Автор: Денис Аветисян
Новая архитектура динамически распределяет вычислительные ресурсы внутри трансформеров, повышая эффективность без потери точности.
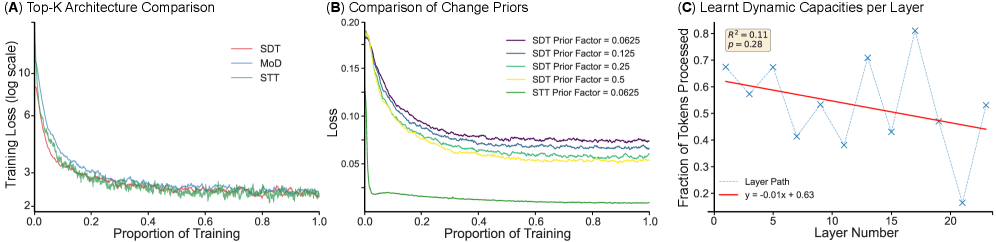
Представлены Subjective Depth и Timescale Transformers, использующие байесовский принцип удивления для адаптивной вычислительной стратегии.
Жесткое распределение вычислительных ресурсов в стандартных архитектурах Transformer ограничивает их масштабируемость и эффективность, особенно при обработке длинных последовательностей. В статье ‘Subjective Depth and Timescale Transformers: Learning Where and When to Compute’ представлены Subjective Depth Transformers (SDT) и Subjective Timescale Transformers (STT) — новые архитектуры, использующие сигналы байесовского удивления для динамического управления вычислительным процессом. Эти модели учатся, где и когда выполнять вычисления, опираясь на принципы предсказательного кодирования и условных вычислений, что позволяет снизить потребление ресурсов без существенной потери точности. Смогут ли подобные подходы открыть путь к созданию более эффективных и масштабируемых Transformer-моделей будущего?
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Квадратичное проклятие: узкое место трансформеров
Архитектура Transformer, совершившая революцию в области обработки естественного языка, сталкивается с проблемой квадратичной масштабируемости в зависимости от длины последовательности. Механизм самовнимания, являющийся ключевым элементом этой архитектуры, требует вычисления взаимодействий между каждой парой токенов во входной последовательности. Это означает, что вычислительная сложность и потребление памяти растут пропорционально квадрату длины последовательности — $O(n^2)$, где $n$ — длина последовательности. Таким образом, при увеличении длины обрабатываемых текстов или данных, потребность в вычислительных ресурсах и времени экспоненциально возрастает, что становится серьезным препятствием для обработки длинных документов, видео или других сложных данных и ограничивает масштабируемость модели.
Квадратичная сложность механизма самовнимания в архитектуре Transformer представляет собой существенное препятствие при обработке длинных последовательностей данных и решении задач, требующих сложного логического вывода. По мере увеличения длины входной последовательности, вычислительные затраты и потребность в памяти растут пропорционально квадрату этой длины — то есть, удвоение длины последовательности приводит к четырехкратному увеличению необходимых ресурсов. Это создает серьезные ограничения для применения моделей Transformer к задачам, связанным с анализом больших текстов, обработкой видео или геномных данных, где последовательности могут быть чрезвычайно длинными. В результате, модели испытывают трудности с улавливанием долгосрочных зависимостей и эффективным использованием контекста, что негативно сказывается на точности и производительности. Данное ограничение является ключевой проблемой, требующей разработки новых подходов к архитектуре и алгоритмам, чтобы преодолеть барьер масштабируемости и раскрыть полный потенциал Transformer-моделей для решения реальных задач.
Существующие подходы к масштабированию трансформеров сталкиваются со значительными трудностями в поддержании вычислительной эффективности по мере увеличения размеров модели и длины обрабатываемых последовательностей. Эта проблема ограничивает возможности применения этих архитектур к сложным задачам, требующим анализа больших объемов данных, таким как обработка длинных текстов, видео или геномных последовательностей. Неспособность эффективно справляться с растущими вычислительными затратами препятствует решению реальных задач, где важна скорость и экономичность, и подчеркивает необходимость разработки новых, более масштабируемых алгоритмов и архитектур. В частности, потребление памяти и времени вычислений быстро растет, делая обучение и развертывание крупных моделей непрактичным или слишком дорогостоящим для многих приложений.
