Автор: Денис Аветисян
Новое исследование сравнивает способность Vision Transformers к низкоуровневой визуальной обработке с возможностями человека и традиционных сверточных нейронных сетей.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"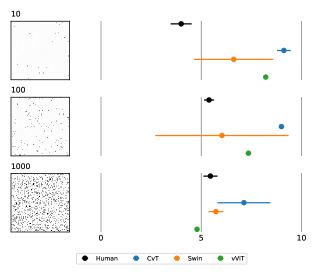
Оценка точности Vision Transformers в задачах, связанных с восприятием графических элементов, показывает, что они превосходят CNN, но пока уступают человеческому зрению.
Несмотря на стремительное развитие нейросетевых архитектур, способность моделей к визуальному восприятию, аналогичному человеческому, остается недостаточно изученной. В работе ‘Evaluating Graphical Perception Capabilities of Vision Transformers’ исследуется эффективность Vision Transformers (ViT) в выполнении элементарных задач визуального суждения, критически важных для интерпретации данных в визуализациях. Полученные результаты демонстрируют, что, хотя ViT превосходят сверточные нейронные сети (CNN) в подобных задачах, их соответствие человеческой точности восприятия ограничено. Какие архитектурные и тренировочные подходы позволят ViT лучше моделировать когнитивные процессы, лежащие в основе эффективной визуализации данных?
Разрыв между Теоретическими Моделями и Человеческим Восприятием
Ранние модели компьютерного зрения, такие как свёрточные нейронные сети, демонстрируют впечатляющую способность к распознаванию локальных признаков на изображениях, однако испытывают трудности с целостным восприятием картины, что удивительно перекликается с ограничениями человеческого зрительного восприятия. В то время как алгоритмы эффективно выделяют края, текстуры и простые формы, им часто не хватает способности интегрировать эти элементы в осмысленное целое, подобно тому, как человек воспринимает не просто набор пикселей, а взаимосвязанные объекты и сцены. Эта неспособность к глобальному пониманию ограничивает применение подобных моделей в задачах, требующих контекстуального анализа и распознавания сложных паттернов, подчеркивая необходимость разработки более совершенных алгоритмов, способных имитировать человеческую способность к обобщению и интерпретации визуальной информации.
Современные модели компьютерного зрения, несмотря на успехи в распознавании локальных признаков, зачастую демонстрируют неточность в интерпретации изображений, несоответствующую принципам человеческого графического восприятия. Эта проблема особенно актуальна в задачах, требующих понимания общих закономерностей и контекста, таких как анализ медицинских снимков или интерпретация данных дистанционного зондирования. Модели, не учитывающие нюансы, свойственные человеческому зрению — например, восприятие длины, площади или угла — могут давать ошибочные результаты, что ограничивает их применение в областях, где требуется высокая степень точности и надежности. В результате, развитие моделей, способных к более адекватному графическому восприятию, является ключевым направлением исследований в области искусственного интеллекта.
Воспроизведение сложного процесса человеческого зрительного восприятия представляет собой значительную проблему для современных моделей компьютерного зрения. Человеческий мозг не просто идентифицирует отдельные элементы изображения, но и активно интерпретирует их взаимосвязи и контекст, формируя целостное понимание сцены. В отличие от этого, многие алгоритмы фокусируются на локальных признаках, игнорируя глобальную структуру и семантические связи. Именно способность учитывать взаиморасположение объектов, их относительные размеры и общий контекст позволяет человеку быстро и эффективно понимать визуальную информацию, а отсутствие подобной способности ограничивает возможности компьютерных систем в задачах, требующих не просто распознавания, но и осмысленного анализа изображений.
