Автор: Денис Аветисян
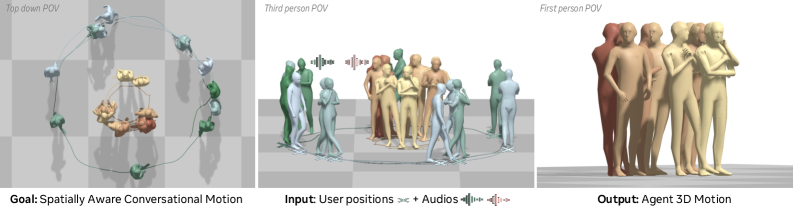
Новая система позволяет создавать виртуальных агентов, способных понимать пространственное окружение и естественным образом взаимодействовать с пользователем в реальном времени.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Разработана система для генерации реалистичной и контекстно-зависимой анимации виртуальных агентов, использующая причинно-следственные трансформаторы, сопоставление потоков и управление взглядом.
В современных виртуальных средах, где воплощенные агенты становятся все более распространенными, их движения часто ограничиваются простой синхронизацией с речью, упуская из виду важные аспекты пространственного взаимодействия. В работе ‘SARAH: Spatially Aware Real-time Agentic Humans’ представлен первый в своем роде метод, обеспечивающий генерацию реалистичных движений виртуальных агентов в реальном времени, учитывающих положение и перемещения пользователя. Достигнуто это благодаря сочетанию причинно-следственных трансформеров, моделей потокового соответствия и механизма контроля взгляда, позволяющего агентам естественным образом реагировать на пользователя и поддерживать зрительный контакт. Не откроет ли это новые возможности для создания более убедительных и интерактивных виртуальных взаимодействий?
Оживление Цифрового Аватара: Основа Глубокого Погружения
Для создания действительно захватывающих виртуальных сред необходимы воплощённые разговорные агенты, способные реалистично реагировать на окружающую обстановку. Эти агенты должны не просто отвечать на вопросы, но и демонстрировать поведение, соответствующее физическим законам и логике виртуального мира. Например, агент должен уметь обходить препятствия, реагировать на изменение освещения или звука, а также адаптировать свою позу и жесты в зависимости от контекста беседы. Отсутствие такой реалистичной реакции приводит к эффекту «зловещей долины», когда кажущаяся близость к человеку лишь усиливает ощущение неестественности и дискомфорта, разрушая иллюзию погружения и снижая эффективность взаимодействия.
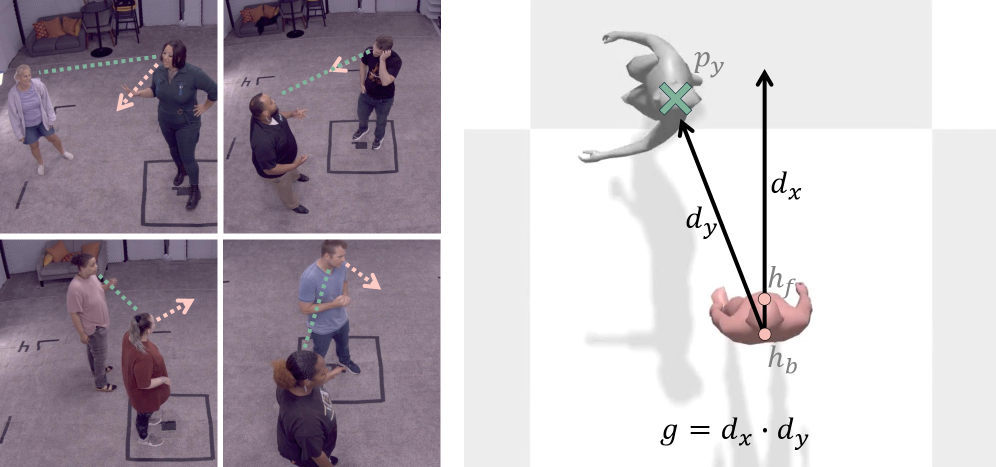
Создание убедительных виртуальных агентов требует одновременного достижения двух сложных задач: естественной разговорной речи и правдоподобной, соответствующей контексту, моторики. Ключевым аспектом, определяющим реалистичность поведения агента, является его способность к пространственному осознанию. Агент должен не только понимать смысл сказанного, но и учитывать свое положение в виртуальном пространстве, а также взаимное расположение объектов и других персонажей. Недостаточное внимание к пространственному восприятию приводит к неестественным движениям и реакциям, разрушая иллюзию присутствия и снижая степень погружения пользователя. Поэтому, разработка алгоритмов, позволяющих агенту динамически оценивать окружающую среду и адаптировать свои действия соответствующим образом, является критически важной для создания действительно правдоподобных и интерактивных виртуальных персонажей.
