Автор: Денис Аветисян
Новое исследование показывает, что представление изображений как отдельных объектов значительно улучшает способность моделей обобщать новые комбинации элементов, особенно при ограниченных данных и вычислительных ресурсах.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"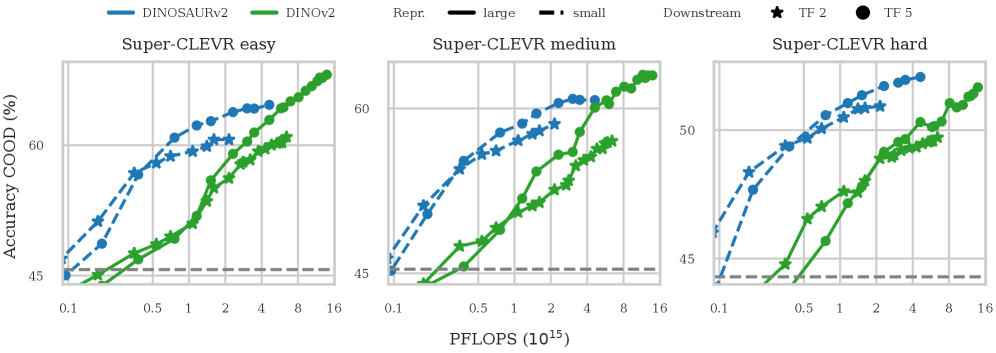
Объекто-центрические представления демонстрируют превосходство над плотными в задачах композиционного обобщения, используя контролируемый бенчмарк и синтетические наборы данных.
Способность к обобщению на основе новых комбинаций знакомых концептов остается сложной задачей для современных систем машинного обучения, несмотря на ее фундаментальную роль в когнитивных процессах человека. В работе, озаглавленной ‘Are Object-Centric Representations Better At Compositional Generalization?’, исследуется, насколько эффективно объектно-центричные представления (OC) поддерживают такое обобщение в задачах визуального восприятия. Полученные результаты демонстрируют, что OC-подходы превосходят плотные представления, особенно в сложных сценариях обобщения, требующих ограниченных вычислительных ресурсов или небольшого объема обучающих данных. Можно ли разработать универсальную архитектуру, сочетающую преимущества OC и плотных представлений для достижения оптимальной производительности в различных задачах компьютерного зрения?
Пределы Плотных Представлений: Зачем Разделять Целое на Части?
Традиционные методы компьютерного зрения зачастую оперируют плотными представлениями изображений, рассматривая их как единые, неструктурированные массивы данных. Такой подход, несмотря на свою кажущуюся простоту, существенно ограничивает возможности сложных рассуждений и анализа. Вместо того чтобы выделять и интерпретировать отдельные объекты и их взаимосвязи, система обрабатывает изображение целиком, что затрудняет понимание композиции сцены и препятствует решению задач, требующих детального осмысления визуальной информации. Подобное монолитное восприятие не позволяет эффективно использовать знания о мире и применять логические выводы, необходимые для достижения истинного визуального интеллекта.
Традиционные методы компьютерного зрения часто испытывают трудности в понимании взаимосвязей между объектами и композиционной структуры изображения, что является ключевым аспектом для достижения настоящего визуального интеллекта. Вместо анализа сцены как совокупности отдельных элементов и их отношений, системы часто обрабатывают изображение как единый массив пикселей. Это приводит к тому, что даже простые задачи, требующие понимания пространственных отношений («объект А находится слева от объекта Б») или иерархической структуры сцены (например, определение, что «стул стоит перед столом»), становятся сложными. Неспособность выделить и логически осмыслить эти связи ограничивает возможности систем в решении задач, требующих более глубокого понимания визуальной информации, что препятствует созданию действительно «умных» систем компьютерного зрения.
Ограниченность в выделении и логическом анализе отдельных объектов существенно снижает эффективность систем компьютерного зрения при решении задач, требующих глубокого понимания сцены. Традиционные подходы, рассматривающие изображение как единый массив пикселей, испытывают трудности в идентификации и интерпретации взаимосвязей между составляющими его элементами. Например, система может распознать наличие «стула» и «стола», но не способна понять, находится ли стул «перед» столом или «рядом» с ним, что критически важно для понимания контекста и выполнения сложных действий, таких как планирование маршрута или взаимодействие с окружением. В результате, даже при высокой точности распознавания отдельных объектов, системы оказываются неспособны к полноценному семантическому анализу и демонстрируют низкую производительность в задачах, требующих понимания пространственных отношений и причинно-следственных связей.
