Автор: Денис Аветисян
Новая методика позволяет моделям искусственного интеллекта понимать пространственные связи в изображениях и рассуждать о трехмерном окружении.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"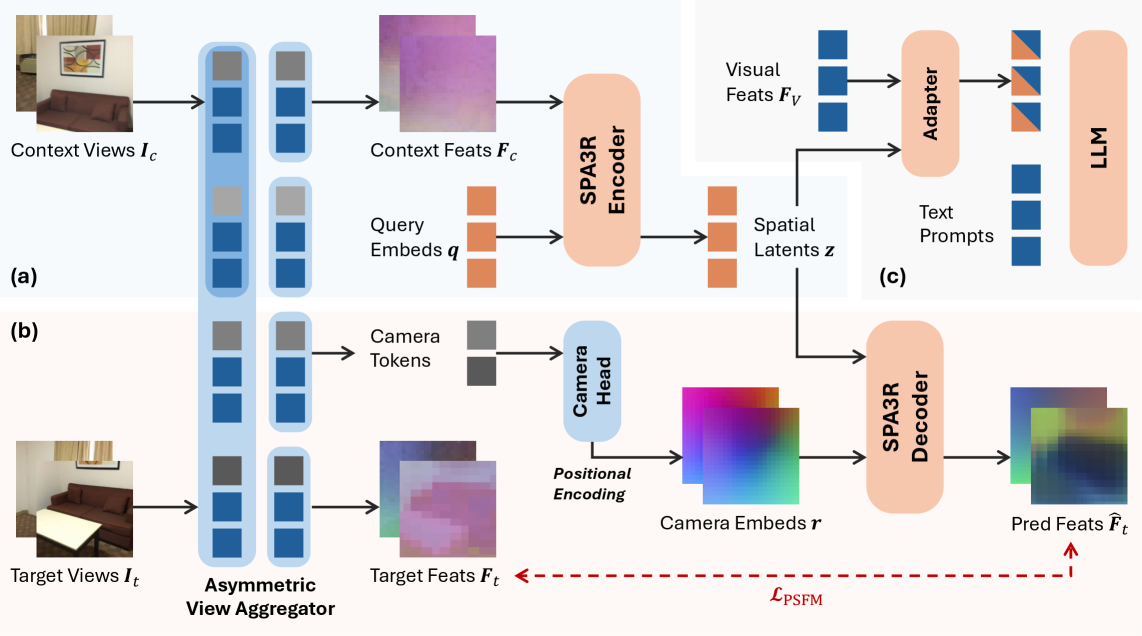
Предложена платформа Spa3R, использующая предсказательное моделирование пространственных полей для обучения моделей пониманию 3D-пространства по 2D-изображениям.
Несмотря на впечатляющие успехи моделей «зрение-язык» в понимании 2D-изображений, их способность к трехмерному пространственному мышлению остается ограниченной. В данной работе, представленной под названием ‘Spa3R: Predictive Spatial Field Modeling for 3D Visual Reasoning’, предлагается новый самообучающийся фреймворк Spa3R, использующий парадигму предсказательного моделирования пространственного поля для обучения надежным представлениям 3D-пространства исключительно из 2D-изображений. Spa3R позволяет моделям «зрение-язык» синтезировать поля признаков для произвольных, ранее невидимых ракурсов, создавая согласованное и инвариантное к точке обзора понимание сцены. Может ли подобный подход к обучению пространственному мышлению стать масштабируемым путем к созданию действительно интеллектуальных систем компьютерного зрения?
Пределы Визуально-Языкового Рассуждения
Современные модели, объединяющие зрение и язык, испытывают трудности при решении задач, требующих надежного понимания трехмерного пространства, что ограничивает их способность рассуждать о физическом мире. Эти модели, несмотря на прогресс в архитектурах-трансформерах, часто демонстрируют недостаток интуитивного понимания геометрии и пространственных отношений, особенно в сложных сценах. В результате, они могут ошибочно интерпретировать расположение объектов, их размеры и взаимосвязи, что приводит к неточным ответам на вопросы, требующие пространственного мышления. Данное ограничение существенно снижает эффективность этих моделей в таких областях, как робототехника, дополненная реальность и анализ сцен, где точное восприятие и понимание трехмерной среды является ключевым фактором успеха.
