Автор: Денис Аветисян
Новый подход позволяет создавать детализированные трехмерные модели с высоким динамическим диапазоном, используя данные обычных камер и событийных сенсоров.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"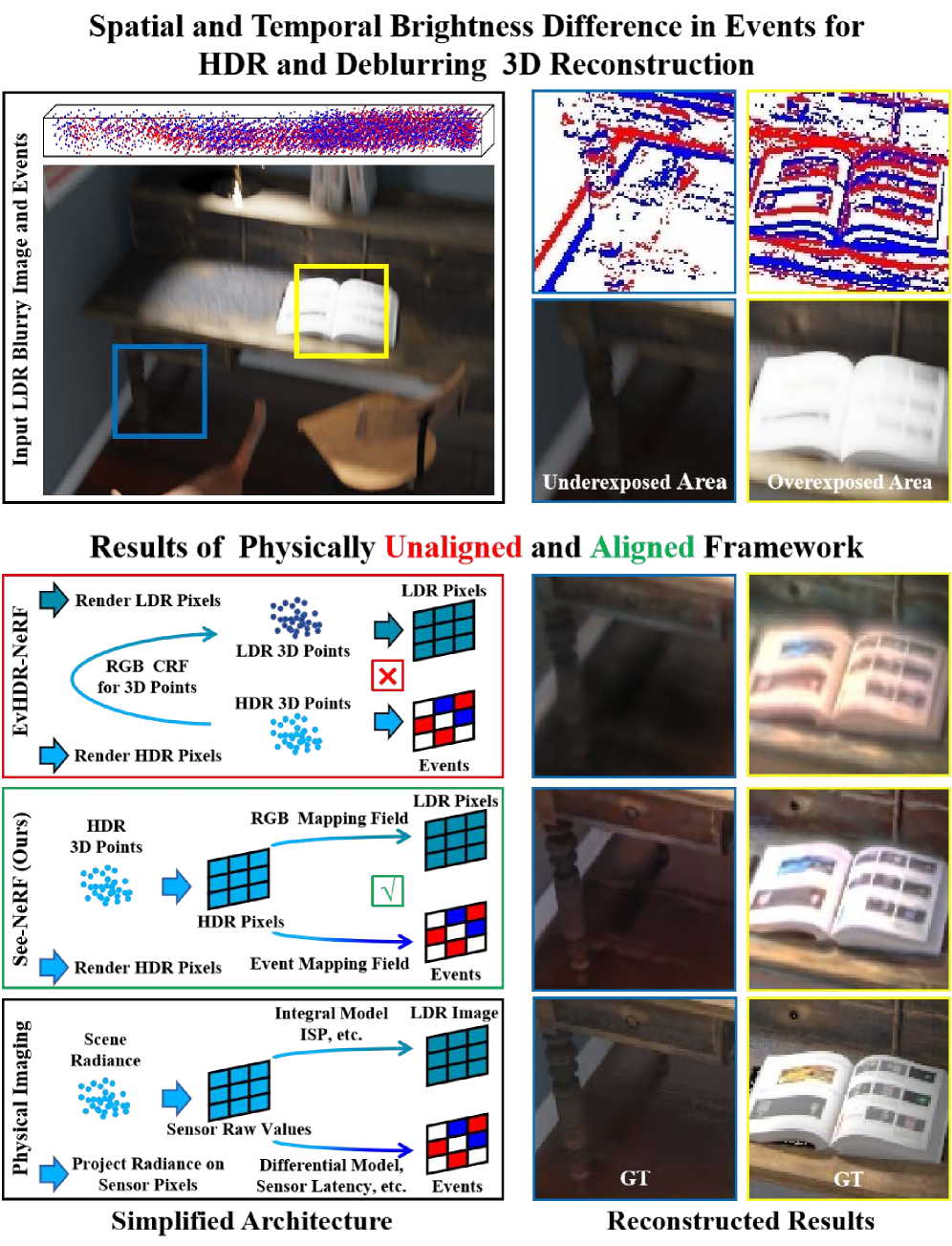
Представлена методика See-NeRF, объединяющая физику сенсоров и нейронные поля излучения для реконструкции резких HDR-сцен из одиночных размытых изображений и событийных данных.
Восстановление детализированных и высокодинамичных 3D-сцен из размытых изображений в сложных условиях освещения остается сложной задачей. В работе ‘Seeing through Light and Darkness: Sensor-Physics Grounded Deblurring HDR NeRF from Single-Exposure Images and Events’ предложен новый подход, объединяющий нейронные поля излучения (NeRF) и данные событийных камер для реконструкции четких HDR-сцен. Ключевой особенностью является моделирование физики работы как RGB-, так и событийных сенсоров, что позволяет преодолеть несоответствия между зарегистрированным сигналом и реальным излучением сцены. Способны ли подобные физически обоснованные модели радикально улучшить качество и реалистичность синтеза новых видов в условиях недостаточной освещенности и движения?
