Автор: Денис Аветисян
Новое исследование показывает, что даже без визуального контента, движение камеры несет в себе значимую информацию для понимания происходящего в видеоряде.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"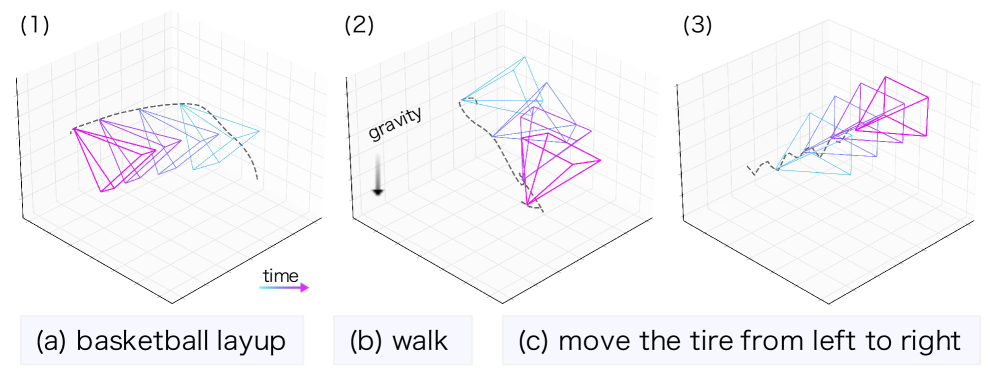
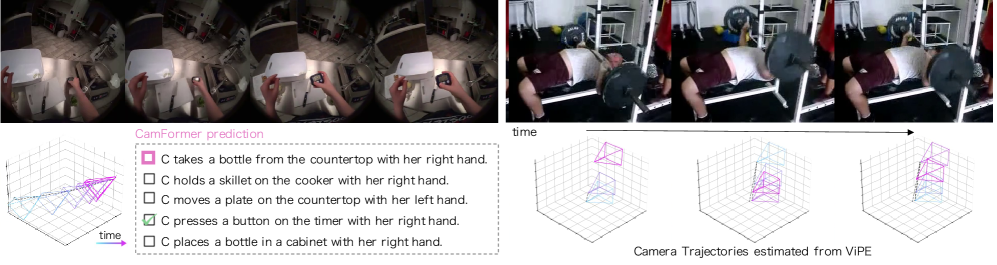
Траектория камеры, закодированная с помощью CamFormer, позволяет эффективно распознавать действия и интерпретировать сцены, не опираясь на визуальные данные.
Неочевидно, что содержание видео можно понять, не анализируя его визуальные пиксели, а лишь траекторию движения камеры. В статье ‘Seeing without Pixels: Perception from Camera Trajectories’ предложен новый подход к пониманию видео, основанный исключительно на анализе траектории камеры в пространстве. Исследование показывает, что траектория движения камеры содержит удивительно богатую семантическую информацию, позволяющую эффективно распознавать действия и интерпретировать сцены. Может ли траектория камеры стать полноценной модальностью для анализа видео, дополняющей или даже заменяющей традиционные методы обработки изображений?
Понимание Визуального Повествования: Задачи Движения Камеры
Традиционные методы анализа видеоконтента часто сталкиваются с трудностями при установлении связи между визуальными данными и их временным контекстом, а также при извлечении семантического смысла происходящего. Проблема заключается в том, что изображение, хотя и содержит богатую информацию, само по себе лишено указаний на последовательность событий и их значение. Для полноценного понимания видео необходимо не просто распознавать объекты и действия, но и учитывать, когда и как они происходят во времени. Это требует разработки алгоритмов, способных эффективно обрабатывать временные зависимости и выявлять причинно-следственные связи между различными кадрами, что представляет собой значительную проблему для современных систем компьютерного зрения. Отсутствие понимания временной структуры видео ограничивает возможности автоматического анализа, аннотирования и поиска по видеоархивам, препятствуя созданию действительно интеллектуальных систем обработки видеоинформации.
