Автор: Денис Аветисян
Исследователи предложили инновационный подход к поиску людей по описанию, сочетающий в себе силу текстовых запросов и визуального анализа.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"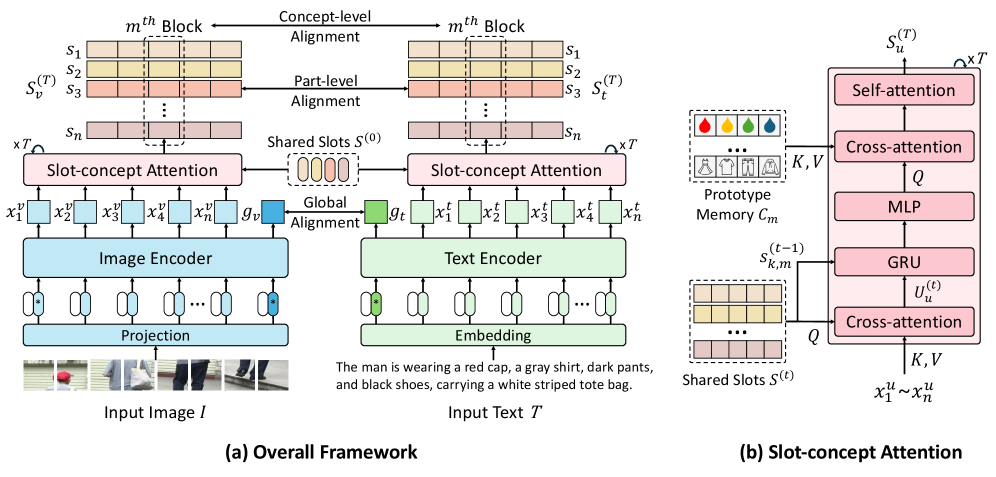
В статье представлена архитектура DiCo, использующая разделение визуальных и текстовых представлений на общие слоты и концептуальные блоки для повышения точности и интерпретируемости кросс-модального сопоставления.
Задача идентификации личности по текстовому описанию и изображению представляет собой сложную проблему из-за существенного расхождения между визуальными признаками и лингвистическим описанием. В данной работе, посвященной теме ‘Disentangled Concept Representation for Text-to-image Person Re-identification’, предлагается новый подход, основанный на разделении иерархических концептуальных представлений. Предложенный фреймворк DiCo обеспечивает более точную кросс-модальную согласованность за счет декомпозиции визуальных и текстовых данных на общие слоты и разделенные концептуальные блоки. Позволит ли подобный подход создать более интерпретируемые и эффективные системы идентификации личности в сложных условиях?
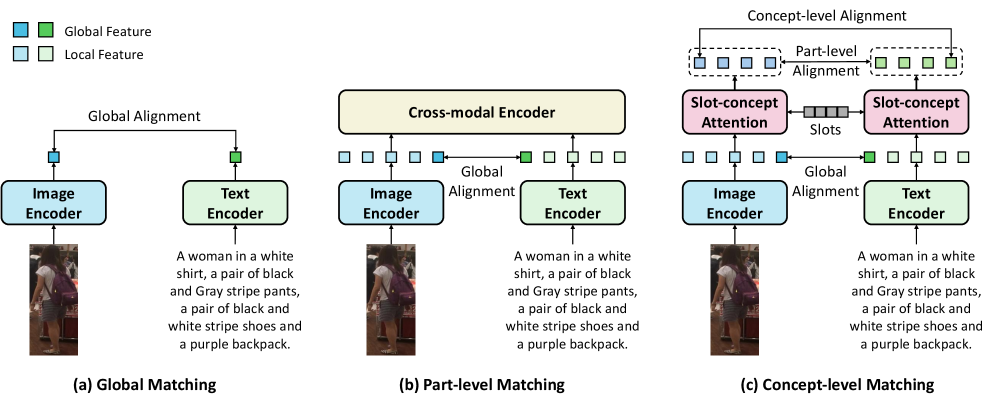
Задача семантического выравнивания в TIReID: вызов для исследователей
Традиционные системы идентификации изображений по текстовому запросу (TIReID) часто опираются на архитектуру двойных кодировщиков, однако сталкиваются с трудностями в понимании тонких семантических нюансов. Данные системы, кодируя изображения и текстовые описания в отдельные векторные представления, испытывают затруднения в установлении точной связи между визуальными деталями и лингвистическими характеристиками. В результате, способность к точному сопоставлению изображений с комплексными запросами, учитывающими едва заметные атрибуты, существенно ограничена. Это особенно заметно при поиске по сложным признакам, требующим детального анализа визуального контента и его сопоставления с семантическим значением текстового описания, что подчеркивает необходимость разработки более совершенных методов семантического выравнивания.
