Автор: Денис Аветисян
Новое исследование объединяет зрение и осязание, позволяя роботам лучше понимать и взаимодействовать с окружающим миром.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"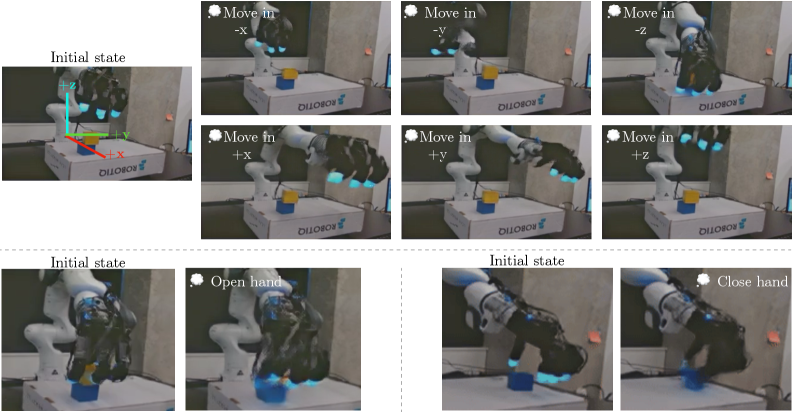
Многозадачная модель мира, объединяющая визуальную и тактильную информацию для повышения точности предсказаний и надежности планирования манипуляций роботами.
Несмотря на значительные успехи в области робототехники, надежное понимание физического взаимодействия остается сложной задачей, особенно в условиях окклюзий и неопределенности. В данной работе представлена концепция ‘Visuo-Tactile World Models’ — многозадачной модели мира, объединяющей зрительную и тактильную информацию для улучшения понимания роботом манипулируемых объектов. Интеграция тактильных ощущений позволяет модели точнее предсказывать динамику контактов, что приводит к повышению точности прогнозирования на 33% и улучшению соблюдения законов движения на 29% в задачах с обратным распространением. Способны ли такие модели стать основой для создания действительно автономных роботов, способных к сложным манипуляциям в реальном мире?
За гранью зрения: Необходимость воплощенного интеллекта
Современные робототехнические системы зачастую чрезмерно полагаются на зрение как основной источник информации для манипулирования объектами, при этом недооценивая критическую роль тактильных ощущений. Такая тенденция приводит к хрупкости и ненадёжности работы роботов в реальных условиях, где визуальная информация может быть неполной, зашумленной или вовсе недоступной. В отличие от человеческого восприятия, где зрение и осязание работают в тесной взаимосвязи, многие роботы лишены возможности «чувствовать» объект — определять его форму, текстуру, твёрдость и вес — что существенно ограничивает их способность к адаптации и выполнению сложных задач, требующих тонкой моторики и чувствительности.
Современные робототехнические системы, чрезмерно полагающиеся на зрение, демонстрируют хрупкость в сложных, реальных условиях. Неполнота или ненадежность визуальной информации, возникающая из-за плохого освещения, заслонений или динамически меняющейся среды, приводит к сбоям в манипуляциях и навигации. В ситуациях, когда визуальные данные недостаточны для точного определения формы, текстуры или устойчивости объекта, робот оказывается неспособным успешно выполнить задачу. Это особенно заметно при работе с деформируемыми объектами, неровными поверхностями или в условиях, требующих адаптации к непредвиденным изменениям окружающей среды, подчеркивая необходимость разработки более надежных систем, способных эффективно функционировать даже при ограниченном визуальном восприятии.
Для создания по-настоящему интеллектуального робота необходимо объединение зрительной и тактильной информации, позволяющее ему эффективно ориентироваться и взаимодействовать с окружающим миром. Простое восприятие визуальных данных зачастую оказывается недостаточным в сложных, динамично меняющихся условиях реальной среды. Робот, способный интегрировать данные от зрения и осязания, получает более полное и надежное представление об объектах, их свойствах и взаиморасположении. Это позволяет ему не только распознавать предметы, но и понимать, как с ними обращаться, адаптируясь к различным поверхностям, формам и текстурам. Такой подход обеспечивает более гибкое и надежное поведение в условиях неопределенности, позволяя роботу успешно выполнять задачи манипулирования и навигации даже при частичной потере визуальной информации.
