Автор: Денис Аветисян
Представлена новая платформа HoloBrain-0, объединяющая возможности восприятия, языка и действий для достижения передовых результатов в робототехнике.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"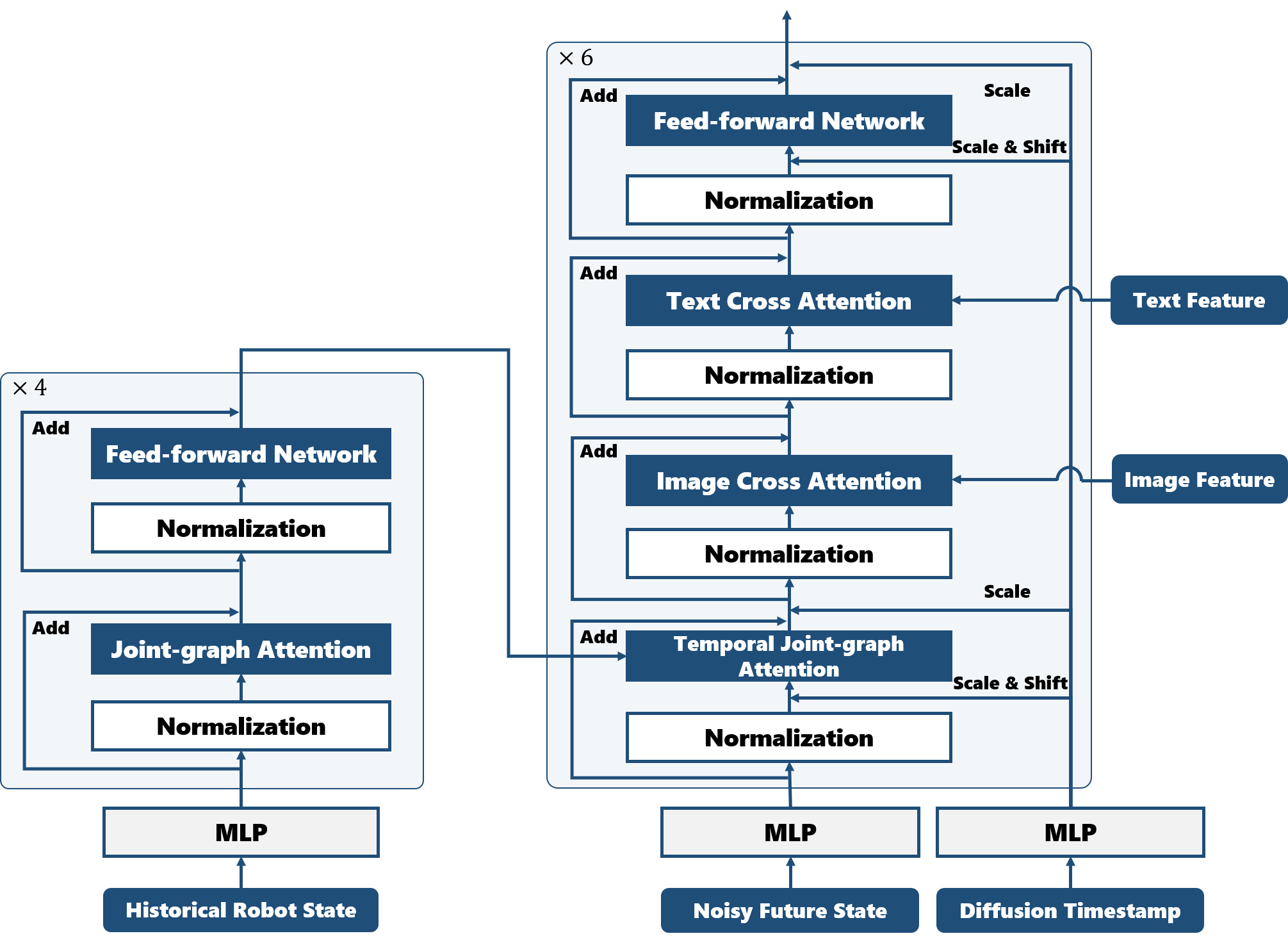
Исследование представляет собой полнофункциональную инфраструктуру для обучения роботов, демонстрирующую высокую эффективность и обобщающую способность в симуляции и на реальном оборудовании.
