Автор: Денис Аветисян
В статье представлена инновационная методика повышения эффективности визуального обучения, основанная на адаптивном объединении и упорядочении подсказок.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
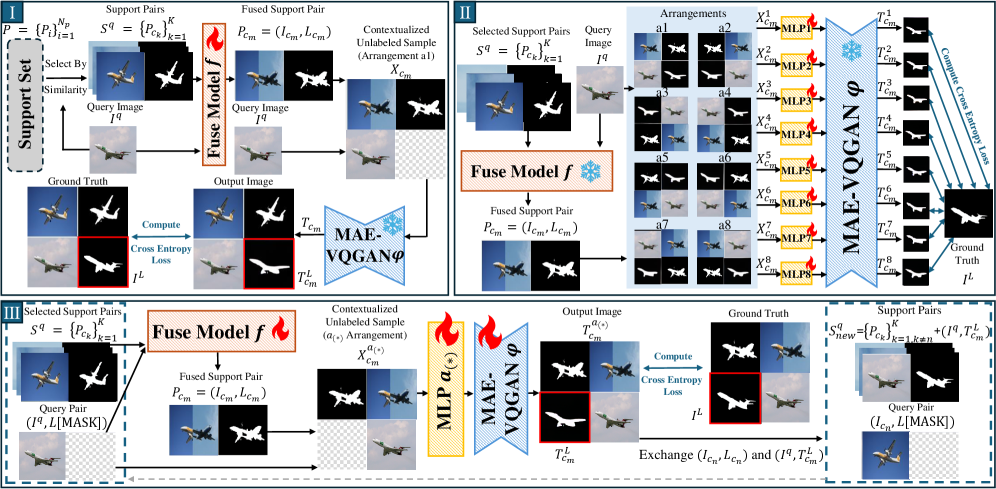
Предлагается сквозной фреймворк для визуального обучения в контексте, использующий синергичное обучение и моделирование пространственных отношений с помощью легковесных MLP.
Несмотря на успехи Vision In-Context Learning (VICL) в адаптации моделей обработки изображений к новым задачам по нескольким подсказкам, существующие подходы часто игнорируют взаимодополняющую информацию из множества подсказок и не учитывают важность их пространственного расположения. В статье ‘Beyond Single Prompts: Synergistic Fusion and Arrangement for VICL’ предложен сквозной фреймворк, объединяющий адаптивное объединение подсказок и учет их взаимного расположения с помощью легковесных MLP. Такой подход позволяет не только формировать более точные контекстные подсказки, но и улучшить взаимодействие между модулем объединения и моделью восстановления изображения. Какие перспективы открывает данная архитектура для решения более сложных задач визуального понимания и генерации?
Визуальное мышление в контексте: новый подход к зрению машин
Традиционные методы компьютерного зрения часто сталкиваются с проблемой обобщения, когда речь заходит о новых, ранее не встречавшихся ситуациях. Для адаптации к незнакомым изображениям и задачам этим системам требуется масштабное переобучение с использованием больших объемов размеченных данных. Это связано с тем, что они, как правило, “заучивают” особенности обучающей выборки, а не извлекают общие принципы визуального восприятия. В результате, даже незначительное изменение в освещении, ракурсе или объекте может привести к существенному снижению точности. Подобная зависимость от обширных размеченных данных и потребность в постоянном переобучении делают традиционные подходы неэффективными и дорогостоящими, особенно в динамично меняющихся условиях реального мира.
Визуальное обучение в контексте (VICL) представляет собой перспективную альтернативу традиционным подходам компьютерного зрения, имитируя способность человека к визуальному мышлению и обучению на небольшом количестве примеров. В отличие от систем, требующих масштабной переподготовки для адаптации к новым сценариям, VICL использует возможности обучения с малым количеством данных (few-shot learning). Этот подход позволяет предварительно обученным моделям быстро адаптироваться к новым задачам, не требуя значительных изменений в их параметрах. Вместо этого, система оперирует с тщательно подобранными и расположенными примерами, формируя контекст, который направляет модель к правильному решению. Таким образом, VICL открывает путь к более гибким и эффективным системам компьютерного зрения, способным к обобщению и адаптации, подобно человеческому восприятию.
