Автор: Денис Аветисян
Новое исследование раскрывает взаимосвязь между точностью, разреженностью и интерпретируемостью моделей, использующих концептуальные узкие места для представления данных.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"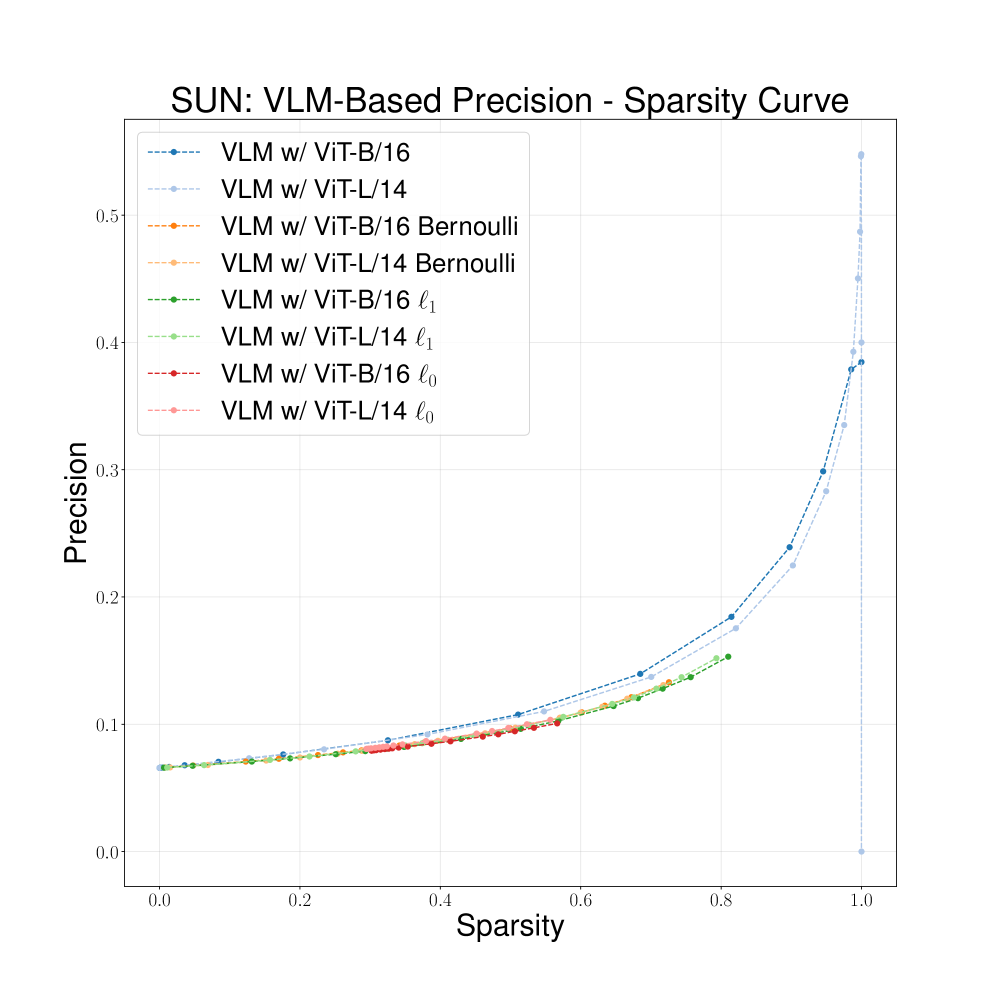
Предлагается метрика ‘ясность’ для оценки интерпретируемости концептуальных моделей, демонстрирующая компромисс между гибкостью модели, разреженностью и точностью предсказаний атрибутов.
Несмотря на широкое распространение моделей «зрение-язык», их интерпретируемость остается серьезной проблемой, часто игнорируемой при оценке эффективности. В данной работе, озаглавленной ‘Clarity: The Flexibility-Interpretability Trade-Off in Sparsity-aware Concept Bottleneck Models’, исследуется влияние различных проектных решений на формирующиеся представления в концептуальных моделях-узких местах. Предлагается метрика «ясность», количественно оценивающая взаимосвязь между производительностью, разреженностью и точностью концептуальных представлений, и демонстрируется, что высокая производительность не гарантирует интерпретируемость. Возможно ли разработать методы, позволяющие эффективно находить баланс между гибкостью модели и ее способностью к понятной интерпретации?
