Автор: Денис Аветисян
В новой работе представлена прогрессивная система, позволяющая роботам осваивать навыки игры в футбол, от точного движения до адаптации к реальным условиям.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"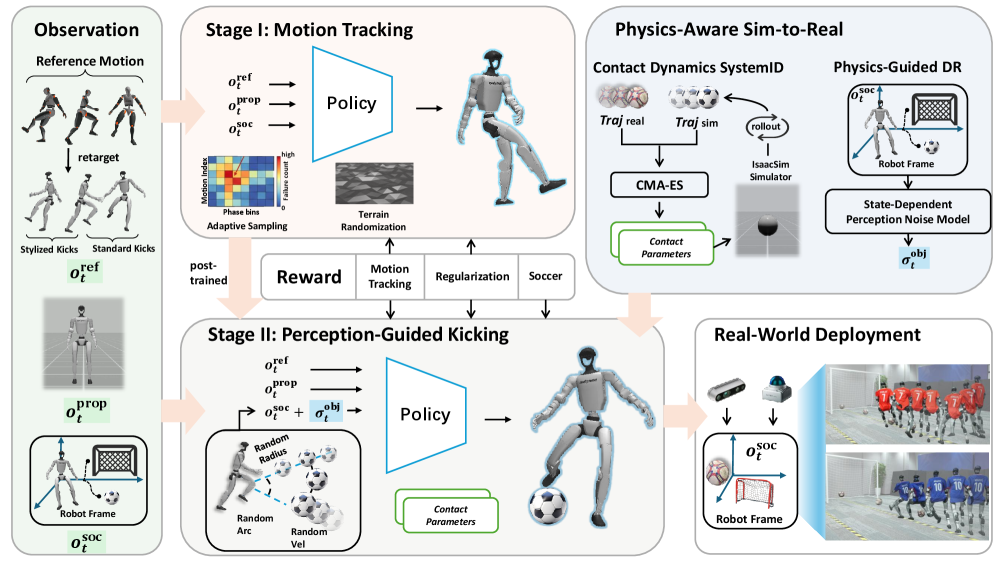
Предложенная PAiD-структура объединяет сбор данных о движении, восприятие окружения и перенос обучения из симуляции в реальный мир для повышения эффективности и надежности футбольных навыков гуманоидных роботов.
Обучение гуманоидных роботов сложным манипуляциям, таким как игра в футбол, представляет собой серьезную проблему из-за необходимости тесной интеграции восприятия и управления. В данной работе, ‘Learning Soccer Skills for Humanoid Robots: A Progressive Perception-Action Framework’, предложен новый подход PAiD, основанный на последовательном обучении — от воспроизведения движений человека до обобщения восприятия и переноса в реальный мир. Этот метод позволяет добиться высокой точности ударов по мячу и устойчивой работы робота в различных условиях, включая неподвижный или катящийся мяч, разные позиции и возмущения. Сможет ли подобный поэтапный подход стать основой для создания более сложных и адаптивных навыков у гуманоидных роботов в широком спектре задач?
Раскрытие Сложности: Футбольные Роботы и Искусство Адаптации
Программирование роботов для игры в футбол представляется задачей, сложность которой часто недооценивается. Успешное выполнение даже базовых действий требует одновременной координации множества факторов: точного восприятия окружающей среды, включая положение мяча и других игроков, выработки оптимальной стратегии действий и, наконец, реализации этих действий посредством сложной системы моторов и сенсоров. Роботы должны не просто двигаться, но и адаптироваться к постоянно меняющейся ситуации на поле, предсказывать траектории движения мяча и соперников, а также координировать свои действия с другими членами команды. Это требует не только разработки сложных алгоритмов управления, но и создания систем, способных к обучению и адаптации в реальном времени, что делает задачу значительно более трудоемкой, чем может показаться на первый взгляд.