Существующие методы, такие как подходы, основанные на разложении изображения на части, и модели «зрение-язык» (VLMs), зачастую испытывают трудности при установлении чёткой связи между текстовыми описаниями и визуальными деталями. Несмотря на прогресс в обработке изображений и естественного языка, эффективное сопоставление текстовых атрибутов с конкретными областями на изображении остаётся сложной задачей. Это несоответствие приводит к неточностям при поиске изображений по сложным запросам, особенно когда требуется распознавание тонких характеристик и деталей. Например, VLM может правильно идентифицировать «человека в синей куртке», но не сможет точно указать, где именно на изображении находится эта куртка, или определить оттенок синего цвета. Подобные ограничения подчёркивают необходимость разработки более совершенных методов, способных обеспечить более глубокое и точное семантическое выравнивание между текстом и визуальными данными.
Неспособность установить прочную связь между текстовыми описаниями и визуальными деталями существенно ограничивает точность поиска изображений в системах TIReID. Особенно это проявляется при обработке сложных запросов, требующих учета множества характеристик, и при распознавании тонких атрибутов, которые легко упускаются из виду. Вследствие этого, даже незначительные неточности в понимании запроса могут привести к значительным ошибкам в результатах поиска, поскольку система не способна адекватно сопоставить семантическое содержание текста с мельчайшими визуальными особенностями изображения. Данная проблема становится критичной в сценариях, где требуется поиск по сложным критериям, например, определение личности по описанию одежды, аксессуаров и других специфических деталей.
DiCo: Разделенное представление концепций для TIReID
DiCo представляет собой новый подход к задаче TIReID (Text-to-Image Retrieval with Identity Discrimination), основанный на концепции разделенного представления (disentangled representation). В рамках данной структуры, визуальные признаки разделяются на отдельные, независимые компоненты, что позволяет более эффективно моделировать и сопоставлять изображения с текстовыми описаниями. Ключевой особенностью является обучение модели разделять информацию об идентичности объекта от других атрибутов, таких как поза, фон или аксессуары. Это достигается путем явного обучения представлений, которые кодируют семантически значимые концепции, что способствует более точному поиску и сопоставлению изображений по текстовым запросам.
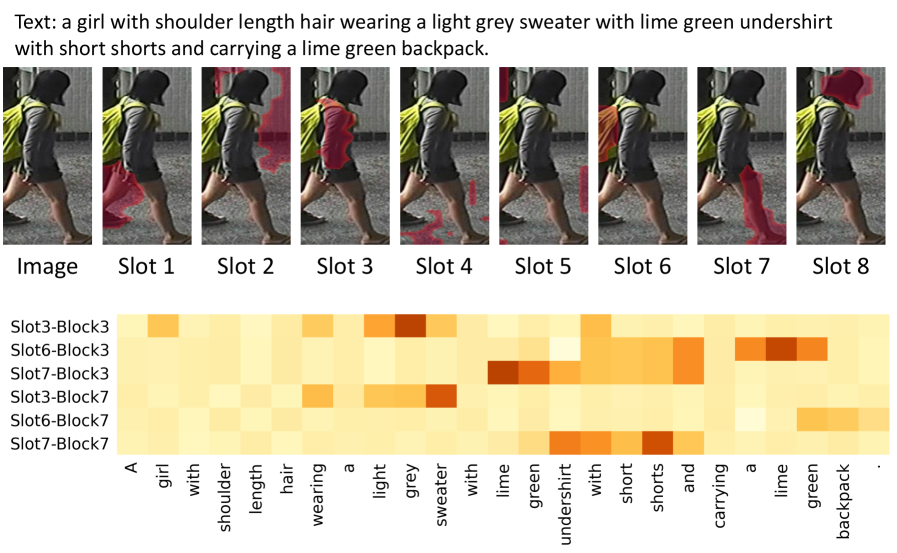
В основе DiCo лежит использование механизма Slot Attention для формирования объектно-ориентированных представлений. Slot Attention позволяет идентифицировать и выделить отдельные объекты на изображении, формируя для каждого из них векторное представление — слот. В DiCo этот подход расширен для обучения концепциям более высокого уровня. Вместо прямого сопоставления изображения и текста, Slot Attention позволяет выделить ключевые объекты, а затем уже строить связи между этими объектами и текстовыми описаниями, что способствует более точному и детализированному представлению концепций и улучшает качество идентификации в задачах TIReID. Это позволяет модели фокусироваться на значимых визуальных элементах и их взаимосвязях, а не на общем контексте изображения.