Несмотря на значительный прогресс в области фундаментальных моделей, надежное развертывание робототехнических систем в реальном мире остается сложной задачей. В данной работе, представленной в ‘HoloBrain-0 Technical Report’, мы представляем HoloBrain-0 — комплексный фреймворк Vision-Language-Action (VLA), объединяющий архитектуру, учитывающую физические характеристики робота, эффективную стратегию обработки данных и полнофункциональную инфраструктуру. Это позволило добиться передовых результатов в симуляциях (RoboTwin 2.0, LIBERO, GenieSim) и добиться впечатляющих успехов в сложных задачах манипулирования в реальном времени, даже с компактной моделью в 0.2B параметров. Станет ли HoloBrain-0 основой для создания нового поколения интеллектуальных роботов, способных к адаптивному и надежному взаимодействию с окружающим миром?
Современные Вызовы Роботизированных Манипуляций
Современные роботизированные системы демонстрируют значительные трудности в адаптации навыков манипулирования к незнакомым условиям и объектам. Вместо гибкости и универсальности, присущих человеческому восприятию, роботы часто требуют точной настройки и программирования для каждого конкретного случая. Эта проблема особенно остро проявляется в динамичных средах, где объекты могут меняться, а условия освещения и расположения — варьироваться. Неспособность к обобщению полученных навыков ограничивает широкое внедрение роботов в реальные условия, требуя разработки принципиально новых, более устойчивых и адаптивных подходов к управлению манипуляциями. Исследования направлены на создание систем, способных самостоятельно обучаться и приспосабливаться к новым задачам, не требуя постоянного вмешательства человека и обеспечивая надежную работу в непредсказуемых обстоятельствах.
Традиционные методы роботизированной манипуляции зачастую сталкиваются с трудностями при одновременной обработке визуальной информации, лингвистических команд и координации движений. Существующие системы, как правило, разрабатываются с акцентом на один из этих аспектов, что приводит к ограниченной гибкости и адаптивности. Например, робот может успешно захватывать