Анализ движения камеры — последовательности её положений, известной как «траектория камеры» — играет ключевую роль в понимании происходящих действий и общей картины в видеоматериалах. Траектория камеры не просто фиксирует перемещение устройства, но и несет в себе информацию о намерениях оператора, динамике сцены и значимости определенных объектов. Например, резкое изменение траектории может указывать на внезапное событие, а плавное следование за объектом — на фокусировку внимания зрителя. Изучение этой последовательности позволяет алгоритмам машинного зрения не только распознавать объекты, но и понимать, как они взаимодействуют друг с другом и что происходит в кадре, что является важным шагом к созданию систем, способных к полноценному визуальному осмыслению.
Существующие методы анализа видео часто рассматривают данные о траектории камеры как простой входной сигнал, упуская из виду богатый контекст, заложенный в последовательности её движений. Вместо того чтобы воспринимать траекторию как динамичный рассказ о происходящем, эти подходы склонны к её упрощению, что приводит к потере важной информации о действиях, взаимоотношениях объектов и общей структуре сцены. По сути, игнорируется тот факт, что каждое изменение в положении камеры — будь то панорама, наклон или приближение — несёт в себе семантический смысл, который необходимо извлечь для полноценного понимания визуального повествования. Такой подход ограничивает возможности систем компьютерного зрения в интерпретации сложных сцен и распознавании тонких нюансов происходящего, что снижает эффективность анализа видеоконтента.
CamFormer: Трансформер для Семантики Траектории
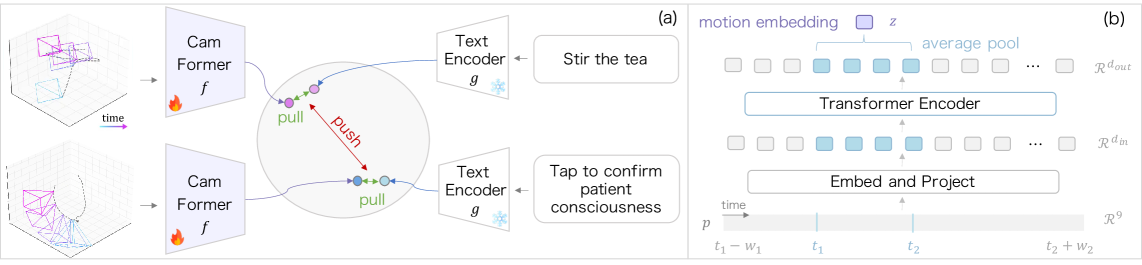
CamFormer использует архитектуру Transformer для преобразования данных о траектории камеры в семантическое векторное представление. Входные данные, представляющие собой последовательность координат и ориентации камеры во времени, обрабатываются механизмами самовнимания (self-attention), что позволяет модели устанавливать зависимости между различными моментами траектории. Это приводит к формированию плотного векторного представления, кодирующего информацию о движении камеры и, как следствие, о наблюдаемой сцене и происходящих действиях. Полученное семантическое вложение может быть использовано для различных задач, таких как распознавание действий, оценка сцены и прогнозирование будущей траектории камеры.
Архитектура CamFormer явно моделирует последовательный характер данных о траектории камеры, что позволяет улавливать временные зависимости, критически важные для понимания действий и атрибутов сцены. В отличие от методов, рассматривающих каждый кадр изолированно, CamFormer учитывает взаимосвязь между последовательными кадрами, выявляя закономерности во временной последовательности движения камеры. Это особенно важно для распознавания сложных действий, требующих учета последовательности шагов, и для точного определения атрибутов сцены, которые могут меняться со временем. Учет временных зависимостей позволяет модели более эффективно различать схожие действия и сцены, повышая общую точность анализа видео.
Архитектура CamFormer использует кодирование контекстуализированной траектории (Contextualized Trajectory Encoding) для включения информации из соседних кадров. Этот подход позволяет учитывать более широкий временной контекст, что повышает точность понимания последовательности действий и атрибутов сцены. В частности, для каждого кадра траектории анализируются не только его непосредственные данные, но и информация из окружающих кадров, что обеспечивает учет временных зависимостей и улучшает распознавание сложных сценариев. Данный метод позволяет моделировать последовательность действий как взаимосвязанный процесс, а не как набор независимых событий.