Тёмный лес интерпретируемости: Почему нейросети молчат
Несмотря на впечатляющую способность глубоких нейронных сетей решать сложные задачи, их внутренняя работа часто остается непрозрачной и непонятной. Эти модели, функционирующие как своеобразные “черные ящики”, принимают решения, механизм которых трудно отследить или объяснить. В отличие от традиционных алгоритмов, где логика каждого шага ясна, глубокое обучение оперирует сложными многослойными преобразованиями данных, делая проблематичным понимание того, какие факторы и каким образом влияют на конечный результат. Эта непрозрачность вызывает серьезные затруднения в областях, требующих обоснования решений, таких как медицина или финансы, и препятствует дальнейшему совершенствованию и надежности этих мощных инструментов.
Отсутствие прозрачности в работе глубоких нейронных сетей существенно снижает уровень доверия к ним, особенно в критически важных областях применения. Невозможность понять, на каких основаниях модель принимает решения, затрудняет выявление и исправление ошибок, а также ограничивает возможности её дальнейшей оптимизации и совершенствования. В ситуациях, когда требуется не просто результат, но и объяснение, например, в медицине или финансах, непрозрачность становится серьезным препятствием для внедрения этих мощных технологий. Эффективная диагностика и точная настройка моделей оказываются затруднены, что замедляет прогресс и ограничивает потенциал глубокого обучения.
Одной из ключевых сложностей в понимании работы глубоких нейронных сетей является определение концепций, на которые опирается модель при принятии решений. Исследователи сталкиваются с задачей не просто получить точный прогноз, но и выяснить, какие признаки или паттерны в данных модель считает наиболее важными для этого прогноза. Это требует разработки методов, способных «заглянуть внутрь» модели и выявить, какие абстрактные понятия она формирует в процессе обучения. Например, при анализе изображения кошки, модель может основываться на распознавании ушей, усов или определенного типа шерсти, а не на целостном восприятии животного. Идентификация этих концепций имеет решающее значение для повышения доверия к модели, выявления потенциальных ошибок и обеспечения возможности ее эффективной модификации и улучшения.
Концептуальные узкие места: Принуждение к понятности
Концептуальные модели узкого места (Concept Bottleneck Models) представляют собой подход к созданию интерпретируемого искусственного интеллекта, основанный на принуждении модели к представлению данных через ограниченный набор понятных человеку концепций. Вместо того, чтобы модель напрямую отображала входные данные в выходные, она вынуждена сначала закодировать данные в виде набора атрибутов, представляющих эти концепции. Это обеспечивает возможность проверки логики принятия решений моделью на уровне этих понятных атрибутов, делая процесс более прозрачным и понятным для человека. Фактически, модель должна “объяснить” свои выводы, используя эти заранее определенные концепции, что позволяет оценить, насколько адекватно модель понимает и использует информацию.
В концептуальных моделях с узким местом (Concept Bottleneck Models) введение ограничивающего слоя направлено на создание разреженного и осмысленного представления данных. Этот слой, как правило, имеет значительно меньшую размерность, чем входные данные, что вынуждает модель сжимать информацию, выделяя наиболее релевантные признаки. Разреженность достигается за счет применения регуляризации, например, L1-нормализации, к активациям этого слоя, что приводит к установке многих значений в ноль. В результате, модель обучается представлять входные данные в виде комбинации небольшого числа активных концептов, что облегчает интерпретацию и анализ ее работы. Такой подход позволяет отбросить несущественные детали и сконцентрироваться на ключевых характеристиках входных данных, формируя более компактное и понятное представление.
Эффективность моделей с концептуальным «узким местом» напрямую зависит от точности предсказания наличия заданных концептов на основе входных данных. Методы предсказания атрибутов (Attribute Prediction) используются для обучения модели сопоставлять входные признаки с вероятностью активации конкретного концепта. Высокая точность предсказания обеспечивает эффективное кодирование входных данных в разреженное представление, основанное на человеко-понятных концептах, что позволяет модели принимать решения на основе интерпретируемых факторов. Неточное предсказание приводит к потере информации и снижению эффективности как интерпретируемости, так и производительности модели.