объекты, основываясь на заранее заданных визуальных параметрах, но не способен интерпретировать словесные инструкции, такие как «аккуратно переместить хрупкий предмет». Или же, наоборот, система может понимать человеческую речь, но испытывать трудности с распознаванием объектов в незнакомой обстановке или с точным выполнением требуемых манипуляций. Эффективная интеграция этих трех ключевых элементов — зрения, языка и управления — представляется необходимым условием для создания действительно интеллектуальных и универсальных роботов-манипуляторов, способных к самостоятельной работе в динамичных и непредсказуемых условиях.
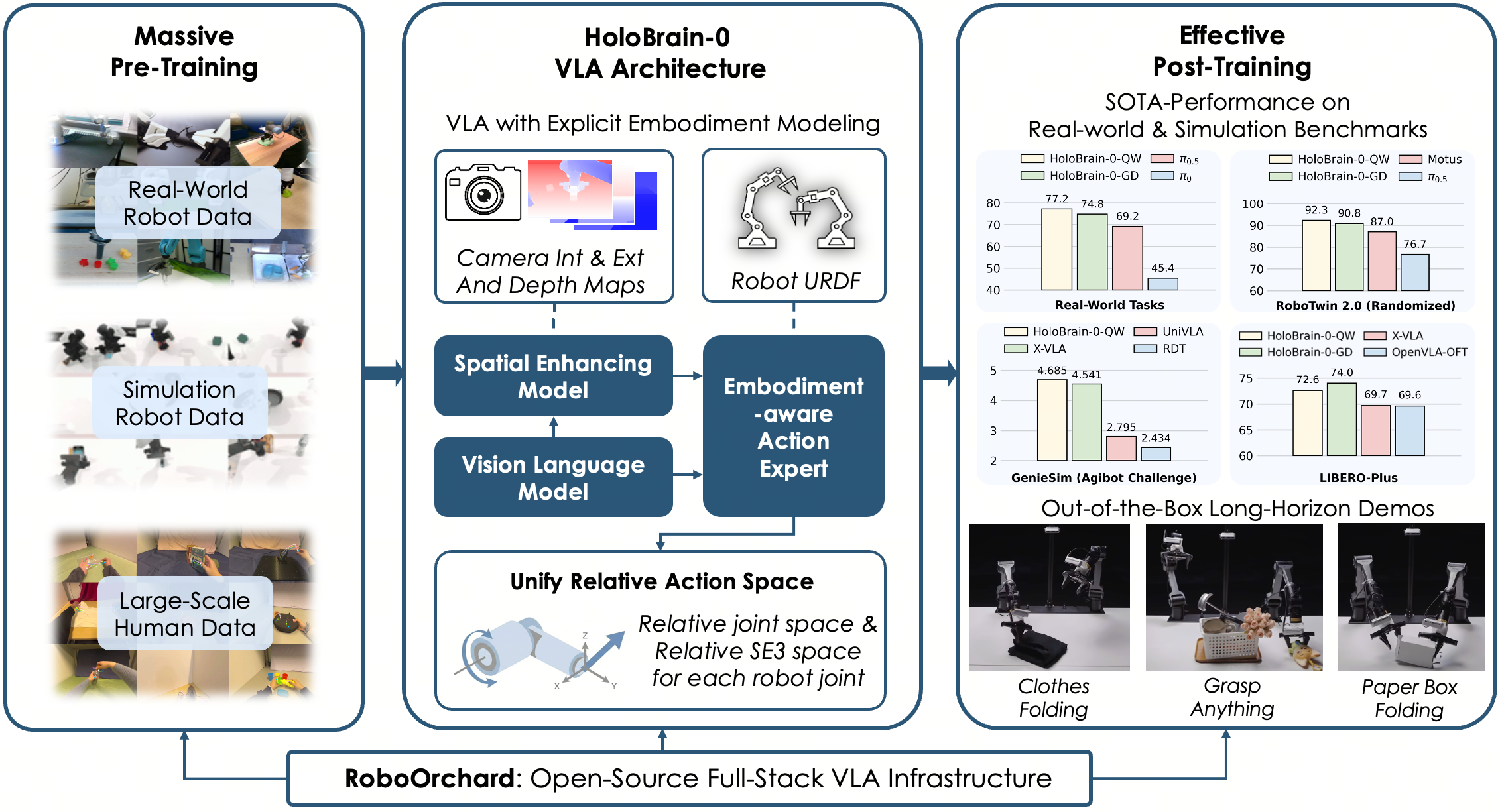
HoloBrain-0: Целостная Рамка VLA
HoloBrain-0 представляет собой новую структуру Vision-Language-Action (VLA), разработанную для надежного управления роботами. В отличие от существующих моделей VLA, HoloBrain-0 ориентирована на повышение устойчивости и адаптивности в реальных условиях эксплуатации. Ключевым отличием является расширенная архитектура, позволяющая интегрировать данные из визуальных сенсоров, лингвистических команд и данных о действиях робота в единый процесс принятия решений. Это позволяет системе не только понимать инструкции, но и адаптировать свои действия к изменяющимся условиям окружающей среды и ограничениям робота, что обеспечивает более надежную и гибкую роботизированную манипуляцию.
В основе HoloBrain-0 лежит концепция “встроенных априорных знаний” (Embodiment Priors), подразумевающая явное включение в модель кинематических параметров робота и параметров камеры. Это достигается путем кодирования информации о геометрии робота, длинах звеньев, углах соединения и внутренних параметрах камеры (фокусное расстояние, искажения) непосредственно в архитектуру VLA. Такая интеграция позволяет модели более эффективно рассуждать о пространственных отношениях между объектами и действиями робота, повышая точность планирования траекторий и успешность манипуляций. Включение этих параметров обеспечивает более реалистичное представление о физическом мире и улучшает способность модели предсказывать последствия действий робота в пространстве.