Существующие подходы к созданию виртуальных агентов зачастую не способны обеспечить плавность и адекватную реакцию на изменяющуюся обстановку, что приводит к ощущению неестественности и отчужденности у пользователя. Несмотря на успехи в области обработки естественного языка, синхронизация речи с движениями и жестами остается сложной задачей. Агенты нередко демонстрируют задержки в реакциях или нелогичные действия, что разрушает эффект присутствия и снижает уровень погружения в виртуальную среду. Такой разрыв между сказанным и сделанным, между намерением и воплощением, создает ощущение неполноты и препятствует формированию доверия к виртуальному собеседнику, делая взаимодействие неубедительным и искусственным.
Для создания действительно убедительных виртуальных агентов необходим принципиально новый подход, объединяющий обработку естественного языка и управление движениями. Существующие методы часто рассматривают эти аспекты изолированно, что приводит к несогласованности между речью и действиями агента и разрушает эффект присутствия. Новый подход предполагает интеграцию лингвистических моделей с системами планирования движений, позволяя агенту не просто понимать сказанное, но и мгновенно реагировать на него соответствующими жестами, мимикой и перемещениями в пространстве. Это требует разработки алгоритмов, способных преобразовывать смысл высказываний в конкретные моторные команды, обеспечивая плавность, естественность и контекстуальную релевантность поведения агента, что является ключевым фактором для достижения полного погружения в виртуальную среду.
Причинно-Следственная Моторика: Выход за Рамки Прогнозирования
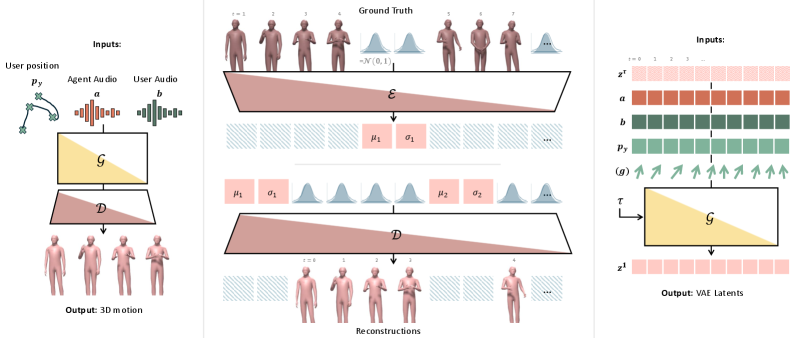
Традиционные методы генерации движения основываются на предсказании будущих состояний, что неизбежно вносит задержку между текущим состоянием и реакцией персонажа. Этот подход, требующий оценки будущих состояний, приводит к неестественным и запаздывающим движениям, особенно в динамичных сценариях. Задержка возникает из-за необходимости обработки данных и вычисления траектории движения на основе предсказаний, что не позволяет мгновенно реагировать на изменения окружающей среды или действия пользователя. В результате, движения могут выглядеть несинхронными и неправдоподобными, снижая общее качество и реалистичность симуляции.
В отличие от традиционных методов генерации движения, основанных на предсказании будущих состояний, причинно-следственный подход позволяет создавать движение непосредственно из текущего состояния системы. Это исключает задержки, связанные с необходимостью прогнозирования, и обеспечивает немедленную реакцию на изменения. Вместо того, чтобы предсказывать куда система двинется, данный подход генерирует движение, исходя из текущих условий, что обеспечивает более естественное и отзывчивое поведение. Такой механизм особенно важен в приложениях, требующих высокой точности и минимальной задержки, например, в системах управления роботами и виртуальной реальности.
Для реализации данного подхода используется модель потокового соответствия (Flow Matching Model), представляющая собой генеративную модель, обучающуюся отображать случайный шум в реалистичные последовательности движений. Обучение происходит путем определения векторного поля, которое постепенно трансформирует шум, распределенный по некоторому пространству, в данные, соответствующие желаемым движениям. Этот процесс основан на задании непрерывного пути между образцами шума и целевыми данными, что позволяет генерировать новые, правдоподобные последовательности движений, не требуя прогнозирования будущих состояний. Эффективность модели достигается за счет оптимизации транспортного процесса и минимизации расхождения между сгенерированными и реальными данными.
В отличие от традиционных методов генерации движения, которые основываются на прогнозировании будущих состояний, предлагаемый подход ориентирован на непосредственное создание движения, исходя из текущего состояния. Это достигается за счет отказа от предсказательной логики и перехода к моделированию причинно-следственных связей, что позволяет избежать задержек и неестественных реакций. Вместо того, чтобы предсказывать, как система будет двигаться, модель формирует траекторию движения, учитывая текущие условия и внутренние факторы, обеспечивая тем самым более согласованное и реалистичное поведение.