Разреженность как искусство: Регуляризация и вероятностный выбор
Методы, ориентированные на разреженность (sparsity-aware methods), играют важную роль в создании компактных и интерпретируемых представлений концепций. Разреженность, подразумевающая наличие большого количества нулевых или близких к нулю значений в векторном представлении, позволяет уменьшить размер модели и снизить вычислительную сложность. Кроме того, отбор только наиболее значимых концепций упрощает понимание логики работы модели и повышает её объяснимость. В контексте машинного обучения, разреженные представления особенно полезны при работе с высокоразмерными данными, где большинство признаков могут быть нерелевантными или избыточными, что позволяет выделить ключевые факторы, определяющие результат.
Методы ℓ_0 и ℓ_1 регуляризации широко используются для достижения разреженности в моделях машинного обучения. ℓ_0 регуляризация напрямую штрафует количество ненулевых параметров, эффективно отбирая лишь наиболее значимые концепты, однако ее оптимизация является NP-трудной задачей. В отличие от нее, ℓ_1 регуляризация, также известная как LASSO, заменяет ℓ_0 норму на сумму абсолютных значений параметров, что обеспечивает выпуклость функции потерь и позволяет использовать эффективные алгоритмы оптимизации, такие как градиентный спуск. Оба подхода способствуют созданию более компактных и интерпретируемых моделей, уменьшая переобучение и повышая обобщающую способность за счет исключения из рассмотрения нерелевантных признаков или концепций.
Вероятностные методы, использующие распределение Бернулли и его непрерывную релаксацию — распределение Hard Concrete, обеспечивают возможность оптимизации разреженности с помощью градиентных методов. Распределение Бернулли, принимающее значения 0 или 1, напрямую моделирует бинарный выбор концепции (включение или исключение). Однако, для обеспечения дифференцируемости и совместимости с алгоритмами градиентного спуска, применяется релаксация Hard Concrete, которая аппроксимирует дискретное распределение Бернулли непрерывным распределением. Это позволяет вычислять градиенты через процесс семплирования и использовать стандартные методы оптимизации для обучения разреженных представлений. p(x=1) = \sigma(logits) , где σ — сигмоидная функция, а logits — логиты, определяющие вероятность выбора концепции.

Ясность как компас: Новый взгляд на интерпретируемость
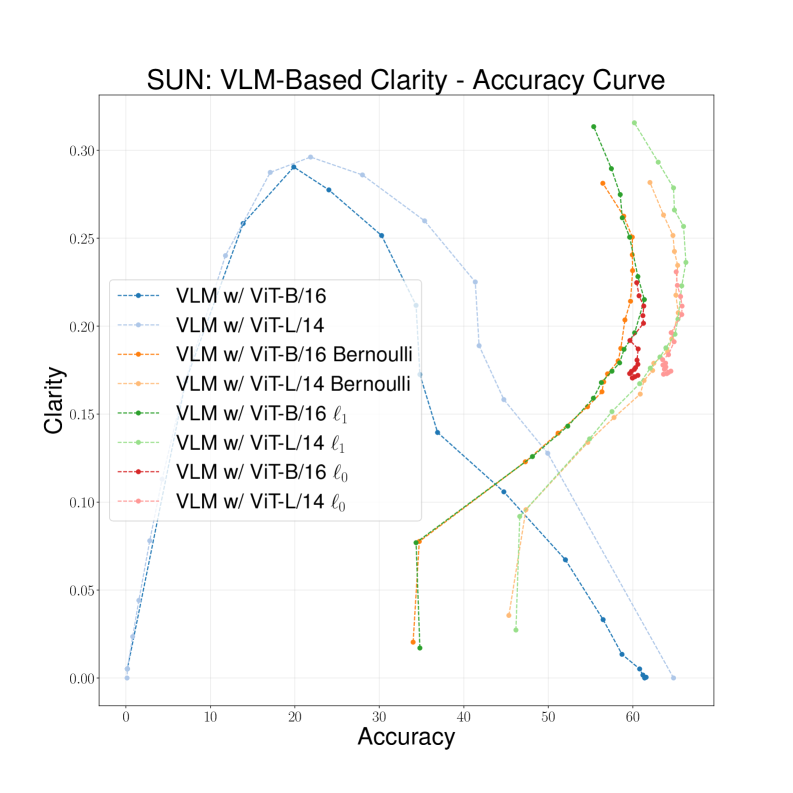
В настоящее время, оценка интерпретируемости моделей машинного обучения представляет собой сложную задачу. Для решения этой проблемы предложена новая метрика — “Ясность” (Clarity), объединяющая три ключевых аспекта: разреженность (Sparsity), точность концептов (Concept Precision) и эффективность на целевой задаче (Downstream Task Performance). Данная метрика рассчитывается с использованием среднего гармонического \frac{3}{\frac{1}{Sparsity} + \frac{1}{Concept\,Precision} + \frac{1}{Downstream\,Task\,Performance}}, что обеспечивает сбалансированную оценку. Высокое значение “Ясности” свидетельствует о том, что модель не только точно выполняет поставленную задачу, но и делает это лаконичным и понятным образом, используя минимальное количество параметров и четко определяемые концепты.