Создание действительно интеллектуальной роботизированной системы требует не просто сбора данных от различных сенсоров, а их бесшовной интеграции и синергетического использования. Проблема заключается в том, чтобы разработать алгоритмы, способные эффективно объединять визуальную информацию с тактильными ощущениями, извлекая максимум пользы из сильных сторон каждой модальности. Видение обеспечивает общее понимание сцены и обнаружение объектов, в то время как тактильные сенсоры предоставляют детальную информацию о форме, текстуре и силе взаимодействия. Успешное сочетание этих данных позволит роботу не только распознавать объекты, но и манипулировать ими с высокой точностью и надежностью, даже в условиях неполной или искаженной визуальной информации, что критически важно для работы в реальном мире и выполнения сложных задач.
Визуально-тактильная модель мира: Единое представление
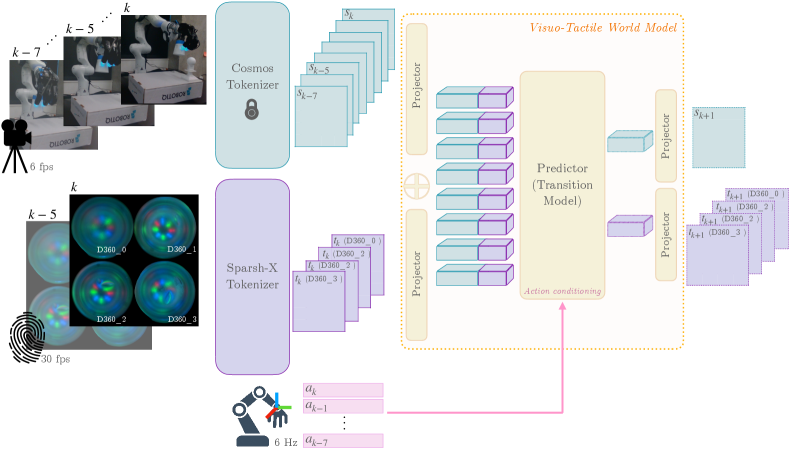
Визуально-тактильная модель мира (VT-WM) преодолевает ограничения, присущие подходам, основанным исключительно на зрении, путем интеграции тактильной обратной связи в свою предсказательную структуру. Традиционные системы, полагающиеся только на визуальные данные, испытывают трудности в ситуациях с частичной видимостью, сложными текстурами или при взаимодействии с деформируемыми объектами. Включение тактильной информации позволяет VT-WM формировать более полное и надежное представление об окружающей среде, что критически важно для успешного планирования и выполнения манипуляций, особенно в условиях неопределенности и сложности.
Для создания единого скрытого представления окружающей среды, модель VT-WM использует как Vision Encoder (например, Cosmos Tokenizer), обрабатывающий визуальную информацию, так и Tactile Encoder (например, Sparsh), кодирующий тактильные ощущения. Vision Encoder преобразует визуальные данные в компактное векторное представление, отражающее геометрические и семантические характеристики сцены. Аналогично, Tactile Encoder преобразует данные, полученные от тактильных датчиков, в векторное представление, описывающее контактные силы, текстуру поверхности и другие тактильные свойства объекта. Эти два векторных представления затем объединяются и обрабатываются для формирования единого скрытого состояния, которое служит обобщенным представлением окружающей среды, учитывающим как визуальную, так и тактильную информацию.
Для планирования и выполнения сложных манипуляций, объединенное латентное представление, сформированное визуальным и тактильным кодировщиками, используется в модели динамики, обусловленной действиями (Action-Conditioned Dynamics Model). Эта модель предсказывает будущие состояния окружающей среды на основе текущего состояния и выбранного действия робота. Прогнозируемые состояния позволяют роботу симулировать различные сценарии и выбирать оптимальную последовательность действий для достижения заданной цели. Модель динамики обучается предсказывать изменения в латентном пространстве, что позволяет ей эффективно обобщать на новые ситуации и обеспечивать надежное планирование движений даже в условиях неопределенности.
Архитектура Visuo-Tactile World Model (VT-WM) разработана с учетом соответствия физическим законам (Physical Laws Compliance), что обеспечивает реалистичность и физическую правдоподобность прогнозируемых состояний окружающей среды. Это достигается за счет включения в модель ограничений, основанных на принципах динамики и механики, таких как сохранение энергии и импульса. Соблюдение этих принципов критически важно для надежного планирования действий робота и предотвращения нереалистичных или невозможных сценариев манипулирования объектами. В частности, VT-WM стремится минимизировать нарушения физических законов в предсказанных траекториях и взаимодействиях, что повышает устойчивость и безопасность роботизированных систем.
