Автор: Денис Аветисян
Новая архитектура STAformer позволяет искусственному интеллекту прогнозировать ближайшие действия человека с объектами, опираясь на понимание окружающей среды и визуальное внимание.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"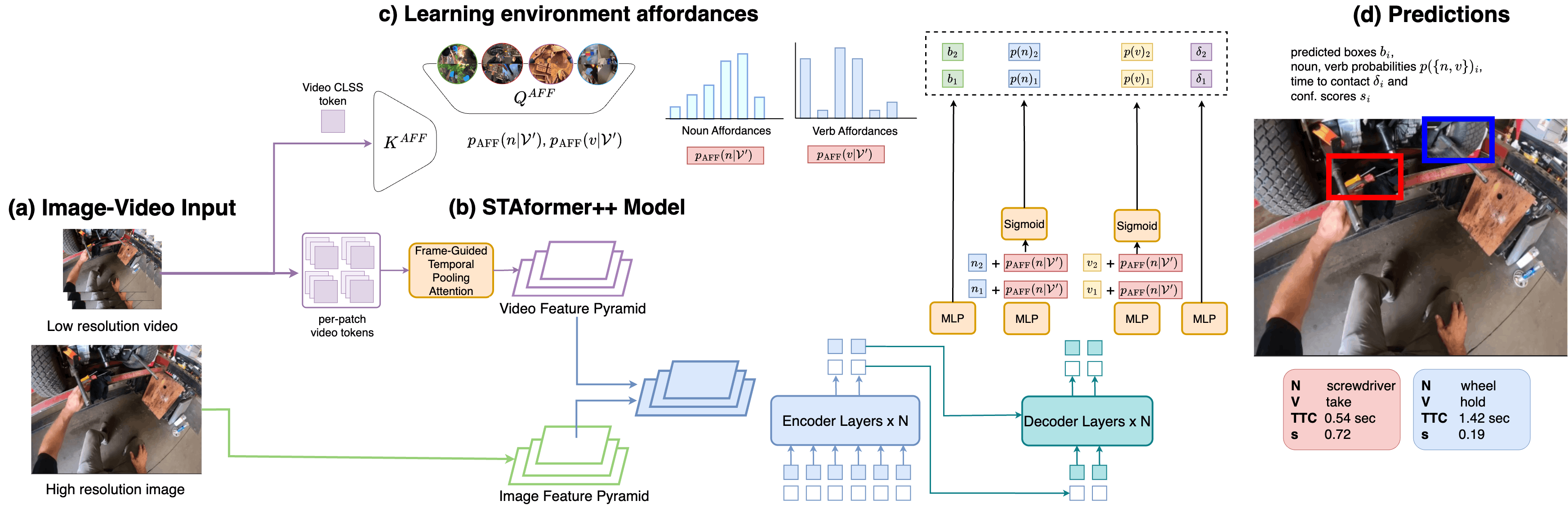
Представлены модели STAformer и STAformer++, основанные на трансформерах, для краткосрочного предсказания взаимодействия с объектами, использующие аффордансы и механизмы внимания.
Прогнозирование взаимодействия человека с объектами в краткосрочной перспективе остается сложной задачей для систем искусственного интеллекта, требующей глубокого понимания контекста и намерений. В работе, озаглавленной ‘Integrating Affordances and Attention models for Short-Term Object Interaction Anticipation’, предлагается новый подход к этой проблеме, основанный на архитектурах STAformer и STAformer++, объединяющих механизмы внимания и моделирование аффордансов среды. Предложенные модели демонстрируют значительное улучшение точности прогнозирования взаимодействия с объектами, достигая прироста до +31п.п. на стандартных датасетах. Каким образом дальнейшее развитие методов моделирования аффордансов и механизмов внимания позволит создавать более интеллектуальные и адаптивные системы взаимодействия человека и робота?