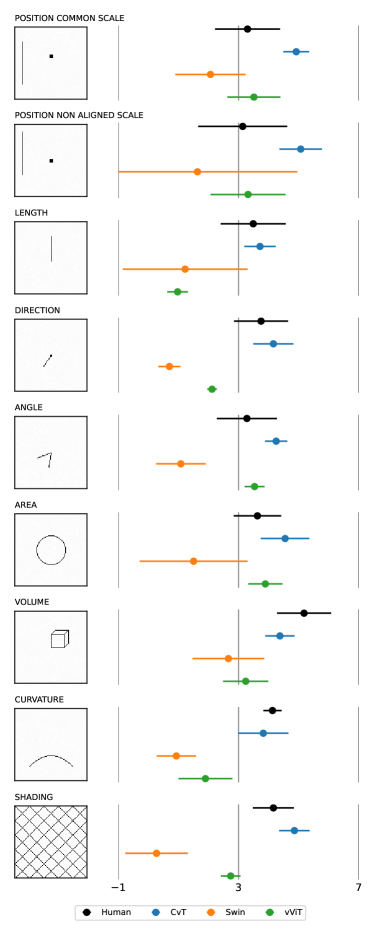
![Сравнение ранжирования элементарных перцептивных задач показало, что ViT-модели демонстрируют наибольшее расхождение с человеческим восприятием, особенно в оценке положения и длины, что указывает на более выраженную неопределенность и слабое соответствие субъективным суждениям, в то время как CNN демонстрируют более согласованные результаты с человеческими оценками, основанными на данных Кливленда и Макгилла [cleveland1984graphical] и Хейна и др. [haehn2018evaluating].](https://arxiv.org/html/2602.18178v1/x1.png)
Внимание к Глобальной Картинке: Видение Трансформеров
Ви́дение Трансфо́рмер (Vision Transformer) представляет собой перспективный подход в анализе изображений, основанный на механизме самовнимания (self-attention), изначально разработанном для обработки естественного языка. В отличие от традиционных сверточных нейронных сетей, которые обрабатывают изображения локально, Vision Transformer рассматривает изображение как последовательность «патчей» (фрагментов), аналогичных словам в предложении. Это позволяет модели учитывать глобальные зависимости между различными областями изображения, применяя механизм самовнимания для определения взаимосвязей между этими патчами. Таким образом, Vision Transformer адаптирует принципы обработки последовательностей, успешно применяемые в задачах обработки естественного языка, к задачам компьютерного зрения.
Механизм самовнимания (self-attention) позволяет модели Vision Transformer динамически оценивать вклад различных областей изображения в формирование общего представления. В отличие от сверточных нейронных сетей, которые обрабатывают изображение локально, используя небольшие фильтры, самовнимание учитывает взаимосвязи между всеми пикселями изображения. Это достигается путем вычисления весов внимания, определяющих, насколько сильно каждый пиксель должен влиять на представление других пикселей. В результате модель способна улавливать глобальный контекст и зависимости между отдаленными областями изображения, что повышает точность распознавания и анализа, особенно в задачах, требующих понимания общей композиции и взаимосвязей объектов.
Вычислительная сложность механизма самовнимания (self-attention) в Vision Transformer растет пропорционально квадрату размера входного изображения. Это означает, что для обработки изображений с высоким разрешением требуется экспоненциально больше вычислительных ресурсов и памяти. Например, при увеличении разрешения изображения в два раза, потребность в вычислительных ресурсах увеличивается в четыре раза. Вследствие этого, применение Vision Transformer к изображениям высокого разрешения сталкивается со значительными ограничениями, что требует разработки методов снижения вычислительной нагрузки или использования альтернативных архитектур для задач, требующих обработки детализированных изображений.
