Автор: Денис Аветисян
Новое исследование показывает, что разнообразие данных важнее их количества при обучении роботов выполнению задач манипулирования объектами.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"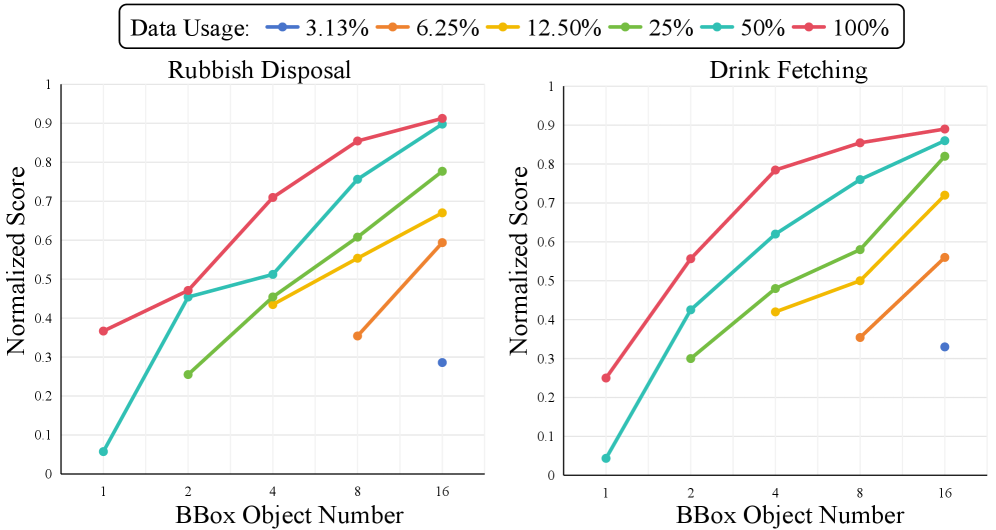
Работа демонстрирует зависимость эффективности политики от разнообразия набора данных, используя ограничивающие рамки для визуального управления роботом.
Несмотря на значительный прогресс в области робототехники, семантическая манипуляция объектами остается сложной задачей из-за трудностей с визуальным пониманием и обобщением. В работе ‘Learning to Manipulate Anything: Revealing Data Scaling Laws in Bounding-Box Guided Policies’ предложен новый подход, использующий ограничивающие рамки (bounding boxes) в качестве визуальных инструкций для управления диффузионными моделями. Авторы показали, что производительность политики тесно связана с разнообразием объектов в обучающей выборке, демонстрируя закон убывающей отдачи, и разработали эффективную стратегию сбора данных, ориентированную на увеличение этого разнообразия. Возможно ли создание универсальных робототехнических систем, способных к адаптивной семантической манипуляции в реальных условиях, благодаря более эффективному использованию данных и визуальному ориентированию?
Преодолевая ограничения: Семантическое управление роботами
Традиционные системы управления роботами часто демонстрируют ограниченные возможности при выполнении задач, требующих понимания содержания манипуляций, а не только последовательности действий. В то время как роботы превосходно справляются с повторяющимися движениями, точно заданными в коде, они испытывают трудности, когда необходимо идентифицировать объекты, понимать их свойства и адаптировать действия к изменяющимся условиям. Например, робот может быть запрограммирован на перемещение объекта из точки А в точку Б, но не сможет распознать, что этот объект — хрупкая ваза, требующая особой осторожности, если такая информация не была явно включена в его программу. Эта неспособность к семантическому пониманию ограничивает возможности роботов в реальном мире, где объекты и ситуации постоянно меняются, и требует разработки новых подходов к управлению, ориентированных на понимание смысла выполняемых действий.
Для обеспечения надежного поведения роботов необходимо объединение семантических инструкций высокого уровня с точными физическими действиями. Это означает, что робот должен не просто выполнять запрограммированные движения, а понимать смысл поставленной задачи и адаптировать свои действия к конкретной ситуации. Например, при получении инструкции «подай красное яблоко», робот должен распознать яблоко среди других объектов, определить его цвет и, используя соответствующие манипуляции, безопасно доставить его адресату. Такое объединение требует разработки сложных алгоритмов, способных преобразовывать абстрактные команды в конкретные последовательности движений, учитывая при этом физические ограничения робота и особенности окружающей среды. Успешная интеграция семантического понимания и физического исполнения является ключевым шагом к созданию действительно автономных и гибких робототехнических систем, способных эффективно функционировать в реальном мире.
