Автор: Денис Аветисян
Исследователи представили систему Trifuse, позволяющую компьютерам более точно интерпретировать графический интерфейс пользователя, объединяя визуальную информацию, текст и иконки.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"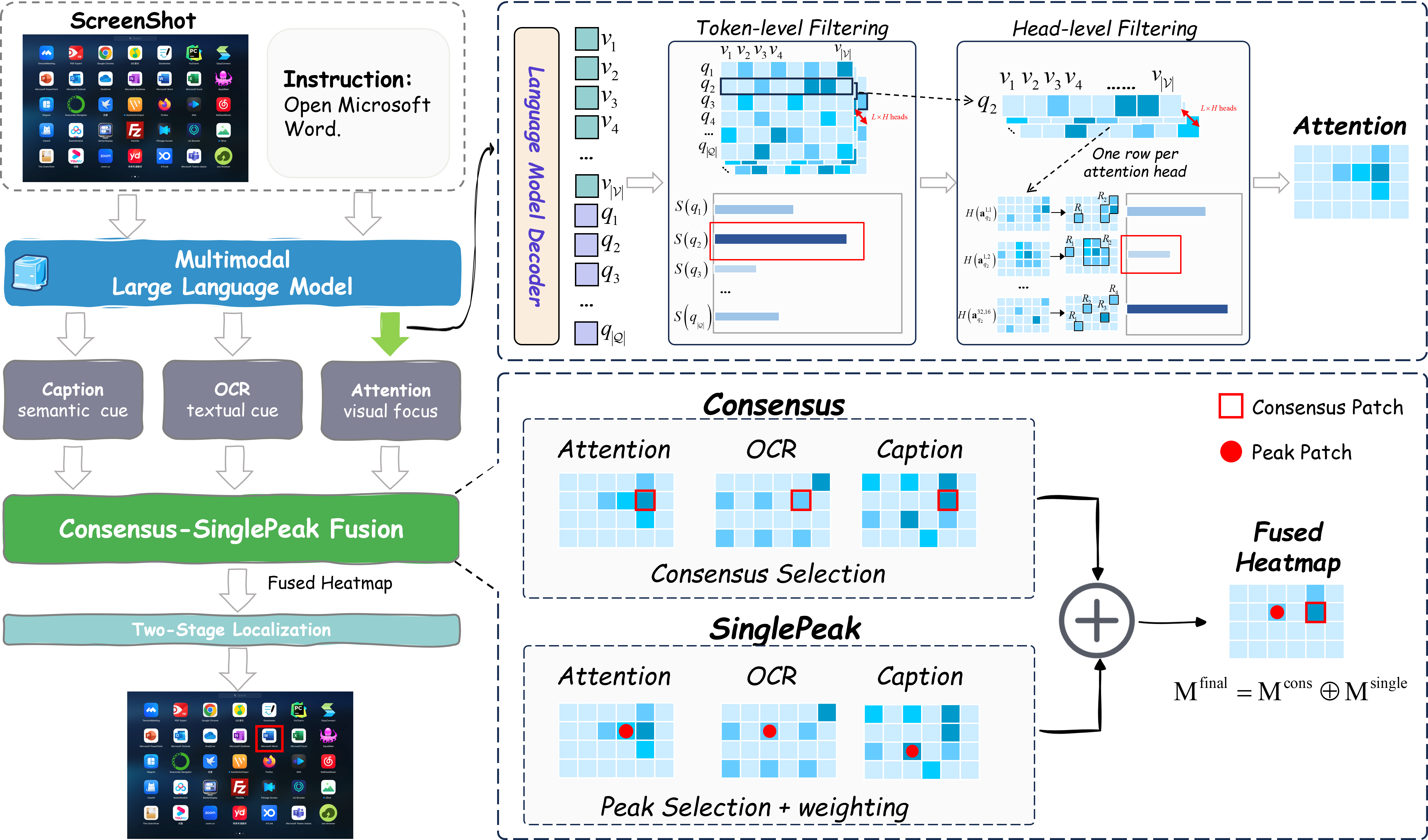
Предложенная платформа Trifuse улучшает точность определения элементов GUI за счет мультимодального слияния внимания, данных OCR и подписей к иконкам, не требуя специальных обучающих данных для интерфейсов.