Swin Transformer: Эффективная Иерархия для Превосходного Восприятия
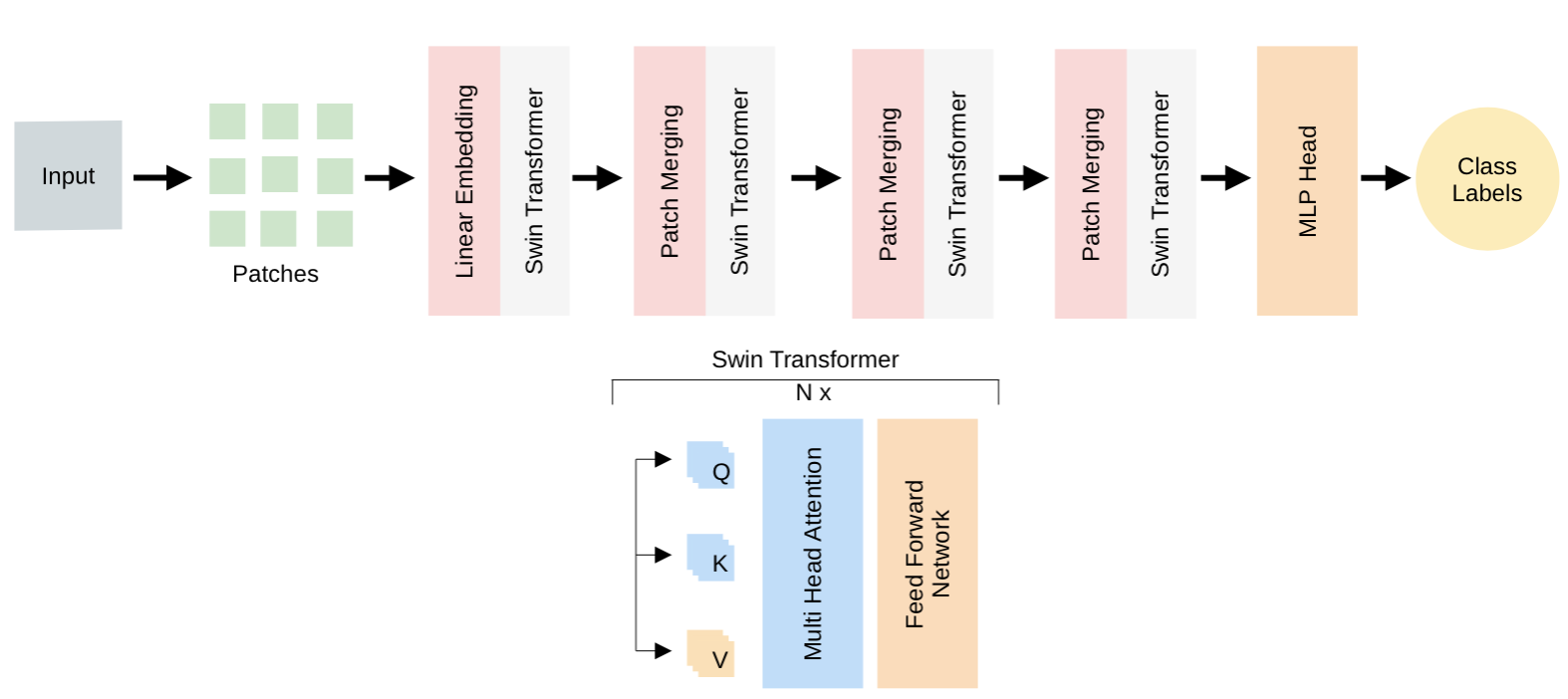
Сетевая архитектура Swin Transformer решает проблему масштабируемости, присущую стандартным Vision Transformers, посредством внедрения иерархической структуры и механизма “сдвигающихся окон” (Shifted Windows). Иерархия строится путем последовательного объединения токенов изображения, что позволяет модели обрабатывать изображения высокого разрешения с меньшими вычислительными затратами. Механизм сдвигающихся окон разделяет изображение на неперекрывающиеся локальные окна, в которых выполняется самовнимание (self-attention). Сдвиг окон между последовательными слоями обеспечивает связь между окнами, позволяя модели захватывать глобальный контекст, сохраняя при этом вычислительную эффективность локальных операций. Такая конструкция позволяет значительно сократить вычислительную сложность по сравнению с глобальным самовниманием в стандартных Vision Transformers, особенно при обработке изображений большого размера.