Несмотря на значительный прогресс в архитектурах трансформеров, современные модели, объединяющие зрение и язык, зачастую испытывают трудности в задачах, требующих точного пространственного мышления. Это связано с недостатком врожденных геометрических представлений, или «априорных знаний» о трехмерном мире. В отличие от человека, который интуитивно понимает такие понятия, как перспектива, окклюзия и относительное положение объектов, модели, основанные на трансформерах, вынуждены «учиться» этим принципам исключительно на основе данных. В сложных сценах, насыщенных деталями и требующих учета множества взаимосвязей между объектами, этот недостаток становится особенно заметным, приводя к ошибкам в оценке расстояний, размеров и ориентации. Таким образом, для достижения действительно надежного пространственного рассуждения, необходимо интегрировать в архитектуру моделей явные геометрические представления, позволяющие им эффективно обрабатывать и интерпретировать трехмерную информацию.
Ограниченность возможностей в трехмерном восприятии мира существенно сужает сферу применения современных моделей, объединяющих зрение и язык. В частности, это представляет собой серьезную проблему для робототехники, где точное понимание пространственных отношений необходимо для навигации и манипулирования объектами. Аналогичная ситуация наблюдается в системах дополненной реальности — без надежного трехмерного анализа окружения виртуальные объекты не могут быть реалистично интегрированы в реальный мир. Кроме того, глубокое понимание геометрии сцены является основополагающим для задач анализа изображений, позволяя, например, автоматически реконструировать трехмерные модели объектов или оценивать их взаимное расположение с высокой точностью. Таким образом, развитие трехмерного пространственного мышления является ключевым шагом на пути к созданию по-настоящему интеллектуальных систем, способных эффективно взаимодействовать с физическим миром.
Кодирование Пространственного Понимания: Подход PSFM
Метод Predictive Spatial Field Modeling (PSFM), представленный в Spa3R, представляет собой принципиально новый подход к пониманию трехмерного пространства. Вместо традиционных методов, основанных на реконструкции полной 3D-модели или обработке отдельных видов, PSFM формулирует задачу 3D-понимания как предсказание характеристик (features) для новых, ранее невидимых перспектив. Такой подход позволяет создавать устойчивые и надежные представления сцен, поскольку система учится прогнозировать, что должно быть видно из новой точки обзора, а не просто хранить существующие данные. Это обеспечивает более эффективное и гибкое представление сцены, особенно в условиях неполной информации или изменяющейся геометрии.
Метод Spa3R решает проблему зависимости от конкретной точки обзора и высокой стоимости 3D-реконструкций, свойственных традиционным подходам к пониманию трехмерного пространства. Вместо построения полной 3D-модели, Spa3R формирует единое, инвариантное к изменению точки зрения пространственное представление. Это достигается за счет обучения модели предсказывать характеристики новых видов сцены, основываясь на изученных геометрических отношениях, что позволяет эффективно обрабатывать данные и получать надежные результаты без необходимости предварительной реконструкции геометрии сцены или ограничения анализа одной точкой обзора.
Архитектура Spa3R использует Transformer-архитектуру в сочетании с координатами Плюккера для эффективного кодирования геометрических связей и обеспечения точного пространственного рассуждения. Координаты Плюккера, представляющие собой шестимерный вектор, описывающий прямую в трехмерном пространстве, позволяют компактно и однозначно представлять геометрию окружения. Transformer-архитектура, благодаря механизмам внимания, позволяет модели эффективно устанавливать зависимости между различными элементами сцены, представленными в виде координат Плюккера, и предсказывать характеристики новых ракурсов. Данный подход обеспечивает эффективное кодирование геометрических отношений, превосходя традиционные методы по скорости и точности пространственного анализа.
Многовидовое Слияние и Надежное Представление Сцены
Spa3R использует данные из нескольких видов для формирования полного представления о сцене. Ключевым элементом является асимметричный агрегатор видов, который объединяет информацию, полученную из разных перспектив. Для извлечения пространственно-выровненных признаков применяется VGGT-сеть, позволяющая модели эффективно обрабатывать визуальные данные и создавать согласованное представление геометрии сцены. Асимметричная структура агрегатора видов оптимизирована для снижения вычислительных затрат и повышения эффективности обработки данных, что особенно важно при работе с большими и сложными сценами.
Модель Spa3R использует семантические признаки, полученные с помощью DINOv3, для обогащения пространственного представления сцены. DINOv3 обеспечивает выделение признаков, основанных на семантическом понимании объектов и их взаимосвязей в кадре. Интеграция этих семантических признаков в пространственную карту позволяет Spa3R не только понимать геометрию сцены, но и интерпретировать ее содержимое, что повышает точность и надежность процессов понимания и анализа сцены, а также способствует обобщению модели на новые, ранее не виданные сцены.