Несмотря на успехи современных мультимодальных больших языковых моделей, задача привязки естественного языка к элементам графического интерфейса (GUI grounding) остается сложной из-за высокой потребности в размеченных данных и слабой обобщающей способности. В данной работе, представленной под названием ‘Trifuse: Enhancing Attention-Based GUI Grounding via Multimodal Fusion’, предлагается новый подход, Trifuse, который повышает точность GUI grounding за счет интеграции внимания, текстовых данных, полученных с помощью OCR, и семантики подписей к иконкам. Эксперименты показывают, что Trifuse достигает высоких результатов без дополнительной настройки на специфических GUI-данных, снижая зависимость от дорогостоящей разметки. Способна ли эта архитектура стать основой для создания более эффективных и адаптивных GUI-агентов, способных понимать и взаимодействовать с любым пользовательским интерфейсом?
Задача GUI-Основания: За Пределами Простого Визуального Восприятия
Традиционные методы компьютерного зрения сталкиваются с серьезными трудностями при надежном сопоставлении естественного языка с элементами графического интерфейса пользователя, что существенно замедляет разработку доступных GUI-агентов. Проблема заключается не в самой возможности «видеть» интерфейс, а в интерпретации намерений пользователя в контексте сложной визуальной среды. Несмотря на значительный прогресс в распознавании образов, системы часто ошибочно идентифицируют элементы или неверно понимают связь между запросом на естественном языке и конкретным действием в приложении. Это особенно заметно в динамических интерфейсах или при наличии неоднозначных формулировок, где требуется более глубокое семантическое понимание, чем просто визуальное соответствие. Как следствие, создание универсальных и интуитивно понятных GUI-агентов, способных эффективно взаимодействовать с различными приложениями, остается сложной задачей.
Суть сложности взаимодействия с графическими интерфейсами заключается не в распознавании визуальных элементов, а в интерпретации намерений пользователя в контексте сложного визуального окружения. Современные системы часто испытывают трудности при определении, что именно пользователь хочет сделать, даже если все элементы интерфейса успешно идентифицированы. Проблема заключается в том, что для успешного взаимодействия требуется не просто “видеть” кнопки и поля, а понимать, какое действие пользователь ожидает от системы в данный момент, учитывая все контекстуальные факторы и возможные неоднозначности. Понимание намерений пользователя требует анализа не только визуальной информации, но и семантики элементов интерфейса, а также истории взаимодействия и общих знаний о задачах, которые обычно решаются с помощью данного приложения.