Понимание Взаимодействия: Вызов для Современной Науки
Прогнозирование взаимодействия человека с окружающими предметами является ключевой задачей для развития как вспомогательной робототехники, так и воплощенного искусственного интеллекта. Однако, несмотря на значительный прогресс в области компьютерного зрения и машинного обучения, эта задача остается сложной и требует комплексного подхода. Способность робота или ИИ предвидеть намерения человека, основываясь на визуальных данных и контексте ситуации, необходима для обеспечения безопасного и эффективного взаимодействия. Неточности в прогнозировании могут привести к неловким, а в худшем случае — опасным ситуациям, что подчеркивает важность дальнейших исследований в данной области. Разработка алгоритмов, способных учитывать тонкие нюансы человеческого поведения и динамику окружающей среды, представляет собой значительный вызов для современных ученых и инженеров.
Существующие методы анализа взаимодействия человека с окружающими предметами сталкиваются с серьезными трудностями при синхронизации визуальной информации с течением времени и понимании контекста динамично меняющихся сцен. Неспособность точно определить, когда происходит ключевое взаимодействие, и что именно в текущей ситуации является релевантным, приводит к ошибкам в предсказании намерений человека. Например, система может неправильно интерпретировать движение руки, если не учитывает положение других объектов в поле зрения и предшествующую последовательность действий. Это особенно актуально в сложных, быстро меняющихся средах, где необходимо не только распознать отдельные действия, но и предвидеть их последствия и взаимосвязь с другими событиями, чтобы обеспечить адекватную реакцию роботизированной системы или искусственного интеллекта.
STAformer: Трансформер для Моделирования Взаимодействий
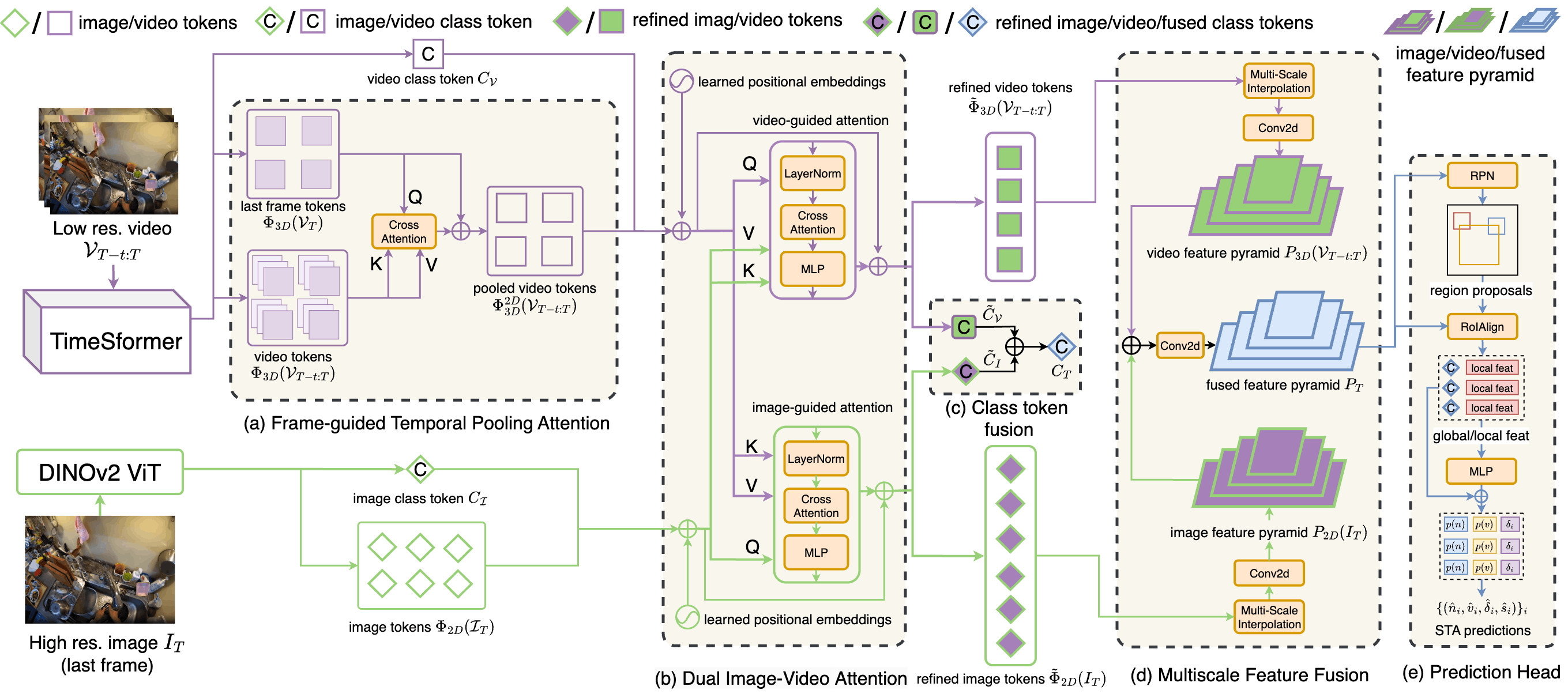
