Автор: Денис Аветисян
Новое исследование предлагает метод снижения склонности мультимодальных моделей к «выдумыванию» объектов на изображениях, улучшая точность описаний.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Метод основан на маскировании значимых визуальных признаков с использованием карт внимания из самообучающихся визуальных трансформеров и контрастивной декодировки.
Несмотря на впечатляющие успехи мультимодальных больших языковых моделей, проблема «галлюцинаций» объектов в генерируемых описаниях остается актуальной. В статье ‘Mask What Matters: Mitigating Object Hallucinations in Multimodal Large Language Models with Object-Aligned Visual Contrastive Decoding’ предложен метод снижения этих галлюцинаций посредством создания вспомогательных видов, маскирующих наиболее значимые визуальные свидетельства на основе карт внимания, полученных из самообучающихся Vision Transformers. Этот подход, улучшающий визуальное контрастное декодирование, позволяет повысить точность описаний изображений без значительных вычислительных затрат. Не приведет ли дальнейшее развитие подобных методов к созданию действительно «видящих» и понимающих моделей?
Иллюзия Реальности: Проблема Галлюцинаций в Мультимодальных Моделях
Мультимодальные большие языковые модели (MLLM) демонстрируют впечатляющую способность к обработке информации, однако склонны к феномену, известному как «галлюцинации объектов». Этот процесс проявляется в том, что модель генерирует детали, которых фактически нет на представленном изображении. Несмотря на значительный прогресс в области искусственного интеллекта, MLLM могут спонтанно добавлять несуществующие объекты или атрибуты, что приводит к неточностям и потенциально ошибочным выводам. Данная особенность представляет серьезную проблему, особенно в приложениях, требующих высокой точности визуального понимания, таких как автономная навигация, медицинская диагностика или анализ изображений для служб безопасности. Неспособность модели достоверно соотносить генерируемый текст с визуальным входом подрывает доверие к её ответам и ограничивает возможности практического применения.
Ограниченная надежность мультимодальных больших языковых моделей (MLLM) в критически важных приложениях представляет серьезную проблему. Способность точно интерпретировать визуальную информацию и генерировать ответы, основанные исключительно на представленных данных, является ключевым требованием для таких областей, как медицинская диагностика, автономное вождение и робототехника. Однако, склонность MLLM к «галлюцинациям» — генерации деталей, отсутствующих на входном изображении — существенно снижает доверие к их результатам. В ситуациях, где точность имеет первостепенное значение, даже незначительные ошибки, вызванные галлюцинациями, могут привести к серьезным последствиям, подчеркивая необходимость разработки более надежных и обоснованных визуальными данными моделей.
Существующие подходы к смягчению галлюцинаций в мультимодальных больших языковых моделях (MLLM) демонстрируют ограниченную эффективность, что указывает на необходимость разработки принципиально новых техник. Текущие методы часто не способны адекватно сопоставить генерируемые описания с визуальным содержанием входного изображения, приводя к появлению несуществующих объектов или атрибутов. Основная проблема заключается в недостаточной интеграции визуальных доказательств в процесс генерации текста — модели склонны полагаться на общие знания и языковые закономерности, игнорируя или неправильно интерпретируя информацию, представленную на изображении. Таким образом, ключевым направлением исследований является создание алгоритмов, которые будут более эффективно использовать визуальные данные в качестве основы для генерации точных и правдивых описаний, обеспечивая тем самым надежность и достоверность ответов мультимодальных моделей.
Современные мультимодальные большие языковые модели (MLLM) демонстрируют впечатляющие возможности, однако, как показывают сравнительные тесты, такие как POPE и MME, склонность к «объективным галлюцинациям» — генерации деталей, отсутствующих на входном изображении — остается серьезной проблемой. Эти бенчмарки последовательно выявляют распространенность и значительность данной ошибки в различных MLLM. Несмотря на предпринимаемые усилия, существующие методы смягчения галлюцинаций показывают ограниченную эффективность, что подчеркивает необходимость разработки более совершенных техник, способных обеспечить более точное визуальное понимание и надежные ответы, основанные на фактических данных изображения. Неспособность эффективно устранить эту проблему ограничивает применимость MLLM в критически важных областях, где точность и соответствие реальности имеют первостепенное значение.