Проверка модели: Предсказание и обобщение
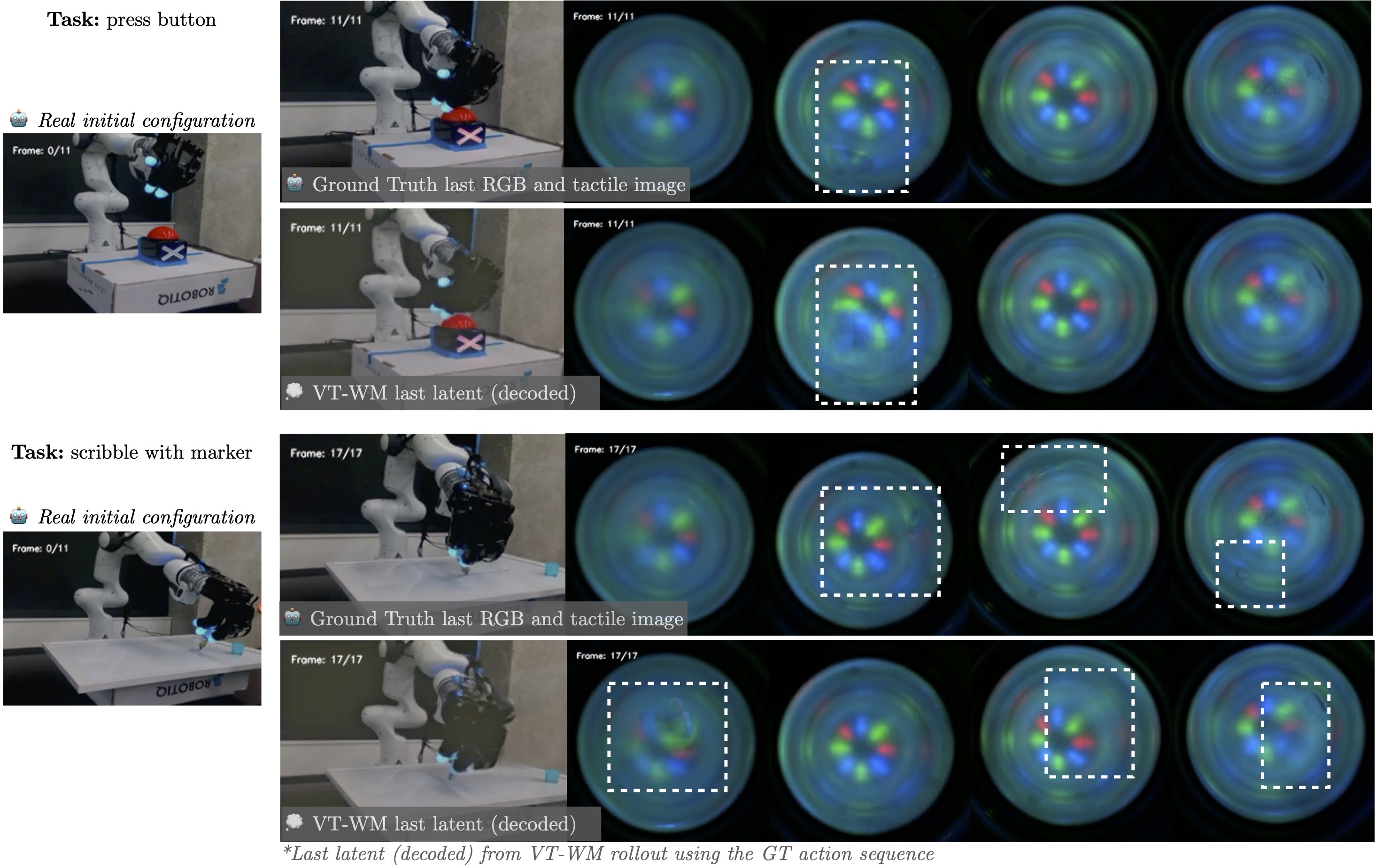
Для валидации точности предсказаний VT-WM используются Авторегрессионные Развертки (Autoregressive Rollouts), представляющие собой итеративный процесс генерации последовательных будущих состояний системы. В ходе развертки модель предсказывает следующее состояние на основе текущего, а затем использует это предсказанное состояние для прогнозирования следующего, и так далее. Этот процесс позволяет оценить способность модели предсказывать динамику системы на протяжении определенного периода времени, без использования реальных данных для этих будущих состояний. Каждая развертка представляет собой траекторию, сгенерированную моделью, которая затем сравнивается с наблюдаемыми траекториями для количественной оценки точности предсказаний.