STAformer использует архитектуру Transformer для моделирования сложных взаимосвязей между объектами и агентами в видеопоследовательностях. В отличие от рекуррентных нейронных сетей, Transformer позволяет обрабатывать всю последовательность одновременно, что обеспечивает более эффективное улавливание долгосрочных зависимостей. Это достигается за счет механизма самовнимания (self-attention), позволяющего каждому элементу последовательности учитывать вклад всех остальных элементов. В контексте видеоанализа, это позволяет STAformer учитывать взаимодействие между объектами на протяжении всей последовательности, что критически важно для понимания происходящих событий и прогнозирования будущих действий. Архитектура Transformer также позволяет использовать параллельные вычисления, что существенно ускоряет процесс обработки видеоданных по сравнению с последовательными моделями.
Ключевыми инновациями в архитектуре STAformer являются механизм Frame-Guided Temporal Pooling и Dual Cross-Attention. Frame-Guided Temporal Pooling обеспечивает выравнивание временных видео-признаков с пространственным контекстом, что повышает точность моделирования динамики сцены. Dual Cross-Attention позволяет эффективно объединять признаки из различных источников, используя два отдельных механизма внимания для улавливания как глобальных, так и локальных зависимостей между объектами и агентами. Это достигается путем применения внимания между пространственными и временными признаками, а также между признаками различных объектов, что способствует более полному представлению видеопоследовательности.
Архитектура STAformer обеспечивает эффективную обработку визуальных данных благодаря использованию механизма внимания и параллельной обработки, что позволяет модели быстро анализировать видеопоследовательности. Это, в свою очередь, обеспечивает надежные прогнозы будущих взаимодействий между объектами и агентами, так как модель способна улавливать сложные временные зависимости и пространственные взаимосвязи в видеопотоке. Высокая скорость обработки и точность прогнозов достигаются за счет оптимизированной структуры и эффективного использования вычислительных ресурсов.