Традиционные подходы к программированию роботов для игры в футбол часто сталкиваются с серьезными трудностями из-за высокой размерности и динамичности игровой среды. Огромное количество возможных состояний — положение каждого игрока и мяча, их скорости, углы обзора — создает экспоненциально растущее пространство поиска оптимальных стратегий. Кроме того, непредсказуемость движения мяча и соперников требует от роботов мгновенной адаптации и принятия решений в условиях неопределенности. В результате, алгоритмы, успешно работающие в лабораторных условиях, демонстрируют ограниченную эффективность в реальной игре, где столкновения, изменения освещения и другие факторы вносят значительные помехи. Поэтому, для создания действительно автономных футбольных роботов необходимы новые методы, способные эффективно справляться с этой сложностью и обеспечивать надежную производительность в динамически меняющейся обстановке.
Достижение человеческого уровня ловкости и адаптивности в робототехнике требует принципиально новой методологии освоения и переноса навыков. Традиционные подходы, основанные на жестком программировании каждого движения, оказываются неэффективными в динамичной и непредсказуемой среде, такой как футбольное поле. Вместо этого, исследователи сосредотачиваются на разработке систем, способных к обучению с подкреплением и имитации, позволяющих роботам самостоятельно приобретать и совершенствовать навыки, аналогично тому, как это делают люди. Ключевым аспектом является создание алгоритмов, которые позволяют эффективно переносить полученные навыки из одной ситуации в другую, адаптируясь к изменяющимся условиям и непредсказуемому поведению соперников. Такая гибкость требует интеграции различных методов машинного обучения, включая глубокое обучение и обучение с подкреплением, а также разработки новых архитектур нейронных сетей, способных к быстрому и эффективному обучению.
Определение релевантной информации об окружающей среде, так называемого «пространства наблюдений», является ключевым фактором для эффективного управления роботами-футболистами. Игнорирование или избыточное включение неважных данных может привести к перегрузке системы и снижению её способности к принятию быстрых и точных решений. Правильно спроектированное пространство наблюдений должно содержать только ту информацию, которая непосредственно влияет на текущие и будущие действия робота, такую как положение мяча, позиция соперников и собственные координаты. Оптимизация этого пространства требует тщательного анализа и баланса между полнотой информации и вычислительной сложностью, что напрямую влияет на способность робота адаптироваться к динамично меняющейся игровой ситуации и успешно выполнять поставленные задачи. Именно умение эффективно обрабатывать и интерпретировать релевантные данные позволяет роботу демонстрировать разумное поведение и достигать высоких результатов в соревновательном контексте.
PAiD: Многоэтапный Подход к Совершенству Навыков
В основе PAiD — последовательный трехэтапный подход к обучению человекоподобных роботов игре в футбол. Первый этап, Освоение Двигательных Навыков, фокусируется на изучении базовых навыков, таких как удары по мячу, посредством анализа движений человека и адаптивной выборки данных. Второй этап, Интеграция Восприятия и Действий, направлен на обобщение этих навыков для работы с различными положениями мяча, используя облегченные методы восприятия и систему вознаграждений за выполнение задач. Завершающий этап, Перенос из Симуляции в Реальность, призван обеспечить надежную производительность робота в реальном физическом мире, преодолевая разрыв между виртуальной средой и практическими условиями.
Первоначально, разнообразные навыки ударов по мячу осваиваются на основе демонстраций, выполненных человеком, с использованием технологии отслеживания движений всего тела (Whole-Body Motion Tracking). Этот процесс включает сбор данных о траекториях движений человека при выполнении различных типов ударов. Для повышения эффективности обучения применяется адаптивная выборка (Adaptive Sampling), которая позволяет фокусироваться на наиболее информативных кадрах и движениях, оптимизируя процесс обучения и снижая вычислительные затраты. Адаптивная выборка динамически определяет, какие кадры наиболее важны для освоения навыка, и приоритезирует их обработку, что приводит к более быстрому и точному обучению робота.
