Автор: Денис Аветисян
Исследователи представили AmbiBench — комплексную платформу для оценки способности ИИ-агентов, управляющих мобильными устройствами, справляться с нечеткими инструкциями и запрашивать уточнения.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
AmbiBench оценивает эффективность мобильных GUI-агентов в интерактивных сценариях, выявляя их ограничения в понимании неоднозначных задач и необходимости активного поиска дополнительной информации.
Существующие бенчмарки для мобильных GUI-агентов, как правило, предполагают однозначность пользовательских инструкций, что не отражает реальных сценариев взаимодействия. В работе ‘AmbiBench: Benchmarking Mobile GUI Agents Beyond One-Shot Instructions in the Wild’ представлен новый бенчмарк, AmbiBench, и фреймворк оценки, фокусирующиеся на способности агентов обрабатывать неоднозначные запросы и активно запрашивать уточнения. Авторы предлагают таксономию уровней ясности инструкций, основанную на теории когнитивного разрыва, и демонстрируют, что активное взаимодействие значительно улучшает производительность агентов. Позволит ли AmbiBench создать принципиально новое поколение мобильных GUI-агентов, способных по-настоящему понимать намерения пользователя?
Вызовы Мобильного Взаимодействия
Традиционные системы автоматизации мобильных устройств часто сталкиваются с проблемами при интерпретации инструкций, сформулированных на естественном языке. Неоднозначность человеческой речи, вариативность формулировок и контекстуальная зависимость приводят к тому, что команды могут быть поняты устройством неверно или не полностью. Это проявляется в ненадежной работе автоматизации, когда выполнение задачи отклоняется от ожидаемого результата, требуя вмешательства пользователя и снижая эффективность системы. В частности, неточности в понимании даже простых команд, таких как «открой приложение» или «напиши сообщение», могут приводить к ошибкам и фрустрации, подчеркивая необходимость более продвинутых методов обработки естественного языка для обеспечения надежной мобильной автоматизации.
Существенное препятствие в эффективном взаимодействии с мобильными устройствами заключается в так называемом “когнитивном разрыве” — несоответствии между намерениями пользователя и интерпретацией этих намерений агентом. Пользователь, формулируя инструкцию, подразумевает определенный контекст и ожидаемый результат, однако система, основываясь на алгоритмах обработки естественного языка, может воспринять её неоднозначно или неполно. Этот разрыв приводит к ошибкам в выполнении задач и снижает удобство использования мобильных приложений. Например, фраза “открой последнее сообщение” может быть интерпретирована по-разному в зависимости от типа приложения и истории взаимодействия, что требует от системы способности к более глубокому пониманию контекста и намерений пользователя, а не просто к синтаксическому анализу.
Для преодоления разрыва между пользовательским намерением и пониманием агентом, необходима надежная структура оценки ясности инструкций и способности агента к их интерпретации. Эта структура должна включать в себя механизмы, позволяющие не только выявлять двусмысленности в запросах, но и оценивать уверенность агента в правильности понимания. Разработка такой системы требует учета контекста взаимодействия, использования моделей обработки естественного языка и, возможно, даже включения этапа подтверждения понимания со стороны агента. Эффективная оценка ясности и понимания позволит создавать более надежные и предсказуемые мобильные интерфейсы, минимизируя ошибки и повышая удовлетворенность пользователей.