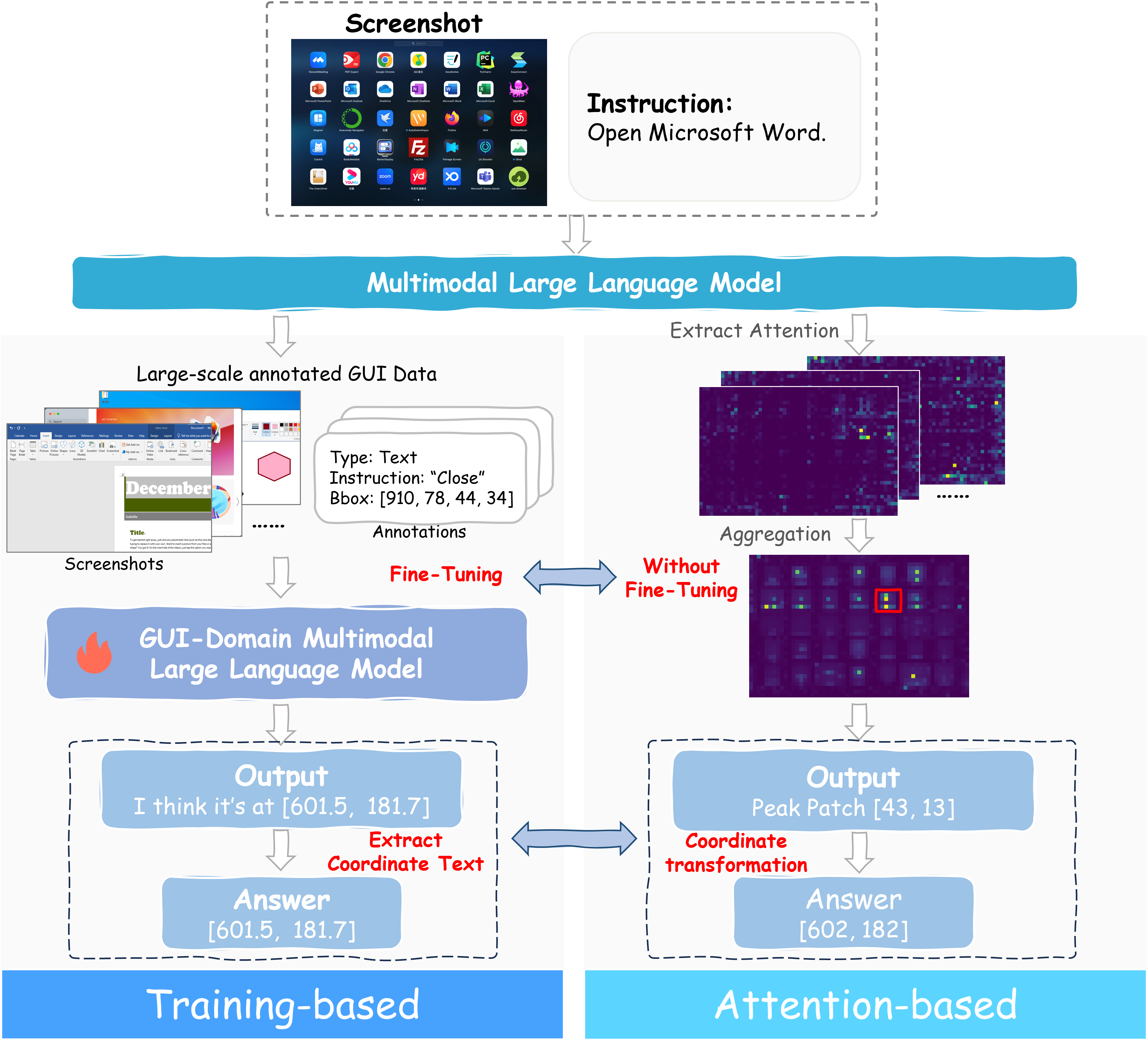
Существующие подходы к взаимодействию с графическими интерфейсами часто требуют значительной адаптации и тонкой настройки для каждой конкретной задачи и каждого нового приложения. Это связано с тем, что модели, обученные для выполнения определённых действий в конкретной среде, испытывают трудности при переносе знаний на незнакомые интерфейсы или новые типы задач. Такая зависимость от узкоспециализированного обучения существенно ограничивает возможность создания универсальных агентов, способных эффективно взаимодействовать с разнообразными графическими средами без необходимости повторного обучения для каждого нового приложения или обновления интерфейса. Необходимость обширной тонкой настройки становится серьёзным препятствием для масштабируемости и практического применения подобных систем в реальных условиях.
Механизмы Внимания: Мощная Основа Распознавания
Механизмы внимания позволяют моделям сосредотачиваться на релевантных участках графического пользовательского интерфейса (GUI), имитируя процесс визуального внимания человека. В отличие от традиционных методов, анализирующих весь GUI целиком, механизмы внимания динамически взвешивают различные элементы интерфейса, определяя наиболее важные для текущей задачи. Этот процесс основан на вычислении весов, которые присваиваются каждому элементу GUI, отражая степень его значимости. Более высокие веса указывают на элементы, на которые модель должна обратить больше внимания, что позволяет ей эффективно обрабатывать информацию и игнорировать несущественные детали. Такой подход значительно снижает вычислительную сложность и повышает точность определения релевантных элементов интерфейса.
Методы, такие как TAG (Transformer-based GUI Attention Graph) и GUI-Actor, используют механизмы внимания для определения местоположения элементов графического интерфейса пользователя (GUI) без необходимости обширного обучения, специфичного для конкретной задачи. TAG формирует граф внимания, представляющий взаимосвязи между элементами GUI, а GUI-Actor использует архитектуру, основанную на акторах, и механизмы внимания для определения релевантных элементов. Оба подхода позволяют модели концентрироваться на наиболее значимых частях GUI, существенно снижая потребность в больших объемах размеченных данных для обучения и повышая эффективность обнаружения элементов по сравнению с традиционными методами, требующими детального анализа всего интерфейса.
