Автор: Денис Аветисян
Новый подход к рекомендациям последовательных действий решает проблему нехватки данных о редких товарах, не ухудшая при этом качество предложений для популярных позиций.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"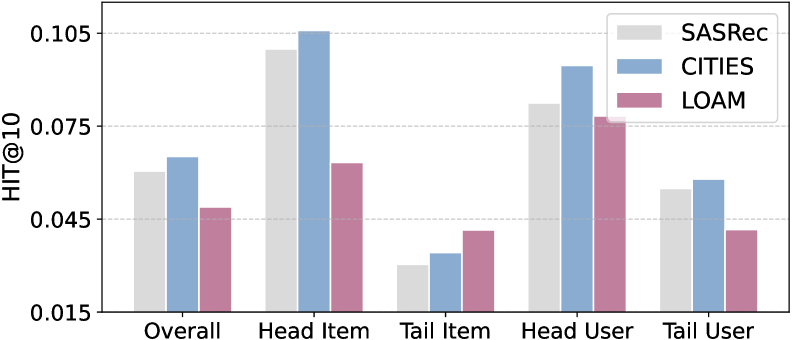
В статье представлена методика Tail-Aware Data Augmentation (TADA) для улучшения рекомендаций последовательных действий, основанная на специализированном увеличении данных и смешивании последовательностей для борьбы с разреженностью взаимодействий.
В задачах рекомендаций последовательностей часто наблюдается дисбаланс между популярными и редко взаимодействуемыми элементами, ограничивающий способность моделей к обучению предпочтений пользователей. В данной работе, посвященной ‘Tail-Aware Data Augmentation for Long-Tail Sequential Recommendation’, предложен новый подход, направленный на увеличение частоты взаимодействий с «длинным хвостом» элементов без снижения производительности для популярных позиций. Ключевым нововведением является метод аугментации данных, учитывающий взаимосвязи между редко взаимодействуемыми элементами и применяющий смешанную стратегию аугментации последовательностей. Позволит ли предложенный подход эффективно решить проблему разреженности данных и повысить качество персонализированных рекомендаций в реальных условиях?
Долгая Тень Рекомендаций: Проблема Редких Товаров
Традиционные системы последовательных рекомендаций сталкиваются с серьезными трудностями при работе с так называемым «длинным хвостом» — множеством наименований, для которых доступно ограниченное количество данных о взаимодействии пользователей. Эта проблема возникает из-за того, что алгоритмы машинного обучения требуют достаточного объема информации для точного прогнозирования предпочтений. Когда данные о взаимодействии с конкретным наименованием редки, система не может эффективно оценить его релевантность для конкретного пользователя, что приводит к снижению точности рекомендаций и уменьшению вероятности того, что пользователь откроет для себя новые, менее популярные товары или контент. В результате, пользователи часто видят рекомендации, основанные на популярных, хорошо изученных элементах, в то время как ценные, но малоизвестные наименования остаются незамеченными, ограничивая разнообразие предлагаемого контента и возможности для открытия нового.
Недостаток данных о взаимодействии с товарами из «длинного хвоста» приводит к снижению точности рекомендаций, что существенно ограничивает возможности пользователей находить новые, менее популярные, но потенциально интересные предложения. Это, в свою очередь, негативно сказывается на разнообразии контента, доступного на платформе, поскольку алгоритмы склонны отдавать предпочтение хорошо известным и часто выбираемым позициям. В результате, пользователи могут упускать из виду уникальные товары или контент, а платформы теряют возможность представить более широкий спектр предложений, что снижает общую привлекательность и потенциал для роста.
Существующие методы последовательных рекомендаций часто сталкиваются с трудностями при работе с так называемым «длинным хвостом» — множеством наименее популярных товаров или контента. Обобщения, применяемые к данным, не позволяют уловить тонкие взаимосвязи между этими элементами, поскольку их взаимодействие с пользователями ограничено. Вместо детального анализа специфических предпочтений пользователей к товарам из «длинного хвоста», алгоритмы склонны к усреднению, что приводит к неточным предсказаниям и снижает вероятность открытия пользователями новых, но релевантных позиций. Это, в свою очередь, ограничивает разнообразие предлагаемого контента и потенциально снижает вовлеченность пользователей на платформе, поскольку им сложнее найти что-то действительно интересное за пределами наиболее популярных предложений.
Аугментация Данных: Взлом Ограничений «Длинного Хвоста»
Аугментация данных представляет собой эффективный подход к решению проблемы “длинного хвоста” в задачах машинного обучения. Суть метода заключается в искусственном увеличении представленности редких элементов в обучающей выборке. Это достигается путем создания модифицированных копий существующих данных, что позволяет модели получить больше примеров для обучения и улучшить ее способность к обобщению на менее распространенные случаи. Недостаточность данных для редких элементов приводит к ухудшению производительности модели, поэтому аугментация является важным инструментом для повышения точности и надежности системы, особенно в задачах, где важна корректная обработка всех классов данных.