Валидация и Производительность: Согласование Визуального и Текстового Контента
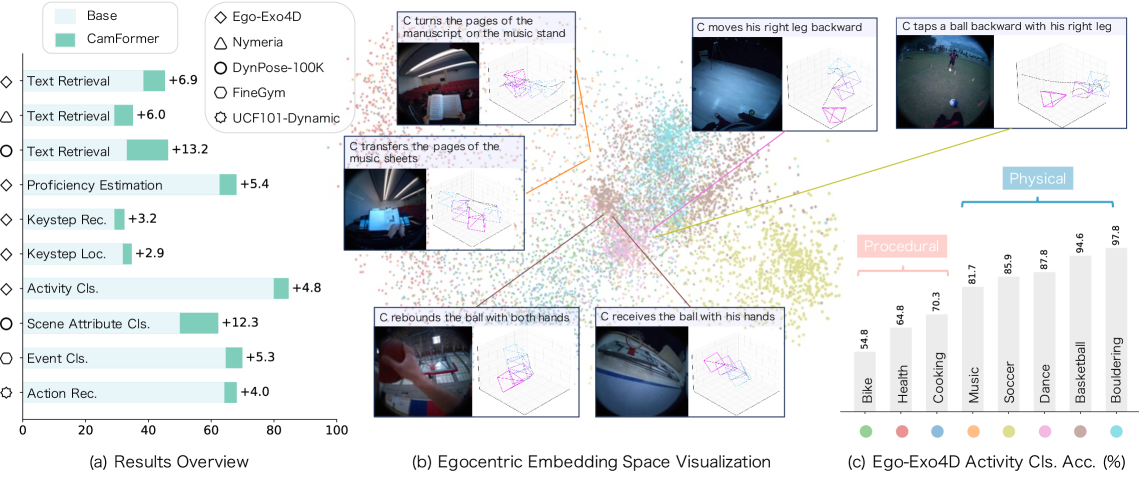
Модель CamFormer демонстрирует превосходные результаты в задачах поиска по тексту (Text Retrieval), обеспечивая эффективное сопоставление траекторий камеры с соответствующими текстовыми описаниями. Это достигается за счет способности модели устанавливать связь между визуальными данными, представленными траекториями движения камеры, и семантическим содержанием, выраженным в текстовых запросах. Фактически, CamFormer способен извлекать релевантные фрагменты видео на основе текстового описания желаемой сцены или действия, что подтверждается результатами экспериментов на датасете Ego-Exo4D.
В ходе тестирования на датасете Ego-Exo4D, модель CamFormer продемонстрировала точность извлечения текста (Text Retrieval Accuracy) на уровне 44.81% при использовании высокоточных данных о позах Aria. Этот показатель отражает способность модели эффективно сопоставлять траектории камеры с соответствующими текстовыми описаниями, основываясь на точных данных о положении и ориентации объектов в кадре. Использование высокоточных данных о позах является ключевым фактором, влияющим на производительность модели в задачах извлечения информации из видео.
При использовании оценок поз, полученных на основе видео, модель CamFormer демонстрирует высокую точность извлечения текста — 43.86% на наборе данных Ego-Exo4D. Этот результат указывает на устойчивость модели к неточностям, возникающим при оценке поз исключительно по видеопотоку, и подтверждает ее способность эффективно сопоставлять траектории камеры с соответствующими текстовыми описаниями даже при наличии шума в данных о позах.