Метрика «Ясность» (Clarity) вычисляется с использованием гармонического среднего, что обеспечивает сбалансированную оценку интерпретируемости модели. В отличие от простых показателей, оценивающих только один аспект, например, разреженность или точность, «Ясность» штрафует модели, демонстрирующие превосходство лишь в одной области, игнорируя другие. F_1 = 2 <i> (Precision </i> Recall) / (Precision + Recall) — подобно гармоническому среднему, эта метрика гарантирует, что высокая оценка достигается только при одновременном достижении хороших результатов во всех ключевых аспектах интерпретируемости. Таким образом, «Ясность» предоставляет более надежный и всесторонний инструмент для оценки способности модели к объяснению своих решений, что особенно важно в областях, требующих прозрачности и доверия.
Высокая «Ясность» модели, как новый показатель, свидетельствует о её способности к лаконичному представлению информации и одновременно — к точным прогнозам. Исследования показали, что достижение высокой точности классификации не всегда гарантирует и высокую «Ясность», что подчеркивает необходимость использования данного показателя для всесторонней оценки интерпретируемости моделей.

В статье рассматривается метрика ‘clarity’ для оценки интерпретируемости концептуальных моделей. Авторы демонстрируют, что высокая производительность модели не гарантирует понятность её внутренних представлений. Это, конечно, не новость. Как гласит известная фраза Барбары Лисков: «Хороший дизайн — это не просто элегантность, а предвидение того, как система будет меняться». В данном случае, стремление к гибкости и разреженности неизбежно приводит к компромиссам в интерпретируемости, что лишь подтверждает, что любая революционная идея рано или поздно превращается в технический долг. Особенно учитывая, что в погоне за точностью, тесты чаще всего проверяют лишь то, что модель не сломалась, но никак не то, что она действительно понимает.
Что дальше?
Представленная работа, как и большинство попыток обуздать искусственный интеллект, лишь аккуратно подсветила проблему, а не решила её. Показанный компромисс между гибкостью модели, разреженностью и точностью предсказаний атрибутов — закономерность, которую опытный инженер предвидел заранее. Высокая производительность на тестовом наборе данных никогда не гарантировала, что модель действительно «понимает» что-либо, а лишь демонстрирует умение находить статистические закономерности. Если система стабильно выдаёт неверные ответы, по крайней мере, она последовательна.
Будущие исследования, вероятно, сосредоточатся на более изощрённых метриках «ясности», пытаясь отделить истинную интерпретируемость от простого совпадения. Но стоит помнить: любая метрика — это лишь прокси, и всегда найдётся способ её обмануть. Мы не пишем код — мы оставляем комментарии будущим археологам, которые будут гадать, что мы имели в виду.
В конечном итоге, «cloud-native» или «sparsification» — это лишь слова, прикрывающие тот факт, что каждый новый уровень абстракции добавляет ещё один слой потенциальных проблем. Возможно, пора признать, что идеальной, полностью интерпретируемой модели не существует, и сосредоточиться на разработке инструментов, позволяющих хотя бы частично понимать её поведение — даже если это означает признание неизбежной ошибки.
Оригинал статьи: https://arxiv.org/pdf/2601.21944.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Как сбросить приложение безопасности Windows, чтобы устранить проблемы в Windows 11 и 10
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Нефть вниз, инфляция под контролем: что ждет российский рынок в апреле? (14.03.2026 04:32)
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- vivo Y05 ОБЗОР: удобный сенсор отпечатков, плавный интерфейс, яркий экран
- HP Omen 16-ap0091ng ОБЗОР
- Motorola Moto G67 Power ОБЗОР: яркий экран, плавный интерфейс, удобный сенсор отпечатков
2026-02-01 21:29