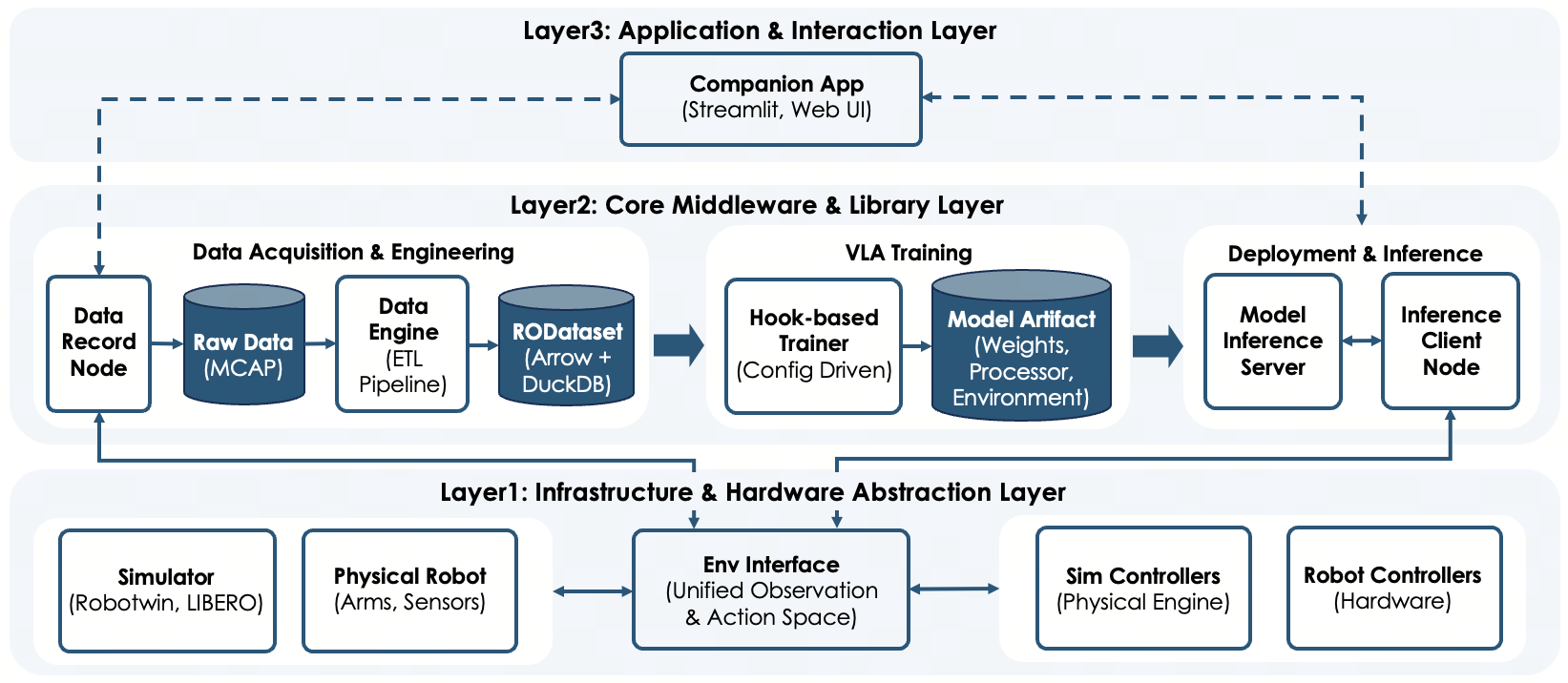
В основе HoloBrain-0 лежит полнофункциональная инфраструктура RoboOrchard, обеспечивающая упрощенный сбор данных, обучение моделей и развертывание на робототехнических платформах. RoboOrchard использует эффективные форматы данных, такие как Apache Arrow и MCAP, для оптимизации процессов обработки и хранения больших объемов информации, необходимых для обучения моделей Vision-Language-Action. Apache Arrow обеспечивает высокую пропускную способность и низкую задержку при передаче данных, а MCAP (Message Capture) — стандартизированный формат для записи и воспроизведения данных с роботов, включая изображения, команды и показания датчиков. Это позволяет эффективно управлять данными на всех этапах жизненного цикла модели, от сбора до развертывания.

Стратегия Сбора Данных и Архитектурные Улучшения
В HoloBrain-0 используется итеративная стратегия сбора данных, управляемая тестированием. Она сочетает в себе проактивное расширение пространства состояний и целевое восстановление после ошибок, что обеспечивает эффективное обучение. В ходе экспериментов по складыванию ткани, после четырех итераций сбора данных, управляемых тестированием, система достигла 75% успешности выполнения задачи. Данный подход позволяет HoloBrain-0 оптимизировать процесс обучения за счет фокусировки на областях, требующих улучшения, и повышения надежности системы в целом.
Пространственный энхансер (Spatial Enhancer) использует архитектуру Swin Transformer для эффективного кодирования карт глубины и их последующего слияния с признаками изображения. Swin Transformer, благодаря механизму оконного внимания, позволяет эффективно обрабатывать изображения высокого разрешения и устанавливать связи между различными областями сцены. Кодирование карт глубины обеспечивает понимание трехмерной структуры окружения, что, в свою очередь, улучшает визуальное восприятие и позволяет более точно интерпретировать изображения. В результате слияния признаков изображения и карт глубины формируется более полное и информативное представление сцены, необходимое для выполнения задач, требующих понимания пространственных отношений.
В HoloBrain-0 модуль “Эксперт по Действиям” реализован на базе архитектуры Transformer и предназначен для предсказания состояний робота и планирования его действий. Для обеспечения надежности обучения используется комплекс процессов контроля качества данных (Data Quality Assurance), включающий в себя валидацию, очистку и аугментацию данных, поступающих из сенсоров и симуляций. Данный модуль совместно с процессами контроля качества позволяет повысить точность предсказаний и стабильность работы робота при выполнении сложных задач, таких как манипулирование предметами.