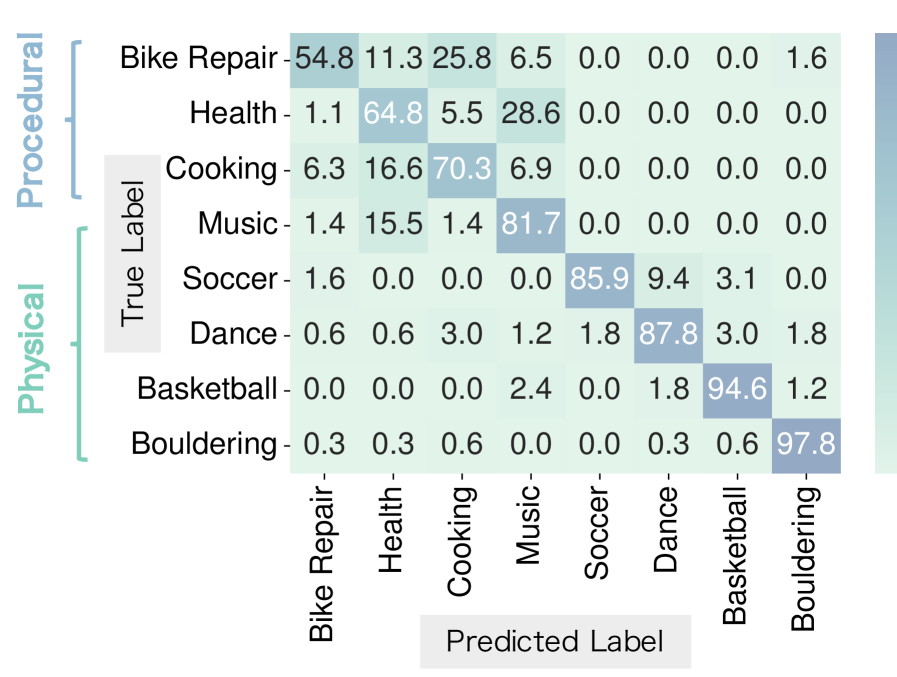
Модель CamFormer демонстрирует передовые результаты в задачах ‘Распознавания действий’ и ‘Классификации атрибутов сцены’, что подтверждает её способность к интерпретации визуального контента. Данные результаты, полученные на стандартных наборах данных, свидетельствуют о высокой точности модели в определении происходящих действий и характеристик изображаемых сцен. Эффективность CamFormer в данных задачах указывает на успешную реализацию механизма визуального понимания и способность к извлечению значимой информации из видеопоследовательностей.
Оценка устойчивости CamFormer проводилась на крупных наборах данных Ego-Exo4D и DynPose-100K. Использование этих масштабных данных позволило подтвердить способность модели к обобщению, то есть к эффективной работе с новыми, ранее не встречавшимися сценариями и условиями. Набор Ego-Exo4D включает в себя видео первого лица, демонстрирующие взаимодействие человека с окружающей средой, а DynPose-100K содержит большое количество данных о позах человека. Успешная работа CamFormer на этих наборах данных подтверждает её применимость в различных реальных условиях и сценариях использования.
В процессе обучения модели CamFormer ключевую роль играет метод контрастивного обучения. Этот подход позволяет модели формировать значимые представления данных путем сопоставления схожих и различных пар траекторий и текстовых описаний. Контрастивное обучение способствует выявлению корреляций между визуальными траекториями камеры и соответствующими текстовыми данными, что позволяет модели эффективно сопоставлять их. При этом, модель обучается увеличивать расстояние между представлениями несовпадающих пар траекторий и текстов, одновременно уменьшая расстояние между представлениями соответствующих пар. Такой подход обеспечивает более точное и надежное выявление взаимосвязей между визуальным и текстовым контентом.
