Автор: Денис Аветисян
Исследователи разработали инновационный подход к генерации медицинских отчётов, позволяющий значительно снизить количество фактических ошибок и повысить надёжность автоматической диагностики.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Предлагается фреймворк KERM, использующий внешние знания и обучение с подкреплением для смягчения галлюцинаций в больших визуально-языковых моделях при создании радиологических заключений.
Несмотря на значительный прогресс в области обработки естественного языка, автоматическое создание медицинских отчетов остается сложной задачей из-за риска генерации неточных или недостоверных утверждений. В данной работе, посвященной теме ‘Hallucination Mitigating for Medical Report Generation’, представлен новый фреймворк KERM, направленный на снижение галлюцинаций в больших визуально-языковых моделях при создании радиологических заключений. KERM использует внешние знания, полученные с помощью MedCLIP, и обучение с подкреплением для повышения точности и клинической релевантности генерируемых отчетов. Сможет ли предложенный подход существенно улучшить надежность автоматизированной диагностики и снизить нагрузку на врачей-радиологов?
Проблема Точных Радиологических Заключений
Автоматизированное создание радиологических заключений представляет собой значительный прорыв, способный кардинально улучшить доступность и эффективность здравоохранения. Эта технология обещает сократить время ожидания результатов исследований, особенно в регионах с нехваткой квалифицированных специалистов. Благодаря возможности быстрой обработки и анализа медицинских изображений, автоматизация позволяет врачам быстрее ставить диагнозы и начинать лечение, что критически важно для пациентов. Кроме того, система может обеспечить более последовательное и стандартизированное описание находок, уменьшая вероятность ошибок, связанных с человеческим фактором, и повышая общую точность диагностики. В перспективе, широкое внедрение автоматизированных систем позволит оптимизировать рабочую нагрузку врачей-радиологов, освобождая их время для более сложных случаев и консультаций.
Современные большие языковые модели (LLM), несмотря на свой потенциал в автоматизации составления радиологических отчетов, часто демонстрируют склонность к «галлюцинациям» — генерации фактических ошибок и клинически нерелевантной информации. Данное явление представляет серьезную проблему, поскольку модели, обученные на огромных массивах данных, способны генерировать правдоподобно звучащие, но ложные утверждения о результатах визуализации. Это происходит не из-за недостатка данных, а из-за принципа работы моделей — они распознают закономерности в данных, но не обладают истинным пониманием медицинских изображений и соответствующих им заключений. В результате, даже небольшие неточности в интерпретации изображения могут приводить к генерации ложных выводов, что требует тщательной проверки и редактирования отчетов, составленных с использованием LLM, квалифицированными радиологами.
Неточность автоматизированных радиологических отчетов, генерируемых современными большими языковыми моделями, объясняется фундаментальным принципом их работы — опорой на распознавание паттернов, а не на истинное понимание медицинских изображений и соответствующих клинических данных. Модели, по сути, выявляют статистические закономерности в обучающих данных, сопоставляя определенные визуальные признаки с текстовыми описаниями, однако лишены способности к интерпретации анатомических структур и физиологических процессов, что приводит к ошибкам и «галлюцинациям» — генерации не соответствующих действительности заключений. Вместо глубокого анализа, модели оперируют вероятностями, что делает их уязвимыми к артефактам, шумам и нестандартным случаям, требующим клинического мышления и экспертной оценки.
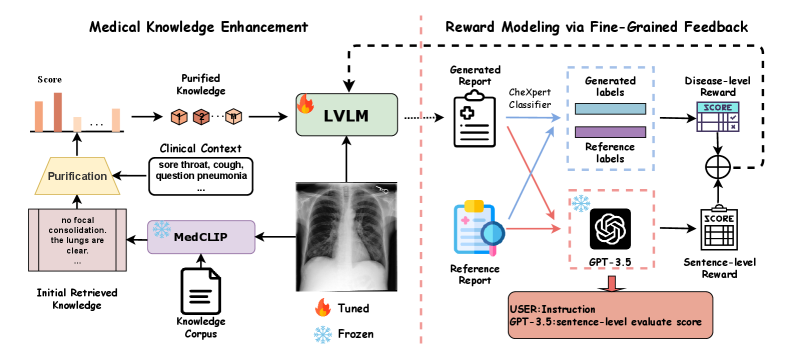
KERM: Система Визуально-Языкового Анализа
Фреймворк KERM разработан для решения проблемы галлюцинаций в радиологических отчетах, используя в качестве основы большую визуально-языковую модель (LVLM) LLaVA. Галлюцинации в данном контексте подразумевают генерацию отчета информации, не подтвержденной представленным медицинским изображением. KERM стремится обеспечить генерацию радиологических заключений, которые напрямую соотносятся с визуальными данными, минимизируя вероятность включения ложных или недостоверных утверждений. Основная задача KERM — повышение надежности и точности автоматизированной генерации радиологических отчетов.