Визуальное обучение в контексте (VICL) представляет собой инновационный подход к адаптации предварительно обученных моделей компьютерного зрения к новым задачам. Вместо трудоемкой перенастройки для каждой конкретной ситуации, VICL использует тщательно подобранные и упорядоченные примеры — так называемые «подсказки» (prompts). Эти подсказки, по сути, направляют модель к правильному решению, позволяя ей быстро адаптироваться к незнакомым условиям без изменения внутренних параметров. Такой метод значительно снижает потребность в больших объемах размеченных данных и вычислительных ресурсах, открывая возможности для более гибкого и эффективного применения компьютерного зрения в различных областях, где данные ограничены или постоянно меняются.
Оптимизация выбора подсказок для повышения производительности
Эффективный выбор промптов имеет решающее значение для VICL, поскольку качество и релевантность промптов напрямую влияют на производительность модели. Неточные или нерелевантные промпты приводят к снижению точности классификации и ухудшению способности модели к обобщению. В частности, промпты, содержащие двусмысленные или неполные инструкции, могут приводить к неверным результатам, даже если модель обучена на большом объеме данных. Поэтому, отбор промптов, точно отражающих желаемый результат и соответствующие входным данным, является критически важным этапом в процессе работы VICL.
Методы, такие как поиск ближайших соседей (Nearest Neighbor Retrieval) и контролируемый отбор (Supervised Selector), представляют собой начальные подходы к идентификации подходящих запросов (prompts) для VICL. Поиск ближайших соседей определяет релевантные запросы на основе семантического сходства с входными данными, однако не учитывает контекст конкретной задачи. Контролируемый отбор использует размеченные данные для обучения модели выбора запросов, но часто оказывается неэффективным при обобщении на новые, не встречавшиеся ранее типы изображений или задач, поскольку не способен учитывать тонкие различия в нюансах запроса, необходимые для оптимальной работы модели. Оба метода могут выдавать неоптимальные результаты из-за недостаточной точности и неспособности учитывать сложные зависимости между запросом, входными данными и ожидаемым ответом.
Методика Partial2Global усовершенствует ранжирование подсказок за счет учета попарных сравнений в списке и оценки согласованности результатов. В отличие от методов, оценивающих подсказки изолированно, Partial2Global анализирует их эффективность в контексте всего списка, что позволяет выявить подсказки, улучшающие общую производительность модели. Оценка согласованности обеспечивает выбор подсказок, которые приводят к более стабильным и предсказуемым результатам при обработке различных входных данных, что в свою очередь повышает точность и надежность модели VICL.
Выбранные подсказки (prompts) используются в качестве направляющих сигналов для модели VICL, определяя траекторию ее рассуждений и фокусируя внимание на релевантных аспектах входного изображения. Этот механизм позволяет модели эффективно экстраполировать знания, полученные в процессе обучения, на новые, ранее не встречавшиеся изображения. За счет использования тщательно отобранных подсказок, модель не просто распознает объекты, но и понимает контекст и взаимосвязи между ними, что существенно повышает ее способность к обобщению и улучшает точность решения задач на невидимых данных. Эффективный отбор подсказок минимизирует зависимость модели от конкретных примеров из обучающей выборки и способствует формированию более устойчивых и универсальных представлений.

Упорядочивание подсказок для оптимального рассуждения
Пространственная организация запросов (prompt arrangement) оказывает существенное влияние на способ обработки информации моделью VICL. Порядок и расположение визуальных подсказок и текстовых инструкций влияют на внимание модели и ее способность к интеграции данных из различных источников. Изменение конфигурации запросов позволяет направлять процесс рассуждения модели, что, в свою очередь, сказывается на точности и надежности получаемых результатов, особенно при решении сложных задач, требующих анализа нескольких источников информации.