Существующие методы управления роботами часто демонстрируют ограниченную способность к обобщению, что существенно снижает их применимость в реальных условиях. Несмотря на успехи в узкоспециализированных задачах, роботы испытывают трудности при взаимодействии с незнакомыми объектами или в незнакомой обстановке. Это связано с тем, что большинство систем полагается на заранее запрограммированные сценарии или обучение на ограниченном наборе данных, что делает их неспособными адаптироваться к новым ситуациям. Неспособность к обобщению требует значительных усилий по перепрограммированию или повторному обучению робота при каждом изменении в окружающей среде или появлении новых объектов, что делает автоматизацию сложных задач крайне затруднительной и дорогостоящей. Таким образом, преодоление этой проблемы является ключевым шагом к созданию действительно автономных и гибких роботизированных систем.

BBox-DP: Расширяя возможности диффузионной политики с помощью визуального восприятия
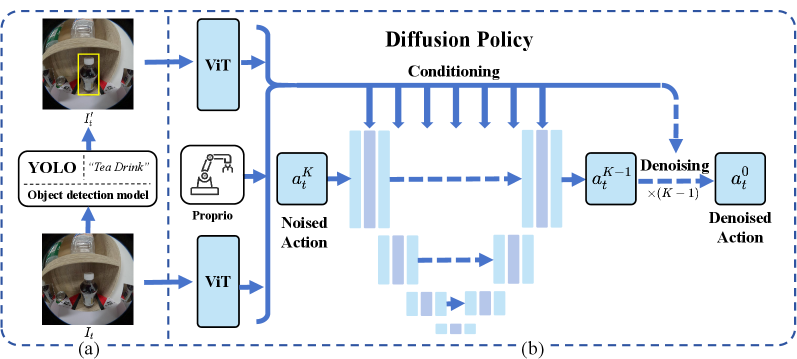
BBox-DP представляет собой новую структуру, расширяющую возможности Diffusion Policy за счет использования визуального восприятия, основанного на ограничивающих рамках (bounding boxes). Данный подход позволяет системе не только обрабатывать семантические команды, но и привязывать их к конкретным объектам в визуальном окружении. В основе BBox-DP лежит интеграция Diffusion Policy с механизмом восприятия, способным идентифицировать и локализовать объекты, что обеспечивает более точное и надежное выполнение задач. В отличие от стандартного Diffusion Policy, BBox-DP учитывает пространственное расположение объектов, что повышает эффективность и гибкость системы в динамических средах.
В основе BBox-DP лежит модуль обнаружения объектов, реализованный на базе YOLO, который обеспечивает визуальную привязку семантических команд к конкретным объектам в окружающей среде. YOLO используется для идентификации и локализации объектов, предоставляя информацию о координатах ограничивающих рамок (bounding boxes) на изображении. Эта информация о местоположении объектов служит визуальным основанием для интерпретации семантических инструкций, позволяя системе точно определить, к каким объектам относится данная команда, и, следовательно, корректно спланировать действия робота. Модуль обеспечивает обработку изображений в реальном времени, что необходимо для динамического взаимодействия робота с окружением.
Интеграция визуальной и семантической информации в BBox-DP позволяет роботам выполнять сложные задачи, основываясь на интуитивно понятных инструкциях. Система объединяет данные, полученные от модуля обнаружения объектов (на базе YOLO), с текстовыми командами, что обеспечивает более точное понимание требуемых действий. Это позволяет роботу не просто следовать абстрактным указаниям, а конкретно идентифицировать и манипулировать объектами в окружающей среде, что существенно повышает надежность и эффективность выполнения задач, требующих взаимодействия с реальным миром.
Масштабирование эффективности: Визуальное обоснование и экспериментальные результаты
Экспериментальные исследования показали, что применение BBox-DP значительно повышает эффективность выполнения разнообразных задач манипулирования роботом, включая уборку мусора, доставку напитков, наливание воды и нажатие кнопок. Наблюдаемое улучшение производительности подтверждено результатами тестов на различных сценариях, демонстрируя универсальность подхода BBox-DP для широкого спектра роботизированных операций. Применение данной методики позволяет повысить надежность и точность выполнения задач в реальных условиях эксплуатации робота.