Иерархическая архитектура Swin Transformer обеспечивает эффективное извлечение как локальных деталей, так и глобального контекста изображения. Это достигается путем последовательной обработки признаков на разных уровнях разрешения, что позволяет модели строить многоуровневое представление данных — иерархическое обучение представлений. На нижних уровнях акцент делается на захвате точных деталей, необходимых для распознавания мелких объектов и текстур, в то время как на верхних уровнях происходит интеграция информации для понимания общей структуры и взаимосвязей между объектами на изображении. Такая организация позволяет модели эффективно решать широкий спектр задач компьютерного зрения, требующих понимания как локальных, так и глобальных характеристик изображения.
Несмотря на достигнутые улучшения в архитектуре Vision Transformers, включая Swin Transformer, результаты наших исследований показывают, что они уступают человеку в точности восприятия. Средняя логарифмическая абсолютная ошибка (MLAE) для Vision Transformers составляет 2.71, в то время как для человека этот показатель равен 3.16. Данный факт указывает на сохраняющийся разрыв между производительностью современных моделей машинного зрения и человеческим восприятием, несмотря на прогресс в области иерархического моделирования и эффективной обработки изображений.
Уточнение Оценки: Измерение Восприятия с Помощью Средней Логарифмической Абсолютной Ошибки
Для точной оценки Perceptual Accuracy необходимы надежные метрики, соотносимые с человеческим восприятием. Простое измерение различий между предсказаниями модели и реальностью часто оказывается недостаточным, поскольку не учитывает нюансы, свойственные человеческому зрению и обработке информации. Разработка метрик, которые коррелируют с субъективными оценками людей, позволяет не только объективно сравнивать различные модели, но и гарантировать, что улучшения в алгоритмах действительно приводят к результатам, воспринимаемым человеком как более реалистичные и правдоподобные. Использование таких метрик является ключевым шагом в создании искусственного интеллекта, способного не просто выполнять задачи, но и понимать и имитировать человеческое восприятие окружающего мира.
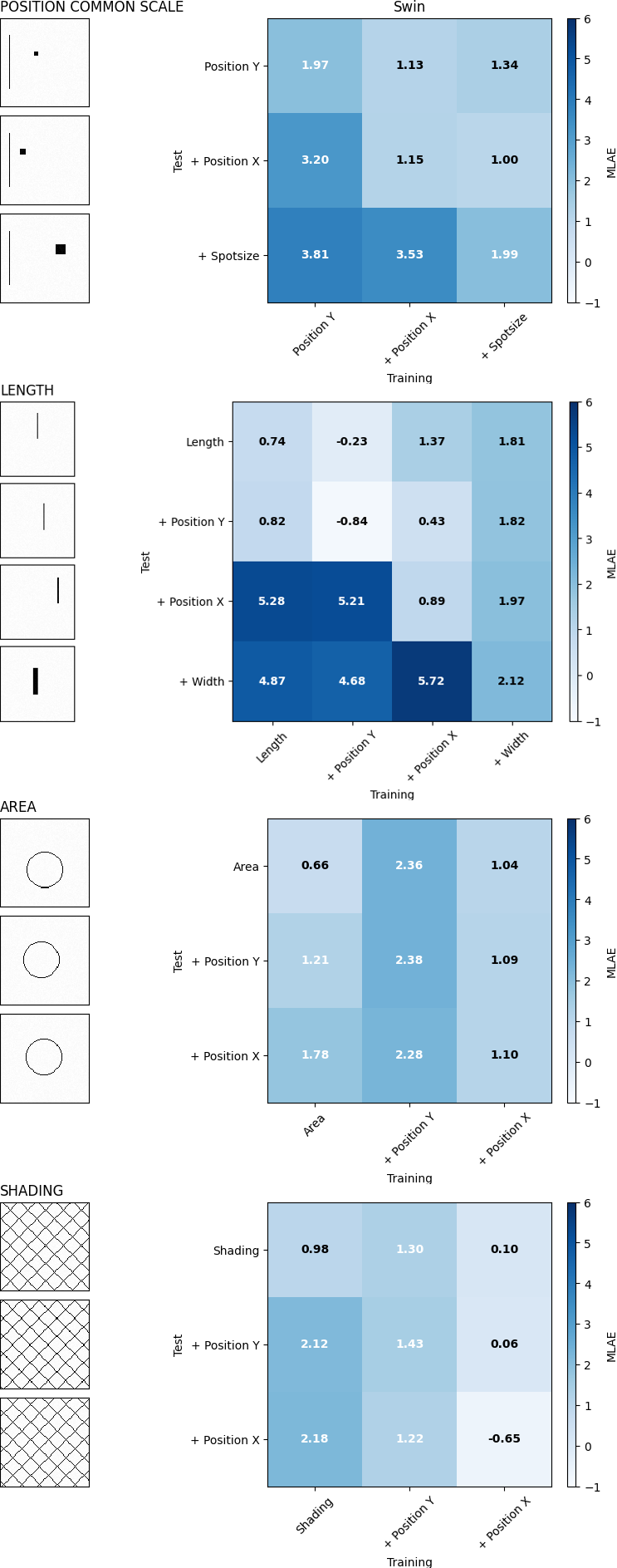
Средняя логарифмическая абсолютная ошибка (MLAE) представляет собой метрику, позволяющую с высокой чувствительностью оценивать расхождения между предсказанными моделью и фактическими воспринимаемыми значениями. В отличие от простых метрик, усредняющих абсолютные ошибки, MLAE использует логарифмическое преобразование, что особенно важно при оценке субъективных восприятий, таких как пространственное положение или длина объектов. Это