За гранью традиционной визуализации: ограничения LDR-съемки
Традиционные системы визуализации, полагающиеся на получение изображений с низким динамическим диапазоном (LDR) за одну экспозицию, сталкиваются с двойной проблемой: размытием при движении и ограниченным диапазоном яркостей, что существенно снижает качество получаемого изображения. В условиях быстрого движения объектов или при значительных контрастах между светлыми и темными участками сцены, одноэкспозиционная съемка не способна зафиксировать все детали. Это проявляется в виде смазанных контуров движущихся объектов и потере информации в пересвеченных или затемненных областях. В результате, визуальная достоверность изображения страдает, а возможности применения в требовательных областях, таких как дополненная реальность и робототехника, оказываются ограниченными. Существующие методы коррекции, как правило, не позволяют полностью компенсировать эти недостатки, подчеркивая необходимость разработки принципиально новых подходов к захвату изображения.
Ограничения, свойственные традиционным системам визуализации, особенно остро проявляются в динамичных сценах и при резких перепадах освещенности. В высокоскоростных ситуациях, таких как автономное вождение или спортивные трансляции, недостаточная скорость захвата и ограниченный динамический диапазон приводят к смазыванию изображения и потере деталей в ярких и темных областях. Это создает значительные трудности для приложений, требующих точной и надежной визуальной информации, включая системы дополненной реальности, где необходимо реалистично накладывать виртуальные объекты на реальный мир, и робототехнику, где точное восприятие окружающей среды критически важно для навигации и манипулирования объектами. Таким образом, преодоление этих ограничений становится ключевой задачей для дальнейшего развития визуальных технологий.
Event-камеры: био-вдохновленное решение для динамичных сцен
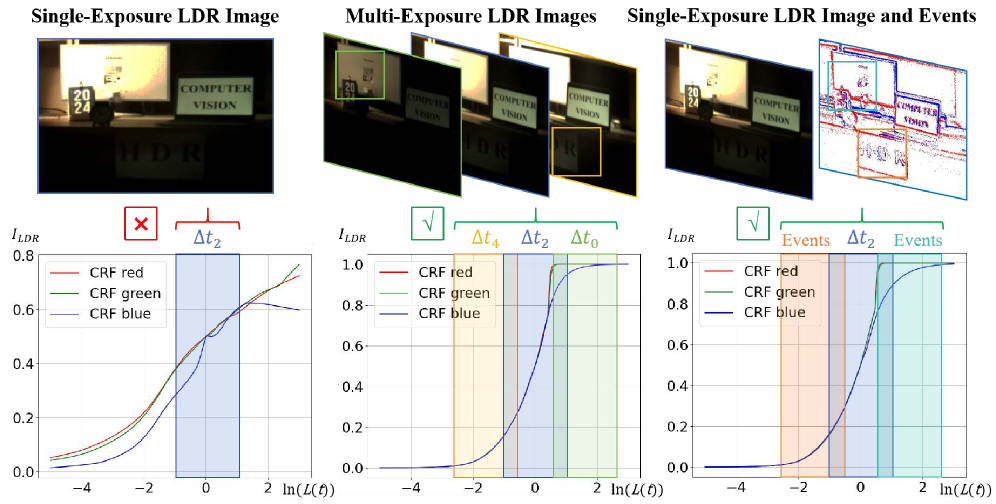
В отличие от традиционных фрейм-камер, фиксирующих изображение дискретными кадрами с определенной частотой, event-камеры представляют собой принципиально новый подход к захвату изображения. Они регистрируют изменения яркости каждого пикселя асинхронно, то есть независимо от глобального времени, что позволяет достичь значительно более высокого временного разрешения и динамического диапазона. Вместо передачи полного изображения в каждый момент времени, event-камера выдает поток «событий» — сигналов, указывающих на локальные изменения яркости, — что существенно снижает требования к пропускной способности и энергопотреблению, особенно при съемке динамичных сцен или в условиях низкой освещенности.
Выходным сигналом событийной камеры является поток “событий” — сигналов, указывающих на изменения яркости на уровне отдельных пикселей. Каждое событие содержит информацию о координатах пикселя, времени возникновения изменения и полярности (увеличение или уменьшение яркости). Этот асинхронный поток данных предоставляет информацию, богатую данными о движении и контрасте, в отличие от дискретных кадров, предоставляемых традиционными камерами. Интенсивность события обычно пропорциональна величине изменения яркости, что позволяет количественно оценивать динамические сцены. Отсутствие глобального затвора и высокая скорость регистрации изменений делают событияе камеры особенно эффективными в условиях быстрого движения и при съемке сцен с высоким динамическим диапазоном.
