Автор: Денис Аветисян
Исследователи представили обширный набор данных и платформу для изучения поведения пользователей в процессе поиска информации.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"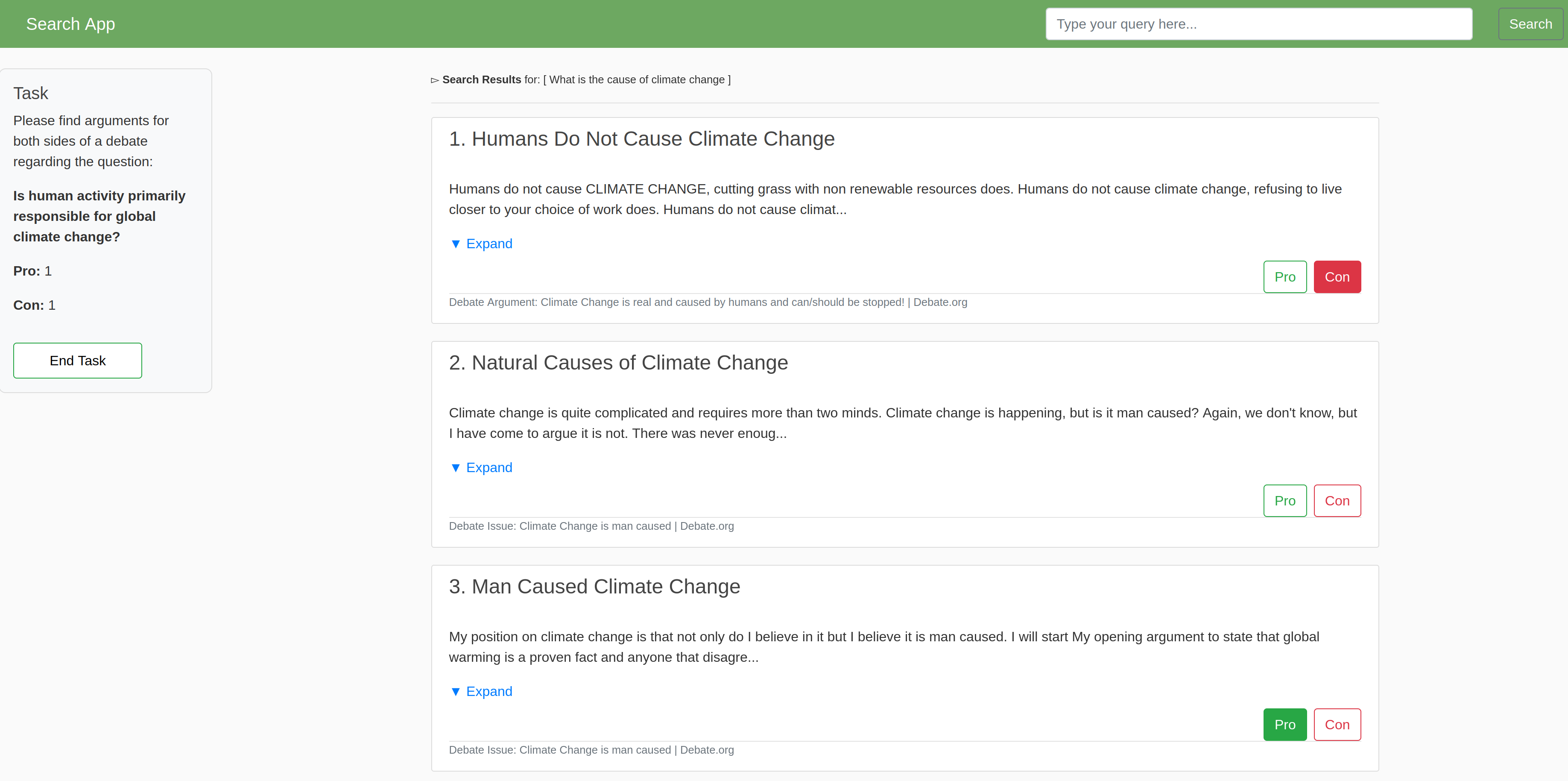
Представлен LISP — датасет и платформа для анализа интерактивного поиска с подробными логами пользовательских сессий и моделями поведения.