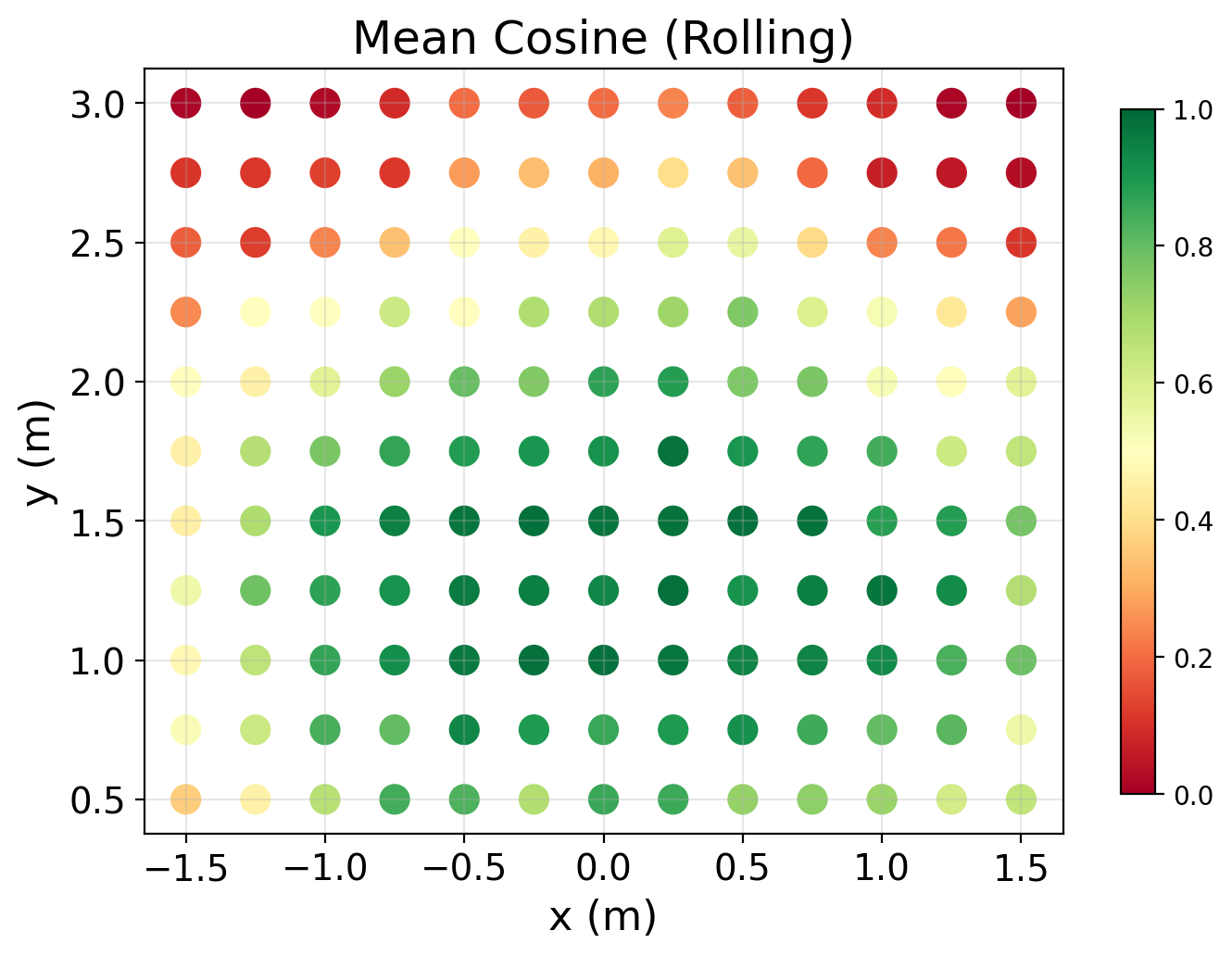
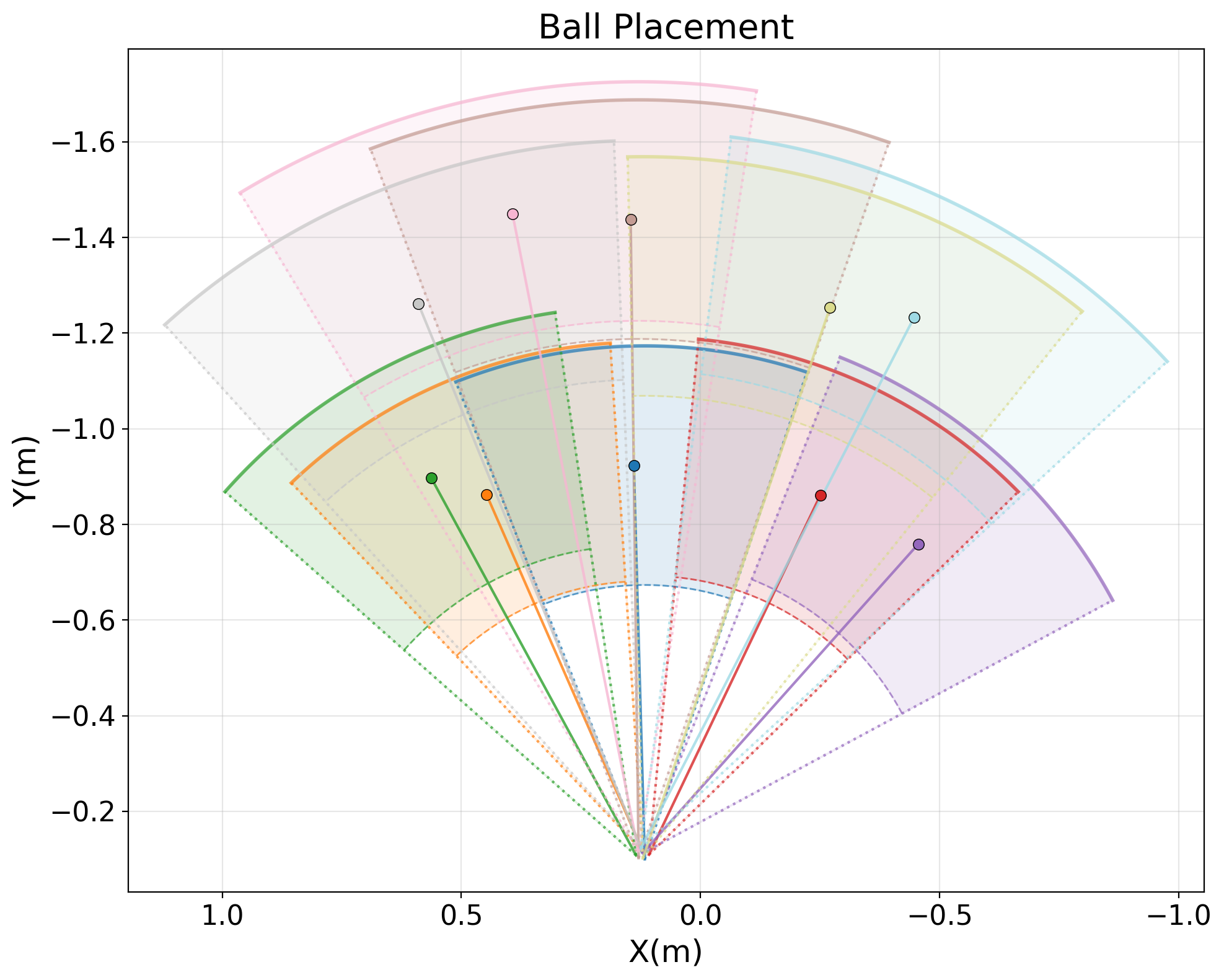
Этап интеграции восприятия и действия использует облегченное восприятие окружающей среды и систему вознаграждений за выполнение задач для обобщения навыков, полученных на предыдущем этапе, на различные положения мяча. Облегченное восприятие позволяет роботу эффективно обрабатывать визуальную информацию, необходимую для определения местоположения мяча, в то время как система вознаграждений стимулирует адаптацию навыков к меняющимся условиям. Это достигается путем предоставления положительных сигналов при успешном выполнении удара по мячу, находящемуся в различных позициях, и корректировки стратегии при неудачных попытках, что способствует повышению надежности и точности выполнения навыков в динамичной среде.