Чувствительность событийной камеры определяется порогом контрастности события (Event Contrast Threshold). Этот параметр регулирует минимальную разницу в яркости, необходимую для генерации события. Уменьшение порога повышает чувствительность камеры к слабым изменениям яркости, что полезно в условиях низкой освещенности или при обнаружении медленных движений. Увеличение порога, напротив, снижает чувствительность, уменьшая количество генерируемых событий и повышая устойчивость к шуму и быстрым изменениям освещения. Таким образом, настройка порога позволяет адаптировать камеру к различным условиям освещения и конкретным задачам, обеспечивая оптимальное соотношение между чувствительностью и помехоустойчивостью.
See-NeRF: объединение событий и поля излучения
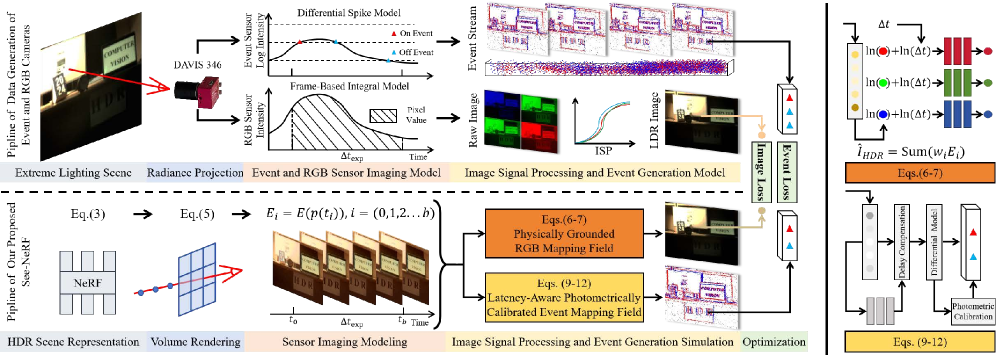
See-NeRF представляет собой новую систему для реконструкции чётких, высокодинамичных (HDR) сцен по размытым изображениям с низким динамическим диапазоном (LDR) и асинхронным данным событий. В отличие от традиционных методов, See-NeRF объединяет информацию из этих двух источников данных для создания более точного и детального представления сцены. Система использует нейронные поля излучения (NeRF) для представления излучения сцены, а также отдельные поля отображения для обработки данных LDR-изображений и событий. Это позволяет эффективно восстанавливать детали сцены, которые были потеряны из-за размытия движения или ограниченного динамического диапазона, что приводит к улучшенному качеству реконструированных изображений.
See-NeRF использует нейронные поля излучения (NeRF) для представления яркости сцены. Для моделирования формирования изображений с низким динамическим диапазоном (LDR) применяется поле отображения RGB, учитывающее временную интеграцию и функцию отклика камеры. Параллельно, поле отображения событий обрабатывает данные с датчиков событий. Комбинация этих полей позволяет системе сопоставлять данные LDR и события для реконструкции сцены, что обеспечивает более точное представление яркости и уменьшает размытие, вызванное движением.
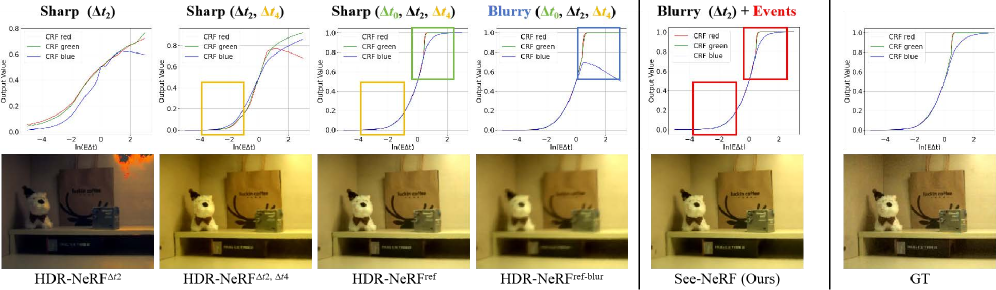
В основе подхода See-NeRF лежит моделирование физических процессов, происходящих в сенсоре, что позволяет эффективно снижать размытость, вызванную движением. Вместо абстрактных представлений, See-NeRF реконструирует исходное излучение сцены R(x, d), учитывая как данные с LDR-изображений, так и асинхронные данные с датчиков событий. Такой подход обеспечивает более точную реконструкцию, что подтверждается улучшением метрик качества изображения, таких как PSNR, SSIM и LPIPS, на различных наборах данных по сравнению с существующими методами. Точность моделирования сенсорных процессов является ключевым фактором, обеспечивающим превосходство See-NeRF в задачах реконструкции HDR-сцен.
