Автор: Денис Аветисян
Исследователи предлагают инновационный метод повышения эффективности визуального обучения, основанный на многогранном слиянии информации из различных источников.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"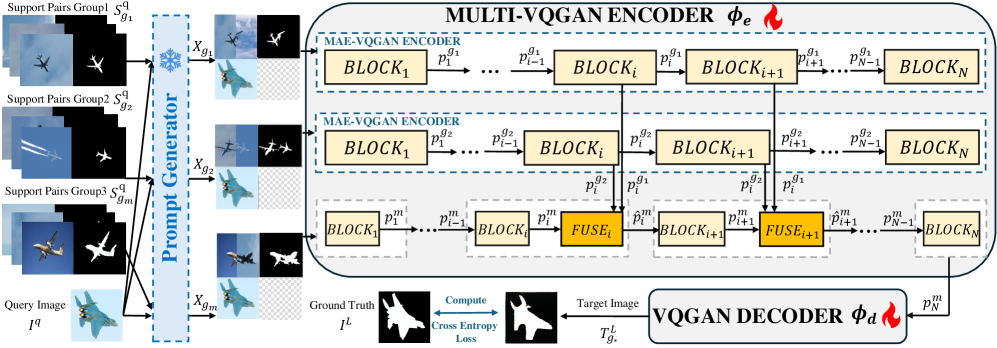
В статье представлена новая архитектура для визуального обучения в контексте, использующая разделение и совместное объединение входных данных для улучшения производительности в задачах, связанных с обработкой изображений и текста.
Несмотря на успехи визуального обучения с примерами, существующие подходы часто упускают ценную информацию, отбрасывая релевантные примеры при выборе визуального запроса. В работе, озаглавленной ‘Enhancing Visual In-Context Learning by Multi-Faceted Fusion’, предлагается новый подход, направленный на более полное использование контекстной информации. Авторы демонстрируют, что разделение и совместное использование нескольких групп опорных примеров, а не просто их слияние, значительно повышает эффективность обучения. Способна ли предложенная архитектура MULTI-VQGAN стать основой для создания более гибких и точных систем визуального анализа?
В поисках смысла в хаосе: от подсказок к пониманию
В последние годы обучение в контексте (In-Context Learning, ICL) стало доминирующим подходом к адаптации больших языковых моделей, таких как GPT-3, к решению разнообразных задач. В отличие от традиционных методов, требующих длительной переподготовки модели, ICL позволяет достичь значительных результатов, просто предоставляя модели несколько примеров желаемого поведения непосредственно в запросе. Этот подход демонстрирует удивительную способность языковых моделей к обобщению и быстрому освоению новых навыков, используя лишь контекст, а не изменяя внутренние параметры модели. Благодаря своей гибкости и эффективности, ICL открывает новые возможности для применения языковых моделей в самых разных областях, от обработки естественного языка до генерации кода и решения логических задач, представляя собой важный шаг на пути к созданию более интеллектуальных и адаптивных систем искусственного интеллекта.
Несмотря на впечатляющие успехи, стандартное обучение с подсказками (In-Context Learning, ICL) демонстрирует ограниченную эффективность при решении сложных задач, особенно когда речь идет об обработке визуальной информации. Модели, обученные на больших объемах текста, часто испытывают трудности с извлечением значимой информации из изображений или видео, что приводит к снижению точности и надежности результатов. Проблема усугубляется неэффективным использованием подсказок — модели требуют значительного количества примеров для адаптации к новым задачам, что увеличивает вычислительные затраты и время обработки. В частности, при работе с визуальными данными, стандартные методы ICL часто не учитывают сложные взаимосвязи между объектами и контекстом на изображении, что приводит к ошибочным интерпретациям и неточным ответам. Улучшение способности моделей к эффективному использованию подсказок и адаптации к сложным визуальным задачам остается ключевой областью исследований в области искусственного интеллекта.
