Автор: Денис Аветисян
Новая работа демонстрирует, как научить робота-гуманоида стабильно передвигаться по различной местности, используя только изображения с камеры.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Предлагается комплексный подход, включающий реалистичную дополненную глубину, многокритериальное обучение с подкреплением и дистилляцию поведения для эффективного переноса из симуляции в реальный мир.
Несмотря на значительный прогресс в области робототехники, надежное зрение-ориентированное передвижение гуманоидных роботов остается сложной задачей из-за разрыва между симуляцией и реальностью, а также противоречивых целей обучения. В статье ‘Now You See That: Learning End-to-End Humanoid Locomotion from Raw Pixels’ представлен сквозной фреймворк для обучения гуманоидных роботов на основе визуальных данных, включающий реалистичную аугментацию данных глубины, многокритериальное обучение с подкреплением и дистилляцию поведения. Это позволяет добиться устойчивого и эффективного передвижения по разнообразным типам местности как в симуляции, так и на реальных роботах. Какие еще инновации могут приблизить нас к созданию по-настоящему автономных гуманоидных роботов, способных уверенно ориентироваться в сложных условиях?
Разрыв Между Симуляцией и Реальностью: Эхо Неизбежных Сбоев
Несмотря на значительный прогресс в робототехнике, обеспечение надёжного передвижения роботов в сложных, реальных условиях остаётся сложной задачей из-за устойчивого разрыва между симуляцией и реальностью. Этот феномен, известный как «разрыв между симуляцией и реальностью», возникает из-за существенных расхождений между данными, полученными в контролируемой среде симуляции, и непредсказуемыми вариациями, встречающимися в реальном мире. Роботы, успешно обученные в симуляции, часто демонстрируют значительное снижение производительности при столкновении с шумом, неточностями датчиков и другими непредсказуемыми факторами, характерными для реальной среды. Преодоление этого разрыва является ключевой задачей для создания по-настоящему автономных и надёжных робототехнических систем, способных эффективно функционировать в динамичных и неструктурированных окружениях.
Существенное различие между обучением роботов в симуляции и их работой в реальном мире обусловлено непредсказуемостью данных, получаемых от датчиков глубины. В виртуальной среде параметры окружения и характеристики датчиков известны и контролируемы, что позволяет создавать идеализированные сценарии обучения. Однако, при переносе алгоритмов в реальность, датчики глубины сталкиваются с шумами, отражениями, изменениями освещения и другими факторами, которые приводят к искажению получаемой информации. Эти несоответствия между смоделированными данными и реальными показаниями датчиков создают проблему, известную как «разрыв между симуляцией и реальностью», существенно ограничивающую надежность и эффективность роботизированных систем в неструктурированных средах. Успешное преодоление этого разрыва требует разработки алгоритмов, устойчивых к шумам и способных адаптироваться к изменчивым условиям реального мира.
Современные методы роботизированного восприятия часто сталкиваются с неточностями, вызванными неопределенностью калибровки сенсоров, что критически влияет на их работоспособность в реальных условиях. Несоответствие между идеализированными параметрами калибровки и фактическим состоянием оборудования приводит к искажению данных глубины, получаемых, например, с камер глубины. Это особенно заметно в зашумленной среде, где помехи и отражения ухудшают качество изображения, а ошибки калибровки многократно усиливаются, приводя к снижению точности оценки расстояний и, как следствие, к сбоям в навигации и манипулировании объектами. Таким образом, надежность робототехнических систем напрямую зависит от способности минимизировать влияние неопределенности калибровки и обеспечивать устойчивость к внешним помехам.
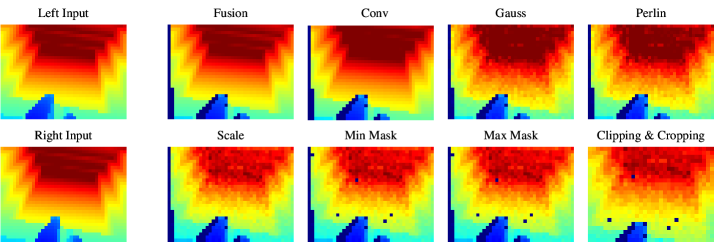
![Дополнительное увеличение глубины на различных типах местности позволяет создавать реалистичные стереоизображения с шумами, зависящими от глубины, и структурированными перлинскими паттернами, сохраняя при этом геометрию местности, необходимую для управления движением, при нормализации значений глубины до [0,2] м и отображении их в виде цветовых карт (холодные цвета - близко, теплые - далеко).](https://arxiv.org/html/2602.06382v1/x7.png)
Реалистичная Аугментация Глубины: Имитация Неизбежных Ошибок
Предлагаемый метод реалистичной аугментации данных о глубине заключается во внесении искусственных шумов и несовершенств в симулированные данные о глубине. Этот подход имитирует ограничения, присущие реальным сенсорам, такие как шум измерения и неточности, возникающие при захвате данных. Внедрение реалистичных артефактов в процессе обучения позволяет повысить устойчивость робота к шумам, встречающимся в реальных условиях, и улучшить обобщающую способность модели при работе с данными, полученными от физических сенсоров. Метод направлен на создание более надежных и адаптивных систем восприятия для робототехники.