Этап переноса из симуляции в реальный мир (Sim-to-Real Transfer) направлен на преодоление разрыва между виртуальной средой и физической реальностью, обеспечивая надежную работу робота в реальных условиях. В результате применения данного этапа была достигнута эффективность выполнения ударов по мячу на уровне 91.3%, а также успешное перехватывание мяча при движении — 71.9%. Данные показатели демонстрируют способность системы обобщать навыки, полученные в симуляции, и успешно применять их в физическом мире, что является ключевым фактором для достижения высокой производительности в задачах, таких как человекоподобный футбол.
Преодоление Разрыва Реальности: Калибровка и Надежность
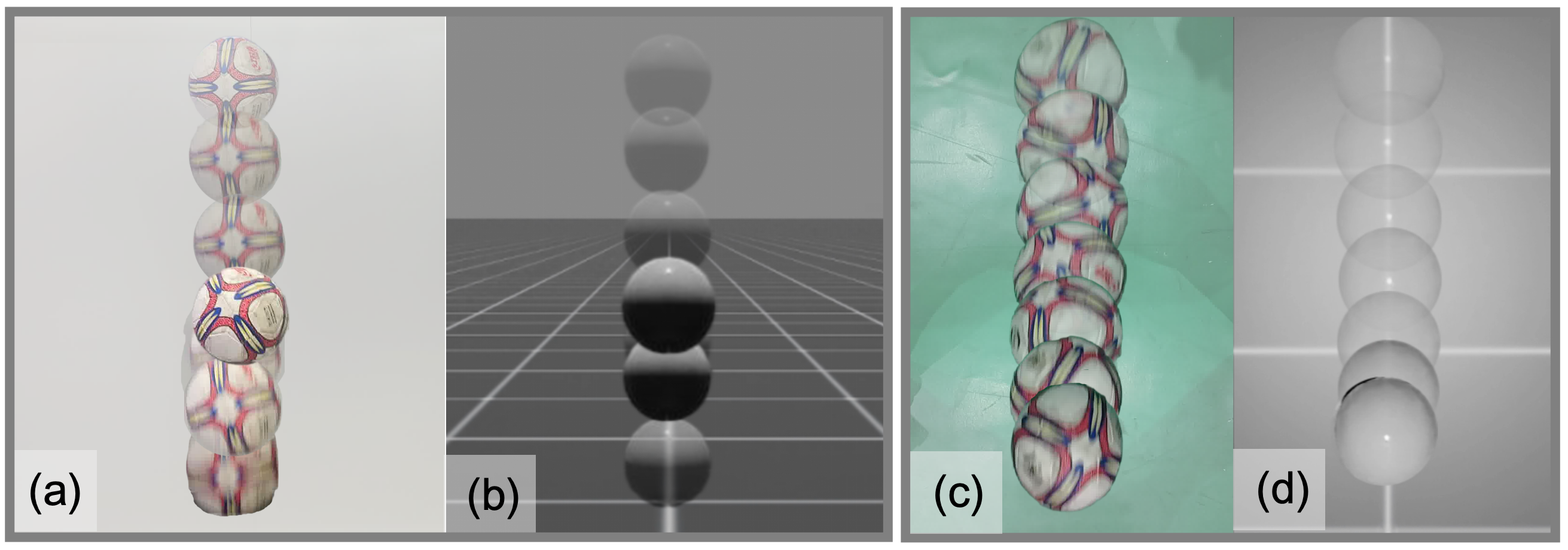
На этапе переноса обучения из симуляции в реальность используется идентификация контактной динамики для калибровки физических свойств мяча в симуляции, что повышает её достоверность. Данный процесс предполагает определение параметров, описывающих взаимодействие мяча с окружающей средой, таких как коэффициент трения и упругости, на основе анализа данных о контактных силах и деформациях. Точная калибровка этих параметров позволяет уменьшить расхождение между поведением мяча в симуляции и в реальном мире, что критически важно для успешного переноса обученной политики управления.