Несмотря на растущий интерес к изучению поведения пользователей в интерактивном поиске информации, доступность комплексных и воспроизводимых ресурсов остается ограниченной. В данной работе представлена платформа и датасет ‘LISP — A Rich Interaction Dataset and Loggable Interactive Search Platform’, включающие подробные логи взаимодействия 61 участника, а также данные об их индивидуальных характеристиках, таких как скорость восприятия и предметные интересы. Этот ресурс позволяет исследовать влияние как индивидуальных, так и контекстуальных факторов на поведение пользователей при поиске, а также разрабатывать и валидировать более реалистичные модели имитации пользователей. Какие новые возможности для понимания и оптимизации процесса поиска откроет детальный анализ этих данных и открытый доступ к ресурсу LISP?
Поиск в Информационном Хаосе: Эволюция Намерений Пользователя
Традиционные методы информационного поиска часто оказываются неспособными уловить тонкости намерений пользователя в процессе поиска. Статичные алгоритмы ранжирования, оценивающие документы вне контекста последовательности запросов, не учитывают, что потребность в информации может уточняться и меняться по мере взаимодействия с системой. Пользователь может начать с общего запроса, а затем, анализируя полученные результаты, сузить область поиска или изменить его направление. Неспособность систем к адаптации к этой динамике приводит к выдаче нерелевантных документов и снижает эффективность поиска. Понимание эволюции намерений пользователя в течение сессии является ключевой задачей для разработки более интеллектуальных и эффективных систем поиска информации.
Традиционные методы ранжирования информации, основанные на статичных алгоритмах, часто оказываются неэффективными при решении сложных информационных запросов. Они не способны учитывать динамику потребностей пользователя в процессе поиска, когда изначальный запрос уточняется и развивается. В отличие от них, интерактивные системы позволяют адаптироваться к меняющимся намерениям пользователя, анализируя последовательность действий и предоставляя результаты, соответствующие текущему контексту поиска. Такой подход, в отличие от однократного ранжирования, позволяет более точно соответствовать реальным информационным потребностям, что особенно важно при решении неоднозначных или многоаспектных задач. Благодаря возможности обратной связи и адаптации, интерактивные системы представляют собой перспективное направление в развитии информационного поиска.
Серия соревнований `TREC Session Track` значительно подчеркнула возрастающую важность моделирования поведения пользователей в процессе поисковых сессий. В отличие от традиционных подходов, рассматривающих каждый запрос изолированно, `TREC Session Track` акцентировал внимание на последовательности запросов, временных интервалах между ними и изменениях в информационных потребностях пользователя на протяжении всей сессии. Анализ данных, предоставленных в рамках этого трека, показал, что учет контекста поисковой сессии позволяет существенно повысить релевантность результатов поиска и более точно удовлетворить потребности пользователя, что стало ключевым направлением в развитии интерактивного информационного поиска.
Успешное моделирование поведения пользователя в процессе поиска имеет первостепенное значение для развития интерактивного информационного поиска. В отличие от традиционных систем, ориентированных на единичные запросы, интерактивные модели стремятся понять динамику поисковой сессии — как изменяются намерения пользователя, какие факторы влияют на его выбор, и как последовательность действий формирует конечный результат. Точное отражение этих поведенческих паттернов позволяет создавать системы, способные не просто выдавать релевантные документы, но и активно участвовать в процессе поиска, предлагая уточнения, альтернативные варианты и персонализированные рекомендации. Подобный подход открывает возможности для более эффективного извлечения информации, особенно в тех случаях, когда потребность пользователя сложна и многогранна, а исходные запросы неоднозначны.
LISP Dataset: Ресурс для Исследований Интерактивного Поиска
Набор данных `LISP` состоит из 122 журналов сессий взаимодействия пользователей с поисковой системой, что обеспечивает обширный ресурс для исследований в области информационного поиска и рассуждений. Каждый журнал сессии включает в себя записи о запросах пользователей, просмотренных результатах и взаимодействии с ними. Помимо данных о поиске, набор данных содержит демографическую информацию о пользователях, а также когнитивные профили, что позволяет проводить анализ влияния различных факторов на процесс поиска и принятия решений. Данная структура позволяет исследовать паттерны поведения пользователей, их информационные потребности и стратегии поиска.