Подходы, основанные на механизмах внимания, демонстрируют значительный прогресс в автоматизации взаимодействия с графическим интерфейсом пользователя (GUI) за счет смещения акцента с исчерпывающего анализа всего интерфейса на определение намерений пользователя. Традиционные методы требовали детального сканирования каждого элемента GUI для определения возможных действий, что было вычислительно затратно и неэффективно. Вместо этого, современные системы, использующие внимание, фокусируются на тех областях интерфейса, которые наиболее релевантны предполагаемому действию пользователя, что позволяет значительно сократить объем необходимых вычислений и повысить точность определения целевого элемента. Такой подход позволяет снизить зависимость от обширного, специфичного для каждой задачи обучения, и повысить обобщающую способность моделей.
Trifuse: Холистический Подход к Мультимодальному Слиянию
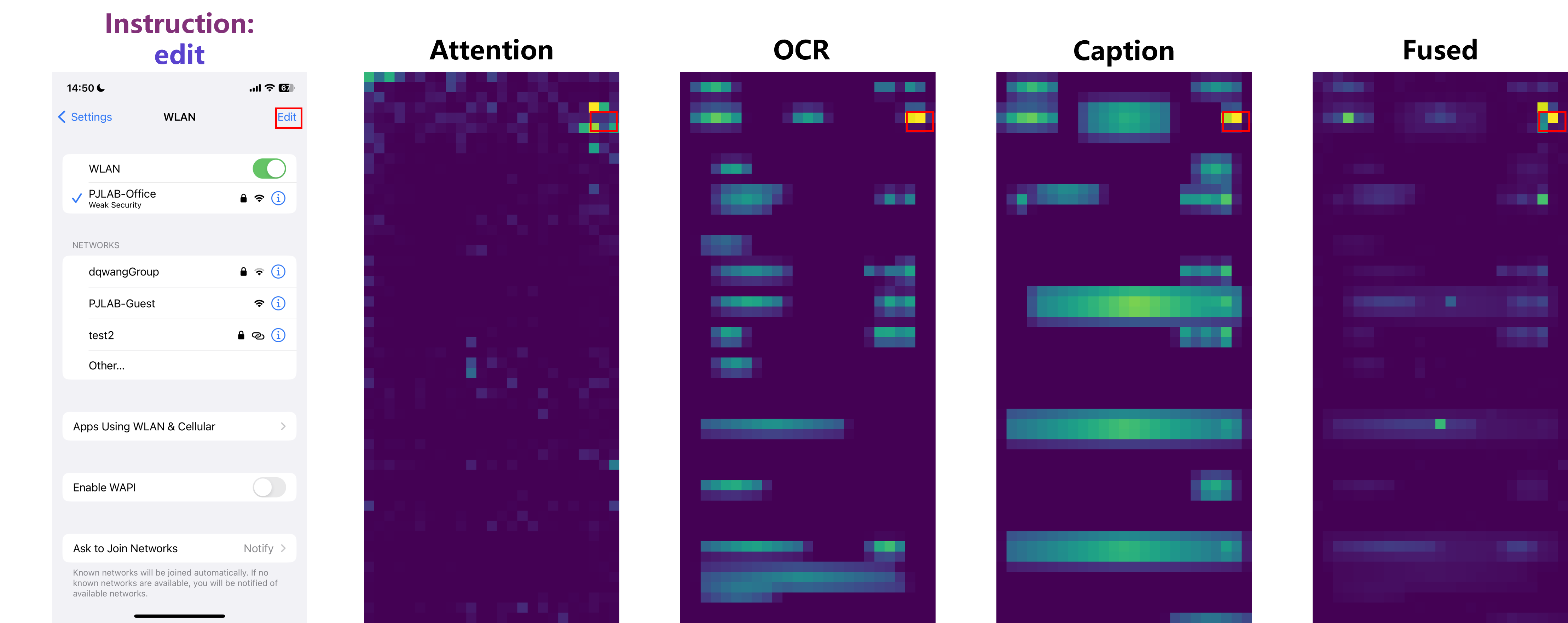
Архитектура Trifuse представляет собой значительный шаг вперед в понимании графических пользовательских интерфейсов (GUI) благодаря интеграции нескольких модальностей. В частности, она объединяет механизмы внимания для определения релевантных областей экрана, оптическое распознавание символов (OCR) для извлечения текстовой информации из GUI и семантический анализ подписей к иконкам. Такое комплексное сочетание позволяет Trifuse учитывать как визуальные, так и текстовые элементы GUI, что обеспечивает более полное и точное понимание интерфейса и контекста взаимодействия с ним. Использование всех трех модальностей в единой архитектуре позволяет преодолеть ограничения, присущие системам, использующим только одну или две модальности, и повысить общую надежность и точность анализа GUI.
