Автор: Денис Аветисян
Исследователи разработали систему, позволяющую создавать более естественные и универсальные взаимодействия человека с окружающими предметами в виртуальной среде.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"![Единая модель InterPrior, обученная на наборе данных OMOMO[28], демонстрирует способность к обобщению на ранее не встречавшиеся объекты и взаимодействия из наборов данных BEHAVE[3] и HODome[96], подтверждая её потенциал в задачах переноса обучения.](https://arxiv.org/html/2602.06035v1/x3.png)
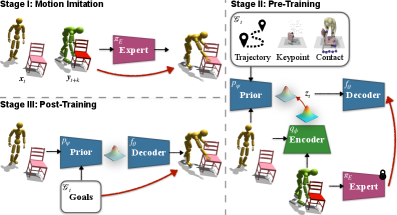
Представлен InterPrior — генеративный контроллер, объединяющий обучение с подкреплением и имитационное обучение для достижения устойчивых и адаптируемых навыков локомото-манипулирования.
Человекоподобные роботы сталкиваются с трудностями при выполнении сложных взаимодействий с объектами в реальном мире из-за огромного пространства возможных движений. В данной работе, ‘InterPrior: Scaling Generative Control for Physics-Based Human-Object Interactions’, представлен масштабируемый генеративный контроллер, объединяющий обучение с подражанием и обучение с подкреплением для достижения надежных и универсальных навыков локомо-манипуляции. Предложенный подход позволяет консолидировать полученные навыки в валидное многообразие, обеспечивая обобщение на новые цели и объекты. Не откроет ли это путь к созданию роботов, способных к гибкому и адаптивному взаимодействию с окружающим миром, подобно человеку?
The Challenge of Robust Human-Object Interaction
Традиционные методы управления роботами зачастую сталкиваются с трудностями при взаимодействии с человеком и объектами в реальном мире, поскольку подобные взаимодействия характеризуются высокой степенью сложности и изменчивости. В отличие от заранее запрограммированных движений в контролируемой среде, реальные сценарии HOI включают непредсказуемые действия человека, вариации в форме и весе объектов, а также влияние внешних факторов. Это приводит к тому, что роботы, разработанные на основе жестких алгоритмов, испытывают затруднения при адаптации к новым ситуациям, поддержании стабильного контакта и выполнении задач, требующих тонкой моторики и чувствительности. Неспособность учитывать эти нюансы часто приводит к ошибкам, нестабильности и даже потенциально опасным ситуациям, подчеркивая необходимость разработки более гибких и интеллектуальных систем управления роботами.
Для достижения действительно адаптивного и надежного взаимодействия человека и объектов, системы должны отказаться от жестко запрограммированных траекторий и перейти к интеллектуальному реагированию на непредвиденные обстоятельства. Традиционные подходы, основанные на заранее определенных движениях, оказываются неэффективными в динамичной и непредсказуемой среде реального мира. Новые разработки направлены на создание роботов, способных воспринимать изменения в окружающей обстановке, анализировать контактные взаимодействия и корректировать свои действия в реальном времени. Это требует интеграции сложных алгоритмов машинного обучения, систем компьютерного зрения и сенсорных технологий, позволяющих роботу не просто выполнять заданную последовательность действий, но и понимать намерения человека и приспосабливаться к его манере взаимодействия с объектами. В результате, появляется возможность создания более интуитивно понятных и безопасных робототехнических систем, способных эффективно работать бок о бок с людьми в различных сферах деятельности.
Современные методы взаимодействия роботов с объектами и человеком часто оказываются недостаточно устойчивыми к тонкостям контактной динамики. Исследования показывают, что при попытке воспроизвести сложные манипуляции, такие как сборка или помощь в переноске предметов, системы испытывают трудности при столкновении с неожиданными изменениями в силе трения, форме объекта или внешних возмущениях. Это приводит к нестабильности, потере контроля и даже повреждению как робота, так и объекта взаимодействия. Неспособность адекватно реагировать на эти нюансы ограничивает возможности роботов в реальных условиях и подчеркивает необходимость разработки более совершенных алгоритмов, способных предвидеть и компенсировать изменения в контактных силах для поддержания стабильного и надежного взаимодействия.