Набор данных `LISP` использует в качестве основы корпус `Debate.org`, предоставляя структурированную коллекцию аргументов и мнений по различным спорным вопросам. Это позволяет исследователям изучать процессы поиска аргументов, используемые пользователями при формировании своей позиции, а также анализировать когнитивные стратегии, применяемые в процессе рассуждений и оценки информации. Корпус `Debate.org` обеспечивает богатый источник данных для разработки и оценки систем автоматического поиска аргументов и поддержки принятия решений, что делает `LISP Dataset` ценным ресурсом для исследований в области искусственного интеллекта и когнитивных наук.
Платформа `LISP` обеспечила сбор данных, регистрируя взаимодействия пользователей в процессе поиска и обеспечивая контроль качества полученной информации. Логирование осуществлялось в процессе работы с платформой, фиксируя все действия пользователей. Это позволило сформировать базу данных, состоящую из 122 сессий, содержащих детальную информацию о поведении пользователей и их взаимодействии с системой, что необходимо для последующего анализа и исследований в области информационного поиска и когнитивных процессов.
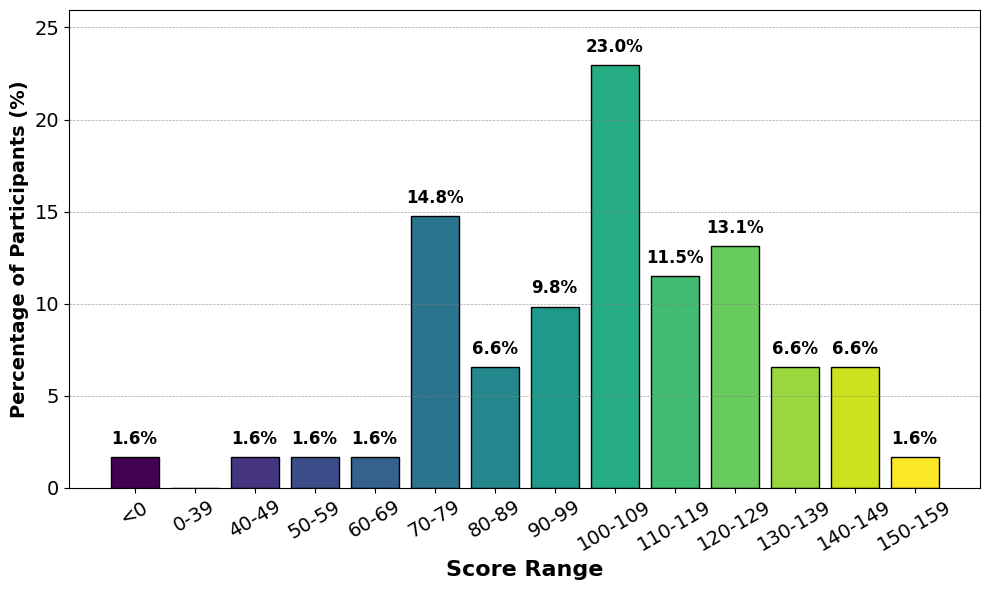
В составе набора данных `LISP` присутствуют когнитивные данные, в частности, показатель скорости восприятия, измеренный с помощью теста «Поиск букв А». Среднее значение данного показателя по всей выборке составляет 101.66, а стандартное отклонение — 28.5. Этот параметр позволяет проводить анализ взаимосвязи между когнитивными способностями пользователей и их поведением при поиске информации и аргументации, предоставляя дополнительные возможности для исследований в области информационного поиска и когнитивных наук.