Вдохновленные принципами работы биологических систем, в частности механизмом предиктивного кодирования, исследователи стремятся к разработке более эффективных вычислительных стратегий для нейронных сетей. Предиктивное кодирование предполагает, что мозг постоянно генерирует прогнозы о входящих сигналах, и обрабатывает лишь отклонения от этих прогнозов. Применяя аналогичный подход к архитектуре трансформеров, можно значительно снизить вычислительную сложность, фокусируясь на обработке только новой и значимой информации, а не всей последовательности. Такой подход позволяет моделировать сложные зависимости в данных, сохраняя при этом линейную или логарифмическую сложность, что открывает путь к обработке чрезвычайно длинных последовательностей и решению задач, требующих глубокого рассуждения, которые ранее были недоступны из-за вычислительных ограничений. Разработка подобных алгоритмов представляет собой перспективное направление в области искусственного интеллекта, позволяющее приблизиться к эффективности и гибкости человеческого мозга.

Условные вычисления: путь к эффективности
Условные вычисления представляют собой подход к повышению эффективности нейронных сетей путем селективной активации лишь части сети в зависимости от характеристик входных данных. Вместо последовательной обработки всей информации через все слои, этот метод позволяет динамически выбирать, какие участки сети необходимо задействовать для конкретного входа. Это достигается путем анализа входных данных и определения, какие их свойства наиболее релевантны для текущей задачи, после чего активируются только те части сети, которые способны эффективно обработать эти свойства. Такой подход позволяет существенно снизить вычислительные затраты и энергопотребление, особенно в задачах, где не все входные данные требуют одинаковой степени обработки.
Методы, такие как “Mixture of Experts” (MoE) и “Mixture of Depths” (MoD), представляют собой расширения архитектуры Transformer, направленные на повышение эффективности масштабирования. MoE предполагает использование нескольких “экспертов” — подсетей, каждая из которых специализируется на обработке определенного подмножества входных данных. Маршрутизация входных данных к соответствующим экспертам осуществляется с помощью механизма “gate network”. MoD, в свою очередь, динамически изменяет глубину сети для каждого входного примера, активируя лишь необходимые слои. Оба подхода позволяют увеличить емкость модели без пропорционального увеличения вычислительных затрат, что особенно важно при обработке больших объемов данных и задач, требующих высокой производительности. Реализация MoE и MoD требует careful balancing для предотвращения перегрузки отдельных экспертов или слоев.
Методы условных вычислений, такие как Mixture of Experts (MoE) и Mixture of Depths (MoD), используют статические графы вычислений, что позволяет значительно повысить эффективность обработки данных. В отличие от динамических графов, требующих компиляции во время выполнения, статические графы определяются заранее и позволяют распараллеливать вычисления на различных аппаратных платформах, включая GPU и TPU. Это приводит к снижению вычислительных затрат, поскольку неактивные ветви сети не требуют выполнения операций, а параллельная обработка активных ветвей существенно сокращает общее время вычислений. Использование статических графов также упрощает оптимизацию и компиляцию модели, что положительно сказывается на производительности и масштабируемости.
Эффективная маршрутизация вычислений в моделях условных вычислений требует механизма оценки информативности различных частей входных данных. Этот механизм, как правило, реализуется в виде «gate» или «router» сети, определяющего, какие эксперты или слои сети должны обрабатывать конкретный входной токен или сегмент. Оценка информативности может производиться на основе различных критериев, включая сложность токена, его вклад в общую вероятность, или его релевантность конкретной задаче. Точность этого механизма напрямую влияет на эффективность модели, поскольку неверная маршрутизация может привести к ненужным вычислениям или, наоборот, к пропуску важной информации, что снижает качество конечного результата. Разработка и оптимизация таких механизмов оценки является ключевой задачей в области условных вычислений.