InterPrior: A Generative Controller for Adaptive Interaction
InterPrior представляет собой генеративный контроллер, основанный на физическом моделировании, предназначенный для создания правдоподобных и адаптируемых последовательностей движений при взаимодействии человека с объектами (HOI). В отличие от традиционных подходов, InterPrior не ограничивается воспроизведением заранее определенных действий, а генерирует новые, реалистичные движения, учитывающие физические свойства окружения и объекта взаимодействия. Этот подход позволяет системе адаптироваться к различным сценариям и обеспечивать стабильные и правдоподобные взаимодействия, даже в сложных условиях, благодаря использованию физического движка для моделирования динамики движения.
В основе InterPrior лежит комбинация обучения с подражанием и методов дистилляции знаний. Система использует экспертную политику InterMimic+ для генерации эталонных траекторий взаимодействия, после чего происходит передача знаний в более компактную и эффективную латентную политику. Дистилляция позволяет уменьшить вычислительную сложность и размер модели, сохраняя при этом высокую точность и реалистичность генерируемых движений. Процесс включает в себя обучение латентной политики имитации поведения эксперта, используя потери, основанные на различиях в действиях и состояниях, что обеспечивает эффективную передачу знаний и адаптацию к новым сценариям взаимодействия.
Использование физически-обоснованной симуляционной среды является ключевым аспектом InterPrior, обеспечивающим реалистичность и стабильность взаимодействий. В рамках этой среды, система моделирует динамику объектов и их взаимодействие с окружением, что позволяет InterPrior генерировать движения, соответствующие законам физики. Это особенно важно в сложных сценариях, где необходимо учитывать столкновения, трение и другие физические эффекты для обеспечения правдоподобности и предотвращения нереалистичных или нестабильных ситуаций. Такой подход позволяет InterPrior успешно функционировать в условиях, требующих точного учета физических ограничений и взаимодействия с окружением.
В отличие от систем, воспроизводящих заранее заданные движения, InterPrior спроектирован как генеративный контроллер, способный создавать разнообразные последовательности действий. Это достигается за счет моделирования в латентном пространстве, что позволяет системе генерировать новые, правдоподобные движения, а не просто повторять заученные. Генеративный подход обеспечивает адаптивность к изменяющимся условиям и позволяет системе эффективно решать широкий спектр задач взаимодействия человека и объектов (HOI) без необходимости хранения огромного количества предопределенных шаблонов поведения.
Enhancing Robustness with Distillation and Reinforcement Learning
В процессе вариационной дистилляции экспертная политика сжимается в компактное латентное пространство, что позволяет снизить вычислительные затраты и ускорить адаптацию модели. Этот метод заключается в обучении новой, более компактной политики, имитирующей поведение экспертной, но при этом требующей меньше ресурсов для вычислений и хранения. Сжатие достигается за счет уменьшения размерности представления политики, сохраняя при этом ее способность генерировать эффективные действия. В результате, модель становится более отзывчивой и способной быстро адаптироваться к изменяющимся условиям, что особенно важно в динамичных средах.
После дистилляции, для повышения устойчивости и способности к восстановлению после неожиданных событий, применяется тонкая настройка с использованием обучения с подкреплением. Этот процесс позволяет политике адаптироваться к непредсказуемым ситуациям, которые не были учтены в исходных данных или во время дистилляции. Обучение с подкреплением позволяет агенту исследовать пространство действий и учиться на ошибках, что приводит к формированию более надежной и отказоустойчивой стратегии поведения. В процессе обучения модель получает вознаграждение или штраф за каждое действие, что способствует оптимизации ее поведения в сложных и непредсказуемых условиях.
