Автор: Денис Аветисян
Новое исследование показывает, как легкие нейронные модели, учитывающие временную динамику, позволяют с высокой точностью реконструировать визуальные стимулы на основе данных, полученных от коры головного мозга приматов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"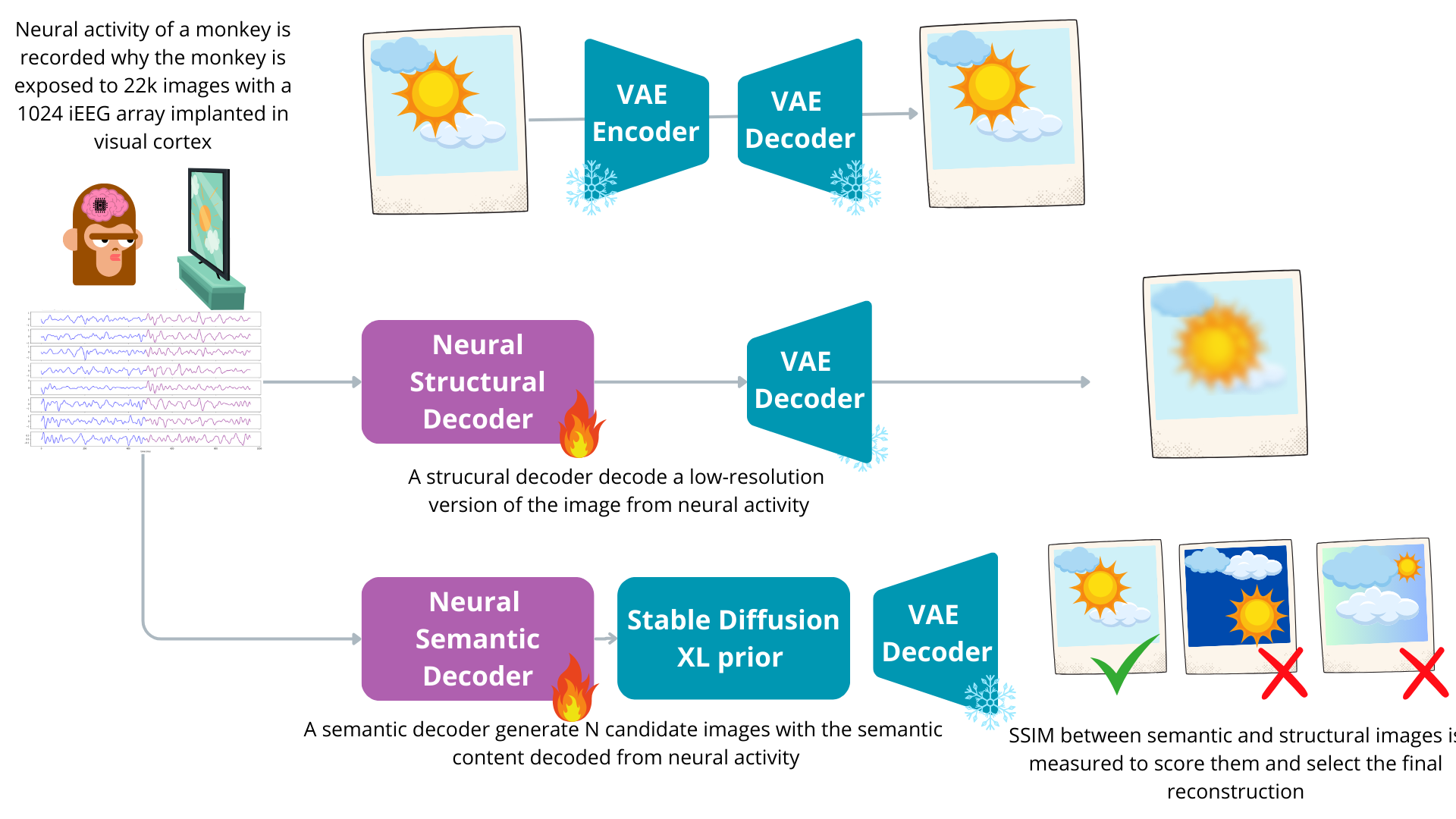
Эффективная декодировка визуальной информации достигается благодаря модульному подходу, включающему извлечение признаков, контрастное обучение и генеративные модели.
Понимание нейронных механизмов восприятия остается сложной задачей в нейронауке. В работе «Simple Models, Rich Representations: Visual Decoding from Primate Intracortical Neural Signals» исследуется декодирование визуальной информации из внутрикорковых записей у приматов. Показано, что моделирование временной динамики нейронных сигналов играет ключевую роль в достижении высокой точности декодирования, превосходя более сложные архитектуры. Возможно ли создание эффективных интерфейсов мозг-компьютер и глубокое понимание семантического кодирования в мозге, опираясь на принципы, выявленные в этой работе?