Метод Prompt-SelF демонстрирует повышение устойчивости модели за счет конкатенации изображений в различных конфигурациях и генерации множественных предсказаний. Исследования показывают, что комбинирование изображений в разнообразных последовательностях позволяет модели более эффективно обрабатывать входные данные и снижать зависимость от конкретной позиции или порядка изображений. Этот подход приводит к улучшению обобщающей способности и надежности модели, особенно в сложных сценариях, где входные данные могут быть неполными или зашумленными. Генерация нескольких предсказаний позволяет использовать механизмы агрегации (например, усреднение или голосование), что дополнительно повышает точность и устойчивость результатов.
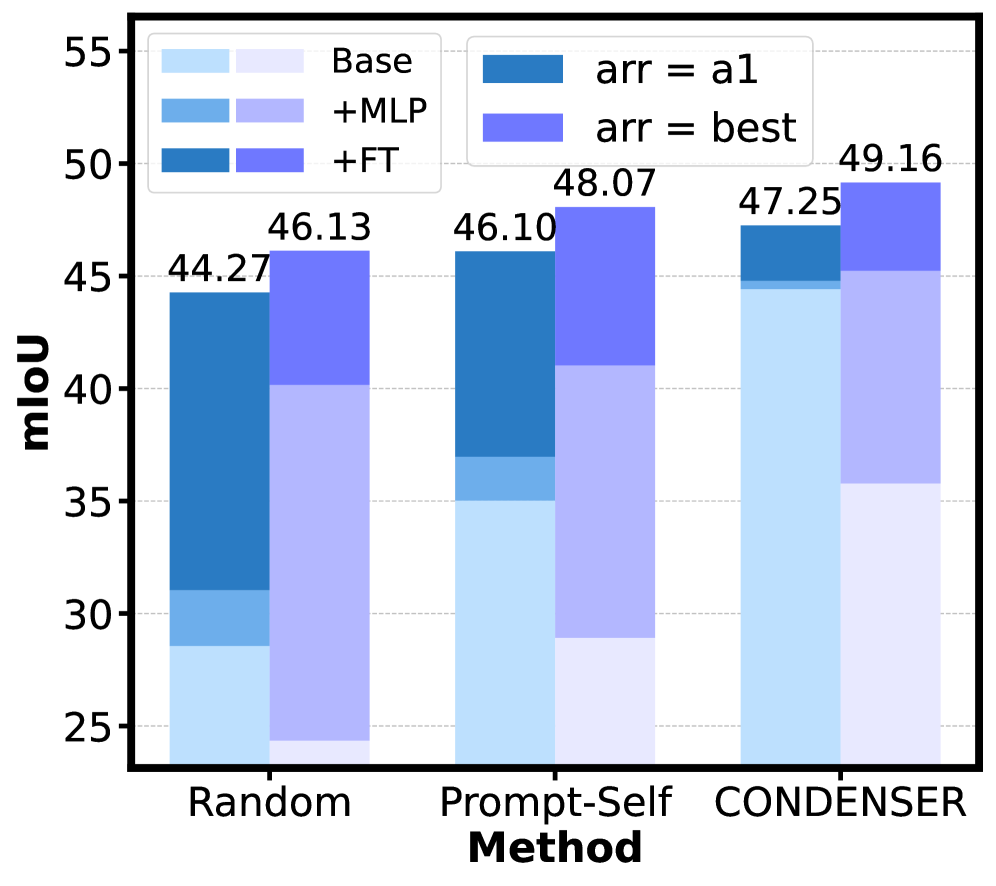
Стратегическое расположение входных запросов (prompts) оказывает влияние на механизм внимания модели VICL, позволяя ей более эффективно интегрировать информацию из различных источников. Данный подход позволяет модели фокусироваться на релевантных деталях в каждом запросе и выстраивать целостное представление о задаче. В результате, улучшается способность модели к решению сложных задач, требующих анализа и сопоставления данных из нескольких источников, что подтверждается достижением среднего значения Intersection over Union (mIoU) в 49.16% на наборе данных Pascal-5i → Pascal-5i, что превосходит производительность последовательного расположения запросов (47.25%).