Объектно-Согласованное Визуальное Контрастивное Декодирование: Новый Подход
Метод объектно-ориентированного визуального контрастного декодирования (Object-Aligned Visual Contrastive Decoding) направлен на снижение галлюцинаций в задачах генерации текста по изображениям путем сопоставления распределений вероятностей следующего токена между исходным изображением и его возмущенной версией. Этот подход основывается на предположении, что галлюцинации возникают, когда модель генерирует текст, не соответствующий визуальному содержанию. Контрастируя прогнозы для исходного и возмущенного изображений, модель обучается фокусироваться на реальных визуальных признаках и избегать генерации контента, не подтвержденного визуальными данными. Различия в распределениях вероятностей служат сигналом для корректировки параметров модели, усиливая ее зависимость от фактического визуального контекста и уменьшая склонность к «выдумыванию» деталей.
Для определения заметных областей на входном изображении используется Self-Supervised Vision Transformer (SVT). SVT извлекает карты внимания (Attention Maps), которые отражают, на какие части изображения модель фокусирует своё внимание при обработке. Эти карты внимания представляют собой матрицы, где каждое значение соответствует степени внимания к конкретному пикселю или региону изображения. Использование Self-Supervised подхода позволяет SVT обучаться без размеченных данных, извлекая полезные признаки и определяя важные области изображения на основе внутренней структуры данных и закономерностей, что критично для последующего процесса маскирования и контрастивного обучения.
Карты внимания, полученные посредством Self-Supervised Vision Transformer, преобразуются в карты значимости (Saliency Maps) для целенаправленного маскирования входного изображения. Этот процесс предполагает, что регионы с высокой значимостью, определяемые картами внимания, подвергаются маскировке в процессе создания дополнительных видов (Auxiliary Views). Целью является создание возмущенных изображений, в которых изменения сосредоточены на визуально важных элементах, а не на случайных пикселях. Такой подход позволяет модели сосредоточиться на значимых визуальных признаках и снизить вероятность генерации галлюцинаций, поскольку контрастивное обучение основывается на различиях в распределениях вероятностей при изменении только существенных деталей изображения.
Для создания контрастивного обучающего фреймворка, мы генерируем вспомогательные виды (Auxiliary Views) посредством целенаправленного маскирования входного изображения. Процесс маскирования ориентирован на области, выделенные картами внимания (Attention Maps), что позволяет сохранять только значимые визуальные признаки. В результате, модель обучается различать оригинальное изображение и его модифицированную версию, где важные элементы остаются неизменными. Это способствует повышению надежности модели и снижению вероятности генерации галлюцинаций, поскольку она учится опираться на подтвержденные визуальные данные, а не на произвольные ассоциации.
