Автор: Денис Аветисян
Исследователи разработали систему, позволяющую роботам предсказывать точки контакта с объектами на основе лингвистических команд, значительно повышая точность и стабильность захвата.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Представлен DextER — фреймворк, использующий модели обработки языка и визуальной информации для генерации надежных и интерпретируемых схем захвата объектов.
Несмотря на успехи в области зрения и языка, генерация надежных и интерпретируемых захватов для роботизированных манипуляторов остается сложной задачей. В данной работе представлена система ‘DextER: Language-driven Dexterous Grasp Generation with Embodied Reasoning’, которая предлагает новый подход к генерации захватов, основанный на предсказании точек контакта между рукой и объектом. Ключевая идея заключается в использовании контактного представления, связывающего семантику задачи с физическими ограничениями, для обеспечения более стабильного и управляемого захвата. Способно ли такое воплощенное рассуждение значительно улучшить возможности роботов в реальных сценариях манипулирования?
Преодолевая Разрыв Между Видением и Действием: Задача Ловкого Захвата
Традиционные методы захвата объектов роботами зачастую опираются на заранее запрограммированные схемы или упрощенные модели, что значительно ограничивает их применимость в реальных условиях. Такой подход предполагает, что все объекты можно захватить одним из нескольких предопределенных способов, игнорируя разнообразие форм, размеров, веса и текстур. В результате, роботы испытывают трудности при работе с незнакомыми предметами или в динамически меняющейся среде, где требуется гибкость и способность адаптироваться к новым условиям. Отсутствие адаптивности приводит к неустойчивым захватам, повреждению объектов или полной неудаче манипуляции, что является серьезным препятствием для широкого внедрения роботов в производственные процессы и повседневную жизнь.
Успешная манипуляция разнообразными объектами требует от роботизированных систем не только распознавания визуальной информации, но и глубокого понимания тонкостей физического взаимодействия. Исследования показывают, что простая идентификация формы и размера объекта недостаточна для надежного захвата и перемещения. Необходимо учитывать такие параметры, как вес, текстура, жесткость и распределение массы, а также прогнозировать реакцию объекта на приложенные силы. Роботы, способные интегрировать визуальные данные с тактильной обратной связью и моделями физического поведения, демонстрируют значительно более высокую эффективность и адаптивность в сложных условиях. Разработка подобных систем открывает перспективы для автоматизации широкого спектра задач — от сборки прецизионных механизмов до помощи в быту и медицинских манипуляциях.
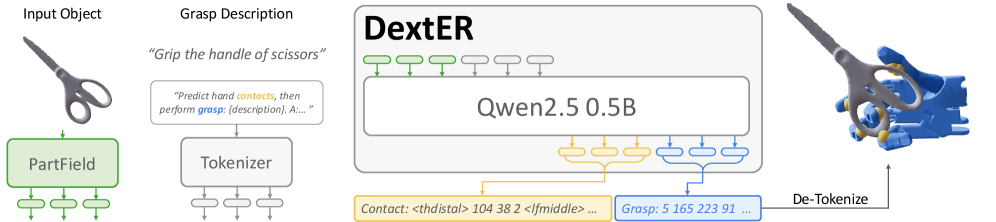
DextER: Контактное Воплощенное Рассуждение для Надежного Захвата
DextER представляет собой новый подход к планированию захвата объектов, основанный на моделировании контактов и воплощенном рассуждении. В отличие от традиционных методов, которые часто полагаются на анализ изображений или облаков точек, DextER явно моделирует потенциальные точки контакта между захватом и объектом. Это позволяет системе предсказывать стабильные конфигурации захвата, учитывая физические взаимодействия и геометрию объекта. Используя принципы воплощенного рассуждения, DextER оценивает влияние различных контактов на стабильность захвата, что повышает надежность и устойчивость к изменениям в окружающей среде. Данный подход позволяет предсказывать успешные захваты даже в сложных и зашумленных сценариях.
Система DextER осуществляет прогнозирование стабильных конфигураций захвата путём явного моделирования потенциальных точек контакта между манипулятором и объектом. Этот подход позволяет предвидеть физические взаимодействия в процессе захвата, учитывая геометрию объекта и характеристики манипулятора. Явное представление точек контакта используется для оценки устойчивости захвата и прогнозирования возможных отклонений от запланированной траектории. На основе этих оценок, система корректирует план захвата в реальном времени, оптимизируя положение и ориентацию захвата для обеспечения надёжного удержания объекта и предотвращения его выскальзывания или повреждения.