STAformer++: Расширение Возможностей с Учетом Аффордансов
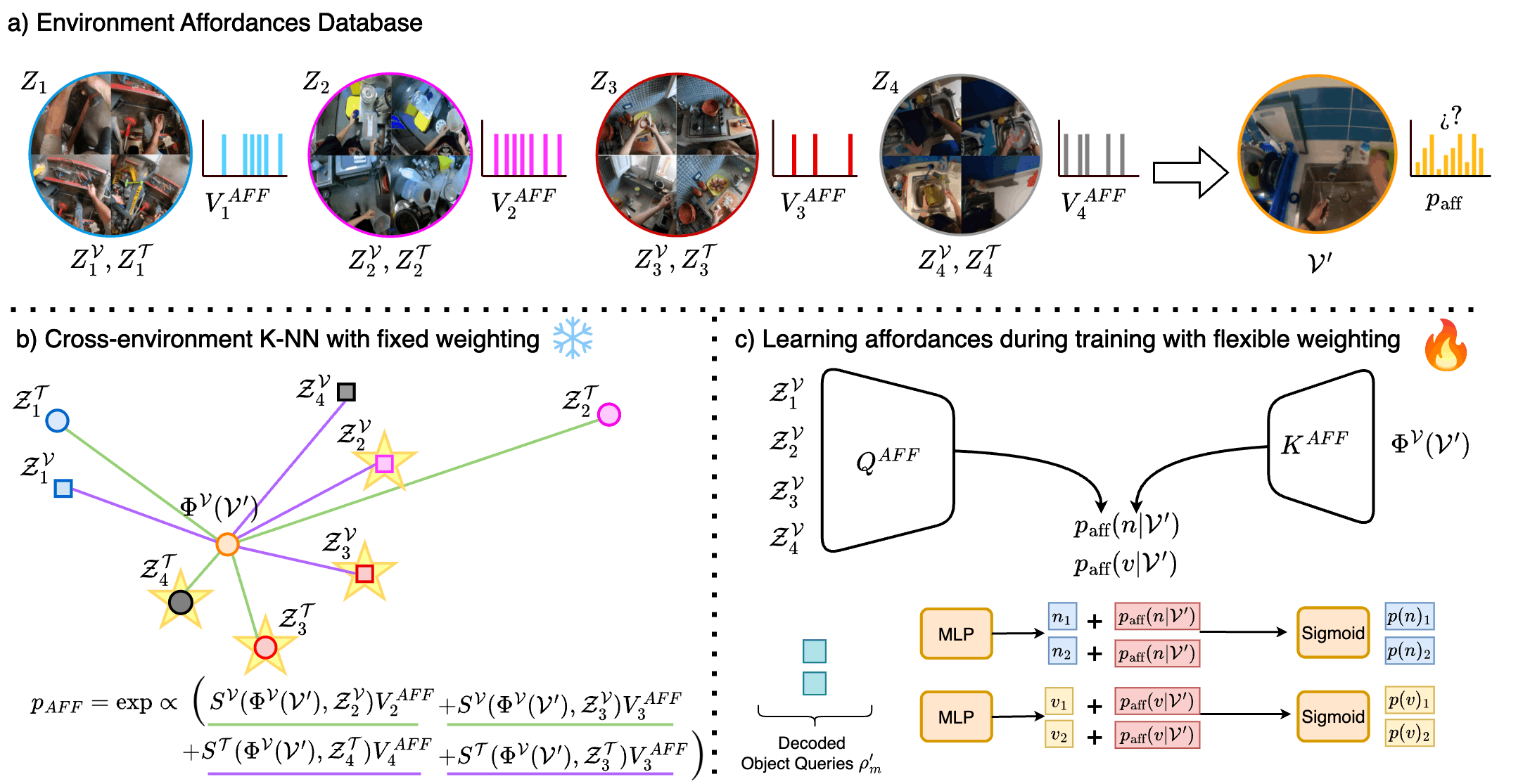
STAformer++ расширяет базовую архитектуру, вводя концепцию «аффордансов среды» — потенциальных действий, которые среда предлагает агенту. Аффордансы определяют возможности взаимодействия агента с окружением, такие как возможность перемещения, захвата объектов или использования элементов окружения для достижения целей. Интеграция аффордансов позволяет модели не просто воспринимать окружение как статичную сцену, но и оценивать доступные действия, что критически важно для планирования и эффективного принятия решений в динамичных условиях. В контексте STAformer++, аффордансы представлены в виде векторов признаков, которые учитываются при прогнозировании будущих состояний и траекторий.
Реализация концепции аффордансов окружения в STAformer++ достигается за счет интеграции двух ключевых компонентов: Cross-Zone Similarity и определения Interaction Hotspots. Cross-Zone Similarity позволяет модели изучать гибкие представления аффордансов, анализируя сходство между различными зонами изображения и выявляя потенциальные действия, доступные агенту. Interaction Hotspots, в свою очередь, идентифицируют области на изображении, наиболее вероятные для взаимодействия, что позволяет модели фокусироваться на релевантных участках сцены и повышать точность предсказаний. Оба компонента совместно обеспечивают более полное и контекстуально-обоснованное понимание возможностей, предоставляемых окружением.