Усиление Реализма: Данные, Представление и Контроль
Критически важным фактором для обучения моделей является использование высококачественного обучающего набора данных. В данном случае, используется Embody 3D Dataset, представляющий собой обширную коллекцию реалистичных примеров человеческих взаимодействий, включая невербальные сигналы и пространственные отношения (проксемику). Набор данных содержит записи движений, поз и жестов людей в различных социальных ситуациях, что позволяет модели изучать и воспроизводить правдоподобное поведение, учитывающее контекст и социальные нормы. Объем и разнообразие данных в Embody 3D Dataset способствуют повышению реалистичности генерируемых моделей и их способности адекватно реагировать на различные сценарии взаимодействия.
Для обеспечения стабильности и физической правдоподобности генерируемых последовательностей движений мы используем представление движений на основе Евклидова пространства (Euclidean Motion Representation). Этот метод кодирует позу и ориентацию объекта в Евклидовом пространстве, позволяя модели прогнозировать движения, которые соответствуют физическим ограничениям и избегают неестественных или нереалистичных поз. В отличие от представления углов Эйлера, которое подвержено проблеме «гибкого замка» (gimbal lock) и может приводить к скачкам в движении, Евклидово представление обеспечивает гладкую и непрерывную интерполяцию между кадрами, что критически важно для реалистичной анимации. Применение данного подхода позволяет модели генерировать последовательности движений, которые соответствуют законам физики и воспринимаются человеком как естественные и правдоподобные.
Для обеспечения точного контроля над генерируемым поведением модели используется метод Classifier-Free Guidance (CFG). CFG позволяет управлять процессом генерации, изменяя баланс между обученным распределением данных и условным входом. В отличие от традиционных методов, требующих обучения отдельных классификаторов для управления различными аспектами поведения, CFG использует единую модель и изменяет ее выходные данные путем масштабирования и смешивания предсказаний с условным и безусловным входами. Это обеспечивает более гибкий и точный контроль над генерируемым поведением, позволяя пользователям настраивать различные параметры, такие как интенсивность действия, скорость реакции или стиль взаимодействия, без необходимости переобучения модели.
Для обеспечения синхронизации между речью и соответствующими действиями в модели используется представление речи на основе HuBERT (Hidden Unit BERT). HuBERT — это метод самообучения, который позволяет извлекать дискретные единицы речи из необработанного аудиосигнала, создавая контекстно-зависимые представления. Эти представления служат входными данными для генерации действий, обеспечивая более точное и согласованное отображение произнесенной речи в соответствующие движения и поведение модели. Использование HuBERT позволяет модели учитывать не только семантическое содержание речи, но и ее просодические характеристики, что способствует созданию более реалистичных и естественных взаимодействий.
Потоковая Взаимодействие: Включение Реального Времени Разговорной Моторики
Для обеспечения эффективного потокового вывода используется комбинация модели потокового соответствия и перемежающихся латентных токенов. Данный подход позволяет генерировать данные последовательно, по мере их поступления, избегая необходимости ожидания завершения всего процесса. Сопоставление потоков, в отличие от традиционных диффузионных моделей, обеспечивает более быструю генерацию, а перемежающиеся латентные токены оптимизируют процесс, уменьшая вычислительную нагрузку и задержку. В результате, система способна обрабатывать данные в реальном времени, что критически важно для интерактивных приложений и позволяет достичь скорости более 300 кадров в секунду. Эта технология открывает новые возможности для создания реалистичной и отзывчивой анимации и виртуальной реальности.
Разработка позволяет генерировать реалистичные движения, имитирующие разговор, в режиме реального времени, что является критически важным для интерактивных приложений. Благодаря оптимизированной архитектуре, система способна обрабатывать до 300 кадров в секунду FPS, обеспечивая плавность и отзывчивость анимации. Эта высокая скорость обработки открывает возможности для создания виртуальных ассистентов, реалистичных игровых персонажей и других приложений, требующих мгновенной реакции на действия пользователя. Возможность генерации движений в режиме реального времени существенно расширяет сферу применения подобных технологий, позволяя создавать более естественные и захватывающие взаимодействия с цифровым миром.
Разработанный подход основывается на принципах диффузионных моделей, но значительно расширяет их возможности как в плане качества генерируемых последовательностей движений, так и в отношении эффективности вычислений. Вместо традиционного процесса диффузии, требующего множества шагов, предложенная архитектура использует оптимизированные методы семплирования и потоковую обработку данных. Это позволяет не только создавать более реалистичные и плавные движения, но и существенно снизить вычислительные затраты, что критически важно для приложений, требующих генерации движений в реальном времени. Улучшения в архитектуре модели позволяют более точно моделировать сложные кинематические зависимости и динамику человеческих движений, что проявляется в более естественной позе, снижении проскальзывания стоп и повышении согласованности взгляда, что в совокупности приводит к созданию высококачественных и убедительных анимаций.