Расширение Понимания Траектории: Выходя за Рамки Основного
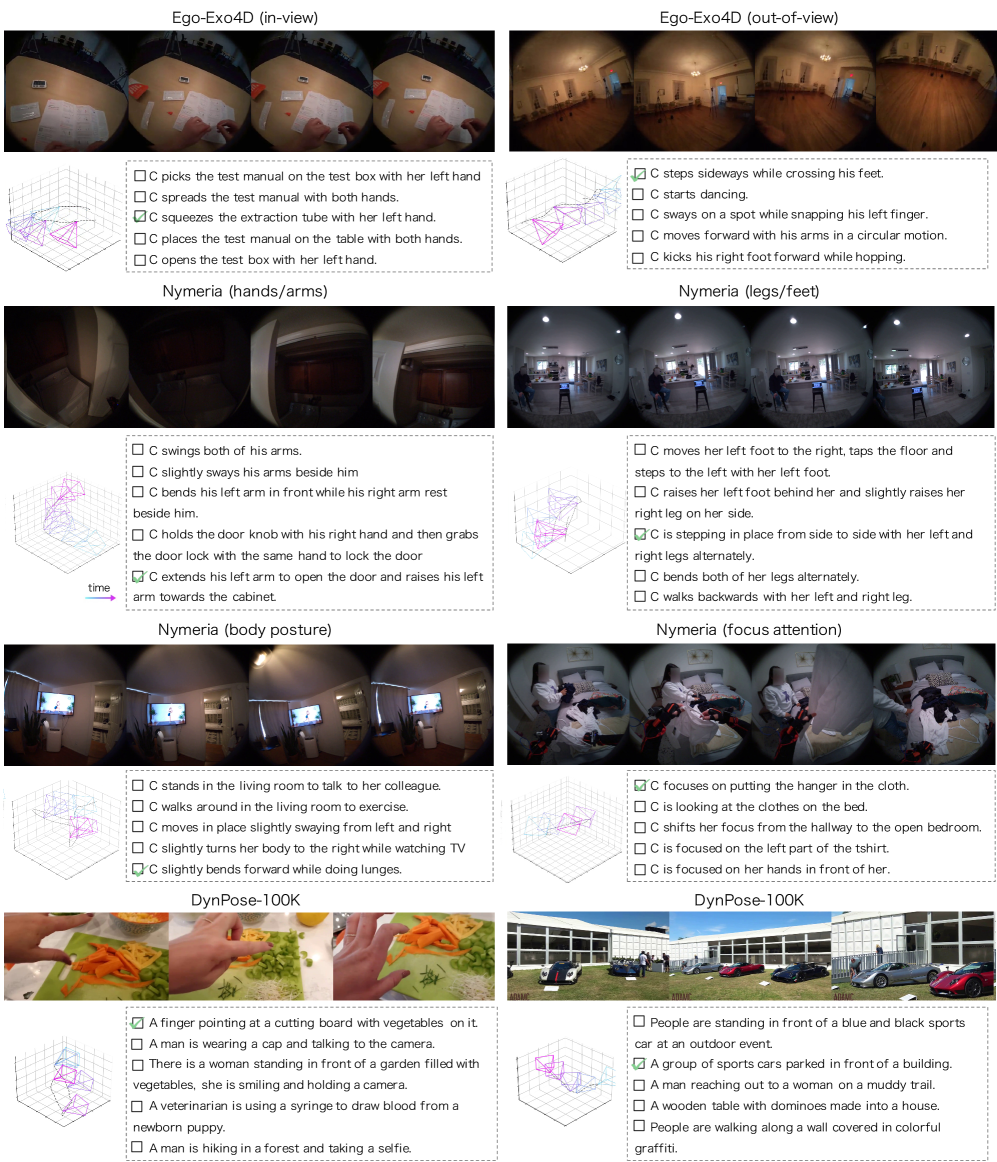
Для повышения точности моделирования траекторий движения, в CamFormer была внедрена кодировка направления гравитации. Этот подход позволяет учитывать влияние силы тяжести на объекты в пространстве, что существенно улучшает понимание моделью пространственных взаимосвязей. Вместо анализа абсолютных координат, система теперь учитывает вектор гравитации как ориентир, что особенно важно для реалистичного моделирования движения объектов, подверженных гравитации, таких как падающие предметы или движущиеся жидкости. Благодаря этому, модель способна более точно предсказывать траектории и понимать взаимодействие объектов в трехмерном пространстве, что открывает новые возможности для применения в областях, требующих высокой точности пространственного анализа, например, в робототехнике и компьютерном зрении.