Формирование функции вознаграждения осуществляется с целью направленного обучения и стимулирования желаемого поведения агента, что непосредственно влияет на качество получаемых взаимодействий. Тщательная проработка функции вознаграждения включает в себя определение значимых параметров, отражающих успешное выполнение задачи, и присвоение соответствующих значений. Например, для задач манипулирования объектами вознаграждение может быть увеличено при приближении к цели и уменьшено при столкновениях. Важно, чтобы функция вознаграждения была не только эффективной в обучении, но и избегала нежелательных побочных эффектов, таких как эксплуатация особенностей среды или нереалистичное поведение. Оптимизация функции вознаграждения является итеративным процессом, требующим экспериментов и анализа полученных результатов для достижения оптимальной производительности.
InterDiff обеспечивает поддержку InterPrior за счет генерации реалистичной кинематической траектории движения, гарантируя физическую правдоподобность действий. Данная система использует диффузионные модели для создания плавной и последовательной кинематики, что позволяет избежать неестественных или невозможных поз и движений. Это критически важно для обеспечения стабильности и надежности системы управления, особенно в сложных и динамичных условиях, где реалистичные действия необходимы для успешного выполнения задач и предотвращения столкновений или других нежелательных ситуаций. Использование InterDiff позволяет создавать более безопасные и эффективные алгоритмы управления роботами и виртуальными агентами.

Impact and Future Directions for Adaptive Robotics
Способность InterPrior к обобщению опыта и восстановлению после сбоев представляет собой значительный прорыв в создании действительно надёжных роботизированных систем. В отличие от традиционных подходов, требующих перепрограммирования при изменении условий, InterPrior демонстрирует адаптивность, позволяющую успешно функционировать в новых, ранее не встречавшихся ситуациях. Это достигается благодаря интеграции физически обоснованного моделирования и обученных политик, что позволяет роботу не просто запоминать последовательности действий, а понимать принципы взаимодействия с окружающей средой. Такая способность к обобщению не только повышает устойчивость системы к неожиданным помехам и ошибкам, но и открывает возможности для её применения в динамичных и непредсказуемых условиях, приближая реальность создания автономных роботов, способных эффективно решать задачи в реальном мире.
Испытания, проведенные на гуманоидном роботе G1, подтвердили практическую применимость разработанного фреймворка в реальных условиях. Успешная интеграция и функционирование системы на сложной механической платформе демонстрирует, что предложенный подход к адаптивной робототехнике не ограничивается симуляциями, а способен эффективно работать с физическими устройствами. В ходе экспериментов G1 успешно выполнял ряд задач, требующих адаптации к меняющимся обстоятельствам и преодоления возникающих трудностей, что свидетельствует о высокой степени надежности и универсальности системы. Полученные результаты указывают на перспективность использования данной технологии для создания роботов, способных автономно действовать в сложных и непредсказуемых средах.
Интеграция физически обоснованного моделирования и алгоритмов машинного обучения позволила системе InterPrior достичь беспрецедентной адаптивности при решении задач, связанных с взаимодействием человека и робота (HOI). Благодаря использованию симуляции, система способна прогнозировать динамику сложных сценариев и планировать траектории, учитывающие физические ограничения и возможности. В сочетании с обученными политиками, это обеспечивает не только высокую точность выполнения заданий, но и способность эффективно восстанавливаться после непредвиденных ситуаций и адаптироваться к изменениям в окружающей среде. Такой подход открывает новые перспективы для создания роботов, способных к гибкому и надежному взаимодействию с людьми в реальных условиях, что является ключевым шагом к их широкому применению в различных областях, от промышленности до повседневной жизни.