Объектно-Ориентированное Зрение: Новый Подход к Анализу Изображений
Объектно-ориентированные представления (object-centric representations) подразумевают разложение визуальной сцены на отдельные объекты, что обеспечивает более структурированное и интерпретируемое представление данных. В отличие от традиционных подходов, оперирующих с пикселями или глобальными признаками, данный метод позволяет выделить и идентифицировать дискретные сущности в изображении. Это достигается путем представления сцены как набора объектов, каждый из которых характеризуется своими собственными атрибутами и положением в пространстве. Такое представление упрощает последующий анализ, позволяя алгоритмам фокусироваться на конкретных объектах и их взаимодействии, а не на всей сцене целиком. Это способствует повышению эффективности решения задач компьютерного зрения, требующих понимания структуры сцены и взаимосвязей между объектами.
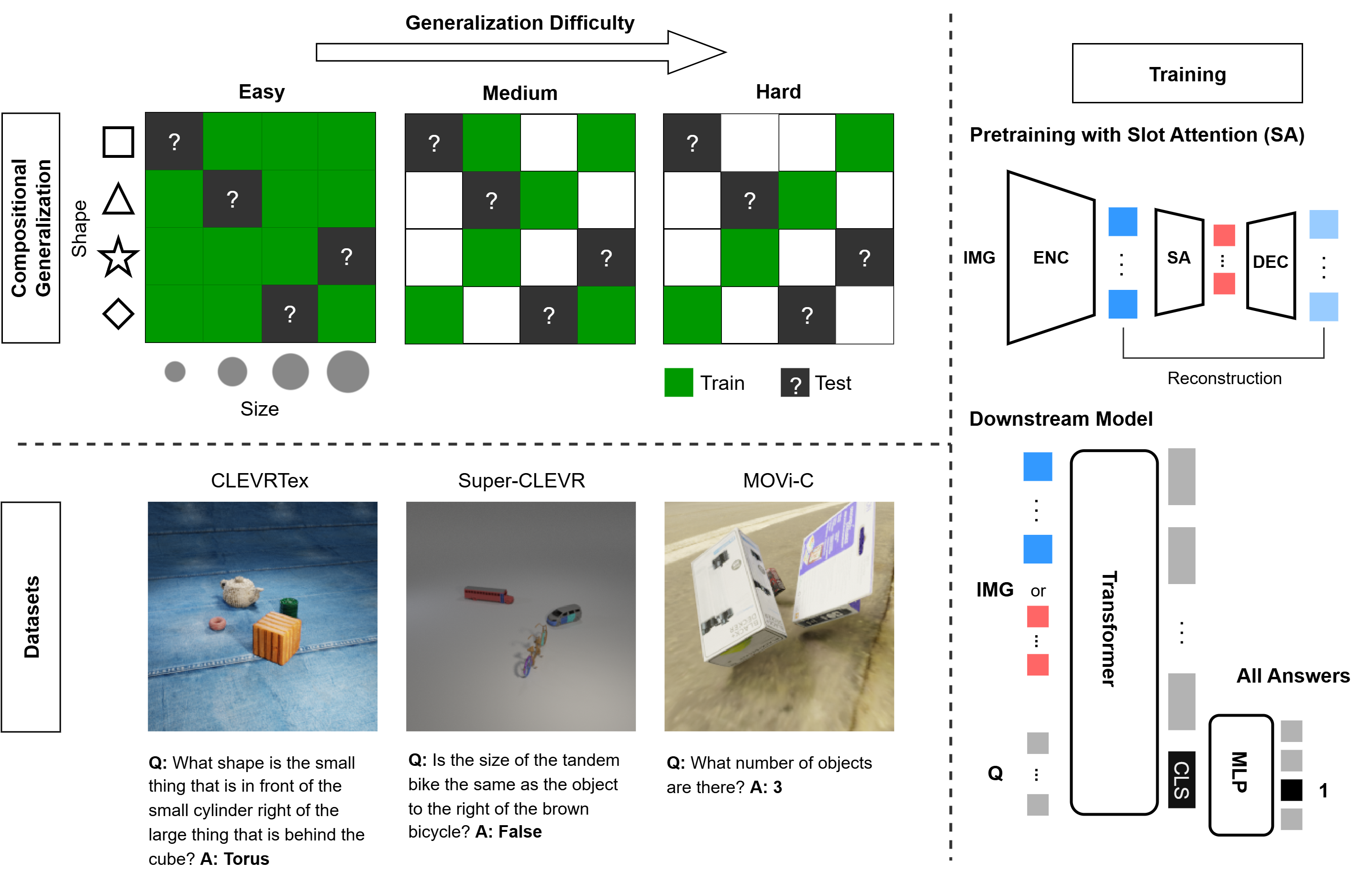
Механизмы, такие как Slot Attention, позволяют создавать объектно-центрированные представления путем фокусировки внимания на различных участках изображения и отнесения их к дискретным слотам, представляющим отдельные объекты. Этот процесс предполагает использование механизма внимания для динамического выделения релевантных признаков, а затем агрегацию этих признаков в отдельные слоты. Каждый слот соответствует конкретному объекту в сцене, что обеспечивает структурированное представление, пригодное для дальнейшей обработки и анализа. Slot Attention, в частности, использует итеративный процесс, в котором слоты уточняются на основе взаимодействия между ними и входным изображением, что позволяет выявлять и разделять объекты даже в сложных и зашумленных сценах.