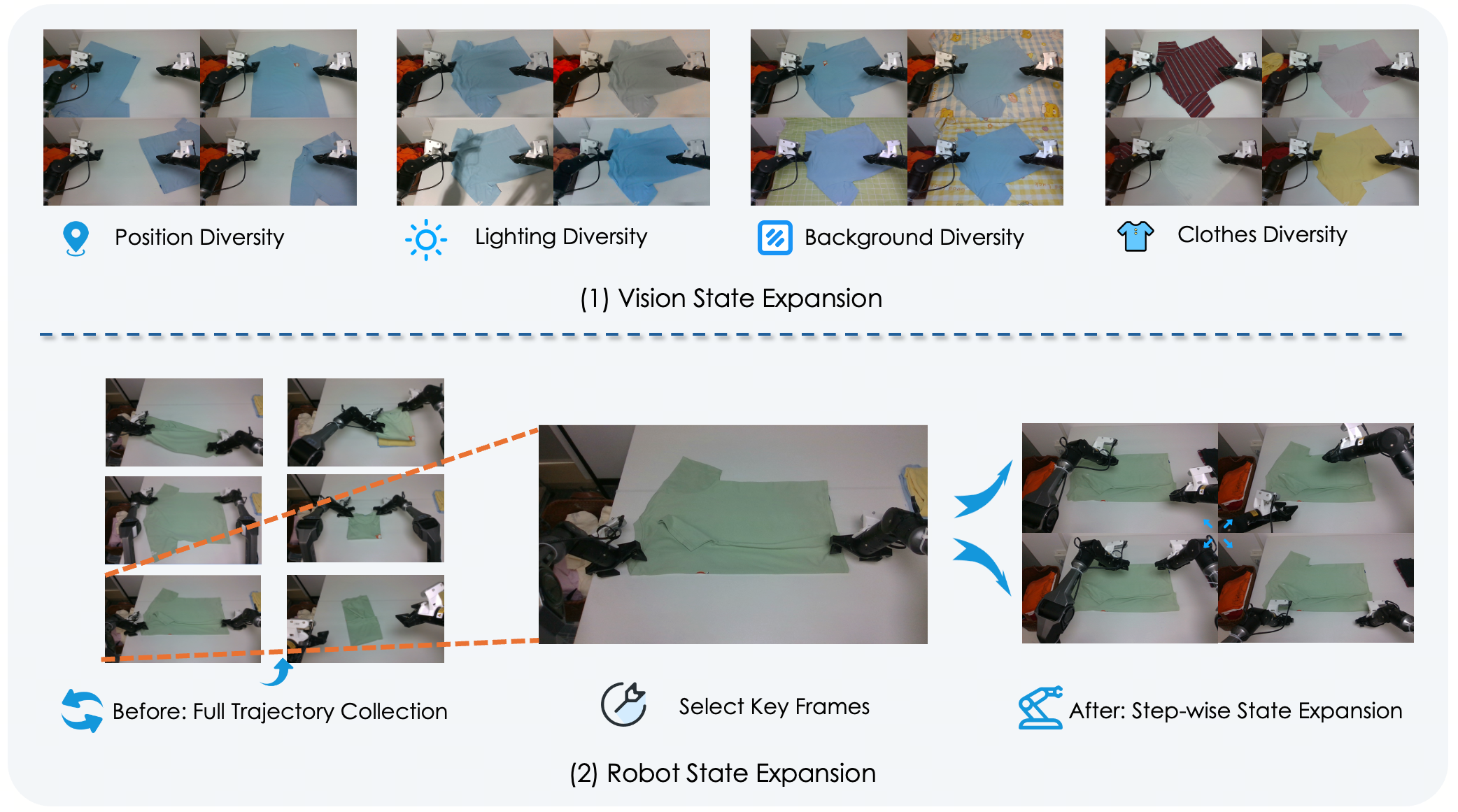
Валидация и Более Широкие Последствия
Разработанная система HoloBrain-0 продемонстрировала значительно превосходящие результаты в сложных симуляционных средах, таких как RoboTwin 2.0, достигнув 92%-ной успешности выполнения задач. В тестах LIBERO-Plus, оценивающих способность к манипулированию объектами, HoloBrain-0 набрал в среднем 74.0 балла, что значительно превосходит показатели OpenVLA-OFT (69.6%) и X-VLA (69.7%). Эти результаты указывают на высокую эффективность новой архитектуры и её способность к решению сложных задач в виртуальной среде, открывая перспективы для применения в робототехнике и автоматизации.