В рамках DiCo для эффективного преодоления разрыва между визуальными и текстовыми данными используется обучение с разделением на части и концепции. Система изучает общие слоты (Shared Slots), представляющие собой якоря для отдельных частей объекта, и концептуальные блоки (Concept Blocks), которые отвечают за отдельные концепции, связанные с этими частями. Такой подход позволяет модели выделять и представлять информацию об объекте на основе его составных частей и соответствующих концепций, что улучшает точность сопоставления визуальных и текстовых представлений. Фактически, общие слоты обеспечивают базовое представление частей объекта, а концептуальные блоки позволяют моделировать более сложные и абстрактные характеристики, связанные с этими частями.
![Визуализация t-SNE[55] встраиваний блоков концепций демонстрирует, что DiCo формирует специализированные и семантически разнообразные представления, поскольку кластеры, соответствующие различным блокам, остаются чётко разграниченными в пространстве встраиваний.](https://arxiv.org/html/2601.10053v1/x5.png)
Обучение разделенным представлениям с помощью DiCo
Механизм Slot-Concept Attention, используемый в DiCo, обеспечивает совместное обучение «якорных точек» для отдельных частей объекта и «разъединенных блоков» для семантических концепций. Этот процесс предполагает, что каждая часть объекта привязывается к определенной концепции, что позволяет модели устанавливать связи между визуальными элементами и их значениями. Совместное обучение позволяет добиться семантической согласованности, гарантируя, что представления частей объекта и связанных с ними концепций соответствуют друг другу. Это достигается путем минимизации расстояния между представлениями частей, принадлежащих одной концепции, и максимизации расстояния между представлениями частей, относящихся к разным концепциям, что способствует формированию четких и различимых семантических категорий.
Процесс обучения в DiCo направляется ограничениями реконструкции и многоуровневой контрастивной функцией потерь, оптимизирующей согласованность на глобальном, уровне частей и уровне концепций. Ограничения реконструкции обеспечивают, что декодированные представления точно воссоздают входные данные, что способствует сохранению информации. Многоуровневая контрастивная функция потерь, в свою очередь, максимизирует сходство между представлениями на разных уровнях детализации: глобальном (весь объект), уровне частей (отдельные компоненты объекта) и уровне концепций (семантические атрибуты). Это позволяет модели изучать более структурированные и интерпретируемые представления, улучшая ее способность к обобщению и рассуждениям.
Память прототипов в DiCo служит для повышения способности модели к представлению и рассуждению о семантических концепциях, что, в свою очередь, улучшает точность поиска. В процессе обучения, для каждого семантического концепта формируется прототип — векторное представление, аккумулирующее информацию о различных экземплярах этого концепта. При поиске, входные данные сравниваются с этими прототипами, что позволяет эффективно идентифицировать наиболее релевантные концепты и, как следствие, повысить точность извлечения информации. Использование памяти прототипов позволяет модели обобщать знания о концептах и эффективно работать с новыми, ранее не встречавшимися экземплярами.
Проверка DiCo: Результаты на стандартных эталонах
В ходе тестирования на авторитетных наборах данных, таких как CUHK-PEDES и ICFG-PEDES, разработанная система DiCo продемонстрировала передовые результаты, значительно превосходя существующие аналоги. Достигнутое качество распознавания пешеходов подтверждает эффективность предложенного подхода к разделению признаков, позволяя DiCo выделять наиболее релевантные характеристики и обеспечивать высокую точность идентификации в различных условиях. Полученные показатели свидетельствуют о существенном прогрессе в области TIReID и открывают новые возможности для применения в системах видеонаблюдения и автоматического анализа видеопотока.
Результаты тестирования разработанной системы на общепринятых наборах данных демонстрируют её высокую эффективность в задаче идентификации пешеходов. В частности, на CUHK-PEDES система достигает показателя Recall@1 в 77.21%, что означает, что в 77.21% случаев правильный вариант идентификации находится среди первых предложенных системой. Аналогичные результаты на наборах данных ICFG-PEDES и RSTPReid составили 67.81% и 67.84% соответственно, подтверждая стабильность и надежность алгоритма в различных условиях и при обработке разных наборов изображений пешеходов. Эти показатели свидетельствуют о значительном прогрессе в области идентификации людей по видеоданным.
Исследования показали, что DiCo демонстрирует высокую устойчивость в задачах идентификации пешеходов на наборе данных CUHK-PEDES, достигая показателя Recall@5 в 91.85% и Recall@10 в 95.63%. Эти результаты указывают на то, что система способна эффективно находить релевантные совпадения даже при различных уровнях строгости поиска — то есть, когда требуется отображать как 5, так и 10 наиболее вероятных кандидатов. Высокие показатели на разных порогах отбора подтверждают надежность и точность системы DiCo в задачах идентификации и отслеживания пешеходов, что особенно важно для приложений, требующих высокой степени уверенности в результатах.