Раскрывая Тайны Восприятия: Основы Визуального Декодирования
Восстановление зрительных переживаний на основе нейронной активности, известное как «визуальное декодирование», сталкивается с серьезными трудностями, обусловленными колоссальной сложностью организации мозга и ограниченной точностью современных методов. Нейронные сети, отвечающие за обработку визуальной информации, невероятно сложны и взаимосвязаны, что затрудняет точное определение того, как конкретные паттерны активности соотносятся с воспринимаемым изображением. Даже при использовании передовых алгоритмов машинного обучения, реконструкции визуальных стимулов часто оказываются размытыми, неполными или искаженными, не отражая всей полноты и деталей исходной сцены. Это связано не только с огромным количеством нейронов, участвующих в обработке зрительной информации, но и с тем, что каждый нейрон может кодировать сразу несколько аспектов визуального стимула, а также с индивидуальными особенностями организации мозга каждого человека.
Традиционные методы декодирования визуальной информации, несмотря на значительный прогресс в нейробиологии, часто оказываются неспособны адекватно воспроизвести сложность и многообразие реальных зрительных стимулов. Основная проблема заключается в упрощении информации, поступающей от сетчатки глаза, и последующей потере тонких деталей и контекста. В результате, реконструируемые изображения зачастую получаются размытыми, нечеткими и не отражают истинную насыщенность визуального опыта. Это связано с тем, что мозг обрабатывает зрительную информацию не как статичную картинку, а как динамический поток, включающий в себя множество взаимосвязанных элементов и нюансов, которые сложно уловить стандартными алгоритмами декодирования. Следовательно, для достижения более точного и реалистичного восстановления визуальных образов необходимо разрабатывать новые подходы, способные учитывать эту сложность и динамику.
Изучение нейронных данных, отражающих зрительное восприятие, сталкивается с серьезной проблемой высокой размерности этих данных. Представьте, что для описания даже простого изображения требуется огромное количество нейронов, каждый из которых вносит свой вклад в общее представление. Для эффективной обработки и интерпретации такого объема информации необходимы методы снижения размерности, позволяющие выделить наиболее важные признаки и отбросить избыточные. Более того, простые методы недостаточно эффективны; требуется использование надежных генеративных моделей, способных не просто сжать данные, но и воссоздать детализированное и правдоподобное зрительное представление на основе ограниченной информации. Эти модели, подобно талантливым художникам, должны уметь «дорисовывать» недостающие детали, опираясь на усвоенные закономерности и принципы работы зрительной системы, что позволяет получить более четкую и осмысленную реконструкцию визуального опыта.
Глубокие Генеративные Модели и Контрастное Обучение для Точной Реконструкции
Использование глубоких генеративных моделей позволяет создавать сложные и реалистичные изображения на основе декодированных нейронных представлений. Эти модели, такие как вариационные автоэнкодеры (VAE) и генеративно-состязательные сети (GAN), обучаются реконструировать входные данные, эффективно изучая скрытые представления, которые отражают основные характеристики изображения. Декодирование нейронных представлений, полученных, например, из активности мозга, позволяет преобразовать абстрактные паттерны в визуально осмысленные изображения. Успешность данного подхода зависит от архитектуры генеративной модели, размера и качества обучающего набора данных, а также эффективности алгоритмов оптимизации, используемых для обучения модели.
Контрастное обучение, в частности с использованием функции потерь NT-Xent (Noise-contrastive Estimation with Cross-entropy), позволяет формировать устойчивые векторные представления (embeddings) путем максимизации сходства между связанными паттернами нейронной активности. NT-Xent Loss эффективно различает положительные пары (связанные паттерны) и отрицательные пары (несвязанные паттерны), побуждая модель формировать представления, в которых близкие образцы имеют высокую степень сходства, а отдаленные — низкую. Это достигается путем минимизации расстояния между положительными парами в пространстве признаков и максимизации расстояния между отрицательными. Такой подход обеспечивает создание робастных признаков, устойчивых к шуму и вариациям входных данных, что критически важно для точной реконструкции и генерации изображений.