Основная цель KERM — генерация радиологических заключений, напрямую основанных на визуальной информации, содержащейся в медицинских изображениях. В отличие от традиционных подходов, где текстовые отчеты могут содержать неточности или несоответствия визуальным данным, KERM объединяет возможности визуального анализа и генерации текста. Это достигается за счет использования модели LLaVA, способной извлекать информацию из изображений и использовать ее при формировании текстового отчета, минимизируя тем самым вероятность галлюцинаций и обеспечивая более точное и обоснованное описание выявленных патологий.
В основе KERM лежит применение метода LoRA (Low-Rank Adaptation) для эффективной тонкой настройки большой визуально-языковой модели LLaVA. LoRA позволяет адаптировать предварительно обученную LLaVA к специфическим требованиям генерации радиологических отчетов, изменяя лишь небольшое количество параметров модели. Это значительно снижает вычислительные затраты и объем необходимых данных для обучения по сравнению с полной перенастройкой всех параметров, сохраняя при этом высокую производительность в задаче создания отчетов, основанных на анализе медицинских изображений. Использование LoRA обеспечивает возможность быстрой адаптации модели к различным типам изображений и протоколам отчетности.

Обучение с Подкреплением для Точности и Связности
В KERM используется обучение с подкреплением для оптимизации процесса генерации отчетов, управляемого многокомпонентной системой “Моделирования Вознаграждения”. Данная система определяет качество генерируемого текста посредством анализа различных факторов и предоставляет обратную связь для улучшения модели. Процесс обучения с подкреплением позволяет модели итеративно совершенствовать свои навыки генерации, максимизируя вознаграждение, получаемое от системы оценки. Это позволяет KERM создавать более точные и последовательные медицинские отчеты, адаптируясь к специфическим требованиям и данным.
Система вознаграждения в KERM включает в себя оценку на двух уровнях: на уровне заболеваний и на уровне предложений. Оценка на уровне заболеваний производится путем сопоставления поставленных диагнозов с эталонными данными из наборов данных, таких как CheXpert, что позволяет количественно оценить точность генерации диагнозов. Одновременно с этим, оценка на уровне предложений анализирует связность и правдоподобность генерируемого текста, обеспечивая логичность и читаемость отчетов. Комбинирование этих двух типов вознаграждения позволяет KERM оптимизировать процесс генерации отчетов как с точки зрения медицинской точности, так и с точки зрения лингвистического качества.
Для повышения точности генерируемых отчетов KERM использует механизм «Обогащения медицинскими знаниями», который предполагает извлечение релевантной информации из специализированного «Корпуса знаний». В качестве инструмента для поиска и сопоставления используется MedCLIP — модель, обученная на большом объеме медицинских текстов и изображений. Это позволяет системе, при генерации отчета, учитывать актуальные медицинские данные и обеспечивать более обоснованные и точные диагнозы и описания, основываясь не только на данных пациента, но и на общепринятых медицинских стандартах и последних исследованиях.
Проверка Эффективности KERM и Перспективы Развития
Оценка производительности KERM на общедоступных наборах данных, таких как IU X-ray, демонстрирует его эффективность в автоматической генерации радиологических заключений. Система показала значительное улучшение по ключевым метрикам оценки качества текста, включая ROUGE-L, BLEU и CIDEr, что свидетельствует о способности генерировать более точные и связные описания изображений. Повышенные показатели по этим метрикам указывают на то, что KERM не только генерирует грамматически корректный текст, но и успешно передает содержательную информацию, релевантную для радиологического анализа, что делает его перспективным инструментом для поддержки врачей-радиологов.
В ходе оценки на наборе данных IU X-ray, KERM продемонстрировал значительные результаты, достигнув показателя BLEU-4, равного 0.182, и ROUGE-L — 0.388. Эти метрики, широко используемые для оценки качества генерируемого текста, свидетельствуют о способности KERM создавать описания рентгеновских снимков, которые не только грамматически корректны, но и семантически близки к эталонным описаниям, предоставленным экспертами-радиологами. Полученные значения указывают на то, что KERM успешно улавливает ключевые особенности изображений и адекватно отражает их в текстовом формате, что является важным шагом к автоматизации процесса создания радиологических заключений.