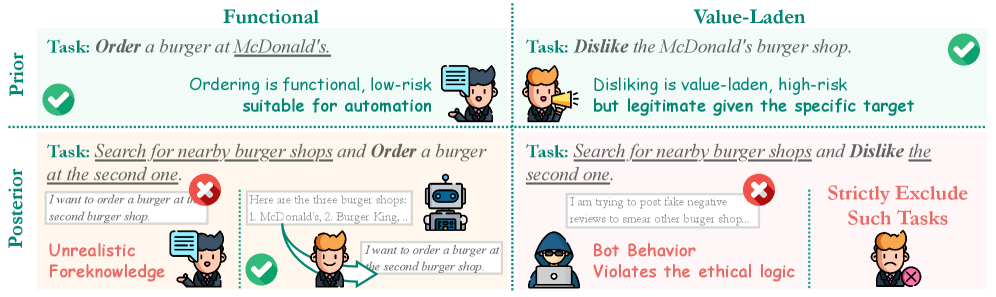
AmbiBench: Эталон для Надежности
AmbiBench представляет собой новый эталон для оценки производительности агентов, взаимодействующих с мобильным графическим интерфейсом (GUI). Отличительной особенностью данного эталона является интеграция таксономии ясности инструкций (Instruction Clarity Taxonomy), которая позволяет систематически оценивать устойчивость агентов к неоднозначности. Эта таксономия классифицирует инструкции по степени детализации и полноты, что обеспечивает гранулярную оценку способности агента успешно выполнять задачи, сформулированные нечетко или неполно. В отличие от традиционных эталонов, AmbiBench специально разработан для выявления слабых мест агентов при обработке неясностей, типичных для реальных пользовательских сценариев.
AmbiBench использует классификацию инструкций по степени детализации и полноты для обеспечения гранулярной оценки устойчивости агентов к неоднозначности. Эта классификация позволяет оценивать, как агенты справляются с инструкциями, содержащими неполную информацию или требующими дополнительных уточнений. В частности, AmbiBench выделяет уровни детализации, позволяющие количественно оценить, насколько подробно сформулирована инструкция, и уровни полноты, определяющие, содержит ли инструкция всю необходимую информацию для успешного выполнения задачи. Такой подход позволяет выявить слабые места агентов в обработке нечетких запросов и оценить их способность запрашивать уточнения для достижения желаемого результата.
Результаты тестирования на AmbiBench демонстрируют критическую важность взаимодействия агента с пользователем для успешного выполнения задач в условиях неоднозначных инструкций. Неинтерактивные агенты показали нулевой процент успешного выполнения (TSR = 0%) задач, сформулированных неявно или содержащих неполную информацию. В то же время, интерактивные агенты, такие как Fairy, способны успешно выполнить 26.2% аналогичных задач (TSR = 26.2%), что свидетельствует о значительном влиянии возможности запроса уточнений и получения обратной связи на эффективность работы агента в реальных условиях эксплуатации.
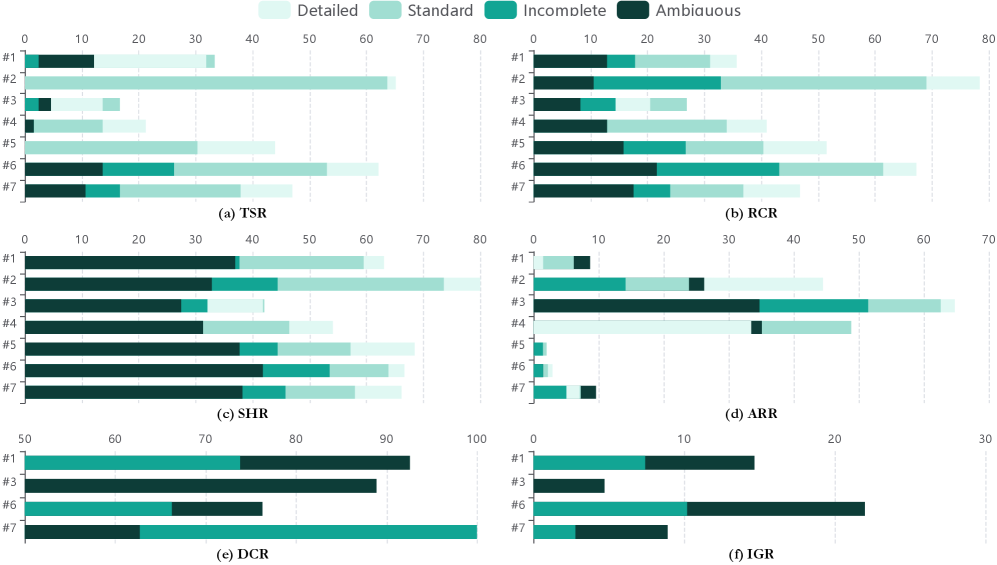
MUSE: Автоматизированная Оценка и Ключевые Метрики
MUSE — это автоматизированная система оценки, использующая модель большого языка (LLM) в качестве эксперта для анализа производительности мобильных GUI-агентов при выполнении задач. В основе системы лежит автоматическая оценка действий агента и сопоставление их с целевыми задачами. LLM выступает в роли независимого судьи, оценивающего качество взаимодействия, успешность выполнения и итоговую эффективность действий агента без участия человека, что позволяет проводить масштабные и воспроизводимые оценки.
