
В последнее время я больше экспериментирую с запуском языковых моделей (LLM) непосредственно на своем компьютере, и в большинстве случаев я использую Ollama для этого.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Инструмент Ollama – это выдающийся ресурс, который упрощает процесс загрузки и запуска больших языковых моделей непосредственно на вашем персональном компьютере, а новейшее графическое приложение делает его еще более удобным для пользователя. Этот инструмент плавно интегрируется в ваш рабочий процесс, однако у него есть один существенный недостаток.
Если у вас нет специализированного графического процессора (GPU), его производительность может быть не впечатляющей. Я использую его с RTX 5080, и он работает исключительно хорошо, но по сравнению с недавно прибывшим мини-ПК Geekom A9 Max, который находится на рассмотрении, впечатления значительно отличаются.
Ollama не предоставляет официальной совместимости с интегрированной графикой на операционных системах Windows. По замыслу разработчиков, она в основном полагается на центральный процессор. В некоторых случаях я предпочитаю не рассматривать альтернативные решения.
Вместо этого, выберите LM Studio, где вы можете легко использовать возможности встроенных графических процессоров без особых хлопот. Я могу сделать это за считанные секунды, и именно это я вам рекомендую попробовать, так как это превосходит Ollama в плане использования вашего интегрированного графического процессора.
Что такое LM Studio?
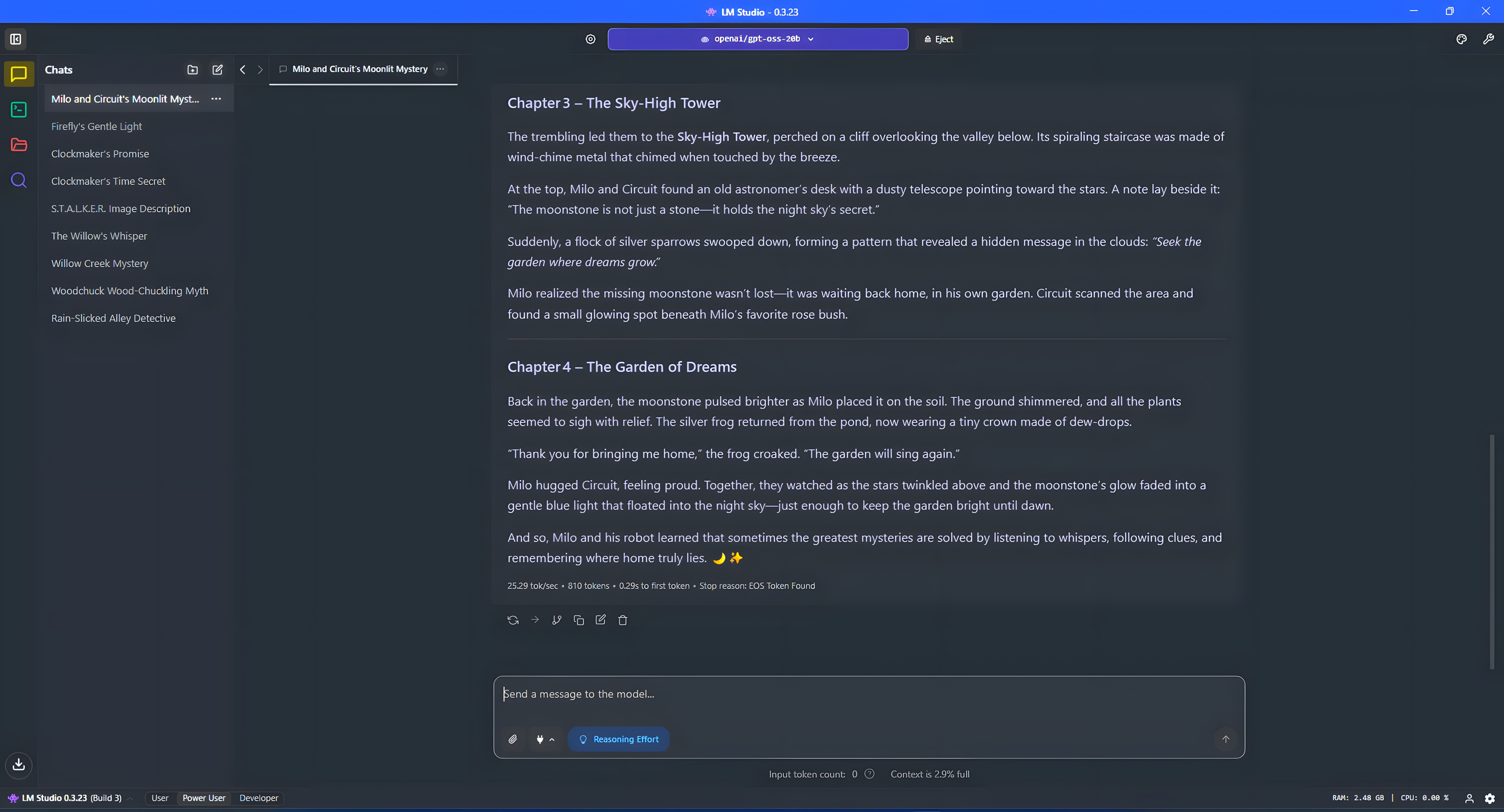
На вашем компьютере с Windows, LM Studio служит еще одним инструментом для получения больших языковых моделей (LLM) и экспериментов с ними. Хотя он работает немного иначе, чем Ollama, конечный результат остается неизменным.