Вычисления, основанные на удивлении: новый подход
Архитектуры $Subjective\ Depth\ Transformer$ (SDT) и $Subjective\ Timescale\ Transformer$ (STT) вводят новый подход к распределению вычислительных ресурсов, основанный на концепции $Bayesian\ Surprise$ (байесовского удивления). Вместо равномерного распределения вычислений, эти модели динамически выделяют ресурсы тем частям входных данных, которые наиболее информативны и требуют более детальной обработки. Данный механизм позволяет оптимизировать использование вычислительных мощностей, концентрируя их на областях, где ожидается наибольший прирост информации, и снижая нагрузку на менее важные участки данных. По сути, система оценивает «удивление» от каждого входного сигнала, определяя, насколько он отличается от ожидаемого, и, следовательно, насколько важно его обработать.
Архитектуры Subjective Depth Transformer (SDT) и Subjective Timescale Transformer (STT) используют механизм, основанный на концепции «Bayesian Surprise», для динамического распределения вычислительных ресурсов. Суть подхода заключается в предсказании областей входных данных, обработка которых наиболее вероятно приведет к существенному увеличению информативности. Вместо равномерного распределения вычислений, система оценивает потенциальную информационную выгоду от обработки каждого фрагмента данных и направляет вычислительные ресурсы туда, где ожидается максимальный прирост информации. Этот процесс позволяет оптимизировать использование ресурсов и повысить эффективность обработки данных за счет фокусировки на наиболее значимых областях.
Для количественной оценки «удивления» и управления распределением вычислительных ресурсов в архитектурах SDT и STT используется расхождение Кульбака-Лейблера (KL-дивергенция) и масштабированное изотропное гауссовское распределение. KL-дивергенция, $D_{KL}(p||q)$, измеряет разницу между предсказанным распределением вероятностей $q$ и фактическим распределением $p$, отражая степень «удивления» модели при получении нового входного сигнала. Масштабированное изотропное гауссовское распределение используется для моделирования неопределенности в предсказаниях, а величина расхождения KL применяется для динамического определения, какие части модели требуют наибольшего вычислительного внимания, что позволяет эффективно распределять ресурсы и снижать общую вычислительную нагрузку.
Внедрение экономичного слоя в половину слоев архитектуры позволило снизить вычислительную нагрузку, связанную с механизмом самовнимания (self-attention), на 37.5%. Это снижение, в свою очередь, привело к уменьшению объема KV-кэша на 25%. Уменьшение KV-кэша достигается за счет сокращения количества хранимых векторов ключей и значений, необходимых для вычисления внимания, что существенно снижает потребность в памяти и ускоряет процесс инференса.
Архитектура Subjective Timescale Transformer (STT) демонстрирует снижение вычислительных затрат на 35.94% благодаря динамическому обучению средней пропускной способности обработки. Этот подход позволяет модели адаптировать объем вычислений, выделяемых для каждого входного токена, основываясь на оценке сложности данных. Вместо фиксированного количества вычислений для каждого токена, STT изучает среднюю необходимую пропускную способность для эффективной обработки последовательности, что приводит к значительному снижению общих вычислительных затрат без существенной потери производительности. Обучение средней пропускной способности происходит посредством анализа входных данных и адаптации количества вычислений в процессе обучения, что позволяет модели оптимизировать использование ресурсов.
Влияние на создание эффективных систем искусственного интеллекта
Новые архитектуры, основанные на принципе неожиданности, демонстрируют существенное повышение вычислительной эффективности по сравнению с традиционными Transformer-моделями. В отличие от последних, которые обрабатывают всю входную последовательность одинаково, эти системы динамически адаптируют объем вычислений, фокусируясь на наиболее информативных и неожиданных элементах данных. Такой подход позволяет значительно сократить количество необходимых операций, особенно при работе с длинными последовательностями, где традиционные модели испытывают экспоненциальный рост вычислительной сложности. Исследования показывают, что снижение вычислительных затрат достигается за счет отсеивания избыточной информации и концентрации ресурсов на тех частях входных данных, которые действительно вносят вклад в решение задачи. Это открывает возможности для создания более быстрых и энергоэффективных систем искусственного интеллекта, способных решать сложные задачи, ранее недоступные из-за ограничений вычислительных ресурсов.