Метод DextER использует авторегрессионную генерацию для создания последовательностей действий, обеспечивающих захват объектов. В процессе захвата, система прогнозирует следующее действие, основываясь на текущем состоянии и предыдущих шагах. Эта рекурсивная процедура позволяет формировать более естественные и адаптивные стратегии захвата, так как система динамически реагирует на изменения в окружающей среде и свойствах объекта. Использование авторегрессии позволяет генерировать последовательности действий переменной длины, что необходимо для успешного захвата объектов различной формы и размера, а также для преодоления препятствий в процессе захвата.

Масштабирование Интеллекта Захвата с Помощью Данных и Токенизации
Обучение DextER осуществлялось на масштабных наборах данных DexGYS и Dexonomy, включающих в себя обширную коллекцию примеров захватов объектов и соответствующих им текстовых описаний. DexGYS содержит разнообразные сценарии захвата, охватывающие различные формы объектов и условия окружающей среды, что позволяет модели обобщать навыки захвата. Dexonomy, в свою очередь, предоставляет детальные языковые аннотации для каждого захвата, описывающие намерения и особенности выполнения, что способствует улучшению понимания и контроля со стороны модели. Совокупность этих данных обеспечивает надежную основу для обучения и оценки эффективности DextER в задачах манипулирования объектами.
Для повышения эффективности и снижения вычислительной сложности, система DextER использует дискретизацию параметров действий и токенизацию позиций контакта. Непрерывные параметры захвата, определяющие действия манипулятора, преобразуются в дискретные токены, представляющие собой конечное число возможных значений. Аналогично, позиции точек контакта между объектом и манипулятором также кодируются в виде дискретных токенов. Такой подход позволяет уменьшить размер пространства поиска при планировании захвата и оптимизировать процесс обучения модели, поскольку вместо работы с непрерывными значениями используются дискретные представления.
В архитектуре DextER используется языковая модель Qwen2.5 для обеспечения более тонкого управления и обобщающей способности системы. Интеграция Qwen2.5 позволяет преобразовывать языковые инструкции в конкретные действия манипулятора, обеспечивая гибкость в управлении захватом объектов. В отличие от традиционных подходов, основанных на жестко заданных параметрах, языковая модель позволяет DextER адаптироваться к различным сценариям и выполнять манипуляции, соответствующие заданным требованиям, даже при неполной или неоднозначной информации. Это способствует повышению надежности и эффективности захвата в различных условиях, а также расширяет возможности системы для решения более сложных задач манипулирования.
В ходе тестирования на бенчмарке DexGYS, разработанная система продемонстрировала 67.14% успешности захвата объектов. Данный показатель на 3.83 процентных пункта превышает результаты, достигнутые ранее лидирующими решениями в данной области. Это подтверждает эффективность предложенного подхода к управлению захватом и его превосходство над существующими аналогами в задачах манипулирования объектами.
Система DextER демонстрирует значительное улучшение соответствия намерению пользователя, достигающее 96.4% по сравнению с предыдущими методами. Это измеряется с помощью метрики P-FID (Perceptual Fréchet Inception Distance), значение которой для DextER составляет 0.20. Более низкое значение P-FID указывает на более высокую степень соответствия между предсказанными и целевыми траекториями захвата, что свидетельствует о лучшем понимании системой желаемого действия и более точном его выполнении.

Повышение Реалистичности и Обобщения Через Физику и Видение
Для повышения реалистичности и обобщающей способности модели DextER используются аннотации, основанные на физике контактов, генерируемые с помощью симулятора MuJoCo. Эти аннотации служат фундаментальной основой, позволяющей системе лучше понимать физические взаимодействия объектов. MuJoCo обеспечивает точное моделирование контактов, что позволяет DextER обучаться на реалистичных сценариях и эффективно прогнозировать последствия манипуляций. В результате, модель приобретает способность к более надежному и точному выполнению сложных задач, связанных с захватом и перемещением объектов в различных условиях, значительно превосходя существующие аналоги в понимании физических принципов, лежащих в основе манипуляций.