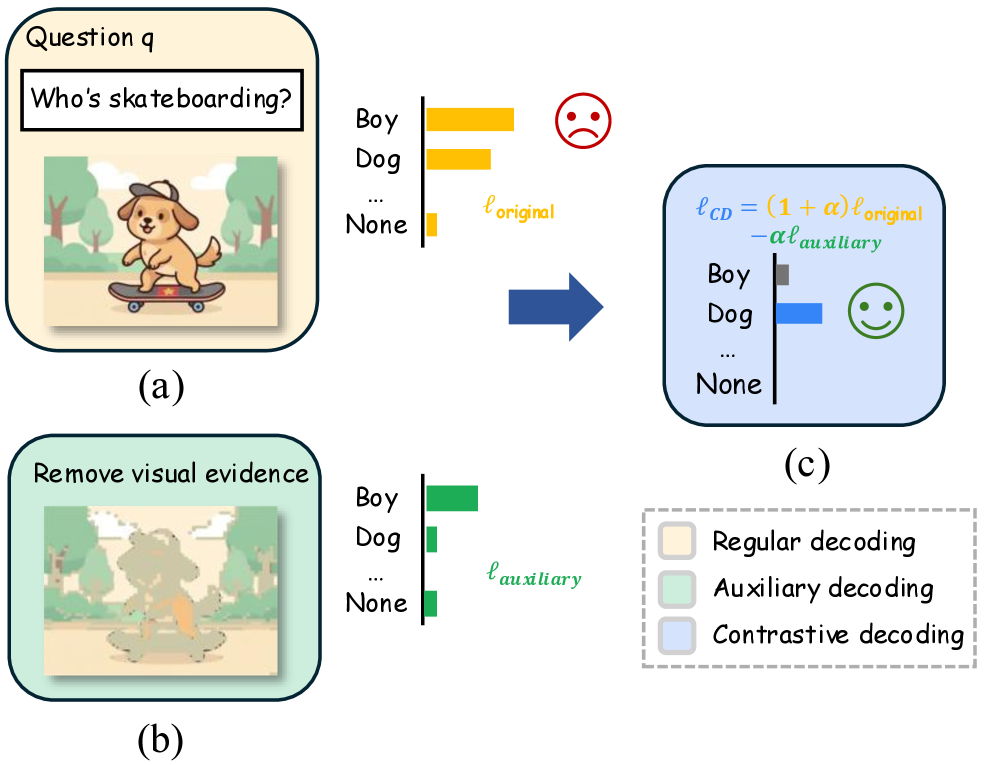
Реализация Целенаправленной Пертурбации Изображений: Детали Метода
Для реализации целенаправленного искажения изображений используется маскирование, управляемое картой заметности (Saliency Map). Этот метод позволяет выборочно скрывать наиболее выраженные визуальные элементы изображения, определяемые на основе карты заметности, которая выявляет области, привлекающие наибольшее внимание. Маскирование применяется к этим областям, эффективно удаляя или заменяя их, что приводит к созданию измененных версий изображения, сохраняющих общую структуру, но с измененными ключевыми деталями. Степень маскирования может варьироваться в зависимости от значения заметности в конкретной области изображения.
Для восстановления замаскированных областей изображения используются методы восстановления фона (inpainting), такие как усреднение цвета (Mean Color) и размытие (Blur). Эти методы позволяют генерировать визуально связные и правдоподобные дополнительные представления (Auxiliary Views) путем заполнения отсутствующих фрагментов, основываясь на окружающем контексте. Применение усреднения цвета предполагает замену замаскированных пикселей средним цветом соседних пикселей, что обеспечивает плавный переход. Размытие, в свою очередь, применяется для смягчения границ между восстановленными и исходными областями, создавая более естественный визуальный эффект. Выбор метода восстановления фона определяется спецификой изображения и желаемым уровнем детализации.
Для динамического определения порога маскирования, используемого при сокрытии наиболее заметных визуальных признаков, применяется квантильное пороговое значение к карте заметности (Saliency Map). Вместо использования фиксированного значения, этот метод автоматически адаптируется к содержанию изображения и силе внимания. Квантильное пороговое значение вычисляет порог, соответствующий определенному процентилю (квантилю) распределения значений в карте заметности. Это позволяет более эффективно маскировать наиболее важные области изображения, игнорируя менее значимые, и обеспечивает адаптацию к изображениям с различной степенью детализации и контрастности. Выбор конкретного квантиля позволяет регулировать степень маскирования, обеспечивая баланс между сохранением визуальной информации и эффективностью пертурбации.
В рамках визуального контрастивного декодирования применяются адаптивные ограничения правдоподобия, позволяющие уточнить процесс генерации. Эти ограничения основаны на вероятностях исходных токенов, при этом в процесс включаются преимущественно те токены, которые имели высокие значения вероятности до применения возмущений. Такой подход позволяет сохранить визуальную когерентность и реалистичность реконструируемых изображений, минимизируя влияние случайных артефактов и обеспечивая соответствие с исходным контентом. Селективное рассмотрение токенов с высокой исходной вероятностью повышает стабильность и качество процесса декодирования, особенно в областях с высокой степенью детализации или сложной текстурой.