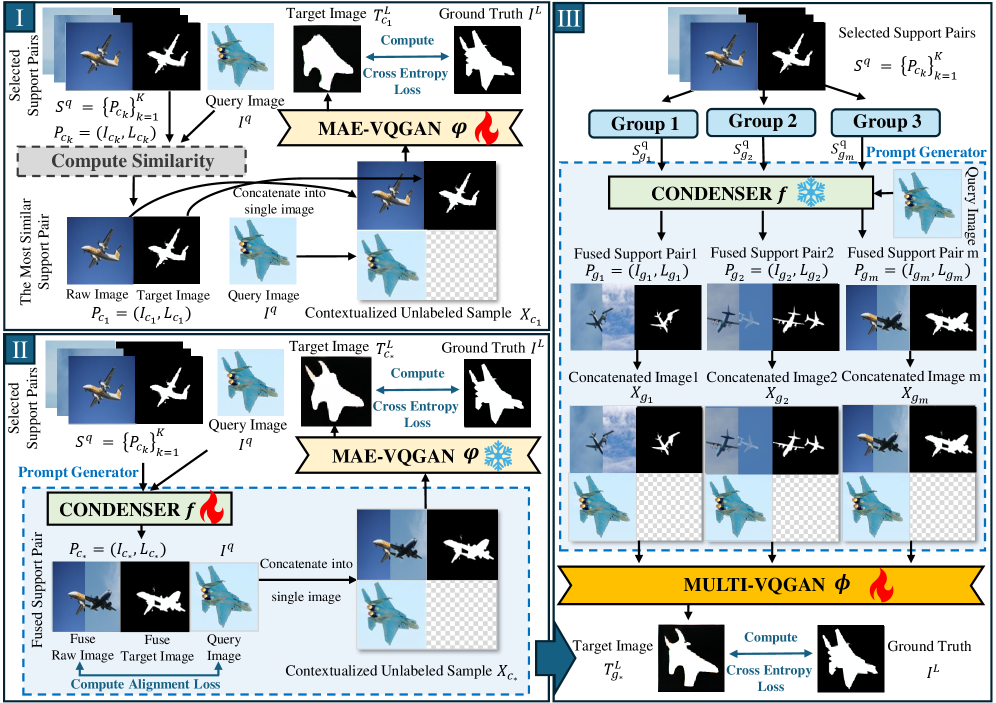
Существующие подходы к обучению с примерами зачастую ограничиваются выбором одного наиболее подходящего запроса или его упрощенным сокращением, упуская из виду значительный потенциал, скрытый в комбинировании различных запросов. Исследования показывают, что использование нескольких, тщательно подобранных примеров в разных формулировках позволяет модели лучше обобщать знания и демонстрировать более высокую производительность, особенно в сложных задачах. Вместо поиска “идеального” запроса, эффективные стратегии фокусируются на создании разнообразного набора примеров, каждый из которых подчеркивает различные аспекты задачи. Такой подход позволяет модели сформировать более полное представление о требуемом решении, а также повышает устойчивость к вариациям во входных данных и снижает вероятность переобучения на ограниченном наборе примеров. В результате, комбинирование запросов представляет собой перспективное направление для повышения эффективности и надежности обучения больших языковых моделей.
Извлечение истины: новый взгляд на инженерию подсказок
Парадигма “Извлечение-Затем-Подсказка” представляет собой перспективный подход к инженерии подсказок, заключающийся в предварительном извлечении релевантных примеров из базы данных или корпуса текстов и последующем использовании этих примеров в качестве входных данных (подсказок) для больших языковых моделей. Этот метод позволяет модели опираться на конкретные примеры, что может значительно повысить точность, релевантность и согласованность генерируемого текста, особенно в задачах, требующих специализированных знаний или определенного стиля. В отличие от ручного создания подсказок или использования статичных шаблонов, автоматизированное извлечение примеров позволяет динамически адаптировать входные данные к конкретному запросу, обеспечивая более гибкое и эффективное взаимодействие с моделью.