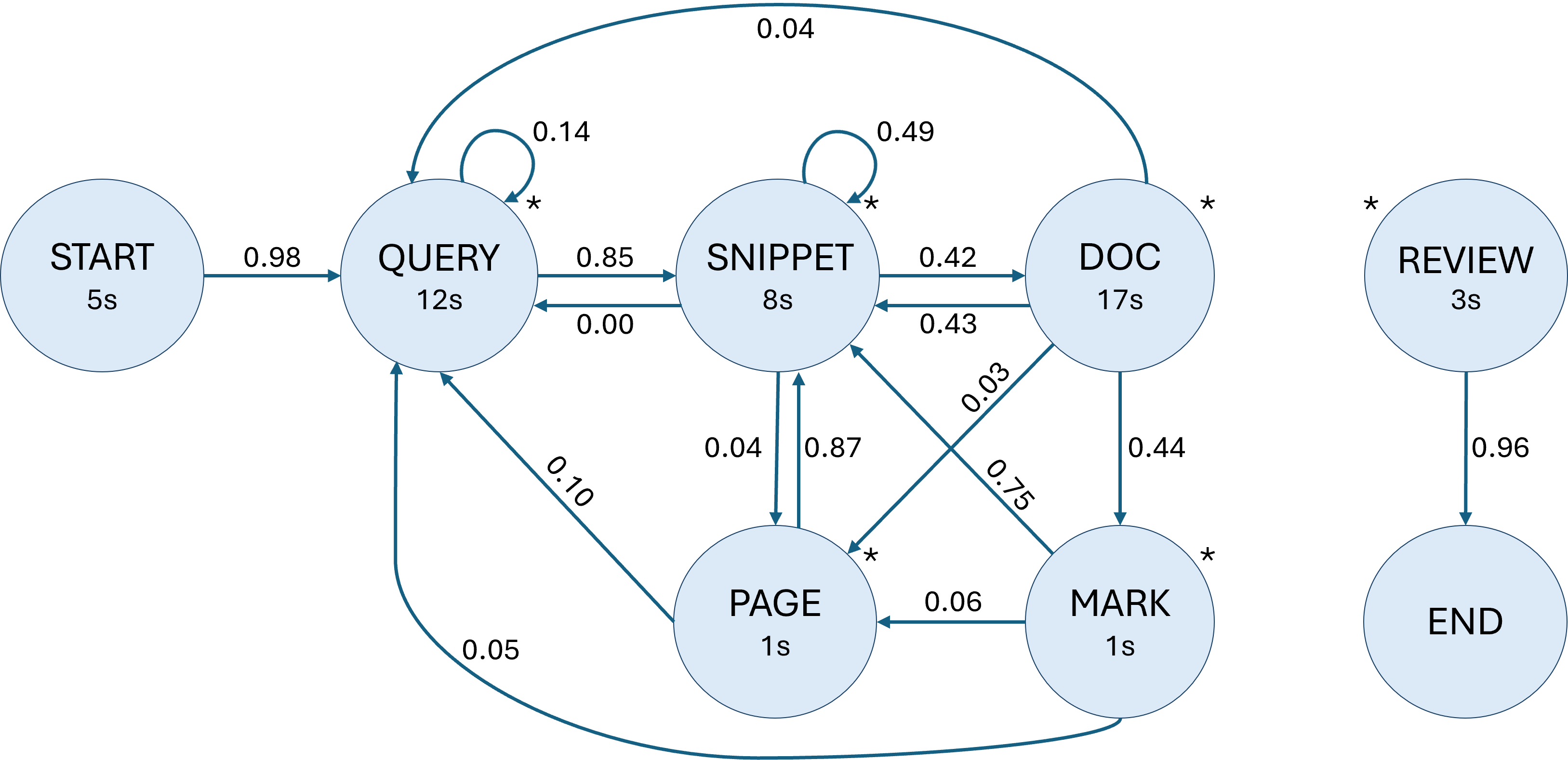
Моделирование Пользовательского Поведения: Аналитические Инструменты
Анализ пользовательских поисковых сессий, основанный исключительно на сопоставлении ключевых слов, является недостаточным для полного понимания поведения пользователей. Такой подход не учитывает последовательность запросов, временные интервалы между ними, а также более сложные паттерны, отражающие информационные потребности пользователя. Для более глубокого анализа требуются методы, способные учитывать контекст поисковых запросов и взаимосвязи между ними, такие как Markov Models и анализ кликов, позволяющие выявлять скрытые закономерности и прогнозировать дальнейшие действия пользователя в системе поиска.