Декомпозиция сцены на отдельные объекты позволяет проводить более эффективный анализ их характеристик, взаимосвязей и взаимодействий. Выделение объектов в дискретные слоты обеспечивает возможность моделирования и прогнозирования изменений в сцене, что существенно улучшает производительность в задачах, требующих пространственного рассуждения и понимания контекста, таких как робототехника, визуальное планирование и анализ видео. Например, идентификация отдельных объектов и их взаиморасположение позволяет предсказывать траектории движения или выявлять аномальные ситуации, что невозможно при анализе изображения как единого целого.
Фундаментальные Модели для Объектно-Ориентированного Зрения: Объединение Зрения и Языка
Использование предварительно обученных моделей, сочетающих зрение и язык, таких как SigLIP2 и DINOv2, в качестве основы значительно повышает эффективность объектно-ориентированных представлений. Эти модели, обученные на больших объемах данных, позволяют извлекать и кодировать визуальную информацию в сочетании с текстовыми описаниями, что обеспечивает более надежное и обобщенное представление объектов на изображениях. Перенос знаний, полученных в процессе предварительного обучения, позволяет снизить потребность в большом количестве размеченных данных для конкретных задач объектно-ориентированного анализа, а также повысить точность и устойчивость полученных моделей.
Модели DINOSAURv2 и SigLIPSAUR2 представляют собой развитие предобученных моделей компьютерного зрения и языка, направленное на создание надежных и эффективных объектно-ориентированных представлений. Эти модели используют архитектуры, оптимизированные для выделения и представления отдельных объектов в визуальной сцене, что позволяет проводить более точный визуальный анализ и рассуждения. В отличие от традиционных подходов, DINOSAURv2 и SigLIPSAUR2 обеспечивают более устойчивое представление объектов к изменениям освещения, ракурса и окклюзии, что повышает их эффективность в задачах визуального мышления и понимания.
Использование объектно-ориентированных представлений значительно повышает точность и обобщающую способность в задачах визуального вопросно-ответного взаимодействия (VQA). В частности, на датасете CLEVRTex, объектно-ориентированные представления демонстрируют улучшение точности композиционного обобщения (COOD) до 12.3% при использовании более компактной последующей модели (TF2). Это свидетельствует о возможности достижения сопоставимых или лучших результатов с меньшими вычислительными затратами и упрощенной архитектурой.
Оценка Обобщающей Способности: Преодолевая Границы Известных Сценариев
Композиционная обобщающая способность, то есть умение понимать новые комбинации визуальных элементов, является ключевым фактором для создания надежных систем искусственного интеллекта. В отличие от простого запоминания увиденного, такая способность позволяет системе адаптироваться к ранее не встречавшимся ситуациям, объединяя знакомые понятия в новые, осмысленные конструкции. Это особенно важно в реальном мире, где количество возможных комбинаций визуальной информации практически бесконечно, и система должна уметь эффективно интерпретировать и реагировать на незнакомые визуальные сцены, не ограничиваясь лишь теми, что были представлены в процессе обучения. Развитие этой способности открывает путь к созданию более гибких и адаптивных ИИ-систем, способных к полноценному взаимодействию с окружающей средой.
Специально разработанные наборы данных, такие как Super-CLEVR, CLEVRTex и MOVi-C, представляют собой ключевой инструмент для оценки способности искусственного интеллекта к композиционной обобщающей способности — умению понимать новые комбинации визуальных элементов, не встречавшиеся ранее в процессе обучения. Эти наборы данных построены таким образом, чтобы намеренно выйти за рамки стандартных сценариев, подвергая модель проверке на понимание не только отдельных объектов, но и их взаимодействия в невиданных ранее конфигурациях. Использование таких наборов позволяет исследователям точно оценить, насколько хорошо система способна к адаптации и обобщению знаний, что критически важно для успешного применения ИИ в реальных условиях, где предсказуемость ограничена.