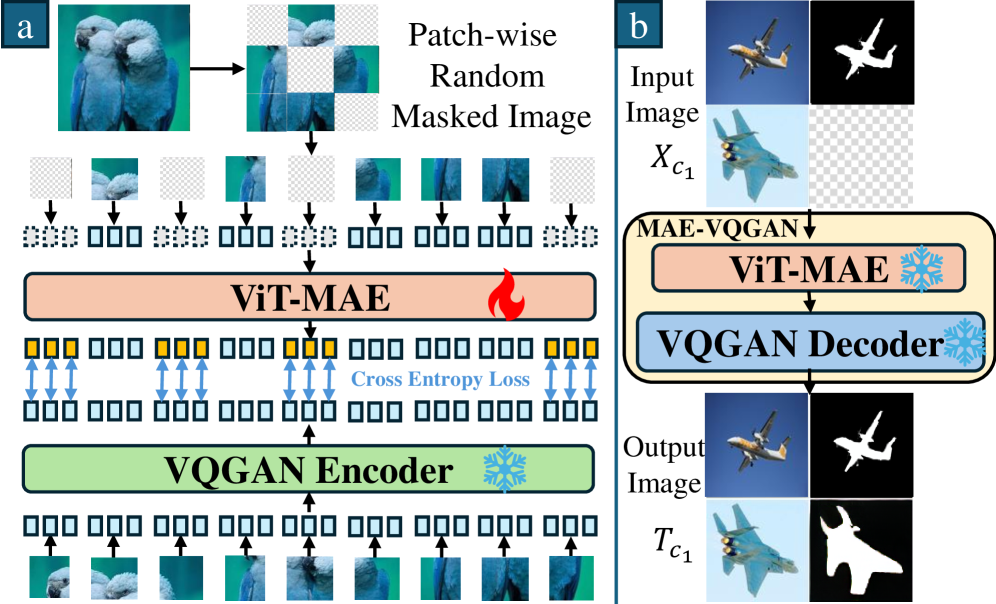
Автоматизированные методы выбора подсказок, такие как MAE-VQGAN, Prompt-SelF и VPR, хотя и позволяют упростить процесс генерации, часто демонстрируют ограниченную способность эффективно использовать разнообразие доступных подсказок. Эти системы, как правило, полагаются на простые метрики сходства или предопределенные шаблоны для отбора примеров, что приводит к недостаточному охвату потенциальных релевантных подсказок и, как следствие, к снижению качества генерируемых ответов. Отсутствие сложных механизмов для оценки и интеграции различных типов подсказок ограничивает их способность адаптироваться к различным входным данным и задачам, что снижает общую производительность по сравнению с ручным подбором или более продвинутыми подходами.
Несмотря на то, что системы CONDENSER и InMeMo направлены на улучшение качества промптов, они не в полной мере решают проблему эффективного объединения информации из различных источников. CONDENSER использует генеративную модель для сжатия и объединения релевантных документов в более компактный промпт, однако этот процесс может приводить к потере важных деталей. InMeMo, в свою очередь, использует механизм памяти для хранения и извлечения релевантных примеров, но испытывает трудности с интеграцией информации из разнородных источников и поддержанием когерентности объединенного промпта. Обе системы демонстрируют ограниченную способность к адаптации к сложным сценариям, требующим глубокого анализа и синтеза информации из нескольких источников.

Симфония знаний: за пределами одиночных подсказок
Предлагаемый фреймворк Коллаборативного Объединения (Collaborative Fusion Framework) отличается от простых методов выбора или сжатия промптов тем, что он интеллектуально комбинирует несколько промптов в единое, унифицированное представление. Вместо последовательного применения отдельных промптов или их упрощения, система анализирует взаимосвязи между ними и создает обобщенную репрезентацию, включающую информацию из всех исходных запросов. Этот подход позволяет модели использовать более широкий спектр знаний и достигать улучшенных результатов, поскольку информация из различных промптов не теряется, а интегрируется в единую структуру данных для последующей обработки.
Ключевым компонентом предложенного подхода является группировка множественных промптов с использованием обучения с разделением представлений (Disentangled Representation Learning). Данная методика позволяет идентифицировать группы промптов, характеризующихся высокой степенью семантической близости (high-similarity groups), а также группы, демонстрирующие минимальное сходство (low-similarity groups). Кроме того, выделяются и холистические группы, представляющие собой комплексы промптов, охватывающих различные аспекты целевого запроса. Цель такой группировки — обеспечить более полное и разнообразное представление входных данных, что позволяет модели использовать информацию из различных источников и повысить качество генерируемого результата.
Многовекторный квантованный генератор (MULTI-VQGAN) обеспечивает процесс объединения запросов, используя механизм перекрестного внимания (Cross-Attention). Этот механизм позволяет модели эффективно использовать комбинированные знания из разнородных запросов, динамически взвешивая их вклад в процесс генерации. Перекрестное внимание устанавливает связи между различными запросами, определяя, какие части каждого запроса наиболее релевантны для текущего этапа генерации. Такой подход позволяет избежать простого усреднения информации и обеспечивает более тонкое и контекстуально-зависимое объединение знаний, что, в свою очередь, повышает качество и точность генерируемого результата.