Относительное позиционное кодирование в Spa3R фиксирует геометрические преобразования между различными видами сцены. Этот механизм позволяет модели учитывать взаимное расположение камер и, как следствие, точно восстанавливать трёхмерную структуру окружения. Используя информацию о положении и ориентации каждой камеры относительно других, Spa3R может обобщать данные и успешно работать с ранее не встречавшимися точками обзора и неизвестными сценами, поскольку не опирается на абсолютные координаты, а учитывает только относительные изменения между видами.
Обучение Spa3R на масштабных наборах данных, таких как ScanNet, позволяет модели формировать устойчивые и обобщающие пространственные представления. ScanNet содержит реалистичные 3D-сканы интерьеров с аннотациями, что обеспечивает достаточное количество данных для обучения сложных нейронных сетей. Использование большого объема данных способствует уменьшению переобучения и повышает способность модели к обобщению на новые, ранее не встречавшиеся сцены и ракурсы. Процесс обучения на ScanNet позволяет Spa3R извлекать и кодировать важные пространственные характеристики, необходимые для точного представления и понимания окружающей среды.
Spa3-VLM: Привязка Языка к Пространственному Миру
Spa3-VLM осуществляет бесшовную интеграцию предварительно обученного энкодера Spa3R с большой визуально-языковой моделью (VLM) Qwen2.5-VL, что позволяет привязать понимание языка к целостному пространственному контексту. Данная архитектура позволяет модели интерпретировать языковые запросы, учитывая трехмерную структуру сцены, представленную Spa3R, и соотносить их с визуальной информацией, обрабатываемой Qwen2.5-VL. Это обеспечивает возможность рассуждений о 3D-сценах на основе как лингвистических, так и визуальных данных, создавая основу для более точного и контекстуально-осмысленного взаимодействия с трехмерным миром.
Адаптер Residual Cross-Attention обеспечивает эффективное слияние латентного представления Spa3R с визуальными признаками VLM, что позволяет проводить эффективное рассуждение о 3D-сценах. Данный адаптер использует механизм кросс-внимания для динамического взвешивания и объединения информации из обоих источников, что позволяет модели учитывать как пространственный контекст, полученный от Spa3R, так и визуальные детали, извлеченные VLM. В результате, модель способна более точно интерпретировать 3D-сцены и отвечать на вопросы, требующие понимания пространственных взаимосвязей между объектами.
Модель Spa3-VLM продемонстрировала передовые результаты в области 3D-пространственного рассуждения, достигнув средней точности в 58.6% на бенчмарке VSI-Bench. Данный показатель свидетельствует о значительном прогрессе в способности модели понимать и анализировать трехмерные сцены, превосходя существующие аналоги по эффективности решения задач, требующих пространственного мышления и интерпретации визуальной информации. Достигнутая точность подтверждает эффективность предложенной архитектуры и методов интеграции пространственных данных.
Применение Residual Cross-Attention Adapter позволило добиться прироста точности в +7.5% по сравнению со стратегией наивной конкатенации (appending) пространственных латентных представлений. Дополнительные +3.5% к точности были достигнуты за счет использования унифицированного пространственного представления, предоставляемого Spa3R. Данный адаптер эффективно объединяет информацию из Spa3R и визуальные признаки, что приводит к более эффективному пространственному рассуждению и повышению общей производительности модели.
Внедрение PRoPE (Perspective-aware Representation of Pose Encoding) для кодирования положения камеры обеспечивает дополнительное повышение точности на 1.0%. PRoPE представляет собой метод кодирования, учитывающий перспективу, что позволяет более эффективно передавать информацию о положении камеры модели Spa3-VLM. Это улучшение демонстрирует важность точного представления положения камеры для задач 3D-пространственного рассуждения и подтверждает эффективность PRoPE как компонента для повышения производительности модели в данной области.
К Интеллектуальным Системам с Пространственным Пониманием
Spa3-VLM представляет собой заметный прогресс в создании интеллектуальных систем, способных взаимодействовать и понимать физический мир. Эта технология объединяет визуальную информацию с трехмерным пространственным рассуждением, позволяя машинам не просто «видеть» объекты, но и понимать их положение, форму и взаимосвязи в пространстве. В отличие от традиционных подходов, полагающихся на двухмерные изображения, Spa3-VLM оперирует с полным трехмерным представлением окружения, что значительно повышает точность и надежность работы систем в реальных условиях. Такой подход открывает новые возможности для робототехники, позволяя роботам более эффективно ориентироваться и манипулировать объектами, а также для дополненной реальности, обеспечивая более реалистичное и интерактивное взаимодействие с виртуальными объектами, интегрированными в реальный мир.