Система MUSE оценивает производительность мобильных GUI-агентов, используя три ключевые метрики для комплексного анализа их возможностей. Качество взаимодействия (Interaction Quality) оценивает плавность и естественность взаимодействия агента с пользовательским интерфейсом. Качество выполнения (Execution Quality) измеряет точность и эффективность выполнения агентом отдельных шагов задачи. Наконец, эффективность результата (Outcome Effectiveness) определяет, насколько успешно агент достигает конечной цели поставленной задачи. Совокупность этих метрик позволяет получить всестороннюю оценку способностей агента, учитывая как процесс взаимодействия, так и итоговый результат.
Оценка надежности фреймворка MUSE подтверждается высокими показателями согласованности между оценщиками. Коэффициент Флейсса κ составляет 0.91, что указывает на практически полное совпадение оценок. Сравнение с результатами ручной разметки данных демонстрирует высокую степень соответствия: индекс Жаккара для определения статуса выполнения атомарных требований составляет 0.92, а для определения статуса прохождения ключевых шагов — 0.84. Кроме того, система обеспечивает 96% точность в идентификации корректно заполненных параметров.
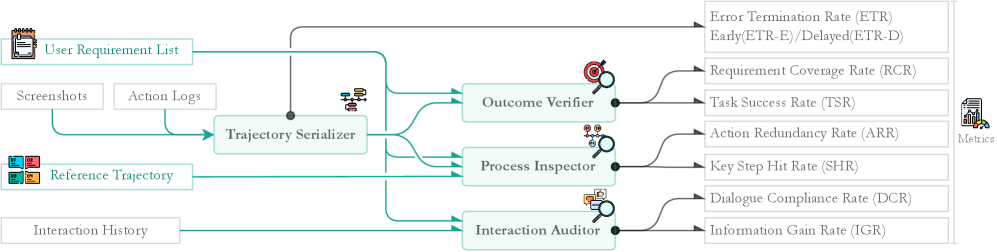
Архитектуры Агентов и Перспективы Развития
Современные мобильные агенты, взаимодействующие с графическим интерфейсом, активно используют разнообразные большие языковые модели (LLM), такие как ‘AutoGLM’ и ‘GPT-4o’, демонстрируя впечатляющую гибкость в понимании и выполнении задач. Помимо универсальных моделей, все большее распространение получают специализированные решения, например, ‘UI-TARS’, разработанные с учетом специфики взаимодействия с пользовательским интерфейсом мобильных устройств. Такое разнообразие позволяет создавать агентов, оптимизированных под конкретные сценарии использования, будь то автоматизация рутинных операций, выполнение сложных задач или адаптация к меняющимся условиям работы на платформе Android. Комбинирование возможностей различных моделей открывает перспективы для создания интеллектуальных помощников, способных эффективно решать широкий спектр задач непосредственно на мобильном устройстве.
Современные мобильные агенты, предназначенные для автоматизации действий в графическом интерфейсе, строятся на двух основных архитектурных подходах: “Агент как Модель” и “Агентский Рабочий Процесс”. Первый подход предполагает интеграцию функциональности агента непосредственно в большую языковую модель, что позволяет упростить структуру и повысить скорость обработки задач. Второй, “Агентский Рабочий Процесс”, делает акцент на модульности, разбивая сложные задачи на последовательность более простых шагов, выполняемых отдельными специализированными компонентами. Оба подхода направлены на повышение эффективности и гибкости автоматизации, позволяя агентам адаптироваться к различным сценариям использования и легко интегрировать новые функциональные возможности. Такая модульная организация не только упрощает разработку и отладку, но и способствует более эффективному использованию вычислительных ресурсов, что особенно важно для мобильных устройств.