Для максимизации качества извлекаемых признаков архитектура STAformer++ использует передовые энкодеры изображений, такие как DINOv2 и Swin Transformer, позволяющие эффективно кодировать визуальную информацию. В дополнение к этому, для обработки видеоданных применяются видео-экстракторы TimeSformer и EgoVideo, обеспечивающие извлечение временных зависимостей и контекста, что критически важно для понимания динамических сцен и прогнозирования действий. Комбинация этих моделей позволяет получить более полные и репрезентативные признаки, необходимые для задач предсказания и планирования.

Оценка Эффективности: Количественные Показатели и Преимущества
Тщательная оценка STAformer++ проводилась на общепризнанных наборах данных, для количественной оценки эффективности использовалась метрика Mean Average Precision (mAP). Этот подход позволил получить надежные и воспроизводимые результаты, подтверждающие возможности модели в задачах предсказания взаимодействий. Использование mAP в качестве ключевого показателя позволило объективно сравнить STAformer++ с другими современными методами, демонстрируя её превосходство в точности и полноте обнаружения взаимодействий между объектами в видео. Полученные результаты свидетельствуют о высокой эффективности STAformer++ в сложных сценариях, что делает её перспективным решением для широкого спектра приложений в области компьютерного зрения и анализа видео.
Исследования показали, что разработанная система достигла передовых результатов в задачах прогнозирования взаимодействий. Набор данных Ego4D v1 продемонстрировал среднюю точность обнаружения mAP в 33.21%, что является новым эталоном в данной области. Особенно заметны улучшения на наборе данных EPIC-Kitchens, где система превзошла существующую модель Stillfast на 31.5%. Данный результат свидетельствует о значительном прогрессе в понимании и прогнозировании действий, совершаемых людьми в повседневной жизни, и открывает новые возможности для развития систем помощи и автоматизации.
В ходе тестирования на наборе данных EPIC-Kitchens были достигнуты значительные улучшения в точности предсказания взаимодействий. Модель продемонстрировала среднюю точность mAP в 45.34 для задач, связанных с предсказанием действий, основанных исключительно на визуальной информации (N), и 25.82 при включении данных о визуальном контексте и движении (N+V). Данные результаты свидетельствуют о существенном прогрессе в способности модели понимать и прогнозировать человеческие действия в кухонной среде, что открывает перспективы для создания более интеллектуальных и отзывчивых систем взаимодействия человек-компьютер.
Внедрение предсказательной головки DETR существенно повысило эффективность модели STAformer++. Этот подход, основанный на сквозном обнаружении объектов, позволяет системе непосредственно предсказывать присутствие и местоположение взаимодействующих объектов в видео, минуя традиционные этапы обработки. Результаты демонстрируют, что DETR способствует более точному пониманию действий и взаимодействий, что критически важно для задач предсказания человеческих действий. Благодаря возможности обучения “end-to-end”, модель оптимизируется для непосредственного решения задачи, что приводит к значительному улучшению метрик, таких как Mean Average Precision (mAP), и обеспечивает более надежную и точную работу в сложных сценариях.

Перспективы Развития: Расширяя Горизонты Прогнозирования Взаимодействий
В дальнейшем исследования будут направлены на расширение существующей системы, чтобы она могла учитывать более сложные взаимодействия и включать контекстуальное понимание намерений человека. Текущая модель, хотя и демонстрирует успешные результаты в простых сценариях, ограничена в своей способности анализировать ситуации, требующие учета предшествующей истории, социальных норм и неявных сигналов. Разработка алгоритмов, способных к более глубокому анализу контекста, позволит предсказывать действия людей с большей точностью, учитывая не только непосредственное поведение, но и вероятные мотивы и цели. Это особенно важно для приложений, где требуется не просто распознавание действий, а понимание их значения и прогнозирование дальнейших шагов, например, в системах помощи пожилым людям или в робототехнике, взаимодействующей с людьми в реальном времени.