Методы CMR (Contextual Masked Replacement) и CMRSI (Contextual Masked Replacement with Semantic Insertion) используют операторы “Замена” (Substitute) и “Вставка” (Insert) для создания разнообразных и реалистичных дополненных последовательностей. Оператор “Замена” предполагает замену фрагмента последовательности другим, семантически похожим, выбранным из исходного набора данных. Оператор “Вставка” добавляет новые фрагменты, также выбранные из исходных данных, в существующую последовательность. Оба оператора применяются контекстно-зависимо, то есть выбор заменяемого или вставляемого фрагмента учитывает окружающие элементы последовательности, что позволяет создавать более когерентные и правдоподобные дополненные данные, повышая эффективность обучения моделей для обработки редких элементов.
Метод RepPad расширяет возможности аугментации данных за счет интеллектуального добавления исходных данных к последовательностям. В отличие от случайного заполнения, RepPad анализирует существующие данные и добавляет наиболее релевантные фрагменты, тем самым увеличивая контекст для обучения модели. Это позволяет модели лучше обобщать информацию о редких элементах, эффективно используя имеющиеся данные для создания дополнительных обучающих примеров и повышения производительности в сценариях с длинным хвостом распределения.
TADA: Индивидуальный Подход к Аугментации Последовательных Моделей
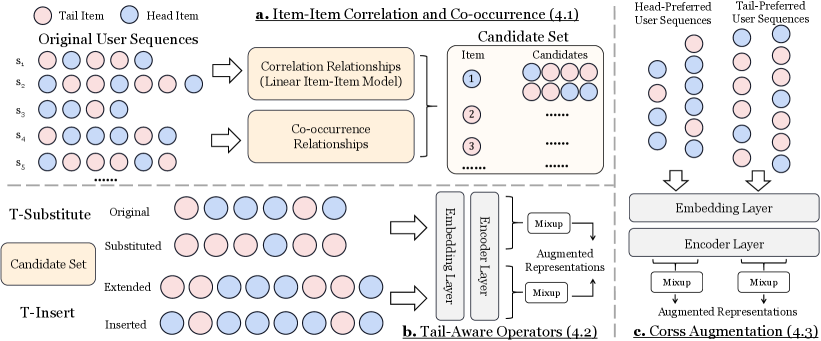
Метод TADA предлагает новый подход к аугментации данных, заключающийся в стратегическом применении операторов, таких как T-Substitute и T-Insert. T-Substitute предполагает замену головных элементов последовательности на релевантные элементы из “длинного хвоста” распределения, что позволяет модели лучше обобщать на редкие события. Оператор T-Insert, в свою очередь, вставляет контекстуально значимые головные элементы, расширяя обучающую выборку и улучшая способность модели к прогнозированию. Применение этих операторов осуществляется не случайным образом, а с целью целенаправленного увеличения представленности редких элементов в обучающих данных, что способствует повышению точности моделей последовательного прогнозирования.
Метод TADA повышает точность предсказания редких элементов последовательности путем замены начальных элементов (head items) на релевантные элементы из “длинного хвоста” (long-tail items). Этот процесс позволяет модели встречать редкие элементы в различных контекстах, улучшая ее способность к обобщению. Дополнительно, TADA вставляет контекстуально связанные начальные элементы, что способствует более эффективному обучению и повышению вероятности корректного предсказания редких элементов в новых последовательностях. Замена и вставка выполняются с учетом семантической релевантности, обеспечивая согласованность и качество аугментированных данных.
Метод TADA эффективно использует кросс-аугментацию (Cross Augmentation) для повышения устойчивости и разнообразия генерируемых выборок. Данный подход предполагает расширение аугментации не только внутри исходной последовательности, но и между различными «хвостовыми» элементами (tail items) и уже аугментированными последовательностями. Это позволяет создавать новые примеры, комбинируя информацию из разных источников и уменьшая зависимость от специфических характеристик отдельных элементов, что способствует улучшению обобщающей способности модели и повышению точности предсказаний для редких элементов.
Проверка Эффективности TADA и Область Его Применения
Эмпирические исследования, проведенные на разнообразных наборах данных, включающих платформы Douyin и Yelp, однозначно демонстрируют превосходство подхода TADA над базовыми моделями в задаче рекомендации товаров из “длинного хвоста”. Систематически превосходя конкурентов на различных метриках, TADA обеспечивает более точные рекомендации для редко встречающихся товаров, что особенно важно для платформ с обширным каталогом. Данный подход подтвердил свою эффективность на нескольких независимых наборах данных, что указывает на его устойчивость и общую применимость в различных сценариях рекомендательных систем. Результаты свидетельствуют о том, что TADA является надежным инструментом для улучшения качества рекомендаций и повышения удовлетворенности пользователей, особенно в отношении товаров, которые обычно остаются незамеченными.