Метод расширения данных о глубине использует алгоритм стерео-слияния для создания реалистичных данных, приближенных к тем, что получает реальный сенсор. Для моделирования ограничений сенсоров и шумов, свойственных реальным условиям, в данные о глубине намеренно вводятся шумовые компоненты, зависящие от расстояния до объекта. Дополнительно, для генерации процедурных текстур и повышения реалистичности, применяется алгоритм Перлина, позволяющий создавать плавные и естественные вариации в данных о глубине и имитировать неидеальность сенсорных измерений.
Целью моделирования несовершенств в процессе обучения является повышение устойчивости робота к шумам, возникающим в реальных условиях, и улучшение обобщающей способности. Внедрение искусственных шумов и дефектов в обучающие данные позволяет алгоритмам машинного зрения научиться игнорировать помехи, свойственные реальным датчикам глубины. Это достигается за счет создания более реалистичных сценариев обучения, приближенных к условиям эксплуатации, что позволяет модели лучше адаптироваться к различным типам шумов и повысить точность восприятия в неидеальных условиях. Такой подход позволяет уменьшить разрыв между синтетическими и реальными данными, что критически важно для успешного развертывания робототехнических систем в реальном мире.
Обучение Надежной Локомоции: Зрение и Подкрепление — Путь к Адаптации
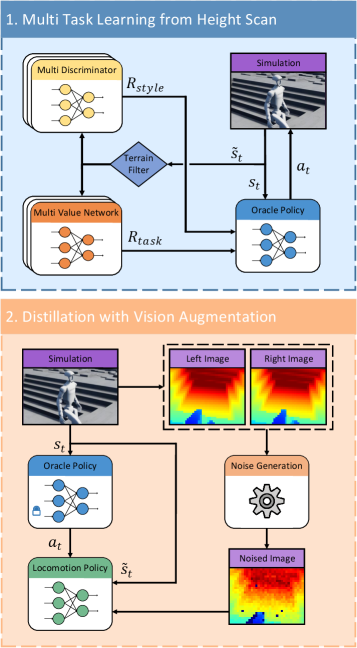
Для обучения политики, обеспечивающей навигацию по сложной местности, используется подход, сочетающий в себе визуальную локомоцию и обучение с подкреплением. В рамках данной системы, робот воспринимает окружающую среду посредством визуальных датчиков, формируя представление о местности. Этот визуальный ввод служит основой для алгоритма обучения с подкреплением, который оптимизирует действия робота с целью максимизации вознаграждения, связанного с успешным перемещением по заданному ландшафту. Обучение происходит итеративно, позволяя роботу адаптироваться к различным типам поверхности и препятствиям, формируя устойчивую стратегию передвижения.
Для повышения эффективности обучения робота передвижению по сложным ландшафтам используется метод обучения с подкреплением на основе нескольких критиков. Вместо использования одного критика для оценки политики, несколько критиков оценивают ее с разных точек зрения, что позволяет более точно учитывать разнообразие условий местности. Дополнительно, применяется формирование вознаграждения, специфичное для типа местности, которое адаптирует функцию вознаграждения в зависимости от характеристик текущей поверхности. Это позволяет направлять поведение робота, поощряя действия, оптимальные для конкретного типа ландшафта, такие как поддержание стабильности на неровной поверхности или минимизация энергозатрат при движении по песку.
Для передачи знаний и генерации естественных, адаптированных к местности, моделей передвижения используется подход, сочетающий многодискриминантные состязательные априорные ограничения на движение и дистилляцию поведения. Многодискриминантные априорные ограничения позволяют обучать политику, различающую реалистичные и нереалистичные траектории движения, основываясь на данных, полученных из различных источников. Дистилляция поведения, в свою очередь, позволяет переносить знания от более сложной или экспертной политики к более простой, что ускоряет обучение и улучшает обобщающую способность робота в различных условиях местности. Данный метод позволяет создавать плавные и эффективные гайты, соответствующие специфике каждой поверхности.