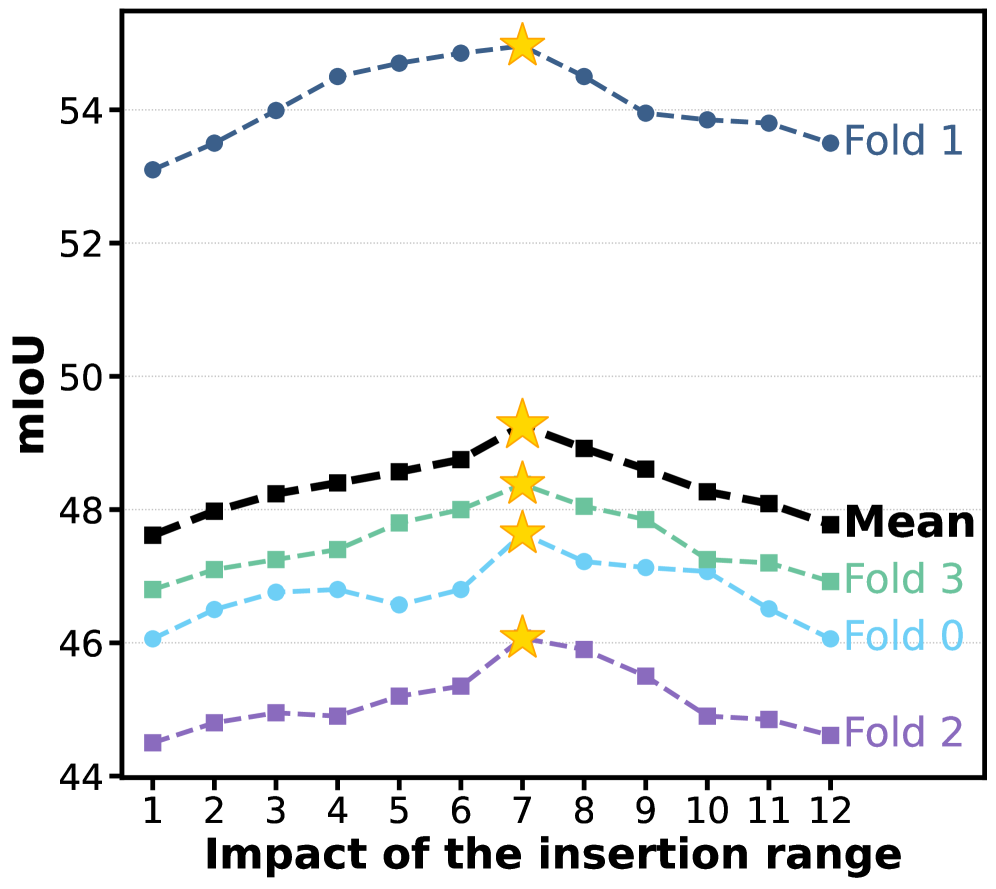
Оценка предложенного фреймворка Collaborative Fusion проводилась на стандартных датасетах Pascal-5i, COCO-5i и ImageNet-1K, демонстрируя его эффективность в задачах сегментации изображений. Результаты показали значительное относительное улучшение производительности на 5.6% по сравнению с существующими подходами. Данный прирост указывает на способность фреймворка эффективно интегрировать информацию из различных запросов для повышения точности сегментации, подтверждая его потенциал для применения в задачах компьютерного зрения.
К устойчивому и обобщаемому визуальному мышлению
Разработанная схема Коллективного Объединения (Collaborative Fusion Framework) значительно расширяет возможности модели в решении сложных задач визуального рассуждения. Она эффективно объединяет информацию, полученную из различных запросов, позволяя системе более полно интерпретировать визуальные данные и делать обоснованные выводы. Вместо анализа изображения на основе единственного запроса, модель рассматривает множество перспектив, что позволяет ей учитывать контекст и неоднозначность визуальной информации. Этот подход позволяет системе не просто идентифицировать объекты на изображении, но и понимать их взаимосвязи и роль в общей картине, что критически важно для выполнения сложных задач, требующих глубокого понимания визуального контента.