Возможность локализации временных действий, реализованная в CamFormer, открывает широкие перспективы применения в различных областях. Данная технология позволяет точно определять моменты времени, когда в видеоряде происходят конкретные события, что критически важно для автоматизированного видеомонтажа и создания динамичных роликов. В системах видеонаблюдения это обеспечивает более эффективное обнаружение аномалий и отслеживание действий, представляющих интерес. Кроме того, в робототехнике, CamFormer позволяет роботам понимать последовательность действий, совершаемых людьми или другими роботами, что необходимо для безопасного и эффективного взаимодействия в реальном времени, а также для обучения роботов выполнению сложных задач посредством анализа видеоданных.
В отличие от традиционных методов, полагающихся на абсолютные координаты для определения траекторий, разработанный подход использует последовательность относительных положений. Это принципиальное отличие обеспечивает повышенную устойчивость к проблемам калибровки камеры. Использование относительных изменений в положении позволяет модели эффективно работать даже при неточностях в определении абсолютных координат, поскольку акцент делается на взаимосвязи между последовательными кадрами, а не на их привязке к фиксированной мировой системе координат. Таким образом, система демонстрирует надежность в различных сценариях, где точная калибровка камеры затруднена или невозможна, открывая возможности для применения в динамичных и неконтролируемых условиях.
Модель демонстрирует значительный потенциал в сочетании с методами видео-оценки для реконструкции сцен на основе скудных данных с камер. Этот подход позволяет создавать трехмерные модели окружения, используя минимальное количество визуальной информации, что особенно ценно в ситуациях, когда установка большого количества камер невозможна или нецелесообразна. Использование относительных координат и кодирование направления гравитации в сочетании с алгоритмами видео-оценки позволяет модели эффективно интерполировать недостающие данные и формировать связные и точные представления пространства. Это открывает возможности для применения в таких областях, как создание виртуальной реальности, автономная навигация роботов и анализ видеоданных с ограниченным количеством камер наблюдения.
Будущие Направления: К Комплексному Визуальному Искусственному Интеллекту
В дальнейшем планируется расширение возможностей CamFormer для обработки данных с нескольких камер и взаимодействия со сложными окружающими средами. Исследователи стремятся к созданию системы, способной эффективно объединять информацию из различных источников, учитывая перспективные искажения и окклюзии. Это позволит CamFormer не только точно реконструировать трехмерное пространство, но и понимать взаимосвязи между объектами и динамику происходящих событий. Особое внимание будет уделено разработке алгоритмов, устойчивых к шумам и изменениям освещенности, что критически важно для применения в реальных условиях, например, в беспилотном транспорте и робототехнике. Предполагается, что усовершенствованная версия CamFormer сможет адаптироваться к различным типам камер и конфигурациям, обеспечивая высокую точность и надежность в самых сложных сценариях.
Исследования направлены на интеграцию CamFormer с масштабными моделями «зрение-язык», такими как CLIP, что позволит значительно расширить возможности семантического понимания и генерации визуального контента. Объединение способности CamFormer к точному анализу траекторий камер с возможностями CLIP по сопоставлению изображения и текста открывает перспективы для создания систем, способных не только распознавать объекты и действия, но и генерировать осмысленные описания сцен, а также создавать новые визуальные представления на основе текстовых запросов. Такой симбиоз позволит CamFormer перейти от простого анализа видеопотока к глубокому пониманию происходящего и эффективной коммуникации с пользователем посредством естественного языка, открывая новые горизонты в областях робототехники, автоматизированного анализа данных и создания иммерсивных сред.
CamFormer рассматривается как ключевой элемент более широкой системы визуального искусственного интеллекта, способной к рассуждениям о сложных сценах и действиях. Разработчики предполагают, что интеграция данного подхода позволит не просто воспринимать визуальную информацию, но и интерпретировать ее в контексте происходящего, предсказывать дальнейшее развитие событий и, в конечном итоге, принимать обоснованные решения. Перспективы включают создание систем, способных к автономной навигации в сложных условиях, анализу поведения объектов и людей, а также к генерации осмысленных описаний визуальных сцен, что открывает возможности для создания интеллектуальных помощников и роботов, способных эффективно взаимодействовать с окружающим миром.