Валидация и Производительность на Реальной Платформе: Эхо Успешной Адаптации
Подтверждение эффективности предложенного подхода было проведено на гуманоидном роботе Unitree G1, где продемонстрирована успешная локомоция на разнообразных, сложных типах местности. Исследование показало, что разработанные алгоритмы позволяют роботу уверенно перемещаться по пересеченной местности, преодолевать препятствия и сохранять устойчивость в динамичных условиях. Данные испытания подтверждают применимость данной методики в реальных сценариях использования гуманоидных роботов, открывая перспективы для их широкого внедрения в различных сферах, требующих автономной навигации и передвижения.
Экспериментальные исследования продемонстрировали значительное повышение надежности предложенного подхода к управлению движением. Средний показатель успешности выполнения задач на разнообразных типах местности достиг 98.9%, что свидетельствует о высокой устойчивости системы к непредсказуемым условиям окружающей среды. При этом, коэффициент ухудшения энергопотребления составил всего 5.8%, что указывает на способность алгоритма эффективно противодействовать искажениям, возникающим в данных, получаемых от сенсоров, и поддерживать стабильную работу даже при наличии помех и неточностей.
Перенос разработанного подхода на гуманоидного робота Unitree G1 продемонстрировал впечатляющую эффективность — 97.8% успешных попыток выполнения заданий с первого раза. Анализ данных, полученных с помощью сканирования высоты местности и метрики KL-дивергенции, позволил установить, что использование дополненных данных существенно сокращает разрыв между симуляцией и реальным миром. Это привело к повышению устойчивости и энергоэффективности локомоции робота в различных условиях, подтверждая эффективность предложенного метода в преодолении сложностей переноса обучения из виртуальной среды в реальную.

Исследование, представленное в данной работе, демонстрирует, как сложная система управления человекоподобным роботом может быть выстроена не как заранее спроектированная структура, а как развивающаяся экосистема. Устойчивость и эффективность передвижения по разнообразной местности достигаются благодаря комбинации методов — реалистичной аугментации глубины, многокритериальному обучению с подкреплением и дистилляции поведения. Этот подход напоминает слова Анри Пуанкаре: «Наука не состоит из ряда заключенных, а из системы, которая постоянно развивается». Подобно тому, как наука стремится к постоянному обновлению, так и эта система управления, построенная на принципах обучения с подкреплением, адаптируется и совершенствуется, демонстрируя, что порядок — это лишь временный кеш между неизбежными сбоями и необходимостью к адаптации.
Что Дальше?
Представленная работа, безусловно, демонстрирует способность системы к адаптации к визуальным данным и навигации по разнообразным поверхностям. Однако, следует помнить: каждая успешно пройденная симуляция — это лишь пролог к неминуемому столкновению с реальностью. Стабильность, достигнутая в контролируемой среде, — это иллюзия, предвещающая крах перед лицом непредсказуемых помех и вариаций. Система не «научилась ходить», она лишь выработала сложный набор рефлексов, готовых к разрушению при малейшем отклонении от ожидаемого.
Более глубокое исследование следует направить не на повышение точности восприятия, а на развитие способности к самовосстановлению и импровизации. Истинный прогресс заключается не в создании «идеального» контроллера, а в проектировании системы, способной извлекать уроки из собственных ошибок и эволюционировать в неожиданных направлениях. Задача не в том, чтобы предсказать будущее сбой, а в том, чтобы создать систему, способную его пережить.
Настоящим вызовом является не преодоление разрыва между симуляцией и реальностью, а признание его неизбежности. Необходимо сместить фокус с оптимизации производительности на проектирование систем, способных к грациозной деградации и непредсказуемой адаптации. И тогда, возможно, удастся создать не просто ходящего робота, а нечто большее — сложную, самообучающуюся экосистему, способную к выживанию в хаотичном мире.
Оригинал статьи: https://arxiv.org/pdf/2602.06382.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Макросъемка
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Российский рынок: между ставкой ЦБ, геополитикой и отчетами компаний (25.03.2026 17:32)
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- От фотографий к фильмам: полное руководство по переходу на видеосъемку
- Три простых изменения в светлой комнате, чтобы создать свой объект съемки.
- Мозг и Искусственный Интеллект: Общая Система Координат
- Motorola Edge 30 Pro ОБЗОР: скоростная съёмка видео, скоростная зарядка, беспроводная зарядка
2026-02-09 19:42