Автор: Денис Аветисян
Новый подход к поиску изображений использует формальную верификацию и «визуальные рутины», чтобы обеспечить более надежные и понятные результаты.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
В статье представлен метод проверки изображений на соответствие запросам на естественном языке с использованием сгенерированного кода и графовых моделей.
Несмотря на значительный прогресс в области информационного поиска, современные системы часто испытывают трудности с запросами, требующими анализа сложных взаимосвязей и точных ограничений. В работе ‘Visual Model Checking: Graph-Based Inference of Visual Routines for Image Retrieval’ предложен новый подход, объединяющий формальную верификацию и глубокое обучение для повышения надежности и интерпретируемости поиска по изображениям. Суть метода заключается в использовании графовых представлений и генерируемого кода для проверки соответствия визуального контента запросам на естественном языке. Способна ли данная методика преодолеть неоднозначность векторных представлений и обеспечить более прозрачный и достоверный процесс извлечения информации?
Пределы Традиционного Поиска Изображений
Современный поиск изображений в значительной степени опирается на метод извлечения, основанный на векторных представлениях — так называемые «embedding». Этот подход позволяет достигать приемлемых результатов при простых запросах, однако демонстрирует существенные ограничения в обработке сложных, многокомпонентных запросов. Суть метода заключается в сопоставлении векторных характеристик изображения с векторным представлением запроса, что эффективно при поиске визуально похожих изображений. Тем не менее, при необходимости найти изображение, удовлетворяющее нескольким условиям или требующее понимания взаимосвязей между объектами на картинке, точность поиска резко снижается. Несмотря на прогресс в области машинного обучения, существующие модели зачастую не способны уловить тонкие нюансы и логические связи, необходимые для адекватной интерпретации сложных запросов, что ограничивает возможности современного поиска изображений.
Существующие методы поиска изображений, основанные на сопоставлении векторных представлений, зачастую оказываются неспособными уловить сложные взаимосвязи между объектами и понимать композиционное построение сцены. Это приводит к тому, что даже при кажущейся схожести изображений, результаты поиска могут быть неточными или попросту нерелевантными запросу. Например, система может успешно находить изображения «красных автомобилей», но испытывать затруднения с запросом «красный автомобиль, припаркованный рядом с высоким зданием», не учитывая пространственное расположение и контекст. Такая неспособность к пониманию сложных отношений ограничивает эффективность поиска и подчеркивает необходимость разработки более интеллектуальных систем, способных к логическому анализу и интерпретации визуальной информации.
Непосредственное сопоставление векторных представлений, лежащее в основе современных поисковых систем по изображениям, демонстрирует фундаментальные ограничения в понимании сложных сцен. Векторы, хотя и эффективны для улавливания общих визуальных признаков, не способны выразить отношения между объектами или их композиционное взаимодействие. Это приводит к тому, что поисковые запросы, требующие анализа контекста или логических связей, часто дают неточные или нерелевантные результаты. В связи с этим, всё большее внимание уделяется разработке подходов, основанных на символическом представлении изображений и структурированном моделировании знаний, позволяющих машине «понимать» содержание изображения, а не просто сопоставлять векторы признаков. Такой переход к более осмысленному анализу открывает перспективы для создания поисковых систем, способных отвечать на сложные запросы и понимать истинный смысл визуальной информации.

Формализация Запросов: От Языка к Логике
Система преобразует запрос, сформулированный на естественном языке, в спецификацию, представляющую собой граф логических троек. Каждая тройка состоит из субъекта, предиката и объекта, что позволяет четко определить отношения между элементами желаемого изображения. Например, запрос «красное яблоко на столе» может быть представлен как тройки: (яблоко, имеет_цвет, красный), (яблоко, находится_на, стол). Этот формальный подход обеспечивает структурированное представление семантики запроса, необходимое для точного выполнения и последующей генерации изображения.
Формальное представление запроса позволяет явно определить взаимосвязи между объектами и их атрибутами в желаемом изображении. Это достигается путем использования логических триплетов, где каждый триплет описывает связь между субъектом, предикатом и объектом. Например, триплет может описывать, что «объект является частью объекта», или что «объект имеет атрибут». Четкое определение этих связей позволяет системе точно интерпретировать запрос пользователя, не полагаясь на неявные предположения или статистические вероятности, и формировать детализированное описание желаемого изображения, включающее не только сами объекты, но и их пространственные и атрибутивные характеристики. Субъект \rightarrow Предикат \rightarrow Объект — типичная структура логического триплета.