Доменная рандомизация представляет собой метод обучения, при котором в процессе симуляции вводятся случайные вариации параметров окружающей среды и объекта. Эти вариации включают, но не ограничиваются, изменения в текстурах, освещении, трении, массе и других физических характеристиках. Введение таких вариаций позволяет обучить политику (стратегию управления) устойчивость к непредсказуемым условиям, которые могут возникнуть в реальном мире. Это достигается за счет того, что политика обучается обобщать свои действия, а не запоминать конкретные параметры симуляции, что значительно повышает ее надежность при переносе в реальную среду и улучшает способность адаптироваться к непредвиденным обстоятельствам.
Оптимизация параметров симуляции осуществляется посредством стратегии адаптации ковариационной матрицы (CMA-ES). CMA-ES представляет собой алгоритм эволюционной оптимизации, эффективно работающий в высокоразмерных пространствах параметров. В контексте переноса симуляции в реальность, CMA-ES используется для тонкой настройки физических свойств симуляции, таких как масса, трение и упругость, для минимизации расхождений между симуляцией и реальным миром. Алгоритм итеративно модифицирует параметры симуляции, оценивая производительность политики обучения в каждой итерации, и адаптирует ковариационную матрицу для более эффективного поиска оптимальных значений. Это позволяет автоматически находить параметры симуляции, которые максимизируют обобщающую способность обученной политики и обеспечивают успешный перенос навыков в реальную среду.
Процесс переноса навыков осуществляется на основе алгоритма Proximal Policy Optimization (PPO) и формализации задачи как Марковского процесса принятия решений (MDP). Использование PPO в рамках MDP обеспечивает стабильное и эффективное обучение агента в симуляции, что, в свою очередь, позволяет достичь конкурентоспособных или лидирующих показателей средней абсолютной ошибки положения суставов (Global Mean Per-Joint Position Error — G-MPJPE) по сравнению с результатами, полученными с использованием алгоритмов GMT, Any2Track, TWIST2 и BeyondMimic. Данный подход позволяет минимизировать расхождение между обучением в симуляции и реальным миром, обеспечивая надежный перенос навыков.
К Адаптивным и Интеллектуальным Футобольным Роботам
Фреймворк PAiD представляет собой перспективный подход к решению сложных задач для роботов, таких как игра в футбол в человекоподобном формате. Данная архитектура позволяет создавать более адаптивных и интеллектуальных роботов, разбивая сложную задачу на управляемые компоненты и используя современные методы обучения движениям, восприятия и переноса опыта из симуляции в реальный мир. В отличие от традиционных подходов, PAiD не ограничивается жестким программированием поведения, а позволяет роботам обучаться и совершенствоваться в процессе взаимодействия с окружающей средой, что открывает возможности для более гибкого и эффективного выполнения задач в динамичных и непредсказуемых условиях. Благодаря своей модульной структуре и способности к обобщению, PAiD является ключевым шагом на пути к созданию действительно автономных и интеллектуальных роботизированных систем.
Значительный прогресс в создании адаптивных футбольных роботов достигнут благодаря декомпозиции сложной задачи на отдельные компоненты и использованию современных достижений в области обучения движениям, восприятия и переноса опыта из симуляции в реальный мир. Этот подход позволяет роботам не просто выполнять заранее запрограммированные действия, но и обучаться новым навыкам, адаптироваться к меняющимся условиям игры и эффективно взаимодействовать с окружением. Обучение движениям обеспечивает плавность и точность выполнения действий, восприятие позволяет роботу понимать происходящее на поле и принимать обоснованные решения, а перенос опыта из симуляции значительно ускоряет процесс обучения и повышает надежность работы в реальных условиях. Такое сочетание технологий открывает путь к созданию действительно интеллектуальных роботов, способных к самостоятельному обучению и решению сложных задач.