Для количественной оценки сходства между сгенерированными в процессе Autoregressive Rollouts траекториями и реальными наблюдаемыми траекториями используется метрика Fréchet Distance. Данная метрика вычисляет расстояние между распределениями признаков, представленных в виде векторов, извлеченных из сгенерированных и реальных данных. Меньшее значение Fréchet Distance указывает на более высокую степень соответствия между предсказанными и фактическими траекториями, что свидетельствует о лучшей способности модели к прогнозированию динамики взаимодействия с объектами. Использование Fréchet Distance позволяет проводить объективное сравнение производительности модели в различных сценариях и при различных условиях.
Модель VT-WM демонстрирует высокую точность предсказания динамики контакта, полей сил, состояний скольжения и даже текстуры объектов. Это достигается за счет способности модели эффективно экстраполировать физические свойства и взаимодействие объектов на основе визуальных данных. В частности, VT-WM способна предсказывать возникающие силы при контакте, распределение нагрузки и потенциальные точки скольжения, что критически важно для задач манипулирования. Точность предсказания текстуры объектов позволяет модели более эффективно оценивать сцепление и обеспечивать надежный захват, что подтверждается результатами экспериментов и количественными метриками.
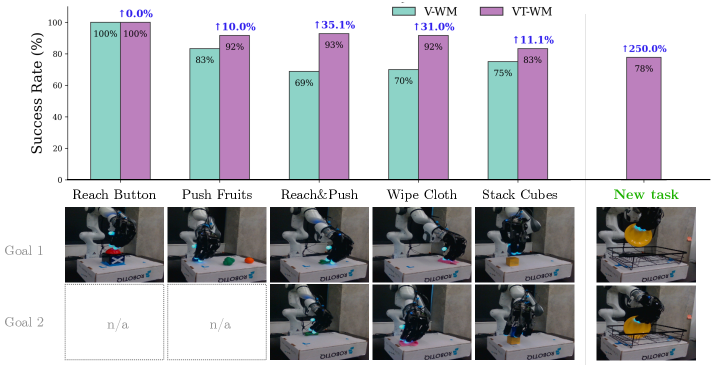
Модель VT-WM демонстрирует высокую эффективность в планировании задач без предварительного обучения (Zero-Shot Planning), позволяя выполнять новые манипуляции без использования данных, специфичных для данной задачи. В контактных задачах, требующих взаимодействия с объектами, VT-WM показывает на 35% более высокую вероятность успешного выполнения по сравнению с моделями, основанными исключительно на визуальной информации. Данный результат указывает на способность модели к обобщению знаний и адаптации к новым ситуациям, не требующим дополнительной тренировки.
В ходе сравнительного анализа, модель VT-WM продемонстрировала улучшение на 33% в понимании постоянства объектов и на 29% в соблюдении законов физики, по сравнению с моделью, основанной исключительно на визуальном восприятии. Данные улучшения были зафиксированы в ходе тестов, направленных на оценку способности модели предсказывать поведение объектов и учитывать гравитацию, инерцию и другие физические принципы при взаимодействии с ними. Повышенная точность в этих областях свидетельствует о более глубоком понимании моделью мира и ее способности к надежному планированию действий в сложных сценариях.
Повышение устойчивости: Сила многозадачного обучения
Визуально-тактильная модель мира (VT-WM) обучается с использованием многозадачного обучения, что позволяет ей одновременно прогнозировать различные физические явления. Вместо фокусировки на отдельной задаче, модель параллельно осваивает предсказание таких параметров, как положение объектов, их скорость, текстуру поверхности и силу прикосновения. Такой подход стимулирует развитие общих представлений о физическом мире, позволяя модели извлекать пользу из взаимосвязей между различными сенсорными модальностями и задачами. В результате, VT-WM не просто решает конкретную проблему, а формирует более глубокое и универсальное понимание окружающей среды, что критически важно для надежного и адаптивного поведения роботов в реальных условиях.
