенция в обучающий процесс — это лишь первый шаг. Перспективным направлением представляется разработка моделей, способных к самоанализу и самокоррекции, моделей, которые признают свою неполноту и стремятся к постоянному совершенствованию. Иначе, мы рискуем построить лишь более сложные и непрозрачные системы, которые продолжат воспроизводить наши собственные предубеждения.
Оригинал статьи: https://arxiv.org/pdf/2601.15931.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Лучшие смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Руководство по Stellaris — Полное прохождение на 100%
- Неважно, на что вы фотографируете!
2026-01-23 18:38