Разработанная методология, изначально протестированная в контексте робофутбола, обладает значительным потенциалом для адаптации к широкому спектру задач, требующих от роботов освоения сложных навыков и обобщения полученного опыта. Принципы декомпозиции задачи, использования современных алгоритмов обучения с подкреплением и эффективного переноса знаний из симуляции в реальный мир применимы к различным сферам, включая промышленные манипуляции, поисково-спасательные операции, а также создание автономных систем для работы в неструктурированной среде. Успешная реализация подобного подхода позволит роботам не просто выполнять заранее запрограммированные действия, а самостоятельно адаптироваться к изменяющимся условиям и эффективно решать новые задачи, значительно расширяя область их применения и повышая степень автономности.
В дальнейшем, исследования сосредоточены на углублении и совершенствовании разработанной PAiD-структуры, с целью раскрытия её полного потенциала. Особое внимание уделяется изучению и внедрению передовых алгоритмов машинного обучения, включая методы обучения с подкреплением и глубокого обучения, для повышения способности роботов адаптироваться к непредсказуемым игровым ситуациям и оптимизировать их поведение. Предполагается, что усовершенствованные алгоритмы позволят значительно улучшить координацию движений, точность выполнения задач и общую эффективность роботов-футболистов, открывая новые возможности для реализации сложных робототехнических систем и расширяя сферу их применения за пределы спортивных соревнований.
Исследование демонстрирует, что создание устойчивых навыков для гуманоидных роботов требует не просто программирования действий, но и формирования целой экосистемы восприятия и адаптации. PAiD, представленный в работе, — это не жесткий алгоритм, а скорее, среда, в которой робот учится, взаимодействуя с окружением и корректируя свои движения. Как говорил Анри Пуанкаре: «Наука не есть совокупность фактов, а совокупность организованных идей». Именно организация, постепенная интеграция восприятия и действий, позволяет роботу не просто выполнить задачу, но и адаптироваться к непредсказуемости реального мира, что особенно важно для сложных навыков, таких как игра в футбол. Этот подход подтверждает мысль о том, что системы растут, а не строятся.
Куда Ведет Игра?
Представленный каркас PAiD, безусловно, демонстрирует прогресс в обучении человекоподобных роботов сложным двигательным навыкам, однако в каждом удачном пасе скрыт страх перед неизбежной деградацией. Иллюзия “прогрессивной интеграции” — лишь отсрочка столкновения с хаосом реального мира. Настоящая проблема не в оптимизации траектории, а в признании, что любая архитектура обречена на вырождение через три релиза, когда меняется освещение или качество газона.
Надежда на “сим-в-реальность” перенос — форма отрицания энтропии. Более плодотворным представляется не стремление к идеальной симуляции, а разработка систем, способных к быстрой адаптации и самовосстановлению. Следующим этапом видится не усложнение моделирования, а создание роботов, способных учиться непосредственно в условиях непредсказуемости, используя ошибки как строительный материал.
В конечном итоге, задача состоит не в создании робота-футболиста, а в понимании, как любая сложная система балансирует между порядком и хаосом. Каждый новый навык — это лишь временная передышка, а настоящая игра — это постоянная борьба с неумолимым ростом неопределенности. И в этой борьбе побеждает не тот, кто строит более сложные модели, а тот, кто умеет быстрее адаптироваться к их неизбежному разрушению.
Оригинал статьи: https://arxiv.org/pdf/2602.05310.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Макросъемка
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Прогнозы цен на эфириум к рублю: анализ криптовалюты ETH
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- MINISFORUM добавляет опцию Ryzen 9 8945HX в линейку мини-ПК MS-A2
- От фотографий к фильмам: полное руководство по переходу на видеосъемку
2026-02-07 00:21