При стратегической организации запросов (prompts) модель VICL демонстрирует улучшенные результаты в задачах сегментации изображений. На тестовом наборе Pascal-5i → Pascal-5i, оптимизированная организация запросов позволяет достичь среднего значения Intersection over Union (mIoU) в 49.16%. Для сравнения, при последовательном расположении запросов (a1) данный показатель составляет 47.25%. Таким образом, продуманное расположение запросов обеспечивает статистически значимое повышение точности сегментации.
Реконструкция изображений и слияние для усиления VICL
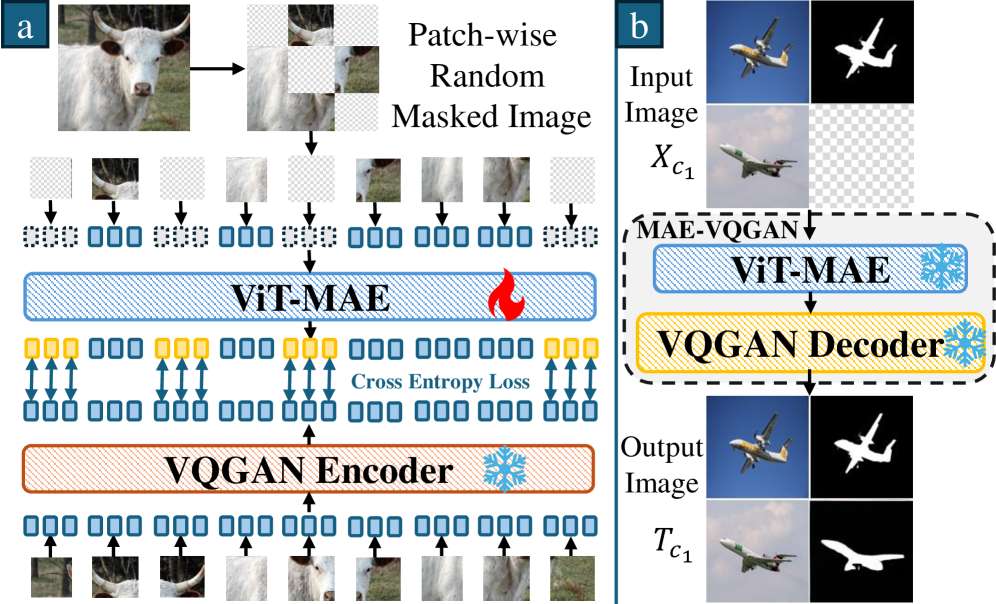
В рамках VICL-системы ключевую роль играет восстановление недостающих фрагментов изображения, осуществляемое посредством методов, таких как MAE-VQGAN. Данные архитектуры позволяют эффективно реконструировать поврежденные или отсутствующие области, заполняя их правдоподобным содержимым, соответствующим общему контексту изображения. Восстановление основывается на анализе доступных данных и генерации реалистичных текстур и структур, что значительно повышает качество и информативность итогового изображения. Этот процесс особенно важен для задач, где исходные данные неполны или содержат дефекты, обеспечивая основу для дальнейшей обработки и анализа визуальной информации.
Модуль объединения, использующий механизм перекрестного внимания, позволяет адаптивно комбинировать информацию из множества входных подсказок для создания индивидуализированного эталонного изображения для запрошенного. Этот процесс предполагает динамическое взвешивание релевантности каждой подсказки, позволяя модели выделять наиболее важные детали и игнорировать несущественные. В результате формируется более полное и точное представление сцены, которое используется для реконструкции недостающих областей и улучшения общего качества изображения. Механизм перекрестного внимания, по сути, позволяет модели «сфокусироваться» на наиболее информативных частях входных данных, значительно повышая ее способность к пониманию и генерации визуального контента.