В основе Trifuse лежит объединение нескольких модальностей данных — визуальной информации, результатов оптического распознавания символов (OCR) и семантики иконок — для решения проблемы неоднозначности, возникающей при взаимодействии с графическим интерфейсом пользователя (GUI). Использование мультимодального подхода позволяет системе более точно интерпретировать элементы GUI, поскольку информация из различных источников дополняет и подтверждает друг друга. Это, в свою очередь, повышает как точность (precision) определения целевых элементов, так и устойчивость (robustness) системы к различным вариациям в оформлении GUI и условиям работы, таким как низкое качество изображения или частичная видимость элементов.
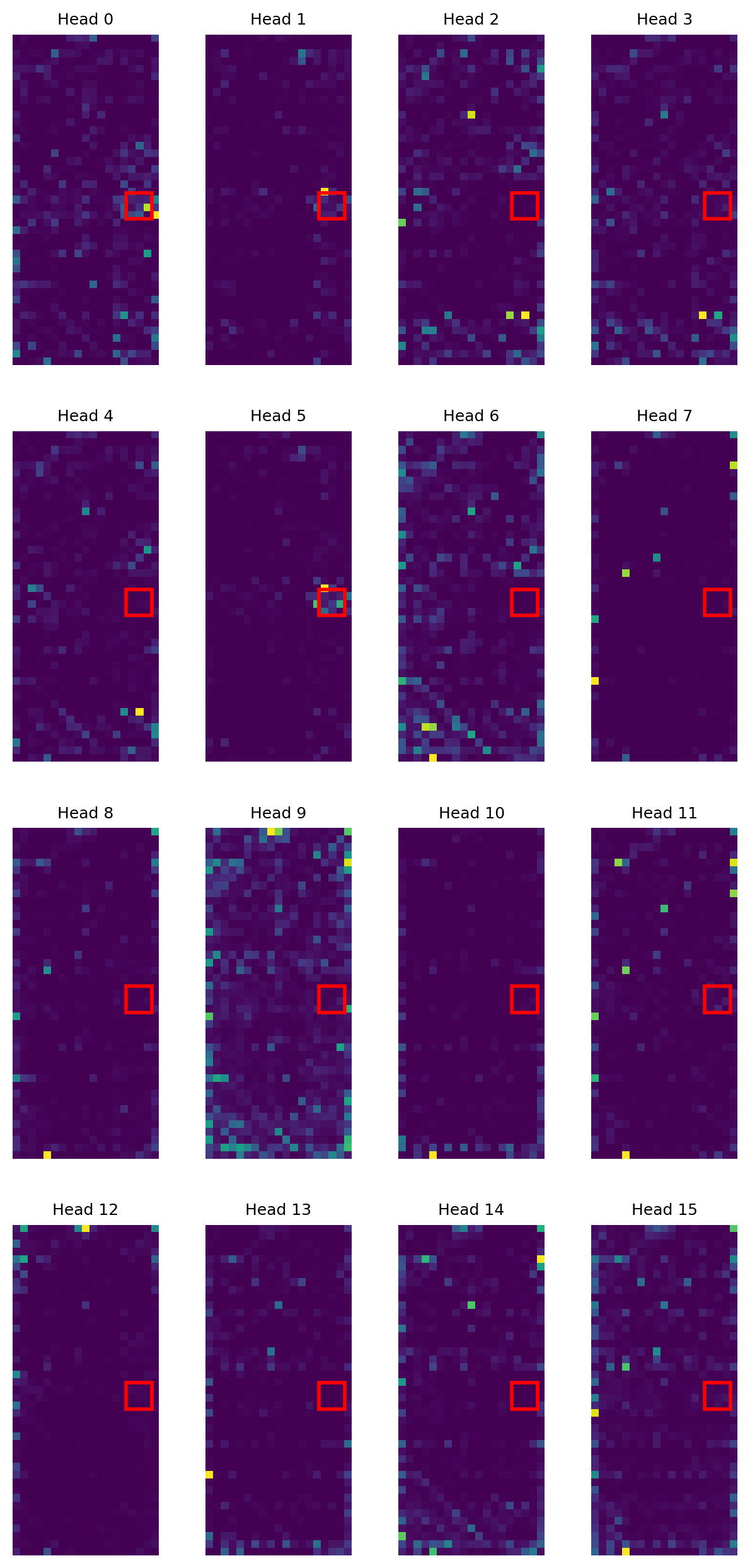
Для повышения точности привязки (grounding) в системе Trifuse применяются методы консенсуса с единым пиком (Consensus-Single peak, CS) и двухэтапной локализации. Метод CS использует консенсус между различными головами внимания для определения наиболее релевантных областей GUI, что позволяет снизить влияние шума и повысить стабильность результатов. Двухэтапная локализация, в свою очередь, сначала определяет общую область, содержащую целевой элемент, а затем уточняет её границы, что позволяет добиться более точной привязки и уменьшить количество ложных срабатываний. Комбинация этих двух подходов позволяет значительно улучшить качество привязки элементов GUI по сравнению с традиционными методами, использующими одноэтапную локализацию или усреднение результатов по всем головам внимания.