Архитектура HoloBrain-0 принципиально отличается от подхода, реализованного в моделях, таких как OpenVLA, и преодолевает присущие им ограничения. В то время как OpenVLA фокусируется на отдельных аспектах обучения, HoloBrain-0 использует целостный подход, интегрируя воплощенные априорные знания — то есть, информацию, полученную из взаимодействия с физическим миром. Этот подход позволяет модели не просто распознавать объекты и действия, но и понимать их физические свойства и взаимосвязи, что критически важно для успешного выполнения сложных задач манипулирования и навигации. В отличие от моделей, полагающихся исключительно на визуальные данные, HoloBrain-0 активно использует информацию о физическом теле агента и его взаимодействии с окружающей средой, что значительно повышает ее эффективность и надежность в реальных условиях.
Исследования показали, что HoloBrain-0 демонстрирует выдающиеся способности к обобщению, успешно захватывая ранее не виденные объекты в 97,5% случаев. Это значительно превосходит показатели существующих систем, указывая на более эффективную обработку новых ситуаций. Кроме того, в задаче по складыванию одежды, HoloBrain-0 показал улучшение на 25% по сравнению с базовыми методами, что свидетельствует о способности не только распознавать объекты, но и выполнять сложные манипуляции с ними. Данные результаты подчеркивают потенциал HoloBrain-0 для применения в реальных сценариях, где роботам необходимо адаптироваться к постоянно меняющимся условиям и выполнять разнообразные задачи.
Представленная работа над HoloBrain-0 демонстрирует стремление к математической чистоте в области робототехники. Разработчики, подобно математикам, ищут доказуемые решения, а не просто эмпирически работающие. Как заметил Бертран Рассел: «Всякая великая идея начинается как ересь». Использование архитектуры, ориентированной на воплощение, и эффективной стратегии данных, действительно, является новаторским подходом к проблеме переноса обучения из симуляции в реальный мир. Подход HoloBrain-0 к решению проблемы обобщения, особенно в контексте Vision-Language-Action (VLA), является ярким примером стремления к алгоритмической ясности и надежности.
Что Дальше?
Представленная работа, демонстрируя достижение передовых результатов в области манипулирования роботами, всё же оставляет ряд вопросов, требующих осмысления. Если повышение эффективности использования данных и улучшение обобщающей способности представляются достижимыми целями, то истинная сложность кроется в самой природе «понимания» со стороны машины. Если алгоритм выглядит как магия — значит, не раскрыт инвариант, и данная работа не является исключением. Необходимо более глубокое исследование принципов, лежащих в основе успешного переноса обучения из симуляции в реальный мир, а не просто оптимизация параметров, дающих наилучший результат на текущем наборе тестов.
Перспективы развития лежат в плоскости не простого увеличения объёма данных или усложнения архитектур, а в разработке принципиально новых подходов к представлению знаний и рассуждениям. Необходимо двигаться от эмпирической оптимизации к формальной верификации алгоритмов, доказывая их корректность, а не просто демонстрируя работоспособность. В противном случае, мы рискуем создать сложные системы, поведение которых будет непредсказуемым и труднообъяснимым.
Следующим шагом представляется не просто создание более «умных» роботов, но и разработка формального аппарата для описания и проверки их поведения, гарантирующего соответствие заданным требованиям и исключающего нежелательные побочные эффекты. В конечном итоге, элегантность кода проявляется в его математической чистоте, и это правило должно быть фундаментальным для развития робототехники.
Оригинал статьи: https://arxiv.org/pdf/2602.12062.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Как самому почистить матрицу. Продолжение.
- Неважно, на что вы фотографируете!
- Российский рынок: между ставкой ЦБ, геополитикой и отчетами компаний (25.03.2026 17:32)
- MSI Katana 17 HX B14WGK ОБЗОР
- vivo iQOO Z11x ОБЗОР: яркий экран, удобный сенсор отпечатков, большой аккумулятор
- Что купить фотографу. Рекомендации
- Oppo K14 Turbo Pro ОБЗОР: большой аккумулятор, плавный интерфейс, скоростная зарядка
- Пульт дистанционного управления для фотоаппарата
- Как фотографировать на телефон.
2026-02-13 19:41