Точная интерпретация траекторий камеры играет ключевую роль в широком спектре современных приложений. От автономной навигации, где роботы и беспилотные автомобили должны понимать свое окружение и планировать маршруты, до иммерсивной виртуальной реальности, где реалистичное воссоздание движения камеры необходимо для ощущения присутствия, — способность точно отслеживать и анализировать перемещения камеры становится все более востребованной. Понимание динамики камеры позволяет не только восстанавливать трехмерную структуру сцены, но и предсказывать будущие положения объектов, что критически важно для принятия решений в реальном времени. Разработка алгоритмов, способных эффективно обрабатывать данные с камер, открывает новые возможности для создания интеллектуальных систем, способных адаптироваться к сложным условиям и взаимодействовать с миром вокруг.
Исследование траектории камеры, представленное в данной работе, подчеркивает важность понимания закономерностей движения для интерпретации видеоданных. Авторы демонстрируют, что даже без визуальной информации, траектория камеры несет в себе значительный семантический смысл, позволяя эффективно распознавать действия и понимать сцены. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен быть направлен на расширение человеческих возможностей, а не на их замену». Данный подход, акцентирующий внимание на траектории как независимом источнике информации, согласуется с этой философией, поскольку позволяет создавать более надежные и объяснимые модели для анализа видео, не полагаясь исключительно на сложные визуальные признаки. CamFormer, разработанный в рамках исследования, служит примером того, как можно использовать эту информацию для создания эффективных систем компьютерного зрения.
Куда Ведут Траектории?
Представленные исследования демонстрируют парадоксальную истину: для понимания видеоряда визуальная информация не всегда является первостепенной. Траектория камеры, сама по себе, несёт в себе значительный семантический вес. Однако, возникает вопрос: насколько глубоко можно продвинуться, полагаясь исключительно на кинематику взгляда? Очевидно, что полное понимание требует интеграции траекторных данных с визуальным контентом, но как найти оптимальный баланс между этими модальностями? Простое добавление визуальной информации к траекторному кодированию может оказаться недостаточным — необходимы более сложные модели, способные к истинному мультимодальному рассуждению.
Особый интерес представляет возможность расширения данного подхода за пределы ограниченного набора действий и сцен. Сможет ли CamFormer, или его преемник, эффективно работать в условиях высокой неопределенности и сложности реального мира? Перспективы кажутся обнадеживающими, но требуют решения проблем, связанных с обобщением моделей и адаптацией к новым, непредсказуемым ситуациям. Кроме того, исследование возможностей траекторного кодирования для задач, выходящих за рамки распознавания действий — например, для понимания намерений агентов или прогнозирования будущих событий — представляется весьма плодотворным направлением.
В конечном счете, данная работа заставляет задуматься о природе восприятия. Возможно, мы переоцениваем роль зрения как доминирующего чувства, упуская из виду важную информацию, заключенную в кинестетических и проприоцептивных ощущениях. Изучение траектории камеры — это, в определенной степени, попытка восстановить потерянный контекст, вернуть «тело» в процесс понимания видеоряда. Ирония заключается в том, что для создания «видящей» машины, возможно, потребуется научиться «чувствовать» движение.
Оригинал статьи: https://arxiv.org/pdf/2511.21681.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Санкционный удар по России: Минфин США расширяет список ограничений – что ждет экономику? (25.02.2026 05:32)
- Новые смартфоны. Что купить в марте 2026.
- Неважно, на что вы фотографируете!
- vivo X300 FE ОБЗОР: портретная/зум камера, беспроводная зарядка, объёмный накопитель
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- Умные Поверхности для Сетей Будущего: Новый Шаг к 6G
- Как установить Virtualbox на Windows 11 для бесплатных виртуальных машин
- Cubot X100 ОБЗОР: отличная камера, удобный сенсор отпечатков, плавный интерфейс
2025-11-28 07:38