Переход от простого сопоставления ключевых слов к формализации запросов позволяет добиться более точного и устойчивого понимания намерения пользователя. Традиционные системы, основанные на поиске по ключевым словам, часто дают нерелевантные результаты из-за неоднозначности языка и отсутствия контекста. Формализация запроса, напротив, позволяет явно определить отношения между объектами и их атрибутами, что снижает вероятность ошибок и повышает точность интерпретации. Это особенно важно для сложных запросов, где значение слов зависит от контекста и взаимосвязей между элементами описания.
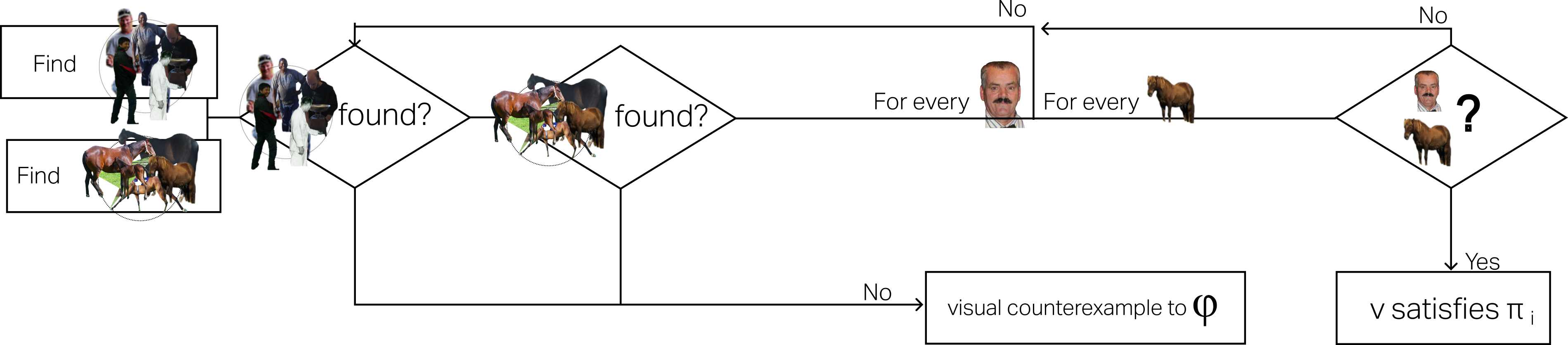
Верификация Визуального Контента с Помощью Визуальных Рутин
Визуальные рутины представляют собой программы, разработанные на языке Python и опирающиеся на визуальную грамматику для извлечения структурированной информации из изображений. Они функционируют путем анализа визуальных элементов и их взаимосвязей, абстрагируясь от низкоуровневых пиксельных данных и формируя представление об объектах и их расположении. Этот процесс позволяет преобразовывать изображения в структурированные данные, пригодные для логического анализа и сопоставления с заданными критериями. Визуальная грамматика определяет правила и шаблоны, используемые для идентификации и интерпретации визуальных элементов, обеспечивая согласованный и предсказуемый способ обработки изображений.
Визуальные рутины осуществляют проверку соответствия изображения ограничениям, заданным в логических тройках, посредством применения методов оптического распознавания текста (OCR) и композиционного рассуждения. OCR позволяет извлекать текстовую информацию из изображения, а композиционное рассуждение — анализировать взаимосвязи между различными элементами изображения и извлеченным текстом. Этот процесс включает в себя декомпозицию сложного запроса на более простые компоненты, которые затем проверяются на соответствие визуальным признакам, представленным в изображении. Результаты этих проверок объединяются для определения общего соответствия изображения заданным ограничениям.
Мировая модель, формируемая на основе запроса, предоставляет необходимый контекст для интерпретации содержимого изображения и оценки результатов работы визуальной рутины. Данная модель содержит информацию об объектах, их атрибутах и взаимосвязях, ожидаемых в соответствии с запросом пользователя. Она позволяет определить, какие элементы изображения релевантны для ответа на запрос, и как их следует интерпретировать. Без мировой модели, визуальная рутина не может однозначно определить, соответствует ли изображение заданным критериям, поскольку отсутствует понимание контекста и ожидаемого содержания. Фактически, мировая модель служит своего рода «знанием о мире», которое позволяет правильно анализировать визуальную информацию.