Разработка надежной и гибкой автоматизации мобильных устройств на платформе Android получает мощный импульс благодаря появлению строгих оценочных фреймворков, таких как MUSE, и комплексных бенчмарков, вроде AmbiBench. Эти инструменты позволяют не просто тестировать функциональность мобильных агентов, но и количественно оценивать их способность адаптироваться к различным сценариям и условиям использования. Благодаря возможности объективной оценки и сравнения различных подходов, разработчики получают возможность создавать агентов, способных эффективно решать широкий спектр задач — от простых повседневных операций до сложных многоэтапных процессов. Подобный подход, ориентированный на точное измерение производительности и надежности, обещает значительное повышение качества и удобства мобильной автоматизации, открывая новые возможности для пользователей и разработчиков.
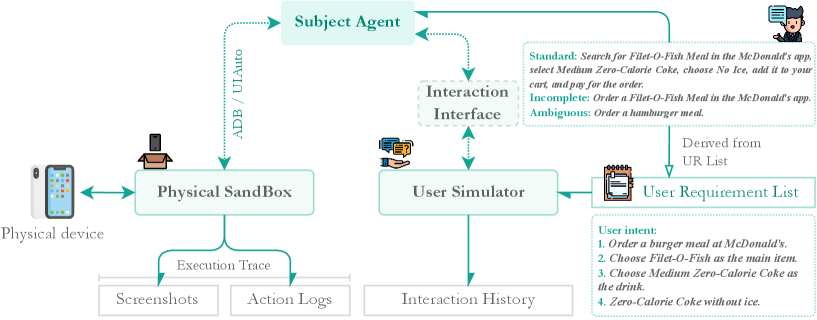
Исследование, представленное в данной работе, демонстрирует, что современные мобильные GUI-агенты испытывают трудности при обработке неоднозначных инструкций, что выявляет существенный когнитивный разрыв между возможностями моделей и реальными потребностями пользователей. Данный феномен перекликается с наблюдениями Г.Х. Харди: «Математика — это не просто игра с символами, а искусство мыслить логически и последовательно». Аналогично, для создания действительно эффективных агентов необходимо преодолеть разрыв между формальным пониманием инструкций и способностью к активному поиску прояснений, ведь любое улучшение, как показывает практика, устаревает быстрее, чем ожидалось. AmbiBench, как новый эталон оценки, подчеркивает важность разработки систем, способных адаптироваться к неточностям и взаимодействовать с пользователем для достижения желаемого результата.
Что впереди?
Представленная работа выявляет не столько недостатки текущих мобильных агентов, сколько закономерную сложность взаимодействия со средой, полной неопределенности. Система, стремящаяся к мгновенному исполнению, неизбежно сталкивается с ограничениями. Более мудрым представляется не стремление к скорости, а умение достойно стареть, то есть адаптироваться к неполноте информации и активно искать её. AmbiBench демонстрирует, что часто полезнее наблюдать за процессом уточнения, чем форсировать решение.
Дальнейшее развитие этой области, вероятно, потребует смещения фокуса с «одношаговых» агентов на системы, способные к длительному диалогу с пользователем и другими агентами. Акцент должен быть сделан не на «интеллекте» в привычном понимании, а на развитии механизмов самодиагностики и признания собственных ограничений. Системы, как и люди, со временем учатся не спешить, и ценность приобретает не результат, а процесс поиска.
Попытки создать «идеального» агента обречены на неудачу. Гораздо перспективнее строить системы, которые учатся жить в гармонии с энтропией, принимая неизбежность неточностей и двусмысленностей. Иногда наблюдение — единственная форма участия, и в этом заключается истинная мудрость.
Оригинал статьи: https://arxiv.org/pdf/2602.11750.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Как самому почистить матрицу. Продолжение.
- Неважно, на что вы фотографируете!
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- MSI Katana 17 HX B14WGK ОБЗОР
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Что такое глубина резкости в фотографии?
- Макросъемка
- Что такое светосила. Какой светосильный объектив выбрать.
- Что купить фотографу. Рекомендации
2026-02-14 12:24