Влияние и перспективы динамичной 3D-реконструкции
Разработанная система позволяет создавать четкие и резкие изображения динамичных сцен с использованием технологии синтеза новых видов, что открывает широкие возможности для приложений в области дополненной и виртуальной реальности. Данный подход позволяет эффективно устранять размытость, возникающую при съемке движущихся объектов или в условиях низкой освещенности, обеспечивая более реалистичное и захватывающее пользовательское восприятие. Способность генерировать высококачественные изображения даже в сложных динамических условиях делает данную разработку особенно ценной для создания интерактивных развлечений, реалистичных симуляций и передовых систем визуализации, где точность и четкость изображения имеют первостепенное значение.
Техники размытия на основе событий могут быть значительно улучшены благодаря подходу, реализованному в See-NeRF, который учитывает особенности работы сенсоров. Данный подход позволяет создавать более устойчивые системы компьютерного зрения, способные эффективно функционировать в сложных условиях освещения и при быстром движении объектов. Использование сенсорной осведомленности позволяет See-NeRF более точно моделировать динамические сцены, снижая влияние размытия, вызванного движением, и повышая четкость реконструируемых изображений. Дальнейшие исследования в этой области направлены на интеграцию сенсорной осведомленности с другими передовыми технологиями, такими как 3D Gaussian Splatting, для достижения еще более высокой производительности и реалистичности в задачах реконструкции динамических сцен.
Несмотря на превосходные результаты, достигнутые See-NeRF в области динамической 3D-реконструкции, процесс обучения данной модели требует на 19.05% больше времени по сравнению с HDR-NeRF. В связи с этим, перспективным направлением исследований является интеграция See-NeRF с технологией 3D Gaussian Splatting. Такой подход позволит существенно ускорить процессы реконструкции и рендеринга динамических сцен, объединяя высокую точность See-NeRF с эффективностью и скоростью 3D Gaussian Splatting, что открывает новые возможности для приложений в области виртуальной и дополненной реальности, а также для робототехники и автономных систем.

Представленная работа, стремящаяся к воссозданию детализированных трёхмерных сцен из размытых изображений, закономерно вызывает лёгкую усмешку. Авторы, безусловно, потратили немало усилий, моделируя физику сенсоров и используя возможности нейронных полей. Однако, как показывает опыт, даже самые элегантные алгоритмы рано или поздно сталкиваются с суровой реальностью продакшена. Как точно подметил Джеффри Хинтон: «Я думаю, что мы находимся в состоянии, когда обучение с подкреплением — это просто другой способ разработки функций». Иными словами, рано или поздно потребуется ручная доработка, чтобы обмануть систему и заставить её выдавать приемлемый результат. В данном случае, стремление к воссозданию HDR сцен с использованием event-камер — это интересный шаг, но не стоит забывать, что идеальной картинки не существует, а каждый «прорыв» неизбежно порождает новый техдолг.
Куда Поведёт Эта Дорога?
Представленный подход, безусловно, элегантен. Моделирование физики сенсоров — это всегда благородная цель. Однако, не стоит забывать, что любое “самовосстанавливающееся” решение просто ещё не столкнулось с достаточным количеством граничных случаев. Как только эта система покинет контролируемую лабораторную среду и встретится с реальным миром — с его грязными линзами, неисправными сенсорами и непредсказуемым освещением — возникнет вопрос о её устойчивости. И, конечно, документация к подобным системам — это всегда форма коллективного самообмана, обещающая больше, чем может быть гарантировано.
Следующим шагом, вероятно, станет попытка расширить область применения за пределы статических сцен. Динамические объекты, сложные деформации — всё это потребует значительных усилий. Особенно интересно, как данная методика будет справляться с шумом и артефактами, неизбежно возникающими в event-камерах. Если баг воспроизводится, значит, у нас стабильная система, а если не воспроизводится — значит, мы просто недостаточно тщательно тестировали.
В конечном счёте, каждая “революционная” технология завтра станет техдолгом. И хотя воссоздание HDR 3D-сцен из одиночных изображений — это впечатляюще, стоит помнить, что продакшен всегда найдёт способ сломать даже самую изящную теорию. И это хорошо. Так и должно быть.
Оригинал статьи: https://arxiv.org/pdf/2601.15475.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Новые смартфоны. Что купить в марте 2026.
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Лучшие смартфоны. Что купить в марте 2026.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Неважно, на что вы фотографируете!
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Infinix Note 60 Ultra ОБЗОР: скоростная зарядка, объёмный накопитель, отличная камера
- Руководство по Stellaris — Полное прохождение на 100%
- Huawei P30 pro
2026-01-25 00:52