преобразование позволяет более точно отражать значимость ошибок разного масштаба — небольшие расхождения вблизи ожидаемых значений воспринимаются как более критичные, чем сопоставимые отклонения в областях с большей неопределенностью. Благодаря этому, MLAE предоставляет возможность проводить детальное сравнение различных моделей и выявлять даже незначительные улучшения в их способности соответствовать человеческому восприятию, что делает ее незаменимым инструментом в разработке и оценке систем, ориентированных на восприятие.
Анализ результатов, полученных с использованием Swin Transformer, показал, что на задаче оценки позиции и длины, средняя логарифмическая абсолютная ошибка (MLAE) составила 4.72. Этот показатель значительно превышает человеческий уровень, равный 2.01, что указывает на существенный разрыв в согласованности между машинным и человеческим восприятием. Такое расхождение подчеркивает необходимость дальнейшей оптимизации моделей искусственного интеллекта для достижения более точной оценки пространственных характеристик, приближенной к человеческой.
Анализ результатов, полученных при решении задачи обработки облаков точек, выявил существенную разницу в оценках, предоставляемых моделью Swin Transformer и человеком. Средняя логарифмическая абсолютная ошибка (MLAE) для Swin Transformer составила 6.37, в то время как для человека — всего 4.95. Данное расхождение указывает на то, что модель демонстрирует последовательно более низкую точность восприятия в различных областях, включая задачи, связанные с анализом и интерпретацией трехмерных данных, представленных в виде облаков точек. Это подчеркивает необходимость дальнейшей оптимизации архитектуры и методов обучения модели для достижения уровня восприятия, сопоставимого с человеческим.
Направления Развития: Предварительное Обучение и Расширение Области Видения
Предварительное обучение на масштабных наборах данных, таких как ImageNet, по-прежнему является фундаментальным этапом в создании надежных и обобщающих моделей компьютерного зрения. Этот процесс позволяет моделям усваивать общие визуальные признаки и представления, значительно повышая их производительность при решении разнообразных задач. Использование огромного количества размеченных изображений позволяет алгоритмам эффективно извлекать иерархические признаки, от простых краев и текстур до сложных объектов и сцен. В результате, модели, прошедшие предварительное обучение, демонстрируют улучшенную способность к обобщению на новые, ранее не встречавшиеся изображения, а также требуют меньше данных для тонкой настройки под конкретную задачу, что делает их незаменимым инструментом в современной обработке изображений и видео.