Результаты и Более Широкие Последствия: Взгляд в Будущее
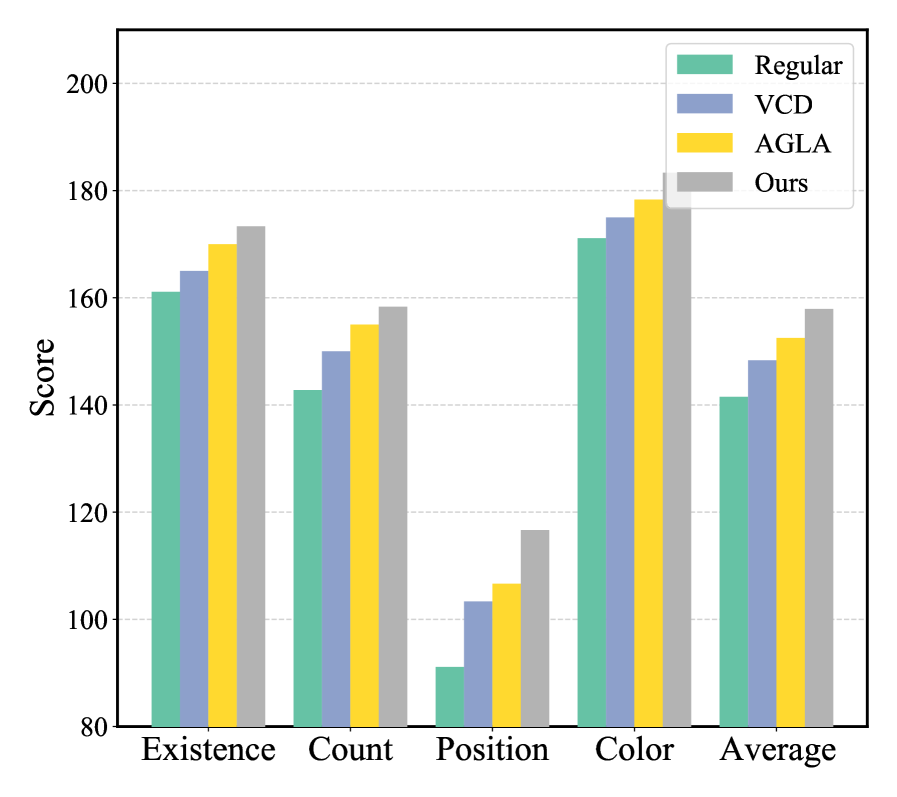
Экспериментальные исследования, проведенные с использованием эталонных наборов данных, таких как POPE и MME, продемонстрировали существенное снижение явления «галлюцинаций» объектов в различных мультимодальных больших языковых моделях (MLLM), включая LLaVA-v1.5 и Qwen-VL. Данный подход последовательно превосходит базовые методы, обеспечивая более высокую точность идентификации и распознавания объектов на изображениях. Установлено, что предложенная методика эффективно подавляет ложные срабатывания и неверные интерпретации визуальной информации, что свидетельствует о повышении надежности и достоверности работы систем искусственного интеллекта, способных обрабатывать как текст, так и изображения.
В рамках визуального контрастивного декодирования применение критерия расстояния Softmax позволяет усилить контрастный сигнал, что приводит к более эффективному различению подлинного содержания изображения и галлюцинаций. Этот подход позволяет модели более четко определять, какие объекты действительно присутствуют на изображении, а какие являются результатом неверной интерпретации или «выдумки». Усиленный контрастный сигнал способствует формированию более точных представлений об изображении, что, в свою очередь, повышает надежность и точность мультимодальных моделей искусственного интеллекта при анализе визуальной информации и снижает вероятность ложных выводов.