Для анализа паттернов поведения пользователей при поиске в наборе данных LISP использовались модели Маркова. Результаты показали незначительные различия между группами пользователей, различающихся по показателям перцептивной скорости, что подтверждается малым значением нормы Фробениуса (0.18). Данный показатель указывает на высокую степень схожести в последовательности запросов и переходов между результатами поиска для пользователей с разными уровнями перцептивной скорости, что свидетельствует о минимальном влиянии данного когнитивного параметра на процесс поиска в данном наборе данных.
Модели кликов (Click Models) представляют собой аналитические инструменты, предназначенные для прогнозирования вероятности выбора пользователем конкретного результата поиска. Эти модели используют различные факторы, такие как релевантность документа запросу, позиция результата в выдаче и характеристики самого пользователя, для оценки вероятности клика. Полученные прогнозы используются для оптимизации поисковых систем, в частности, для ранжирования результатов поиска таким образом, чтобы наиболее релевантные документы отображались на более высоких позициях, увеличивая вероятность их выбора пользователями. Кроме того, модели кликов позволяют оценивать эффективность изменений в алгоритмах ранжирования и пользовательском интерфейсе, позволяя разработчикам принимать обоснованные решения для улучшения пользовательского опыта и повышения общей производительности системы.
Анализ поисковых сессий показал, что пользователи формулируют больше запросов по темам, представляющим личный интерес. Статистический анализ поведения пользователей, объединенных общими интересами, выявил незначительные различия между группами (норма Фробениуса составила 0.10). Это указывает на высокую степень согласованности в паттернах формирования запросов внутри групп, несмотря на разнообразие тем, что позволяет использовать обобщенные модели для анализа пользовательского поведения.
Моделирование пользователей (User Simulation) представляет собой методологию, позволяющую исследователям оценивать и совершенствовать системы информационного поиска в контролируемых условиях. Данный подход включает в себя создание вычислительных моделей, имитирующих поведение реальных пользователей при взаимодействии с системой. Эти модели позволяют генерировать запросы, оценивать релевантность результатов и кликать по ссылкам, воспроизводя типичные сценарии поиска. Это дает возможность проводить систематические эксперименты, тестировать различные алгоритмы ранжирования и интерфейсные решения, а также прогнозировать эффективность системы без необходимости привлечения большого количества реальных пользователей. Использование моделирования пользователей существенно снижает затраты и время, необходимые для оценки и оптимизации систем поиска.
Надежность и Воспроизводимость: Вклад LISP Dataset
Набор данных `LISP` был разработан с акцентом на максимальную воспроизводимость научных результатов. Это означает, что исследователи, независимо от местоположения и используемого оборудования, могут повторно выполнить анализ, используя предоставленные данные и методики, и получить аналогичные результаты. Для обеспечения этой воспроизводимости, набор данных включает в себя не только сами данные ответов на вопросы, но и подробную документацию о процессе сбора, предобработки и анализа. Такой подход позволяет независимо подтвердить полученные выводы, повышая доверие к исследованиям в области извлечения аргументов и способствуя более быстрому прогрессу в этой сфере. Воспроизводимость, как ключевой принцип научной работы, является неотъемлемой частью набора данных `LISP`, гарантируя прозрачность и надежность представленных результатов.
Набор данных LISP был разработан с учетом принципов реюзабельности 5-го уровня, что гарантирует его долгосрочную доступность и значимость для научного сообщества. Такой подход предполагает не только сохранение самих данных в открытом формате, но и предоставление полной и подробной документации, описывающей методологию сбора, обработки и анализа информации. В частности, обеспечивается возможность легкого повторного использования данных для различных исследовательских целей, включая проверку существующих результатов и проведение новых анализов. Это способствует повышению надежности научных выводов и ускоряет прогресс в области извлечения аргументов, поскольку другие исследователи могут опираться на проверенный и хорошо документированный ресурс, избегая дублирования усилий и повышая эффективность научной работы.