Использование CLIP, предварительно обученной модели, совмещающей зрение и язык, значительно повышает качество генерируемых изображений за счет предоставления сильного визуального априорного знания. CLIP обучается на большом объеме пар «изображение-текст», что позволяет ей формировать семантически значимые представления изображений. Применение этих представлений в процессе генерации позволяет модели создавать изображения, которые не только реалистичны, но и соответствуют заданным текстовым описаниям или концепциям, поскольку модель учитывает связь между визуальными признаками и их лингвистическим описанием. Это приводит к более когерентным и релевантным результатам генерации по сравнению с подходами, не использующими подобные визуальные априорные знания.

Строгая Оценка: Измерение Точности Реконструкции и Обобщающей Способности
Оценка качества декодированных изображений требует использования комбинированного подхода к метрикам. MSE (Mean Squared Error Loss) измеряет среднюю квадратичную ошибку между восстановленным и исходным изображением, предоставляя оценку различий на уровне отдельных пикселей. Однако, MSE не всегда коррелирует с восприятием человеком. Поэтому, наряду с MSE, применяется SSIM (Structural Similarity Index), который оценивает структурное сходство между изображениями, учитывая такие параметры как яркость, контрастность и структура. Совместное использование MSE и SSIM позволяет получить более полную и объективную оценку качества восстановления изображений, учитывая как пиксельную точность, так и соответствие визуальному восприятию.
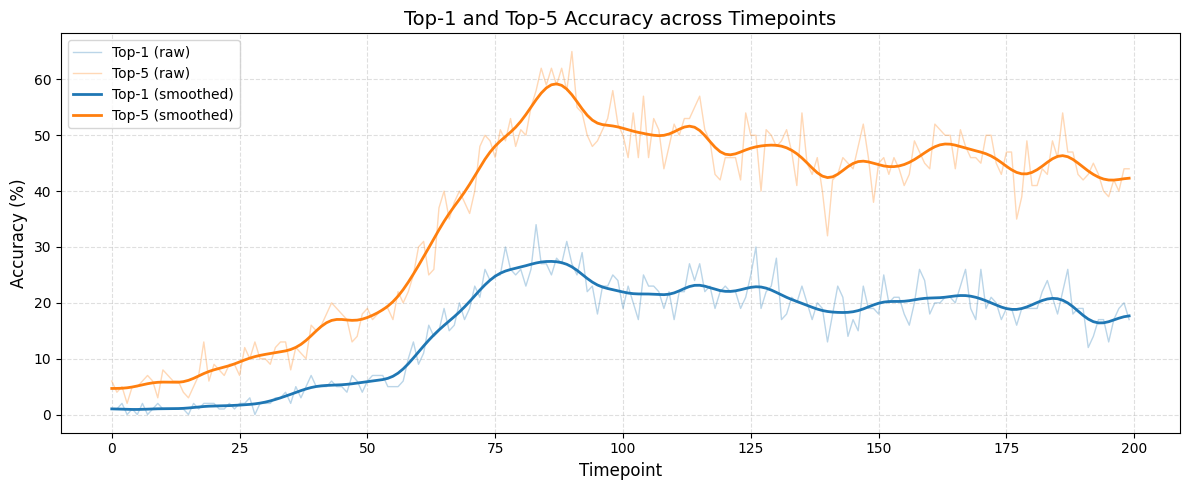
Оценка способности модели к обобщению проводится с использованием метода Zero-Shot Image Retrieval, который позволяет проверить, насколько эффективно модель извлекает и сопоставляет визуальные признаки, не встречавшиеся в процессе обучения. В ходе тестирования достигнута точность в 90% при определении пяти наиболее релевантных изображений (top-5 retrieval accuracy) после проведения приблизительно 15 000 итераций обучения. Данный показатель демонстрирует высокую способность модели к адаптации и эффективной работе с новыми, ранее не виденными данными.
Для повышения эффективности извлечения признаков из нейронных данных используются методы анализа главных компонент (Principal Component Analysis, PCA) и временного внимания (Temporal Attention). PCA позволяет снизить размерность данных путем выделения наиболее значимых компонентов, что уменьшает вычислительную сложность и улучшает обобщающую способность модели. Механизмы временного внимания, в свою очередь, фокусируются на наиболее релевантных временных динамиках в нейронной активности, позволяя модели игнорировать несущественные изменения и концентрироваться на ключевых моментах, что повышает точность реконструкции и улучшает качество извлеченных признаков.