Технология Spa3-VLM открывает новые горизонты в областях робототехники, дополненной реальности и автономной навигации. Благодаря способности к глубокому пониманию пространственных взаимосвязей, системы, использующие данную технологию, демонстрируют повышенную надежность и устойчивость в сложных условиях. В робототехнике это позволит создавать роботов, способных эффективно ориентироваться и взаимодействовать с окружающим миром, а в дополненной реальности — создавать более реалистичные и интуитивно понятные интерфейсы. Автономные транспортные средства, оснащенные подобными системами, смогут более безопасно и эффективно перемещаться в динамичной среде, избегая препятствий и адаптируясь к меняющимся условиям. В конечном итоге, Spa3-VLM способствует созданию интеллектуальных систем, способных к более эффективному и надежному функционированию в реальном мире.
Дальнейшие исследования в области Spa3-VLM направлены на расширение возможностей системы за счет обработки более сложных и детализированных пространственных сцен. Планируется интеграция с другими сенсорными модальностями, такими как звук и тактильные ощущения, что позволит системе формировать более полное и точное представление об окружающем мире. Это, в свою очередь, откроет перспективы для создания интеллектуальных систем, способных не только понимать геометрию пространства, но и эффективно взаимодействовать с ним в различных условиях, улучшая производительность в таких областях, как робототехника и автономная навигация.
Исследование демонстрирует стремление к созданию алгоритмов, лишенных эмпирической магии. Авторы, подобно математикам, ищут не просто работающее решение, а доказуемо корректное представление пространства. Как однажды заметил Дэвид Марр: «Визуальная система не просто регистрирует изображения, а активно конструирует представления о мире». Spa3R, предложенный в данной работе, воплощает этот принцип, предсказывая поля признаков и создавая инвариантное к виду пространственное представление. Это не просто улучшение производительности Vision-Language Models, а шаг к более глубокому пониманию того, как системы могут рассуждать о 3D пространстве, основываясь на предсказуемых инвариантах, а не на случайных особенностях входных данных.
Куда двигаться дальше?
Представленный подход, хотя и демонстрирует потенциал предсказательного моделирования пространственных полей, лишь слегка приоткрывает завесу над истинной сложностью трехмерного рассуждения. Очевидно, что надежда на “самообучение” из двумерных изображений — это, в лучшем случае, приближение, а в худшем — элегантная иллюзия. Истинная проверка ждет в условиях неполных данных, зашумленных сценариях и, что наиболее важно, в задачах, требующих не просто распознавания, а понимания причинно-следственных связей в пространстве.
Будущие исследования должны сосредоточиться на интеграции с другими модальностями — тактильными ощущениями, слухом, даже проприоцепцией. Иначе говоря, необходимо выйти за рамки “видения” и перейти к полноценному “ощущению” пространства. Кроме того, необходимо разработать более строгие метрики оценки, которые отражают не просто точность предсказаний, а степень обобщения и устойчивости к изменениям в окружающей среде. Пока же, в хаосе данных спасает только математическая дисциплина.
В конечном счете, вопрос не в том, как заставить машину “видеть”, а в том, как научить ее рассуждать о пространстве так, как это делает человек — с учетом контекста, интуиции и способности к абстракции. И это, разумеется, задача не для инженеров, а для философов, вооруженных теоремами и доказательствами.
Оригинал статьи: https://arxiv.org/pdf/2602.21186.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Российский рынок в зоне турбулентности: рубль, ставки и новые риски (10.04.2026 01:32)
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Honor X80i ОБЗОР: плавный интерфейс, большой аккумулятор, объёмный накопитель
- Canon EOS 80D
- Искусственный интеллект, ориентированный на человека: новый подход
- Proton только что запустил альтернативу Google Workspace и Microsoft 365, ориентированную на конфиденциальность.
- Realme Narzo 70 ОБЗОР: плавный интерфейс, большой аккумулятор, замедленная съёмка видео
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Пермэнергосбыт акции прогноз. Цена PMSB
- 10 лучших OLED ноутбуков. Что купить в апреле 2026.
2026-02-25 21:12