Результаты исследований демонстрируют, что разработанный подход TADA обеспечивает впечатляющую точность рекомендации редких товаров. На различных наборах данных, включая Douyin и Yelp, TADA достигает показателя Hit Ratio@10 в 51.5% для товаров из «длинного хвоста», что значительно превосходит существующие базовые модели. Этот показатель отражает способность системы успешно предсказывать релевантные товары, даже если они редко приобретаются пользователями, и свидетельствует о значительном улучшении качества рекомендаций для нишевых продуктов и услуг. Таким образом, TADA предоставляет эффективное решение для повышения удовлетворенности пользователей и увеличения продаж товаров с низкой популярностью.
Внедрение TADA не ограничивается лишь повышением точности рекомендаций; система значительно расширяет их разнообразие, предлагая пользователям более широкий спектр товаров и услуг. Анализ показал, что TADA эффективно увеличивает частоту появления “длиннохвостых” товаров — редко запрашиваемых позиций, которые часто остаются незамеченными традиционными алгоритмами. Показатель Tail Coverage@5, измеряющий долю этих товаров в рекомендациях, демонстрирует существенное улучшение, что позволяет пользователям открывать для себя новые и неожиданные варианты. Таким образом, TADA способствует не только удовлетворению текущих потребностей, но и расширению кругозора пользователя, предоставляя доступ к более полному ассортименту доступных товаров.
Предложенный подход TADA демонстрирует устойчивую эффективность даже в условиях «холодного старта», когда информации о новых пользователях или товарах недостаточно для точных рекомендаций. Исследования показывают, что TADA не только поддерживает, но и превосходит существующие методы в подобных ситуациях, обеспечивая релевантные предложения даже при ограниченных данных. Кроме того, алгоритм отличается повышенной вычислительной эффективностью, что делает его применимым для масштабных рекомендательных систем, обрабатывающих огромные объемы информации в режиме реального времени. Это сочетание высокой точности и скорости обработки делает TADA практичным решением для широкого спектра задач, от электронной коммерции до социальных сетей и потоковых сервисов.
Исследование, представленное в статье, демонстрирует стремление к взлому системы рекомендаций, к поиску уязвимостей в алгоритмах, связанных с разреженностью данных. Авторы предлагают не просто улучшить существующие методы, а переосмыслить подход к аугментации данных, чтобы преодолеть ограничения, связанные с длинным хвостом. Этот процесс можно сравнить с реверс-инжинирингом, когда необходимо понять внутреннюю структуру системы, чтобы эффективно её модифицировать. Как заметил Анри Пуанкаре: «Чистая математика — это логическое искусство, и, следовательно, она не имеет ничего общего с опытом». Однако, в контексте рекомендательных систем, логика алгоритмов должна быть подкреплена и адаптирована к реальным данным, чтобы достичь оптимальной производительности, особенно при работе с разреженными взаимодействиями.
Что дальше?
Представленное исследование, по сути, лишь аккуратно подправляет симптомы, а не излечивает болезнь. До тех пор, пока системы рекомендаций оперируют данными, фундаментально искаженными неравномерностью взаимодействий, любые методы увеличения данных будут лишь временно сглаживать углы. Интересно, не является ли эта «аугментация хвоста» признанием собственного бессилия алгоритмов перед хаосом реальных пользовательских предпочтений? Необходимо сместить фокус с искусственного расширения данных на разработку моделей, способных эффективно извлекать знания даже из крайне скудных сигналов.
Более того, предложенная методика «перекрестного увеличения» подразумевает, что ценность последовательности взаимодействий определяется ее связью с другими последовательностями. Это ставит вопрос: не упускаем ли мы из виду истинную индивидуальность пользователя, сводя ее к статистической зависимости от поведения «толпы»? Возможно, стоит обратить внимание на модели, способные строить более абстрактные, устойчивые представления о предпочтениях, независимые от конкретных последовательностей действий.
В конечном итоге, данная работа — это еще один шаг в бесконечной игре «кошки-мышки» между алгоритмами и сложностью человеческого выбора. Утверждать, что проблема «длинного хвоста» решена, было бы наивно. Скорее, она просто приобрела новую, более изощренную форму, требующую дальнейшего анализа и, возможно, радикально новых подходов.
Оригинал статьи: https://arxiv.org/pdf/2601.10933.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Лучшие смартфоны. Что купить в марте 2026.
- Oppo Reno15 ОБЗОР: отличная камера, много памяти, скоростная зарядка
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- vivo V70 ОБЗОР: современный дизайн, портретная/зум камера, высокая автономность
2026-01-20 19:54