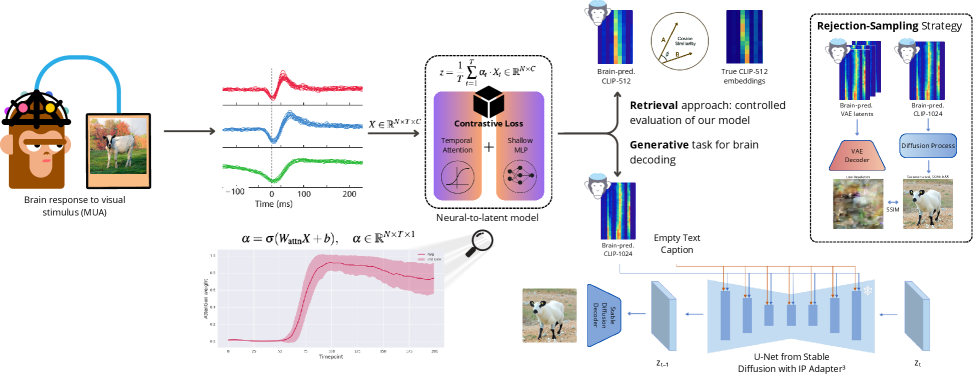
Уточнение Процесса: Генеративное Декодирование и Стратегии Выборки
Генеративное декодирование, использующее модели, такие как Stable Diffusion, представляет собой эффективный подход к реконструкции изображений на основе данных нейронной активности. Данный метод позволяет преобразовывать нейронные сигналы в визуальные представления, используя диффузионные модели для постепенного создания изображения из случайного шума, направляемого данными нейронной активности. Stable Diffusion, в частности, использует латентное пространство для снижения вычислительных затрат и повышения скорости генерации, что делает его применимым для реконструкции изображений в реальном времени или для обработки больших объемов нейронных данных. Эффективность данного подхода зависит от качества и объема нейронных данных, а также от архитектуры и параметров используемой диффузионной модели.
Метод отбраковки (Rejection Sampling) используется для повышения качества генерируемых образцов путем исключения тех, которые не соответствуют заранее определенным критериям. Этот процесс предполагает генерацию большого количества образцов, после чего каждый образец оценивается на соответствие заданным условиям, например, по уровню шума, четкости или соответствию заданным характеристикам изображения. Образцы, не прошедшие проверку, отбрасываются, что позволяет получить более качественный и релевантный результат. Эффективность отбора напрямую зависит от строгости критериев и количества генерируемых образцов; более строгие критерии и большее количество образцов обычно приводят к повышению качества, но также требуют больше вычислительных ресурсов.
Использование рекуррентных нейронных сетей (RNN) и многослойных персептронов (MLP) значительно улучшает способность модели улавливать сложные временные зависимости в данных, что критически важно для генерации реалистичных изображений. RNN, благодаря своей архитектуре, эффективно обрабатывают последовательности данных, позволяя учитывать предыдущие состояния при генерации текущего кадра или пикселя. MLP, в свою очередь, обеспечивают нелинейное преобразование признаков, что необходимо для моделирования сложных взаимосвязей между элементами изображения. Комбинация этих архитектур позволяет создавать модели, способные генерировать изображения с высокой степенью детализации и реалистичности, учитывая контекст и временную последовательность данных.
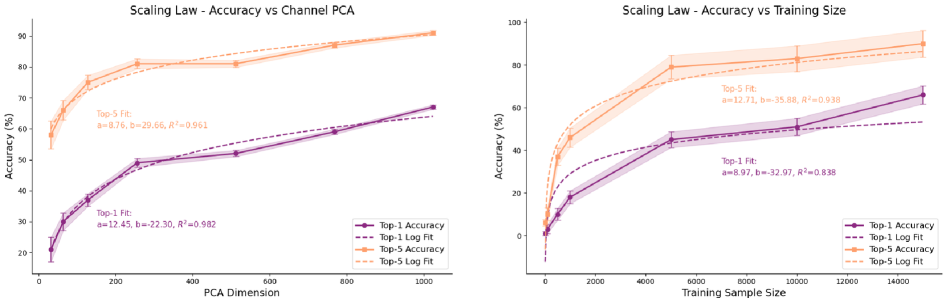
Масштабирование и Будущие Направления в Визуальном Декодировании
Исследования в области визуального декодирования подтверждают, что эффективность восстановления изображений по нейронной активности напрямую связана с закономерностями масштабирования. Установлено, что увеличение как вычислительной мощности модели, так и объема обучающего набора данных приводит к значительному улучшению результатов. Более крупные модели способны улавливать более сложные паттерны в нейронных сигналах, а обширные базы данных позволяют им обобщать полученные знания на новые, ранее не встречавшиеся изображения. Этот принцип масштабирования, наблюдаемый в различных областях машинного обучения, подчеркивает фундаментальную важность ресурсов для достижения прогресса в понимании и реконструкции визуальной информации, открывая перспективы для создания все более точных и реалистичных систем визуального декодирования.