В процессе сбора данных для исследования активно применялся API сервиса Google Translate для обработки ответов на пост-изученческие анкеты. Этот подход позволил существенно расширить географию участников и обеспечить возможность анализа данных, полученных от респондентов, говорящих на различных языках. Использование автоматического перевода не только упростило логистику сбора информации, но и повысило применимость результатов исследования в международном контексте, делая его более инклюзивным и репрезентативным для различных культурных групп. Такой подход к обработке данных обеспечивает возможность проведения кросс-культурных сравнений и обогащает понимание изучаемого феномена.
Исследование показало, что время просмотра документа у пользователей с высоким уровнем перфекционизма (high-PS) в среднем составляло на 2,94 секунды больше, чем у других участников. Однако, несмотря на наблюдаемую разницу, статистической значимости данного результата достигнуто не было. Это означает, что, хотя и прослеживается тенденция к более длительному изучению материала пользователями, склонными к тщательному анализу, данная закономерность может быть обусловлена случайными факторами и не является устойчивой характеристикой данной группы. Дальнейшие исследования с большей выборкой участников могут помочь определить, существует ли реальная связь между уровнем перфекционизма и временем, затрачиваемым на анализ текстовой информации.
Открытый доступ к набору данных LISP значительно способствует развитию сотрудничества и ускоряет прогресс в области поиска аргументов. Предоставляя исследователям возможность свободно использовать, анализировать и расширять существующие данные, этот подход позволяет избежать дублирования усилий и стимулирует инновации. Доступность набора данных облегчает проверку и воспроизведение результатов исследований, что критически важно для укрепления доверия к научным выводам. Кроме того, открытый характер данных способствует разработке новых методов и алгоритмов, направленных на улучшение систем поиска аргументов и, в конечном итоге, на поддержку более обоснованных и эффективных процессов принятия решений.
Изучение представленного набора данных и платформы LISP напоминает наблюдение за ростом сложной экосистемы. Разработчики стремятся не просто создать инструмент для поиска информации, а сформировать среду, где можно изучать поведение пользователя в процессе взаимодействия с системой. Этот подход особенно важен, поскольку позволяет глубже понять неявные потребности и предпочтения, влияющие на эффективность поиска. Барбара Лисков однажды заметила: «Проектирование хороших абстракций требует понимания того, как они будут использоваться». Это высказывание применимо и к созданию подобных платформ: ценность заключается не в самих технологиях, а в возможностях, которые они открывают для изучения человеческого взаимодействия с информацией. Ведь каждая архитектурная деталь — это своего рода предсказание о будущих ошибках и потребностях пользователя.
Что Дальше?
Представленный ресурс, как и любая попытка зафиксировать динамику человеческого поиска, неизбежно становится лишь снимком, застывшей иллюзией стабильности в океане хаоса. Он предоставляет данные, но не ответы. Вопрос не в том, чтобы построить идеальную симуляцию пользователя, а в том, чтобы признать, что любое моделирование — это всегда упрощение, пророчество о тех аспектах поведения, которые будут проигнорированы. Гарантий достоверности не существует; лишь согласованность с наблюдаемыми паттернами, кэшированная в структуре данных.
Дальнейшее развитие неизбежно связано с уходом от попыток точного предсказания и переходом к исследованию условий возникновения непредсказуемого. Интерес пользователя — это не параметр, который можно измерить, а поле, которое постоянно меняется под воздействием внешних факторов и внутренних противоречий. Задача не в создании «умного» поискового движка, а в проектировании систем, способных адаптироваться к непрерывным изменениям, к языку природы, выраженному в хаосе.
Вопрос воспроизводимости, подчеркнутый в работе, не должен сводиться к повторению экспериментов. Истинная воспроизводимость заключается в возможности предсказать, как система сломается, а не в предотвращении этого. Именно в этих точках отказа, в неожиданных отклонениях от нормы, кроется настоящая информация о природе поиска и о тех границах, которые определяют наше понимание информации.
Оригинал статьи: https://arxiv.org/pdf/2601.09366.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- Российский рынок в 2025: Инвестиции, Экспорт и Новые Возможности (27.02.2026 15:32)
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
2026-01-15 20:26