Исследования показали, что разработанная система InterPrior демонстрирует заметные улучшения в успешности выполнения разнообразных задач и значительно снижает погрешности при следовании заданной траектории. В ходе экспериментов зафиксировано превосходство над существующими базовыми методами, что указывает на существенный прогресс в области адаптивной робототехники. Повышенная точность и надежность системы позволяют роботам более эффективно ориентироваться в сложных ситуациях и выполнять поставленные задачи с меньшим количеством ошибок, открывая новые возможности для их применения в различных сферах, от промышленности до помощи человеку.
Политика InterPrior демонстрирует впечатляющую эффективность, обеспечивая время отклика всего в 0,43 миллисекунды. Этот показатель критически важен для практического применения в реальных условиях, поскольку позволяет роботу реагировать на изменения в окружающей среде практически мгновенно. Такая скорость обработки данных открывает возможности для использования системы в динамичных и непредсказуемых сценариях, где требуется немедленное принятие решений и точное выполнение действий. Благодаря этому, InterPrior выходит за рамки лабораторных исследований и становится перспективной основой для создания надежных и адаптивных робототехнических систем, способных функционировать в сложных условиях реального мира.
Дальнейшие исследования сосредоточены на расширении возможностей разработанной системы в отношении более сложных задач и разнообразных сред. Планируется внедрение алгоритмов, позволяющих роботу не только адаптироваться к незнакомым ситуациям, но и прогнозировать возможные изменения в окружении, что значительно повысит надежность и автономность его действий. Особое внимание будет уделено обучению в условиях неполной информации и высокой неопределенности, а также интеграции с другими сенсорными системами для более полного восприятия мира. Развитие алгоритмов обучения с подкреплением, способных к переносу знаний между различными задачами, позволит значительно ускорить процесс адаптации к новым условиям и снизить потребность в больших объемах данных для обучения.
Исследование, представленное в данной работе, демонстрирует значительный прогресс в области управления взаимодействием человека с объектами, преодолевая ограничения существующих методов за счет комбинирования обучения с подкреплением и имитационного обучения. Этот подход позволяет создавать более устойчивые и универсальные навыки локомотоманипуляции. Как отмечал Дэвид Марр: «Представление о том, как вычисляется, является ключом к пониманию того, что вычисляется». Применительно к InterPrior, это означает, что понимание принципов генеративного контроля, лежащих в основе системы, необходимо для расширения её возможностей и адаптации к новым сценариям взаимодействия, что соответствует ключевой идее о создании более обобщенных и надежных моделей управления.
Куда двигаться дальше?
Представленная работа, подобно тщательно откалиброванному микроскопу, позволяет взглянуть на закономерности взаимодействия человека и окружающих предметов. Однако, и самый совершенный инструмент не способен охватить всю сложность реальности. Очевидно, что текущие модели, хоть и демонстрируют впечатляющую адаптивность, всё ещё ограничены в способности к обобщению на принципиально новые ситуации. Подобно тому, как опытный исследователь, стоит признать, что истинная «loco-manipulation» требует не просто имитации, а глубокого понимания физических принципов, лежащих в основе движения и взаимодействия.
Будущие исследования, вероятно, будут направлены на создание более компактных и эффективных представлений о физическом мире. Вариационные политики, безусловно, перспективны, но требуют дальнейшей оптимизации и, возможно, интеграции с другими подходами, такими как обучение с подкреплением на основе модели. Следующим шагом видится разработка систем, способных не только адаптироваться к различным объектам, но и предсказывать их поведение с высокой точностью.
В конечном счёте, цель не в создании идеального «генеративного контроллера», а в разработке алгоритмов, способных к истинному обучению и творческому решению задач. Подобно тому, как человек осваивает новые навыки, машина должна быть способна к самосовершенствованию и открытию новых, неожиданных стратегий взаимодействия с миром. И тогда, возможно, мы сможем приблизиться к созданию действительно «разумных» роботов.
Оригинал статьи: https://arxiv.org/pdf/2602.06035.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Макросъемка
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- Обзор вспышки Yongnuo YN500EX
2026-02-06 09:12