Обучение модели с использованием многозадачного подхода значительно повышает её способность к обобщению и адаптации к новым, ранее не встречавшимся ситуациям. Вместо того, чтобы решать каждую задачу изолированно, модель одновременно учится прогнозировать различные физические явления, выявляя общие закономерности и формируя универсальные представления о мире. Этот процесс позволяет эффективно использовать общие признаки, свойственные разным задачам, что снижает потребность в большом количестве данных для каждой отдельной задачи и улучшает производительность в целом. В результате, модель не просто запоминает конкретные примеры, а приобретает глубокое понимание принципов, лежащих в основе этих явлений, что делает её более устойчивой к изменениям и способной успешно функционировать в разнообразных условиях.
Модель демонстрирует значительное улучшение способности к сохранению объекта в представлении, даже когда он временно скрыт из виду. Это свойство, известное как перманентность объекта, является ключевым аспектом когнитивного развития и необходимо для надежного взаимодействия с окружающей средой. В ходе обучения модель научилась поддерживать внутреннее представление объекта, основываясь на предыдущих наблюдениях и предсказывая его возможное местоположение, даже когда прямая видимость отсутствует. Это позволяет ей эффективно ориентироваться в сложных сценариях, где объекты могут временно пропадать из поля зрения, и продолжать взаимодействовать с ними после их повторного появления, что значительно повышает надежность и адаптивность роботизированного поведения.
Визуально-тактильная модель мира (VT-WM) формирует целостное и устойчивое представление об окружающей среде посредством одновременной обработки зрительной и тактильной информации. Такой подход позволяет модели не просто «видеть» объекты, но и «ощущать» их свойства, например, форму, текстуру и вес, даже в условиях ограниченной видимости или при частичном перекрытии. Это существенно повышает надежность и адаптивность роботизированных систем, позволяя им более эффективно взаимодействовать с объектами и ориентироваться в сложных, динамично меняющихся условиях. Модель, интегрируя различные сенсорные данные, создает более точную и полную картину мира, что способствует принятию более обоснованных решений и выполнению задач с повышенной точностью и гибкостью.

Работа представляет собой попытку обуздать хаос, свойственный взаимодействию робота с миром. Создание мультимноговисной Визуо-Тактильной Мировой Модели (VT-WM) — это не просто интеграция зрения и тактильных ощущений, а стремление к предвидению, к возможности моделировать последствия действий. В этом контексте, слова Барбары Лисков: «Хороший дизайн — это предвидение будущего, а не просто решение текущих проблем» приобретают особое значение. Предложенная модель, опираясь на физику контакта, стремится не просто реагировать на изменения, но и предсказывать их, что, в свою очередь, обеспечивает более надежное планирование и манипулирование объектами. Это не архитектура ради архитектуры, а способ откладывать неизбежные сбои, увеличивая окно возможностей для успешного взаимодействия.
Что же дальше?
Представленная работа, как и многие другие, пытается обуздать неуловимую природу предсказания. Мир моделей, визуальных и тактильных, лишь отсрочивает неизбежное столкновение с хаосом реального взаимодействия. Улучшение точности предсказаний — это не победа над сложностью, а лишь усложнение инструментов для ее описания. Каждая новая архитектура, каждый новый слой нейронной сети — это пророчество о будущей, неминуемой ошибке, о краевом случае, который система не учтет.
Не стоит обольщаться возможностью создания «универсальной» модели манипуляций. Физический мир, с его бесконечным разнообразием материалов и сил, не поддается полной формализации. Акцент сместится не на достижение абсолютной точности, а на разработку систем, способных гибко адаптироваться к неожиданностям, к непредсказуемым изменениям в окружающей среде. Важнее не предсказать будущее, а научиться быстро восстанавливаться после неизбежного провала предсказания.
В конечном итоге, архитектура — это не структура, а компромисс, застывший во времени. Технологии сменяются, зависимости остаются. Истина не в совершенстве модели, а в понимании ее границ. Попытки создать «идеальный» мир моделей — это, в лучшем случае, иллюзия, а в худшем — путь к еще большей хрупкости и уязвимости систем.
Оригинал статьи: https://arxiv.org/pdf/2602.06001.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Макросъемка
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- Обзор вспышки Yongnuo YN500EX
2026-02-06 12:33