Для обработки трехмерных визуальных данных в DextER используется энкодер облака точек, основанный на PartField. Этот подход позволяет системе формировать детальное и богатое представление геометрии объектов, выходящее за рамки традиционных двухмерных изображений. PartField, в частности, эффективно кодирует информацию о форме и структуре объекта, предоставляя DextER необходимую информацию для планирования сложных манипуляций. Благодаря этому, система способна не только распознавать объекты, но и понимать их пространственное расположение и характеристики, что критически важно для успешного взаимодействия с окружающим миром и выполнения поставленных задач.
Система DextER использует концепцию “Воплощенной Цепи Рассуждений” (Embodied Chain-of-Thought, ECoT) для значительного расширения своих возможностей планирования и выполнения сложных манипуляций с объектами. В отличие от традиционных подходов, ECoT позволяет системе не просто реагировать на текущую ситуацию, но и формировать последовательность действий, предвидя последствия каждого шага. Этот процесс включает в себя декомпозицию сложной задачи на более простые подзадачи, планирование действий для решения каждой из них и последующее выполнение этого плана в физическом мире. Такой подход позволяет DextER успешно справляться с задачами, требующими не только точного исполнения, но и способности адаптироваться к изменяющимся условиям и непредсказуемым событиям, демонстрируя более высокий уровень автономности и надежности в процессе манипулирования объектами.
Система DextER демонстрирует передовые результаты в области манипулирования объектами, достигая значения метрики Chamfer Distance (CD) в 1.46. Это значение указывает на высокую точность восстановления формы объекта после манипуляций, превосходящее показатели других существующих систем. Метрика CD измеряет среднее расстояние между точками на восстановленной и исходной поверхностях объекта, и более низкое значение свидетельствует о лучшем качестве реконструкции. Достижение такого результата подтверждает эффективность предложенных методов обработки 3D-данных и планирования движений, открывая новые возможности для автоматизированного манипулирования в различных областях, включая робототехнику и компьютерное зрение. Данный показатель служит важным ориентиром для дальнейшего развития алгоритмов, стремящихся к более реалистичному и точному взаимодействию с окружающим миром.
Исследование, представленное в данной работе, демонстрирует стремление к элегантности в решении сложной задачи манипулирования объектами. Разработанная система DextER, предсказывая точки контакта между рукой и объектом, воплощает идею о том, что истинная эффективность алгоритма определяется не количеством строк кода, а его способностью к масштабированию и устойчивости. Как однажды заметил Пол Эрдеш: «Математика — это искусство предвидеть». В контексте DextER, это предвидение проявляется в способности модели прогнозировать взаимодействие руки и объекта, обеспечивая стабильность и интерпретируемость захвата, что является важным шагом к созданию действительно интеллектуальных робототехнических систем.
Куда Далее?
Без чёткой аксиоматизации задачи манипулирования, любое решение, даже кажущееся успешным, остаётся лишь статистическим шумом. Представленная работа, безусловно, представляет шаг вперёд в предсказании точек контакта, однако, необходимо признать, что предсказание — это не объяснение. Алгоритм должен доказывать свою состоятельность, а не просто демонстрировать работоспособность на ограниченном наборе данных. Следующим этапом представляется разработка формальной логики, описывающей принципы стабильного захвата, применимой к различным формам и материалам объектов.
Очевидным ограничением является зависимость от визуальной информации. Представление о «понимании» объекта, основанное исключительно на пикселях, — это иллюзия. Следует исследовать возможности интеграции тактильных сенсоров и моделей физического взаимодействия, что позволит алгоритму строить внутреннюю, доказанную модель объекта, а не полагаться на неполные и подверженные шуму данные. В противном случае, мы обречены на создание сложных, но хрупких систем, неспособных к адаптации.
Наконец, необходимо признать, что задача манипулирования — это лишь частный случай более общей задачи — задачи планирования действий в сложном, неопределённом мире. Настоящий прогресс потребует разработки универсальных алгоритмов, способных к логическому выводу и доказательству корректности своих действий, а не просто к статистической оптимизации. Иначе, все наши усилия останутся лишь изящной, но бессмысленной игрой с числами.
Оригинал статьи: https://arxiv.org/pdf/2601.16046.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Лучшие смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
2026-01-23 17:00