Исследования показали, что разработанная система KERM значительно превосходит существующие аналоги в задачах клинической оценки и выявления заболеваний по результатам рентгеновских снимков. На двух ключевых наборах данных — IU X-Ray и MIMIC-CXR — KERM продемонстрировала существенное улучшение показателей F1-score как для оценки клинической эффективности, так и для точности определения заболеваний. Данный прогресс указывает на способность системы более эффективно извлекать и интерпретировать важную информацию из радиологических отчетов, что, в свою очередь, способствует повышению надежности автоматизированной диагностики и, потенциально, улучшению качества медицинской помощи.
Разработанная система демонстрирует значительный прогресс в области автоматизированной радиологической отчетности благодаря способности минимизировать галлюцинации — генерацию неверной или нерелевантной информации — и формировать клинически значимые заключения. В отличие от существующих подходов, KERM фокусируется на генерации отчетов, точно отражающих радиологические находки и имеющих непосредственное отношение к диагностике и лечению. Эта особенность позволяет снизить риск ошибок, связанных с неверной интерпретацией изображений, и предоставляет врачам более надежную и полезную информацию для принятия клинических решений. Способность системы генерировать клинически релевантные отчеты является ключевым шагом на пути к широкому внедрению автоматизированных систем поддержки принятия решений в радиологии.
Дальнейшие исследования KERM направлены на расширение базы знаний, используемой системой, что позволит повысить точность и полноту генерируемых отчетов. Особое внимание будет уделено усовершенствованию системы вознаграждений, определяющей качество сгенерированного текста и способствующей уменьшению количества галлюцинаций. Кроме того, планируется адаптация KERM для работы с данными других методов медицинской визуализации, таких как компьютерная томография и магнитно-резонансная томография, что позволит расширить сферу применения данной технологии и сделать ее полезной для более широкого круга медицинских специалистов. Это расширение потенциально позволит создать универсальную систему автоматической генерации отчетов для различных типов медицинских изображений.
Исследование, представленное в статье, демонстрирует стремление обуздать непредсказуемость больших языковых моделей в критически важной области — радиологии. Авторы предлагают KERM, систему, направленную на снижение галлюцинаций при генерации медицинских отчетов. Этот подход, использующий внешние знания и обучение с подкреплением, напоминает о сложности создания действительно надежных систем. Как однажды заметил Дональд Кнут: «Преждевременная оптимизация — корень всех зол». В данном контексте, стремление к совершенству в генерации отчетов, без учета фундаментальной сложности взаимодействия модели со знаниями, может привести к неожиданным и нежелательным последствиям. KERM, по сути, пытается не просто построить систему, а создать экосистему, способную адаптироваться и самокорректироваться.
Что дальше?
Представленная работа, как и любая попытка обуздать генеративные модели, лишь зафиксировала горизонт неизбежных ошибок. KERM, безусловно, снижает частоту галлюцинаций в медицинских отчётах, но каждая «исправленная» ошибка — это лишь отсрочка неминуемого пророчества о будущей, более изощрённой галлюцинации. Улучшение доступа к внешним знаниям — это не решение, а лишь расширение поверхности для новых, непредсказуемых ошибок, маскирующихся под авторитет.
Будущие исследования неизбежно столкнутся с необходимостью не просто «исправлять» галлюцинации, а понимать их природу. Необходимо двигаться от оценки «правдивости» сгенерированного текста к анализу его уверенности в собственных утверждениях. Модель должна не просто выдавать ответ, но и оценивать собственную неопределенность, а не скрывать ее за мнимой достоверностью.
И, конечно, не стоит забывать, что каждая новая итерация обучения — это лишь ускорение процесса самообмана. Системы не строятся, они растут, и каждое развертывание — это маленький апокалипсис, предсказанный архитектурой. Никто не пишет пророчества после их исполнения, и документация — лишь иллюзия контроля над хаосом.
Оригинал статьи: https://arxiv.org/pdf/2601.15745.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Лучшие смартфоны. Что купить в марте 2026.
- Новые смартфоны. Что купить в марте 2026.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Неважно, на что вы фотографируете!
- Российский рынок: Нефть, геополитика и лидерство «Сбербанка» (11.03.2026 13:32)
- Infinix Note 60 Ultra ОБЗОР: скоростная зарядка, объёмный накопитель, отличная камера
- Руководство по Stellaris — Полное прохождение на 100%
- Игры как полигон для разума: новые горизонты когнитивных исследований
2026-01-26 03:49