Внедрение фильтрации токенов и заголовков внимания в архитектуру Trifuse направлено на оптимизацию механизмов внимания, используемых для привязки (grounding) к элементам графического интерфейса. Фильтрация токенов позволяет исключить из рассмотрения нерелевантные или зашумленные входные данные, повышая эффективность процесса внимания. Фильтрация заголовков внимания, в свою очередь, фокусируется на наиболее значимых частях выходных данных внимания, отсеивая менее информативные. Комбинация этих методов позволяет снизить вычислительную сложность, улучшить точность привязки и повысить устойчивость системы к помехам, что особенно важно при работе со сложными и зашумленными GUI.
Предложенный фреймворк Trifuse демонстрирует конкурентоспособную или превосходящую производительность в задачах GUI-определения местоположения элементов, что подтверждает его практическую ценность для улучшения возможностей MLLM в автоматизации GUI. Результаты экспериментов показывают, что точность определения элементов сопоставима или превосходит показатели современных методов на стандартных бенчмарках, включая ScreenSpot, ScreenSpot-v2, ScreenSpot-Pro и OSWorld-G. Это указывает на эффективность Trifuse в решении задач, связанных с пониманием и взаимодействием с графическим интерфейсом пользователя.
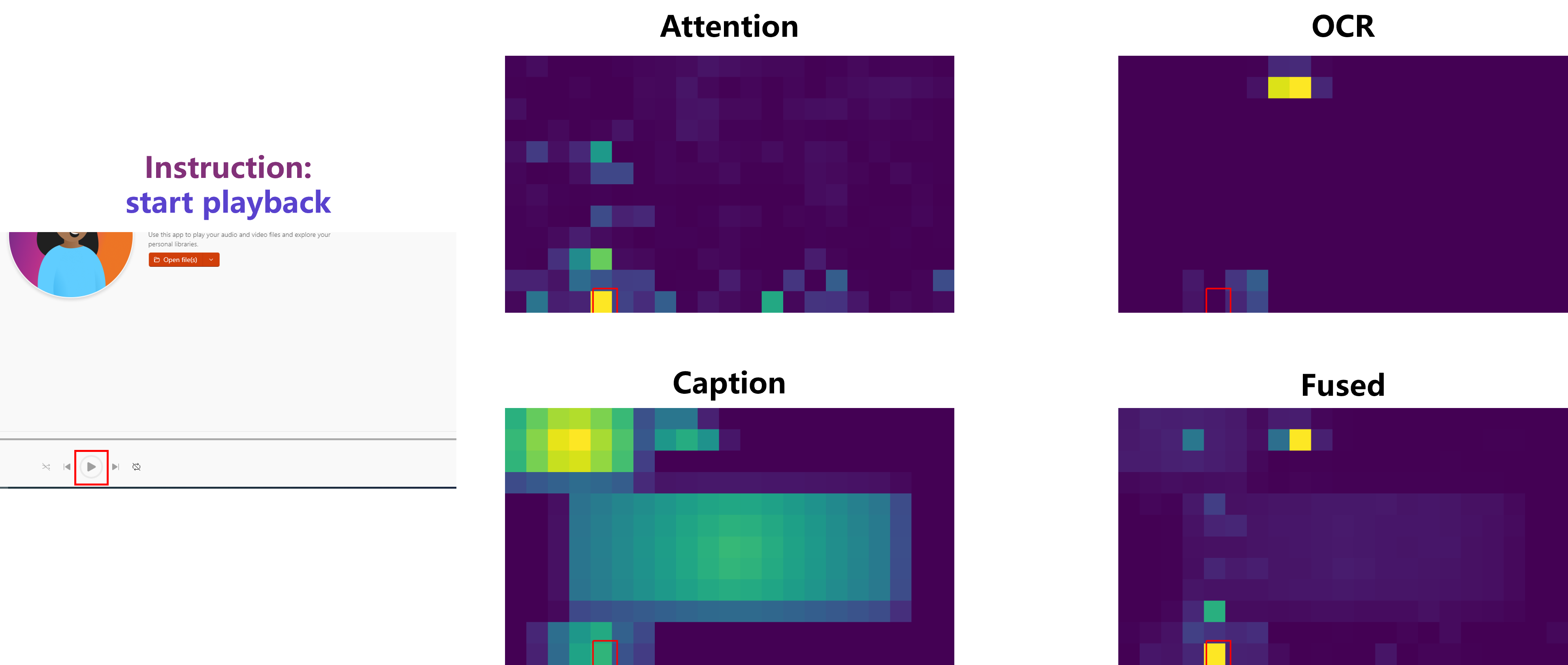
Оценка Прогресса: Наборы Данных для GUI-Основания
Наборы данных, такие как ScreenSpot, ScreenSpot-v2, ScreenSpot-Pro и OSWorld-G, представляют собой ключевые эталоны для оценки методов привязки элементов графического интерфейса (GUI grounding). Эти наборы данных состоят из изображений экранов с аннотациями, определяющими местоположение и тип интерактивных элементов, таких как кнопки, текстовые поля и иконки. Использование стандартизированных наборов данных позволяет исследователям объективно сравнивать производительность различных алгоритмов, измерять прогресс в области и выявлять существующие ограничения. Размер и сложность наборов данных варьируются, что позволяет оценить алгоритмы в различных сценариях и условиях.