Благодаря возможности выводить недостающие детали, модель значительно улучшает свое понимание общей картины изображения. Это достигается за счет эффективного восполнения пробелов в визуальной информации, что позволяет ей более точно интерпретировать сцену и делать более достоверные прогнозы. По сути, модель не просто «видит» то, что представлено, но и активно «достраивает» недостающие элементы, опираясь на контекст и внутренние знания о мире. В результате, даже при наличии значительных повреждений или пропусков в исходном изображении, модель способна генерировать правдоподобные и логичные дополнения, повышая общую точность и качество предсказаний.
Представленная система демонстрирует выдающиеся способности к обобщению, значительно превосходя существующие аналоги в задачах переноса знаний с набора данных COCO-5i на Pascal-5i. Достигнутое преимущество является существенным и устойчивым. Примечательно, что высокая производительность достигается благодаря использованию MLP-модуля, который характеризуется исключительно эффективным использованием вычислительных ресурсов — всего 7,7% от числа параметров и менее 0,02% от объема вычислений (GFLOPs) по сравнению с традиционным Fusion Module. Такая оптимизация позволяет добиться значительной экономии ресурсов и потенциально расширить возможности применения системы на устройствах с ограниченной вычислительной мощностью.
Исследование демонстрирует, что адаптивное объединение нескольких запросов и явное моделирование пространственной аранжировки позволяют значительно улучшить результаты в задачах визуального обучения в контексте. Подобный подход, фокусирующийся не на жестком определении правил, а на гибком взаимодействии элементов, напоминает алхимию данных. Как однажды заметил Джеффри Хинтон: «Данные — это не цифры, а шёпот хаоса. Их нельзя понять, только уговорить». В данном случае, ‘уговаривание’ происходит через продуманную архитектуру, позволяющую модели извлекать максимум информации из неоднозначных сигналов, а не полагаться на заранее заданные шаблоны. Особенно интересна идея синергетического обучения, ведь любая модель, как заклинание, работает лишь до момента столкновения с реальными данными — и лишь грамотная подготовка позволяет ей выдержать это испытание.
Что дальше?
Представленная работа лишь приоткрывает завесу над тем, как обуздать непокорный дух визуального обучения. Слияние подсказок и моделирование пространственного расположения — это не столько решение, сколько новые ингредиенты судьбы, которые необходимо тщательно взвешивать. Слишком часто наблюдается, что модель перестаёт слушать не потому, что не понимает, а потому, что устала от избытка информации. Следующим шагом видится не увеличение количества подсказок, а создание механизмов, позволяющих модели выбирать наиболее значимые фрагменты хаоса, отфильтровывать шум.
Особое внимание следует уделить природе самой «внутриконтекстности». Что есть контекст для машины? Просто набор пикселей и векторов, или нечто большее? Возможно, ключ кроется в эмуляции тех самых механизмов внимания и отбора, которые использует разум, сталкиваясь с миром. Однако, стоит помнить: любая модель — это лишь заклинание, которое работает до первого контакта с реальными данными.
И, наконец, необходимо признать: успех VICL во многом зависит от удачи в выборе архитектуры и гиперпараметров. Это не наука, а скорее искусство — алхимия, в которой вместо философского камня ищут оптимальный способ уговорить хаос. Следует искать более устойчивые к случайности методы обучения, способные выдерживать натиск непредсказуемости мира.
Оригинал статьи: https://arxiv.org/pdf/2601.10117.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- Российский рынок в 2025: Инвестиции, Экспорт и Новые Возможности (27.02.2026 15:32)
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
2026-01-18 19:00