Исследование продемонстрировало впечатляющие результаты в области реалистичности генерируемого движения. Достигнутое значение Fréchet Gesture Distance, составившее 1.28, свидетельствует о высокой степени соответствия синтезированных жестов и движений реальным. Особого внимания заслуживает значительное сокращение эффекта “скольжения” ног, до уровня 0.01, что является ключевым фактором для восприятия движения как правдоподобного. Данные показатели в совокупности подтверждают способность разработанного подхода создавать не только плавные, но и визуально достоверные анимации, приближающиеся к естественным движениям человека.
Исследования показали, что разработанная система демонстрирует высокую согласованность взгляда, достигая показателя в 0.83. Этот результат указывает на способность модели генерировать движения, в которых взгляд персонажа естественно следует за ходом беседы и взаимодействием с другими участниками. Кроме того, дисперсия движений запястья составила 105.0, что сопоставимо с показателем в 137.6, наблюдаемым в реальных данных. Такое соответствие свидетельствует о реалистичности генерируемых движений рук и позволяет создать более убедительные и естественные анимации, избегая неестественной скованности или избыточной плавности, что критически важно для интерактивных приложений и виртуальной реальности.
В результате объединения разработанных методов и технологий представлена модель TalkSHOW, способная генерировать убедительные и естественные движения в режиме реального времени. Эта система демонстрирует значительный прогресс в области создания интерактивных виртуальных персонажей и аватаров, обеспечивая плавные и реалистичные реакции на речевые взаимодействия. TalkSHOW не просто воспроизводит движения, но и создает целостные поведенческие паттерны, приближенные к человеческим, что открывает новые возможности для применения в виртуальной реальности, видеоиграх и системах коммуникации. Оптимизация, достигнутая в процессе разработки, позволила создать модель, способную генерировать высококачественные движения с высокой частотой кадров, что критически важно для интерактивных приложений и погружающего опыта.
Работа представляет собой очередную попытку обуздать хаос, заключённый в движении виртуальных агентов. Авторы стремятся к созданию иллюзии разумности, заставляя этих существ реагировать на действия пользователя в реальном времени. Примечательно, что система опирается на комбинацию причинно-следственных преобразований и потокового сопоставления — словно пытаясь предсказать будущее, основываясь на обрывках прошлого. Как метко заметил Ян Лекун: «Если корреляция высокая — кто-то что-то подстроил». В данном случае, подстройка заключается в тонкой настройке алгоритмов, чтобы добиться правдоподобного взаимодействия, хотя истинная спонтанность, вероятно, остаётся недостижимой мечтой. Ведь даже самые сложные модели — всего лишь заклинания, работающие до первого столкновения с непредсказуемостью реальной жизни.
Что дальше?
Представленная работа, безусловно, добавляет ещё один слой иллюзий в мир виртуальных агентов. Способность реагировать на движения пользователя и поддерживать зрительный контакт — это шаг к более правдоподобным взаимодействиям. Однако, стоит помнить: данные — это не истина, а компромисс между багом и Excel. Каждое «естественное» движение — это всего лишь результат тщательно настроенных параметров, и первая же неожиданная ситуация в продакшене неизбежно обнажит хрупкость этой конструкции.
Будущие исследования, вероятно, будут сосредоточены на преодолении этой хрупкости. Необходимо выйти за рамки реактивного поведения и научить агентов предвидеть намерения пользователя, понимать контекст и, возможно, даже… обманывать правдоподобно. Пока же, всё, что не нормализовано, всё ещё дышит, и каждое новое улучшение — это лишь отсрочка неизбежного столкновения с хаосом реального мира.
В конечном итоге, задача состоит не в том, чтобы создать идеального виртуального человека, а в том, чтобы создать достаточно убедительную иллюзию, чтобы пользователь добровольно приостановил своё неверие. И тогда, возможно, мы сможем продавать эту иллюзию как реальность. Данные, конечно, будут шептать обратное, но кому какое дело до шепота, когда есть прибыль?
Оригинал статьи: https://arxiv.org/pdf/2602.18432.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Российский рынок в зоне турбулентности: рубль, ставки и новые риски (10.04.2026 01:32)
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Неважно, на что вы фотографируете!
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Honor X80i ОБЗОР: плавный интерфейс, большой аккумулятор, объёмный накопитель
- Realme Narzo 70 ОБЗОР: плавный интерфейс, большой аккумулятор, замедленная съёмка видео
- Proton только что запустил альтернативу Google Workspace и Microsoft 365, ориентированную на конфиденциальность.
- Как использовать режимы съёмки P, S, A, M на фотоаппарате?
- Canon EOS 80D
- IdeaPad Slim 3 15IRH10R ОБЗОР
2026-02-23 13:36