Полученные результаты подтверждают, что разработанный подход DiCo, основанный на разделении представлений, эффективно решает проблемы, ограничивающие предыдущие методы идентификации пешеходов (TIReID). Благодаря разделению характеристик, DiCo способен более точно выделять и анализировать ключевые признаки, отвечающие за индивидуальность каждого пешехода, даже в сложных условиях, таких как изменения освещения или позы. Это позволяет значительно повысить точность идентификации и снизить количество ложных срабатываний, обеспечивая более надежную работу системы в реальных сценариях. Достигнутые показатели на стандартных наборах данных, таких как CUHK-PEDES и ICFG-PEDES, демонстрируют превосходство DiCo над существующими решениями и подтверждают перспективность данного подхода для дальнейших исследований в области компьютерного зрения.
Перспективы развития: К более надежному и интерпретируемому TIReID
Архитектура DiCo демонстрирует значительный потенциал за пределами задачи идентификации людей по видео, предлагая гибкую основу для решения широкого спектра задач, объединяющих зрение и язык. Благодаря своей способности эффективно сопоставлять визуальные и текстовые данные, эта модель может быть адаптирована для таких приложений, как визуальный вопрос-ответ, генерация описаний изображений и даже сложные сценарии взаимодействия человека с компьютером, где требуется понимание как визуальной информации, так и естественного языка. Универсальность DiCo заключается в возможности масштабирования и повторного использования его компонентов, что делает его ценным инструментом для развития исследований в области мультимодального искусственного интеллекта и открывает перспективы для создания более интеллектуальных и адаптивных систем.
Дальнейшие исследования в области TIReID могут быть направлены на интеграцию более сложных представлений знаний и механизмов рассуждений в существующую архитектуру. В частности, перспективным направлением является использование графов знаний для кодирования семантических связей между объектами и атрибутами, что позволит системе не просто идентифицировать личность, но и понимать контекст и намерения. Кроме того, разработка алгоритмов, способных к логическому выводу и абстрактному мышлению, позволит улучшить способность системы к обобщению и адаптации к новым, ранее не встречавшимся ситуациям. Такой подход позволит создать системы идентификации, которые не просто распознают людей, но и понимают их действия и мотивы, открывая новые возможности для применения в областях безопасности, робототехники и анализа поведения.
Использование мощных базовых моделей, таких как CLIP ViT-L, позволяет DiCo создавать более надежные и понятные представления данных, что открывает новые возможности для применения в различных областях. В частности, это значительно улучшает точность систем видеонаблюдения, позволяя более эффективно идентифицировать объекты и отслеживать их перемещения. Кроме того, подобные технологии способствуют развитию интуитивно понятных интерфейсов взаимодействия человека и компьютера, где системы могут понимать и реагировать на визуальные сигналы более осмысленно, приближая нас к созданию действительно интеллектуальных помощников.
Исследование представляет собой элегантное применение принципов декомпозиции к задаче идентификации личности по тексту и изображению. Авторы, подобно математикам, стремящимся к доказательству, а не к эмпирической проверке, разлагают визуальные и текстовые представления на общие слоты и отдельные концептуальные блоки. Это позволяет достичь более точной и интерпретируемой кросс-модальной адаптации, что особенно ценно в контексте vision-language моделей. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен служить людям, а не наоборот». В данном случае, дискомпозиция представлений служит именно этой цели — повышению надежности и понятности системы идентификации.
Куда Далее?
Представленный подход, хоть и демонстрирует обнадеживающие результаты в задаче идентификации личности по текстовому описанию и изображению, всё же не решает фундаментальную проблему: истинное понимание концепций. Разложение визуальных и текстовых представлений на «слоты» и «блоки концепций» — это лишь математическое удобство, а не гарантия семантической непротиворечивости. До тех пор, пока алгоритм не сможет доказать, что концепция «красный шарф» действительно соответствует определённому участку изображения, а не является случайным совпадением, он останется лишь сложным сопоставителем признаков.
Будущие исследования, вероятно, будут сосредоточены на создании более строгих метрик для оценки «распакованности» представлений. Недостаточно просто добиться высокой точности; необходимо продемонстрировать, что алгоритм действительно выделяет значимые, независимые концепции. Интересным направлением представляется исследование возможности использования формальных методов верификации для доказательства корректности алгоритмов vision-language моделей. Ведь элегантность решения заключается не в количестве параметров, а в его математической чистоте.
В конечном счете, задача не в том, чтобы научить машину «видеть» и «понимать», а в том, чтобы построить систему, способную к логическому выводу на основе формально определенных концепций. И пока алгоритм не сможет отличить истинное знание от статистической случайности, он останется лишь сложным инструментом, а не искусственным интеллектом в полном смысле этого слова.
Оригинал статьи: https://arxiv.org/pdf/2601.10053.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- vivo V70 ОБЗОР: современный дизайн, портретная/зум камера, высокая автономность
2026-01-19 01:45