Наборы данных, такие как ScreenSpot, ScreenSpot-v2, ScreenSpot-Pro и OSWorld-G, являются критически важными инструментами для количественной оценки прогресса в области привязки графических пользовательских интерфейсов (GUI grounding). Они позволяют исследователям объективно измерять производительность различных методов, выявлять слабые места существующих подходов и сравнивать их эффективность по унифицированным метрикам. Использование стандартизированных наборов данных необходимо для обеспечения воспроизводимости результатов и для продвижения исследований в данной области, поскольку позволяет сравнивать новые алгоритмы с существующими решениями и отслеживать улучшения в производительности.
Развитие эталонных наборов данных для оценки методов привязки GUI, от ScreenSpot до ScreenSpot-Pro, отражает повышение сложности и реалистичности задач. ScreenSpot представлял собой начальный набор данных, содержащий изображения экранов с базовыми элементами интерфейса. ScreenSpot-v2 увеличил размер набора данных и разнообразие GUI. ScreenSpot-Pro значительно расширил сложность, включив в себя более реалистичные сценарии, такие как перекрывающиеся элементы, различные стили и более широкий спектр типов GUI-элементов, а также включил данные, полученные из реальных пользовательских сессий, что потребовало от моделей более надежной и точной работы в сложных условиях. Такая эволюция позволяет более точно оценивать способность моделей к обобщению и применимости в реальных приложениях.

Будущее Взаимодействия с GUI: К Бесшовной Автоматизации
Надежная привязка к графическому интерфейсу пользователя (GUI grounding) является ключевым элементом в создании интеллектуальных агентов, способных к автоматизации сложных задач. Эта технология предполагает, что агент не просто «видит» элементы интерфейса, но и понимает их функциональное назначение и взаимосвязи, подобно тому, как это делает человек. Без такой привязки автоматизация сводится к хрупким скриптам, чувствительным к малейшим изменениям в дизайне или расположении элементов. Разработка эффективных методов GUI grounding требует сочетания компьютерного зрения, обработки естественного языка и машинного обучения, чтобы агент мог надежно идентифицировать и интерпретировать различные компоненты интерфейса, даже в условиях сложной визуальной среды и изменчивых условий. Это позволяет агентам не просто имитировать действия пользователя, но и адаптироваться к новым ситуациям, самостоятельно решать возникающие проблемы и эффективно выполнять поставленные задачи.