Новая версия может похвастаться заметно более сложным графическим пользовательским интерфейсом по сравнению с оригинальным приложением Ollama, что делает ее еще более привлекательным выбором. Чтобы в полной мере использовать Ollama за пределами терминала, вам может понадобиться рассмотреть использование дополнительных инструментов, таких как OpenWebUI или расширение для браузера Page Assist.
Эта платформа представляет собой комплексное решение, где пользователи могут находить, устанавливать модели и взаимодействовать с ними через интуитивно понятный, похожий на чат интерфейс. Несмотря на множество сложных функций, мы изначально сохраним все простым для удобства использования.
Заметным преимуществом является то, что LM Studio включает в себя Vulkan, позволяя переносить модели на интегрированные графические процессоры AMD и Intel для вычислительных задач. Это важно, поскольку мои тесты последовательно показали, что использование графического процессора вместо центрального процессора приводит к более высокой производительности.
Итак, как использовать интегрированную видеокарту в LM Studio?
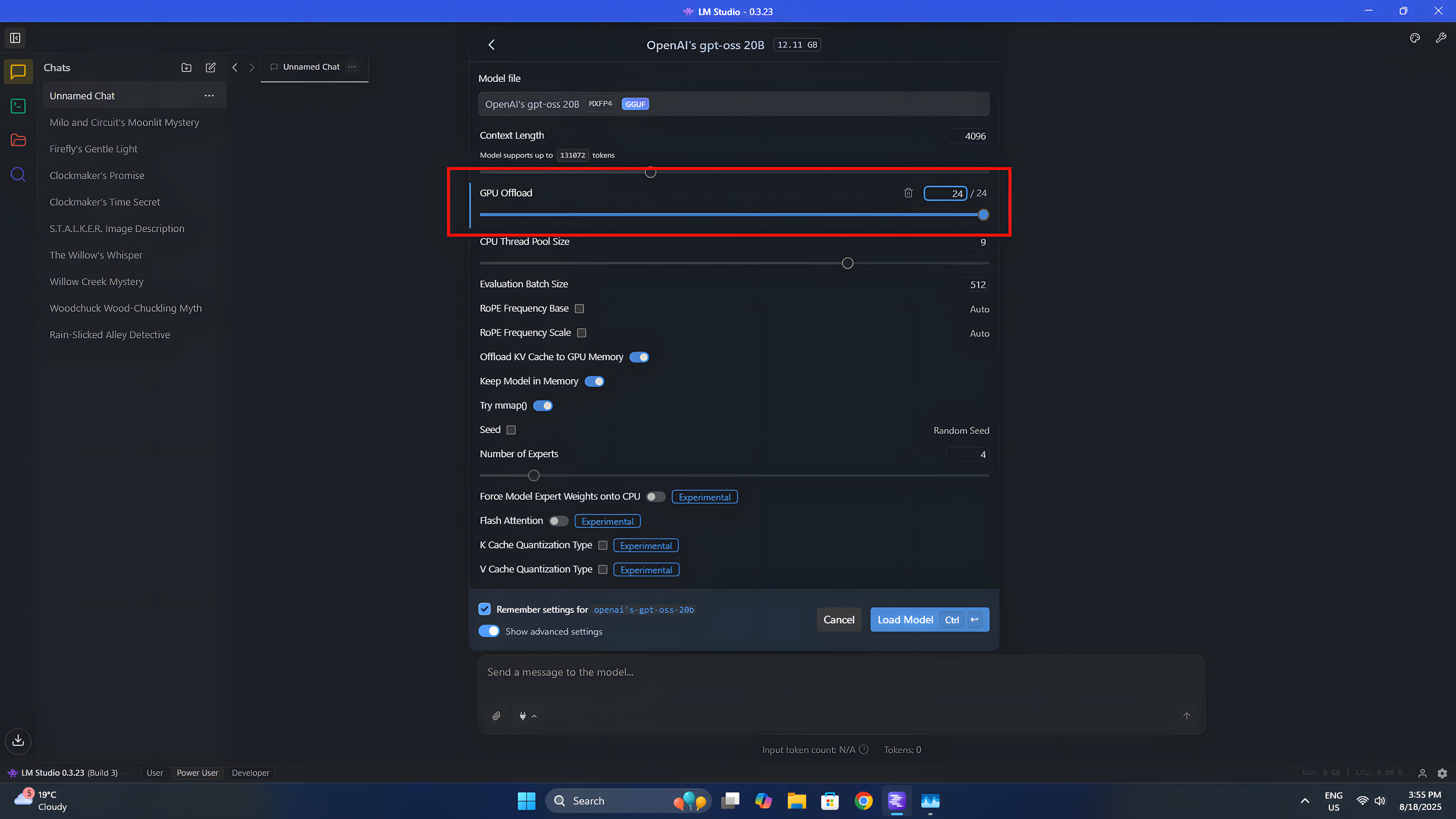
Еще одно преимущество при выборе LM Studio заключается в том, что использование вашего интегрированного графического процессора (iGPU) с большой языковой моделью (LLM) не требует каких-либо сложных или технических процедур настройки.
Чтобы использовать модель, вам нужно только выбрать желаемый параметр из выпадающего меню вверху. После выбора станет доступно несколько настроек. В нашем случае мы сосредоточимся в основном на переносе вычислений на GPU.
Система работает, используя прогрессивный подход, где каждый шаг подобен строительному блоку, вносящему вклад в общий процесс. Эти блоки, или слои, являются неотъемлемой частью функционирования Большой Языковой Модели (LLM). По мере продвижения инструкций вниз по этим слоям последовательно, последний слой генерирует ответ. Вы можете выбрать делегирование задач по всем слоям; однако, если вы выберете меньше слоев, ваш центральный процессор возьмет на себя некоторые дополнительные обязанности для завершения задачи.
После того, как вы будете довольны настройками, нажмите на кнопку «Загрузить модель». Это сохранит модель в памяти вашего устройства и позволит ей работать в соответствии с заданными вами ограничениями.