В ходе экспериментов, проведенных на подмножестве MSCOCO бенчмарка POPE, продемонстрировано значительное повышение показателей F1-меры. Это свидетельствует об улучшенной точности распознавания объектов на изображениях. Полученные результаты указывают на то, что разработанный подход эффективно повышает способность мультимодальных моделей к корректной идентификации и классификации объектов, что является важным шагом к созданию более надежных и точных систем искусственного интеллекта, способных к визуальному пониманию.
В ходе оценки на бенчмарке MME продемонстрирована превосходная эффективность разработанного подхода, который достиг наивысшего среднего показателя Accuracy+ для обеих моделей — LLaVA-v1.5 и Qwen-VL. Данный результат свидетельствует о значительном улучшении способности системы к комплексному пониманию изображений на уровне всего кадра. Повышенный показатель Accuracy+ указывает на то, что модель не только правильно идентифицирует объекты, но и корректно интерпретирует взаимосвязи между ними, демонстрируя более глубокое и целостное восприятие визуальной информации. Это достижение имеет ключевое значение для повышения надежности и практической применимости мультимодальных ИИ-систем, требующих точного и всестороннего анализа изображений.
Устранение проблемы галлюцинаций в мультимодальных системах искусственного интеллекта открывает путь к созданию более надежных и предсказуемых моделей. Вместо того чтобы генерировать несуществующие объекты или неверно интерпретировать визуальную информацию, усовершенствованные алгоритмы, способные эффективно различать реальные и ложные данные, позволяют значительно повысить доверие к результатам работы ИИ. Это особенно важно для приложений, где точность и надежность имеют решающее значение, например, в медицинской диагностике, автономном вождении или системах безопасности. Уменьшение склонности к галлюцинациям не только улучшает качество генерируемого контента, но и способствует более безопасному и ответственному внедрению мультимодальных моделей в различные сферы жизни.
Исследование демонстрирует, что ключевым аспектом создания надежных мультимодальных больших языковых моделей является минимизация галлюцинаций объектов. Предложенный подход, использующий контрастирующую декодировку и маскирование значимых визуальных признаков на основе карт внимания, позволяет модели более точно интерпретировать изображения. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект — это не только о создании машин, которые могут думать, но и о создании машин, которые могут видеть и понимать мир вокруг нас». Этот принцип находит отражение в данной работе, где акцент делается на улучшение способности модели «видеть» и корректно описывать визуальный контент, избегая при этом неверных интерпретаций и выдуманных деталей.
Что дальше?
Представленная работа, безусловно, демонстрирует потенциал направленного вмешательства в процесс декодирования, чтобы уменьшить склонность мультимодальных моделей к «галлюцинациям» объектов. Однако, стоит признать, что полное искоренение этой проблемы представляется скорее утопией, чем достижимой целью. Модель, лишенная возможности генерировать нечто новое, рискует превратиться в простого пересказчика увиденного, утратив способность к креативному синтезу. Ошибка — это не провал, а ценный сигнал, указывающий на пробелы в понимании системы.
Перспективным направлением представляется изучение динамики внимания не только на уровне отдельных объектов, но и на уровне их взаимосвязей. Понимание контекста, в котором объект появляется на изображении, может оказаться ключом к снижению вероятности ложных интерпретаций. Кроме того, необходимо исследовать, как различные типы «галлюцинаций» — от незначительных неточностей до принципиально неверных описаний — влияют на общее качество генерируемого текста.
В конечном счете, задача состоит не в том, чтобы создать модель, которая никогда не ошибается, а в том, чтобы создать модель, которая умеет учиться на своих ошибках и адаптироваться к меняющимся условиям. Поиск закономерностей в хаосе — вот истинный вызов для исследователей в этой области. И, возможно, истинное понимание придет не от устранения «галлюцинаций», а от их глубокого анализа.
Оригинал статьи: https://arxiv.org/pdf/2602.11737.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Неважно, на что вы фотографируете!
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Как самому почистить матрицу. Продолжение.
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- MSI Katana 17 HX B14WGK ОБЗОР
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
- Что такое глубина резкости в фотографии?
- Microsoft возрождает функцию расширения браузера Edge спустя годы после отмены последнего теста
- Макросъемка
2026-02-15 03:37