Технологии надежного определения элементов графического интерфейса открывают значительные перспективы для улучшения доступности компьютерных систем для людей с ограниченными возможностями. Автоматизация взаимодействия с интерфейсом позволяет пользователям, испытывающим трудности с использованием мыши или клавиатуры, выполнять сложные задачи с помощью голосовых команд или альтернативных методов ввода. Например, слабовидящие пользователи смогут эффективно взаимодействовать с программами благодаря автоматическому озвучиванию элементов управления и динамическому описанию содержимого экрана. Данные технологии способны существенно расширить возможности для обучения, работы и социальной интеграции, предоставляя равный доступ к цифровому миру для всех категорий пользователей.
Перспективные исследования в области мультимодальной интеграции, механизмов внимания и разработки стандартизированных тестов производительности открывают путь к созданию принципиально новых интерфейсов взаимодействия человека и компьютера. Сочетание различных каналов ввода — зрения, речи, жестов — позволит системам более точно понимать намерения пользователя, а механизмы внимания помогут им фокусироваться на наиболее значимых элементах интерфейса. Акцент на разработке объективных критериев оценки, или бенчмарков, необходим для сравнения эффективности различных подходов и стимулирования дальнейшего прогресса в создании бесшовных и интуитивно понятных систем автоматизации, способных адаптироваться к индивидуальным потребностям каждого пользователя.
Исследование, представленное в данной работе, демонстрирует стремление к математической чистоте в области взаимодействия человека и компьютера. Авторы, разрабатывая Trifuse, фокусируются на достижении корректности и надежности системы GUI grounding посредством многомодального слияния. Подход, заключающийся в интеграции внимания, текстовой информации, полученной с помощью OCR, и описаний иконок, напоминает стремление к построению алгоритма, доказуемого в своей эффективности. Как однажды заметил Карл Фридрих Гаусс: «Если я знаю, что я ничего не знаю, то в этом я знаю что-то». Эта фраза отражает важность осознания ограничений существующих методов и стремления к более точным и надёжным решениям, что и реализовано в Trifuse, позволяющем добиться улучшения точности без необходимости использования GUI-специфичных данных для обучения.
Куда Дальше?
Без чёткого определения задачи, любое улучшение — лишь шум, маскирующий фундаментальную неопределённость. Представленная работа, хоть и демонстрирует прирост точности в задаче привязки GUI-элементов, лишь косвенно касается истинной проблемы: недостаточной формализации самого понятия «понимание» в контексте взаимодействия человека и компьютера. До тех пор, пока не будет доказано, что система действительно понимает смысл действия пользователя, а не просто сопоставляет визуальные и текстовые паттерны, все улучшения останутся эмпирическими, а не теоретически обоснованными.
Особенно остро стоит вопрос о переносимости. Доказательство устойчивости модели к вариациям в дизайне GUI, шрифтах и языках требует строгой математической формализации. Использование данных, не специфичных для GUI, — шаг в верном направлении, но само по себе не гарантирует обобщающую способность. Необходимо разработать метрики, позволяющие оценивать не просто точность, а надёжность системы в любых условиях.
В конечном счёте, истинная элегантность заключается в простоте и доказуемости. Недостаточно создать систему, которая «работает на тестах»; необходимо доказать её корректность и надёжность математически. Будущие исследования должны быть направлены не на увеличение объёма данных или сложности модели, а на разработку формальных методов верификации и валидации, гарантирующих её безошибочную работу.
Оригинал статьи: https://arxiv.org/pdf/2602.06351.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Макросъемка
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Российский рынок: между ставкой ЦБ, геополитикой и отчетами компаний (25.03.2026 17:32)
- От фотографий к фильмам: полное руководство по переходу на видеосъемку
- Три простых изменения в светлой комнате, чтобы создать свой объект съемки.
- Motorola Edge 30 Pro ОБЗОР: скоростная съёмка видео, скоростная зарядка, беспроводная зарядка
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
2026-02-09 23:04