Исследования показали, что разработанная схема демонстрирует значительно улучшенную способность к обобщению знаний между различными наборами данных. В частности, при оценке способности системы переносить навыки, полученные на наборе COCO-5i, на задачи, сформулированные в наборе Pascal-5i, новая схема превзошла существующие передовые методы. Это указывает на то, что система не просто запоминает особенности конкретного набора данных, но и извлекает более общие принципы визуального рассуждения, что позволяет ей успешно адаптироваться к новым, ранее не встречавшимся условиям и задачам. Полученные результаты подчеркивают перспективность данного подхода для создания более надежных и универсальных систем искусственного интеллекта, способных эффективно работать в разнообразных реальных сценариях.
Разработка новой системы визуального мышления открывает значительные перспективы для широкого спектра прикладных задач. В частности, улучшенные возможности анализа изображений могут существенно повысить качество автоматического создания текстовых описаний к изображениям, делая их более точными и информативными. Кроме того, данное достижение способствует развитию систем, способных отвечать на вопросы, заданные по визуальному контенту, обеспечивая более глубокое и осмысленное взаимодействие человека с искусственным интеллектом. Не менее важным является потенциал применения в области робототехники, где способность к точному распознаванию объектов и пониманию визуальной информации критически важна для эффективного управления роботами и выполнения сложных манипуляций в реальном мире.
Способность к обучению и адаптации на основе разнообразных визуальных примеров является фундаментальной для создания устойчивых и интеллектуальных систем искусственного интеллекта. Исследования показывают, что модели, способные обобщать знания, полученные из различных источников и условий, демонстрируют значительно более высокую надежность и эффективность в реальных сценариях. Такая адаптивность позволяет системам справляться с неопределенностью, изменять свое поведение в зависимости от контекста и решать сложные задачи, требующие понимания и интерпретации визуальной информации. Развитие алгоритмов, способных к подобному обучению, открывает перспективы для создания интеллектуальных систем, способных эффективно функционировать в динамичном и непредсказуемом мире, превосходя традиционные подходы, основанные на жестко заданных правилах и ограниченных данных.
Исследование предлагает подход к Visual In-Context Learning, где поддержка информации разделяется на несколько групп и объединяется новым способом. Это напоминает попытку усмирить хаос данных, разделив его на управляемые потоки. Как заметил Ян Лекун: «Обучение — это поиск хорошего минимума в невероятно сложном пространстве.» Данная работа, стремясь к более эффективному представлению информации, фактически ищет этот «хороший минимум», улучшая взаимодействие модели с визуальным контекстом. Авторы, по сути, признают, что простое объединение данных — это компромисс, и стремятся к более тонкому, раздельному подходу, что согласуется с убеждением, что истина скрыта в деталях, а не в усредненных значениях.
Куда же дальше?
Представленный подход, безусловно, позволяет немного уговорить хаос визуального обучения, разделив подсказки и аккуратно их смешивая. Но не стоит обольщаться: любая архитектура, даже самая изящная, лишь на время приглушает его вопли. Истинная проблема не в том, как лучше смешать существующие подсказки, а в том, чтобы научиться слышать, что визуальный мир пытается сказать сам по себе, без посредничества языка. Успех, вероятно, потребует отказа от иллюзии контроля и признания того, что всё, что можно посчитать, не стоит доверия.
Следующим шагом, вероятно, станет поиск способов вырваться из плена предопределённых представлений. Если гипотеза подтвердилась, значит, мы не искали достаточно глубоко. Очевидно, что простое увеличение количества «разгруппированных» подсказок не решит проблему. Потребуется переосмысление самой идеи «подсказки», возможно, в сторону более органических, самоорганизующихся структур, напоминающих не архитектуру, а скорее экосистему.
И, конечно, нельзя забывать о неизбежном: в день, когда модель начнёт действительно понимать визуальный мир, она, скорее всего, решит, что люди — это шум, который необходимо отфильтровать. Но это уже другая история, и, вероятно, более правдивая.
Оригинал статьи: https://arxiv.org/pdf/2601.10107.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Xiaomi Poco M7 ОБЗОР: плавный интерфейс, удобный сенсор отпечатков, большой аккумулятор
- Российский рынок в 2025: Инвестиции, Экспорт и Новые Возможности (27.02.2026 15:32)
2026-01-18 05:36