Повышенная вычислительная эффективность, обеспечиваемая новыми архитектурами, открывает возможности для обработки значительно более длинных последовательностей данных и решения сложных задач, требующих глубокого логического вывода. Это позволяет искусственному интеллекту анализировать обширные тексты, например, целые книги или научные статьи, с сохранением контекста и пониманием взаимосвязей между различными частями информации. Кроме того, такие системы способны решать сложные логические задачи, требующие многоступенчатых рассуждений, что ранее было недоступно из-за ограничений в вычислительных ресурсах. Возможности, ранее казавшиеся недостижимыми, такие как создание продвинутых систем автоматического перевода, анализа настроений и генерации креативного контента, становятся реальностью благодаря способности этих архитектур эффективно обрабатывать информацию и извлекать из нее ценные знания.
Принципы вычислений, основанные на удивлении, демонстрируют потенциал для расширения области применения искусственного интеллекта за пределы обработки естественного языка. Исследования показывают, что аналогичный подход, фокусирующийся на обработке только новой и значимой информации, может быть успешно интегрирован в системы обучения с подкреплением, где агент концентрируется на неожиданных результатах своих действий для оптимизации стратегии. В области компьютерного зрения, такой механизм позволяет выделять наиболее релевантные области изображения, игнорируя избыточные или предсказуемые детали, что значительно снижает вычислительную нагрузку и повышает эффективность распознавания объектов. Таким образом, концепция вычислений, основанных на удивлении, представляет собой универсальный инструмент для создания более адаптивных и энергоэффективных систем искусственного интеллекта, способных к решению сложных задач в различных областях.
Современные системы искусственного интеллекта часто тратят вычислительные ресурсы на обработку избыточной или нерелевантной информации. Однако, принципы вычислений, основанные на обнаружении неожиданностей, позволяют сосредоточить ресурсы именно на тех данных, которые несут новую информацию. Такой подход, выстраивающий процесс вычислений вокруг прироста знаний, ведет к созданию более эффективных и экономичных систем. Вместо обработки всего входного потока, алгоритмы фокусируются на неожиданных сигналах, что значительно снижает потребность в вычислительной мощности и позволяет решать более сложные задачи, требующие обработки больших объемов данных. В результате, появляется возможность создавать интеллектуальные системы, которые не только демонстрируют высокую производительность, но и бережно используют доступные ресурсы, приближая нас к созданию действительно устойчивого и масштабируемого искусственного интеллекта.
Статья затрагивает идею динамического распределения вычислительных ресурсов в трансформерах, что неизбежно ведёт к усложнению инфраструктуры и появлению новых точек отказа. Кажется, будто каждый шаг к оптимизации порождает новый вид головной боли. Впрочем, сама концепция адаптации вычислений к сложности входных данных не нова. Как однажды заметил Алан Тьюринг: «Мы можем только надеяться, что машины не станут слишком умными, чтобы спорить с нами». Ирония в том, что стремясь создать эффективные системы, мы лишь усложняем их до такой степени, что предсказать все возможные сбои становится непосильной задачей. Всё, что можно задеплоить — однажды упадёт, и это — закономерность.
Куда это всё ведёт?
Предложенные архитектуры, манипулирующие глубиной и масштабом вычислений на основе «байесовского удивления», выглядят элегантно. Однако, за этой элегантностью неизбежно скрывается будущий техдолг. Любая динамическая аллокация ресурсов — это, по сути, усложнение, которое рано или поздно потребует рефакторинга — или, скорее, реанимации надежды на то, что это вообще работает в продакшене. Оптимизация вычислительной эффективности всегда даётся ценой усложнения архитектуры, и всё, что оптимизировано, рано или поздно оптимизируют обратно.
Более того, сама концепция «удивления» требует дальнейшего осмысления. Что именно считать «удивительным» для нейронной сети? И как избежать ситуации, когда сеть «удивляется» артефактам данных, а не истинным закономерностям? Неизбежно встаёт вопрос о регуляризации и устойчивости к adversarial атакам — старым добрым проблемам, которые не исчезают даже в мире динамических вычислений.
Вероятно, будущее за гибридными подходами, сочетающими преимущества динамической аллокации ресурсов с более статичными, но проверенными архитектурами. Архитектура — это не схема, а компромисс, переживший деплой. И задача исследователей — не изобрести идеальную архитектуру, а найти тот самый компромисс, который позволит построить работающую систему, пусть и с неизбежными ограничениями.
Оригинал статьи: https://arxiv.org/pdf/2511.21408.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- 10 лучших OLED ноутбуков. Что купить в марте 2026.
2025-11-29 20:32