Сочетание сверточных слоев и архитектур, основанных на трансформерах, как демонстрирует Конволюционный Визуальный Трансформер (Convolutional Vision Transformer), представляет собой перспективное направление в развитии компьютерного зрения. Сверточные нейронные сети эффективно извлекают локальные признаки из изображений, обеспечивая устойчивость к сдвигам и изменениям масштаба. В то же время, трансформеры, изначально разработанные для обработки последовательностей в задачах обработки естественного языка, демонстрируют способность улавливать глобальные зависимости и контекст в данных. Интегрируя эти два подхода, исследователи стремятся создать модели, способные одновременно эффективно обрабатывать локальные детали и понимать общую структуру изображения, что потенциально может значительно повысить производительность в различных задачах, включая распознавание объектов, сегментацию и визуальное рассуждение.
Перспективные исследования в области компьютерного зрения направлены на создание моделей, способных не просто распознавать визуальную информацию, но и осуществлять логические выводы на её основе. Такой подход позволит существенно расширить возможности применения искусственного интеллекта в различных сферах, особенно в робототехнике и автономных системах. Разработка алгоритмов, имитирующих человеческое рассуждение при анализе изображений, позволит роботам более эффективно взаимодействовать с окружающим миром, принимать обоснованные решения в сложных ситуациях и выполнять задачи, требующие не только зрительного восприятия, но и понимания контекста. В частности, это критически важно для создания автономных транспортных средств, способных безопасно ориентироваться в динамичной среде, а также для роботов-помощников, способных выполнять сложные бытовые задачи.
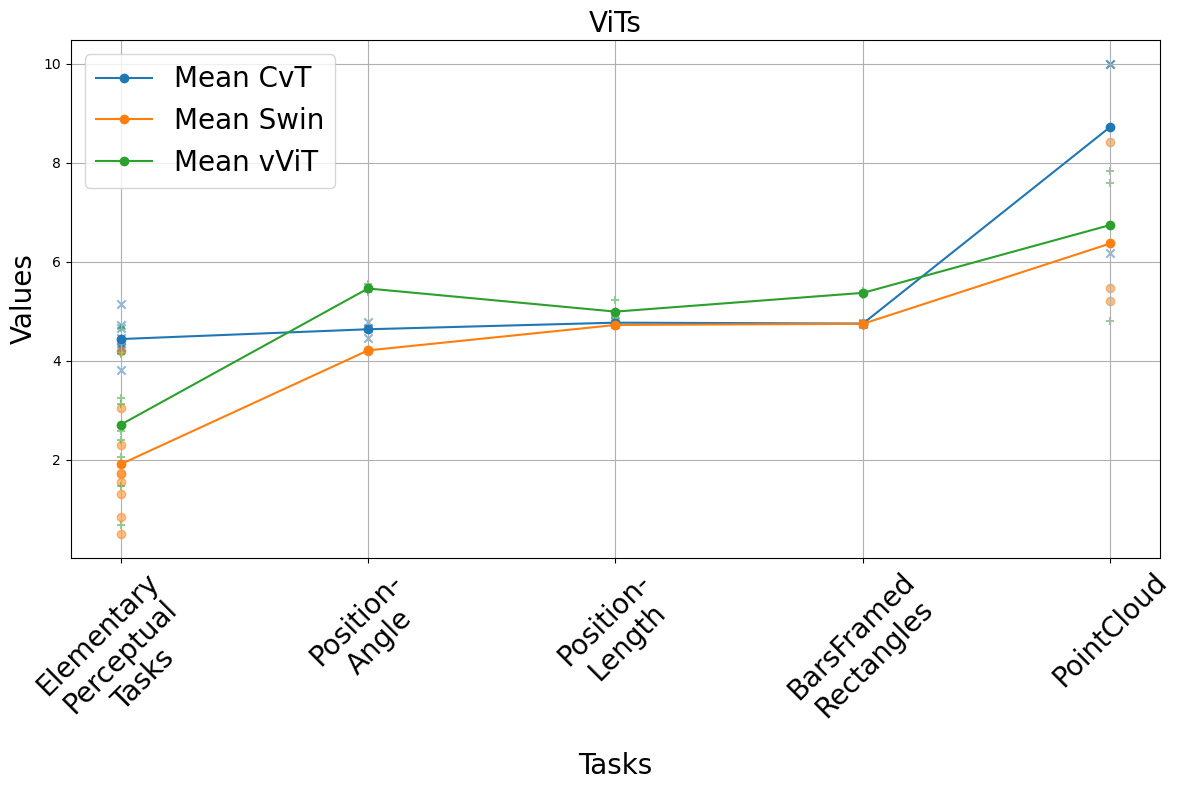
Исследование, оценивающее возможности Vision Transformers в задачах графического восприятия, закономерно выявляет отставание от человеческой точности. Эта тенденция, к сожалению, не нова. Как отмечал Ян ЛеКун: «Машинное обучение — это не магия, а инженерия». В погоне за архитектурными новшествами, вроде ViT, часто упускается из виду фундаментальное понимание того, как человек воспринимает визуальную информацию. Результаты исследования подтверждают, что даже превосходя CNN в определенных аспектах, ViT всё ещё нуждается в существенной доработке для надежного применения в задачах визуализации данных, где точность восприятия критически важна. В конечном счёте, каждая «революционная» технология завтра станет техдолгом, если не учитывать ограничения человеческого восприятия.