Перспективные достижения в области генеративных моделей и контрастивного обучения, в сочетании с использованием все более масштабных и всесторонних наборов данных, открывают путь к созданию исключительно точных и реалистичных визуальных реконструкций. Развитие этих направлений позволяет алгоритмам не просто воссоздавать изображения, но и генерировать новые, правдоподобные визуальные представления, приближающиеся к качеству, воспринимаемому человеческим глазом. Особенно значимым представляется возможность моделирования сложных деталей и текстур, что критически важно для приложений, требующих высокой степени реализма, таких как виртуальная и дополненная реальность, а также медицинская визуализация. По мере увеличения объема и разнообразия обучающих данных, ожидается дальнейшее повышение качества генерируемых изображений и их соответствие реальным визуальным стимулам.
Данное исследование демонстрирует значительный прорыв в области визуального декодирования, достигая точности извлечения информации в 30% по показателю Top-1. Этот результат превосходит показатели базовых моделей, работающих на миллисекундном уровне, что свидетельствует о существенном улучшении эффективности предложенного подхода. Особенно важным фактором повышения точности оказалась модель с механизмом «мягкого внимания» (soft-attention), позволяющая более эффективно фокусироваться на релевантных деталях изображения. Полученные результаты открывают перспективы для разработки более совершенных систем анализа визуальной информации и расширения возможностей взаимодействия человека и компьютера.
Исследование открывает перспективные направления для углубленного понимания нейронных механизмов, лежащих в основе зрительного восприятия. Разработанные методы визуального декодирования могут стать основой для создания усовершенствованных интерфейсов «мозг-компьютер», позволяющих преобразовывать нейронную активность в визуальные образы. Особенно значимым представляется потенциал данной работы в области восстановления зрения у людей с нарушениями, предлагая инновационные подходы к разработке протезов и систем, способных обходить поврежденные участки зрительной коры и возвращать пациентам возможность видеть. Успехи в области декодирования визуальной информации стимулируют дальнейшие исследования в нейрореабилитации и создании адаптивных технологий для людей с ограниченными возможностями.
Исследование демонстрирует, что даже относительно простые модели, ориентированные на временную динамику визуальной информации, способны с высокой точностью реконструировать зрительные стимулы из нейронных сигналов коры головного мозга приматов. Этот подход, сочетающий модульный процесс извлечения и генерации, подчеркивает значимость временных аспектов в нейронном декодировании. Как отмечал Марк Аврелий: «Всё, что происходит с тобой, — это результат твоего разума». Подобно тому, как разум формирует восприятие, так и правильно сконструированная модель способна “расшифровать” нейронные сигналы, воссоздавая изначальную визуальную информацию. В данном случае, понимание принципов работы системы нейронного декодирования позволяет не просто описывать её, но и эффективно использовать, открывая новые возможности для интерфейсов мозг-компьютер.
Что дальше?
Представленные результаты, безусловно, демонстрируют эффективность упрощённых моделей декодирования визуальной информации из нейронных сигналов приматов. Однако, что произойдёт, если отказаться от самой идеи «реконструкции» изображения? Если допустить, что нейронные сети мозга не стремятся воссоздать внешний мир, а лишь выстраивают внутреннюю, функциональную репрезентацию, достаточную для принятия решений? Попытки “воссоздать” изображение могут оказаться всего лишь удобным, но искусственным ограничением.
Особый интерес представляет вопрос о масштабируемости. Достаточно ли будет улучшения алгоритмов контрастного обучения и временного внимания для перехода от декодирования простых стимулов к пониманию сложных сцен? Или же, в конечном итоге, необходим принципиально новый подход, учитывающий иерархическую организацию коры и взаимодействие различных её областей? Упрощение моделей — это хорошо, но упрощение реальности — опасная иллюзия.
В перспективе, исследование подобных систем может выйти за рамки чисто академического интереса. Создание интерфейсов «мозг-компьютер», основанных на декодировании нейронных сигналов, — это, конечно, привлекательная задача. Но что, если подобная технология позволит не только «читать» мысли, но и «внедрять» в мозг новые представления? Где проходит граница между расширением возможностей и манипулированием сознанием? Этот вопрос, возможно, и станет главным вызовом для исследователей в будущем.
Оригинал статьи: https://arxiv.org/pdf/2601.11108.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Лучшие смартфоны. Что купить в марте 2026.
- Oppo Reno15 ОБЗОР: отличная камера, много памяти, скоростная зарядка
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- vivo V70 ОБЗОР: современный дизайн, портретная/зум камера, высокая автономность
2026-01-19 23:45