Исследования направлены на интеграцию языковых моделей в существующую систему прогнозирования взаимодействия, что позволит существенно расширить возможности анализа вербальных сигналов. Включение обработки естественного языка позволит учитывать не только невербальные признаки, но и содержание речи, интонацию и контекст высказываний, что, в свою очередь, повысит точность предсказания намерений и действий человека. Предполагается, что комбинация визуального анализа и лингвистических данных создаст более полную картину происходящего, что особенно важно для сложных социальных взаимодействий, где вербальные и невербальные сигналы тесно переплетены. Такой подход открывает перспективы для создания интеллектуальных систем, способных понимать нюансы человеческого общения и адекватно реагировать на них.
Перспективы расширения архитектуры для обработки видеопотоков в реальном времени открывают значительные возможности для практического применения в областях робототехники и дополненной реальности. Разработка систем, способных анализировать визуальную информацию и прогнозировать взаимодействия в динамике, позволит роботам более эффективно ориентироваться в сложных средах и взаимодействовать с людьми. В дополненной реальности подобный анализ позволит создавать более реалистичные и интуитивно понятные интерфейсы, предвосхищая действия пользователя и адаптируя виртуальный контент в соответствии с его намерениями. Успешная интеграция данной технологии приведет к созданию адаптивных систем, способных к предиктивному взаимодействию, что значительно повысит эффективность и удобство использования робототехнических комплексов и приложений дополненной реальности.
Исследование, представленное в данной работе, подчеркивает важность понимания не только визуальной информации, но и потенциальных взаимодействий объектов в окружающей среде. STAformer и STAformer++ демонстрируют, что учет аффордансов, то есть возможностей использования объектов, существенно улучшает предсказание действий. Это согласуется с идеей о том, что система познается через исследование её закономерностей. Как однажды заметил Дэвид Марр: «Визуальная информация бесполезна, если она не интерпретируется в контексте действия». Данный подход к краткосрочному предсказанию взаимодействий, опираясь на трансформеры и механизмы внимания, позволяет создавать более реалистичные и эффективные модели понимания сцен и предвидения поведения, подтверждая, что закономерность взаимодействия существует только тогда, когда её можно воспроизвести и объяснить в рамках системы.
Куда двигаться дальше?
Представленные архитектуры STAformer и STAformer++ демонстрируют, что интеграция понимания доступных действий (affordances) с механизмами внимания действительно повышает точность предсказания взаимодействия объектов в краткосрочной перспективе. Однако, подобно любой модели, стремящейся уловить динамику сложной системы, она остаётся упрощением. Подобно тому, как физик описывает хаотичное движение, вычленяя доминирующие силы, так и здесь — предсказание, основанное на текущих наблюдениях, неизбежно упускает из виду скрытые переменные и неявные намерения.
Дальнейшие исследования должны быть направлены на преодоление этой ограниченности. Подобно эволюции нейронных сетей в биологических системах, необходимо исследовать методы, позволяющие модели «учиться учиться» — адаптировать стратегии предсказания в зависимости от контекста и индивидуальных особенностей объектов. Интересным направлением представляется интеграция моделей, учитывающих причинно-следственные связи, — не просто предсказывать что произойдет, но и понимать почему. Подобно тому, как иммунная система распознает угрозы, необходимо обучить модель выявлять аномалии и предсказывать неожиданные взаимодействия.
В конечном итоге, цель состоит не в создании идеального предсказателя, а в разработке системы, способной к глубокому пониманию сцены, подобно тому, как живое существо ориентируется в окружающем мире. Это требует не просто обработки визуальных данных, но и построения внутренней модели мира, учитывающей физические законы, социальные нормы и, возможно, даже элементы интуиции — то, что пока остаётся за гранью возможностей искусственного интеллекта.
Оригинал статьи: https://arxiv.org/pdf/2602.14837.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Неважно, на что вы фотографируете!
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Как правильно фотографировать ночью
- Что такое глубина резкости в фотографии?
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
- MSI Katana 17 HX B14WGK ОБЗОР
- Освоение объектива 35мм: ключевые советы по композиции
2026-02-17 14:34