Эксперименты показали, что эффективность системы масштабируется предсказуемо в зависимости от объема размеченных данных, следуя степенному закону y = ax^k. На четырех задачах — Уборка мусора, Принесение напитка, Наполнение водой и Нажатие кнопки — достигнута эффективность около 85% при увеличении объема данных. Наблюдаемая зависимость позволяет прогнозировать производительность системы при различных объемах размеченных данных и оптимизировать процесс сбора и аннотации данных для достижения требуемого уровня эффективности.
Интеграция Visual Transformer (ViT) в архитектуру BBox-DP позволила повысить эффективность извлечения признаков и, как следствие, улучшить производительность в задачах робототехники. Статистический анализ, проведенный с использованием Welch’s t-теста, продемонстрировал статистически значимые улучшения для каждой из рассматриваемых задач: Rubbish Disposal (p=3.363×10-7), Drink Fetching (p=9.736×10-4), Water Pouring (p=4.057×10-4) и Button Pressing (p=7.523×10-3). Полученные результаты подтверждают, что использование ViT в составе BBox-DP способствует более точному анализу визуальной информации и, следовательно, повышает надежность выполнения роботом поставленных задач.
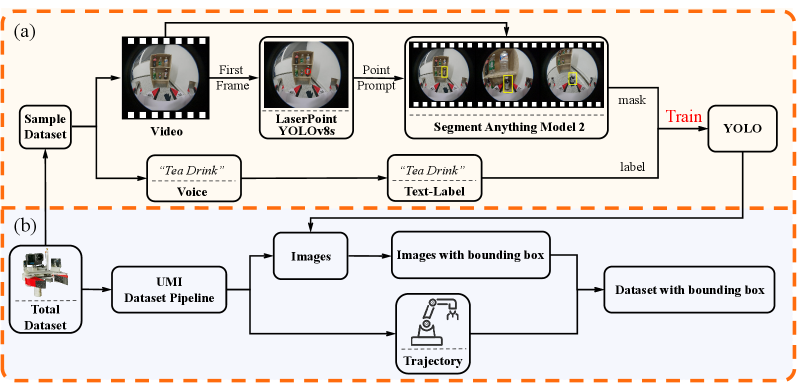
Автоматизированный сбор данных для обеспечения надежности и масштабируемости
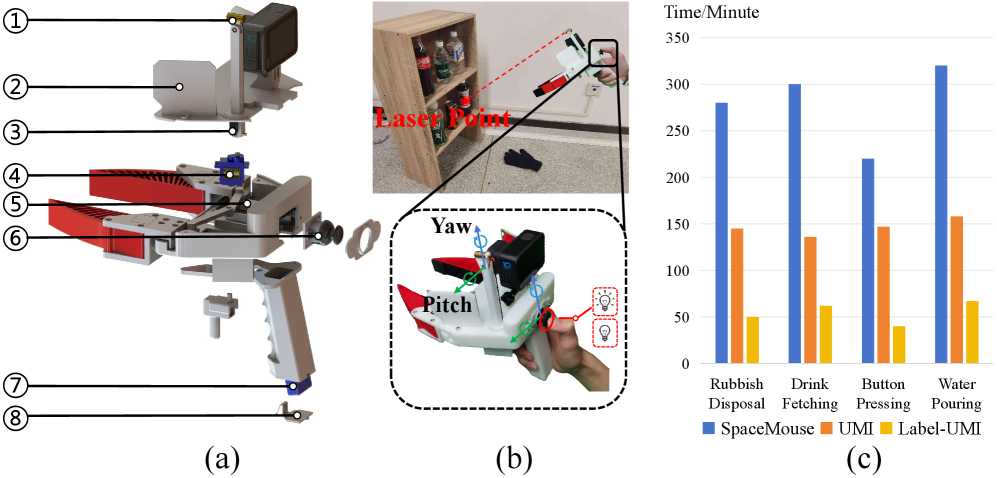
Для обеспечения сбора масштабных объемов данных была разработана автоматизированная система сбора данных, использующая технологию Label-UMI для эффективной семантической аннотации. Данная система позволяет автоматически собирать изображения, генерировать ограничивающие рамки вокруг объектов и фиксировать траектории движения робота. Label-UMI обеспечивает точную и быструю разметку данных, что критически важно для обучения моделей машинного обучения. Автоматизация этого процесса значительно сокращает время и ресурсы, необходимые для создания больших и разнообразных наборов данных, необходимых для повышения надежности и обобщающей способности роботизированных систем в различных условиях эксплуатации. Разработанная система позволяет получать данные, пригодные для обучения моделей, способных к эффективному взаимодействию с окружающим миром.