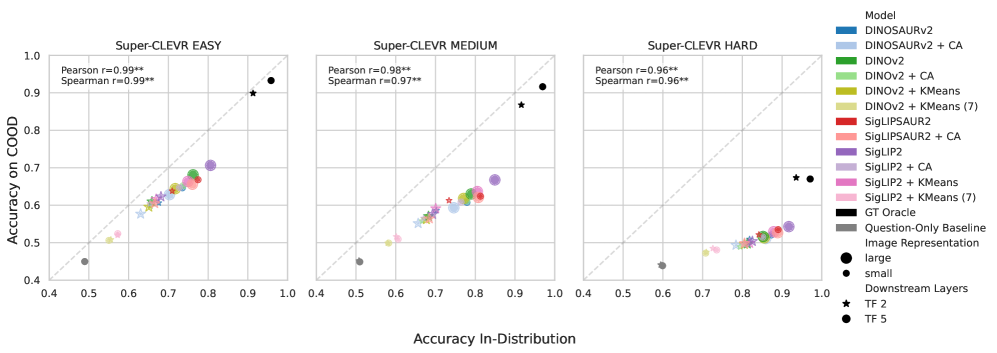
Исследования с использованием наборов данных, таких как Super-CLEVR, CLEVRTex и MOVi-C, выявляют способность моделей к рассуждениям о ранее не встречавшихся свойствах объектов и их взаимодействиях, что демонстрирует перспективность их применения в реальных условиях. Наблюдаемые положительные значения COOD Accuracy Delta, стабильно превышающие ноль в различных наборах данных и при различных вычислительных ограничениях, указывают на превосходство объектно-ориентированных представлений над плотными, особенно в ситуациях, когда объём данных, их разнообразие или вычислительные ресурсы ограничены. Это свидетельствует о том, что модели, способные выделять и понимать отдельные объекты и их атрибуты, более эффективно обобщают знания и адаптируются к новым, незнакомым ситуациям, что является ключевым фактором для создания надежных и интеллектуальных систем искусственного интеллекта.
Исследование закономерностей в визуальных данных является ключевым для достижения прогресса в области машинного обучения. Данная работа подтверждает, что объектно-центрированные представления превосходят плотные представления в задачах композиционной обобщённости, особенно когда ресурсы ограничены. Как отмечал Дэвид Марр: «Визуальное восприятие — это процесс построения структур от света». Эта фраза прекрасно отражает суть работы, ведь именно выделение и структурирование объектов на изображении позволяет системе лучше понимать сцену и успешно обобщать знания на новые, ранее не виденные комбинации. Подход, предложенный авторами, позволяет создавать более устойчивые и эффективные системы визуального восприятия.
Что дальше?
Представленные результаты, хотя и убедительно демонстрируют преимущество объектно-центрированных представлений в задачах композиционной обобщаемости, лишь подчёркивают глубину нерешённых вопросов. Успех в контролируемой среде синтетических данных не гарантирует переноса этих преимуществ на хаотичный мир реальных изображений. Необходимо исследовать, как шум, окклюзии и вариативность освещения влияют на стабильность и интерпретируемость объектно-центрированных представлений. Очевидно, что метрики качества, сами по себе, не отражают истинной способности модели к обобщению — требуется разработка более строгих и объяснимых критериев оценки.
Важным направлением представляется изучение взаимодействия между объектно-центрированными представлениями и символическим рассуждением. Способность выделять объекты — лишь первый шаг; критически важным является понимание отношений между ними и использование этих знаний для решения более сложных задач. Ограничения вычислительных ресурсов и объёма данных, подчеркнутые в данной работе, требуют поиска новых, более эффективных методов обучения, способных извлекать максимум информации из ограниченных источников.
В конечном счете, поиск действительно обобщающих представлений — это не столько инженерная задача, сколько философский поиск понимания мира. Истинная ценность модели заключается не в достижении наивысшего балла на бенчмарке, а в способности воспроизводить закономерности, лежащие в основе наблюдаемых явлений, и делать предсказания, основанные на глубоком понимании системы.
Оригинал статьи: https://arxiv.org/pdf/2602.16689.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Неважно, на что вы фотографируете!
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
- Рекомендации нового поколения: объединяя визуальное и текстовое
- Тело как сеть: NFC для носимой электроники нового поколения
- Российский рынок: Резервы тают, инвестиции растут, прибыли падают: что ждет инвесторов? (02.04.2026 16:32)
- Калькулятор глубины резкости. Как рассчитать ГРИП.
2026-02-20 04:48