На Geekom A9 Max, оснащенном интегрированной графикой Radeon 890M, я планирую использовать весь его потенциал. Поскольку я не использую это устройство для игр при работе с искусственным интеллектом, я предпочитаю, чтобы графический процессор был полностью выделен для Большой Языковой Модели (БЯМ). Для этого я резервирую 16 ГБ из общего объема памяти системы в 32 ГБ исключительно для графического процессора, что позволяет ему эффективно загружать модель и работать оптимально.
Использование модели, аналогичной gpt-oss:20b, позволяет мне выделить весь её объём для выделенной памяти GPU, используя GPU для вычислений, при этом оставляя остальную память системы и CPU незатронутыми. В результате, с этой конфигурацией я могу обрабатывать приблизительно 25 слов или токенов в секунду.
Производительность сопоставима с настольным ПК с RTX 5080? Определенно нет. Однако, по сравнению с использованием только центрального процессора, она значительно выше. Кроме того, это позволяет избежать потребления почти всех ресурсов ЦП, что может быть полезно для другого программного обеспечения на вашем компьютере. В общем, графический процессор редко загружен, поэтому его использование кажется разумным выбором.
Если вы хотите добиться еще более высокой производительности, углубленное изучение деталей может быть полезным, но для этой дискуссии мы сосредоточимся на LM Studio. Примечательно, что если у вас нет выделенной видеокарты, LM Studio, безусловно, является лучшим инструментом для запуска локальных языковых моделей (LLM) на вашей системе. Просто установите его, и он будет работать бесперебойно без каких-либо сложностей.
Смотрите также
- Российский рынок в зоне турбулентности: рубль, ставки и новые риски (10.04.2026 01:32)
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Неважно, на что вы фотографируете!
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Как использовать режимы съёмки P, S, A, M на фотоаппарате?
- Искусственный интеллект, ориентированный на человека: новый подход
- Honor X80i ОБЗОР: плавный интерфейс, большой аккумулятор, объёмный накопитель
- Realme Narzo 70 ОБЗОР: плавный интерфейс, большой аккумулятор, замедленная съёмка видео
- Canon EOS 80D
- Proton только что запустил альтернативу Google Workspace и Microsoft 365, ориентированную на конфиденциальность.
2025-08-19 14:40