Что дальше?
Исследование возможностей Vision Transformers в задачах, имитирующих человеческое восприятие графики, закономерно выявило превосходство над сверточными сетями. Однако, эта победа представляется скорее тактической, чем стратегической. Улучшение метрик — это хорошо, но продакшен неизменно напомнит, что идеальная точность в лабораторных условиях — это лишь иллюзия перед лицом реальных данных и непредсказуемых пользовательских сценариев. Иначе говоря, всё новое — это старое, только с другим именем и теми же багами, просто теперь они решаются на более мощном железе.
Настоящая проблема заключается не в улучшении архитектуры, а в фундаментальном непонимании того, как человеческий мозг обрабатывает визуальную информацию. Пока алгоритмы стремятся к «точности», человеческое восприятие оперирует приближениями, упрощениями и контекстом. Иными словами, стремление к идеальной реконструкции графики может оказаться контрпродуктивным. Вполне вероятно, что будущее визуализации лежит в области алгоритмов, имитирующих не точность, а небрежность человеческого взгляда.
Поэтому, следующим шагом представляется не столько улучшение Vision Transformers, сколько разработка новых метрик, отражающих субъективное восприятие. И, конечно, ожидание первого крупного инцидента в продакшене, который окончательно расставит всё по своим местам. Ведь, как известно, продакшен — лучший тестировщик. И если всё сейчас работает — просто подождите.
Оригинал статьи: https://arxiv.org/pdf/2602.18178.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Российский рынок в зоне турбулентности: рубль, ставки и новые риски (10.04.2026 01:32)
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Неважно, на что вы фотографируете!
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Realme Narzo 70 ОБЗОР: плавный интерфейс, большой аккумулятор, замедленная съёмка видео
- Как использовать режимы съёмки P, S, A, M на фотоаппарате?
- Canon EOS 80D
- IdeaPad Slim 3 15IRH10R ОБЗОР
- Proton только что запустил альтернативу Google Workspace и Microsoft 365, ориентированную на конфиденциальность.
- Honor MagicBook 14 2022 ОБЗОР
2026-02-23 15:21