Для обеспечения масштабного сбора данных была разработана автоматизированная система, способная самостоятельно собирать изображения, определять границы объектов на них и регистрировать траектории движения робота. Данный процесс, ранее требовавший значительных трудозатрат и времени, теперь осуществляется в автоматическом режиме, что позволяет существенно увеличить объем собираемой информации и повысить надежность обучения моделей. Система способна непрерывно фиксировать визуальные данные, точно локализуя объекты интереса посредством генерации ограничивающих рамок, и одновременно записывать последовательность действий робота, обеспечивая комплексный набор данных для последующего анализа и оптимизации алгоритмов управления.
В рамках разработанной системы управления роботом активно используются механизмы FiLM (Feature-wise Linear Modulation) и кросс-внимания для эффективного объединения визуальной и семантической информации. Механизм FiLM позволяет модулировать визуальные признаки на основе семантических данных, что дает возможность гибко адаптировать поведение робота к различным задачам и условиям. Кросс-внимание, в свою очередь, обеспечивает фокусировку на наиболее релевантных участках изображения, основываясь на семантическом контексте, что значительно повышает точность и надежность выполняемых действий. Такое сочетание позволяет политике диффузии, управляющей роботом, эффективно использовать как визуальные данные с камер, так и семантическую информацию, полученную в процессе аннотации, для достижения поставленных целей даже в сложных и динамичных средах.
Исследование демонстрирует, что эффективность политик, управляемых ограничивающими рамками, подчиняется закономерностям масштабирования данных. Это напоминает принцип, который сформулировал Андрей Колмогоров: «Вероятность того, что произойдет событие, очень мала, но она не равна нулю». Аналогично, увеличение разнообразия данных, а не просто их количества, экспоненциально повышает производительность робота в семантической манипуляции. Работа показывает, что понимание внутренней структуры системы, в данном случае — взаимосвязи между разнообразием данных и успехом политики — позволяет взломать её, оптимизируя процесс сбора данных и добиваясь максимальной эффективности при минимальных затратах.
Что дальше?
Представленная работа выявила закономерность: увеличение разнообразия данных для обучения манипуляций с объектами оказывает экспоненциально большее влияние на производительность, чем простое наращивание объёма. Но что, если сама концепция «разнообразия» — лишь иллюзия, порождённая ограниченностью текущих сенсоров и алгоритмов? Что, если существует более фундаментальный параметр, определяющий успешность манипуляции, который мы пока не способны измерить или даже представить? Стоит задуматься, не является ли стремление к «разнообразию» просто попыткой аппроксимировать нечто более сложное, нежели чем реально понять суть процесса.
Текущий подход, использующий ограничивающие рамки (bounding boxes), безусловно, эффективен как визуальная инструкция. Однако, что произойдёт, если отказаться от этой упрощённой репрезентации? Если позволить агенту учиться непосредственно на необработанных сенсорных данных, не навязывая ему заранее заданные структуры? Возможно, тогда возникнет принципиально новый уровень понимания и контроля над манипуляциями, превосходящий всё, что достигнуто на данный момент.
И, наконец, стоит задаться вопросом: а не является ли сама цель «манипуляции» искусственной? Возможно, истинный прогресс в робототехнике заключается не в научении роботов выполнять заданные действия, а в создании систем, способных к самостоятельному обучению и адаптации, способных находить собственные цели и решать собственные задачи. Тогда, возможно, понятие «управления» станет ненужным, а роботы просто начнут…творить.
Оригинал статьи: https://arxiv.org/pdf/2602.11885.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Как самому почистить матрицу. Продолжение.
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Неважно, на что вы фотографируете!
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
- MSI Katana 17 HX B14WGK ОБЗОР
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Что такое глубина резкости в фотографии?
- Макросъемка
2026-02-15 00:11