OWL-V2 предоставляет инфраструктуру для разработки и проверки визуальных рутин, предназначенных для анализа изображений. Данная платформа позволяет создавать скрипты на Python, использующие визуальную грамматику и логические тройки для определения критериев соответствия изображения заданным условиям. В OWL-V2 реализованы инструменты для автоматической верификации этих рутин, включая тестирование их корректности и эффективности на различных наборах данных. Платформа также обеспечивает интеграцию с другими компонентами системы, такими как модуль распознавания текста и движок логического вывода, что позволяет создавать сложные сценарии анализа визуального контента.

Улучшение Ранжирования Поиска и Перспективы Развития
Оценка релевантности каждого изображения поисковому запросу формируется на основе пропорции успешно выполненных визуальных рутин. Данный подход предполагает, что каждое изображение анализируется с точки зрения соответствия определенным визуальным шаблонам или последовательностям действий, необходимым для ответа на запрос. Чем больше визуальных рутин успешно «проходит» изображение, тем выше его оценка релевантности. По сути, система оценивает, насколько полно и точно изображение соответствует ожидаемым визуальным характеристикам, заданным запросом пользователя. Это позволяет не просто находить изображения, содержащие ключевые слова, а оценивать их фактическое соответствие смыслу запроса, обеспечивая более точные и полезные результаты поиска.
Система повторной ранжировки изображений использует полученную оценку релевантности, основанную на успешном выполнении визуальных рутин, для оптимизации порядка выдачи в поисковых результатах. Вместо простого соответствия ключевым словам, этот подход позволяет более точно определить, насколько изображение соответствует запросу пользователя, и, следовательно, отображать наиболее подходящие изображения в верхней части списка. Такая перестановка результатов, основанная на оценке удовлетворенности визуальных рутин, позволяет значительно повысить удобство использования поисковой системы и эффективность поиска нужной информации, обеспечивая более интуитивно понятный и релевантный опыт для пользователя.
Проверка предложенного подхода проводилась на широко известном наборе данных MS-COCO, что позволило оценить его эффективность в реальных условиях. Результаты показали, что разработанный метод демонстрирует производительность, сопоставимую с самыми современными алгоритмами поиска изображений. Особенно заметно превосходство проявляется при работе с подмножеством COCO-Hard, которое включает в себя наиболее сложные и неоднозначные изображения, требующие глубокого понимания контекста. Это указывает на то, что предложенный метод способен эффективно справляться с задачами, представляющими значительную сложность для существующих систем поиска.
Исследования показали, что комбинирование предложенного метода оценки изображений с традиционными методами, основанными на векторных представлениях (embedding), приводит к значительному повышению эффективности поиска в большинстве сценариев. Такой гибридный подход позволяет использовать преимущества обеих систем: точность и детализация оценки визуальных рутин, а также способность векторных представлений к обобщению и быстрому сравнению. В результате, система не только лучше определяет релевантность изображения запросу, но и демонстрирует более стабильные результаты в различных условиях, обеспечивая более точный и полный поиск изображений для пользователя. Практическая реализация этого подхода открывает возможности для создания более интеллектуальных систем поиска, способных понимать не только семантику изображения, но и его визуальные особенности.
Предложенный подход открывает новые возможности для углубленного понимания изображений и более точного поиска необходимого контента. Вместо простого сопоставления ключевых слов, система анализирует визуальные закономерности и оценивает, насколько полно изображение соответствует запросу, что позволяет выходить за рамки поверхностного анализа. Благодаря этому, поиск становится более интуитивным и эффективным, предоставляя пользователю именно те изображения, которые наиболее релевантны его потребностям. Возможность оценивать степень «удовлетворенности» визуальных рутин позволяет системе не просто находить изображения, содержащие определенные объекты, но и понимать их контекст и взаимосвязи, открывая путь к созданию поисковых систем нового поколения, способных к более сложному и осмысленному анализу визуальной информации.
Представленное исследование демонстрирует, что надежность поиска по изображениям может быть значительно повышена за счет применения формальной верификации. Подход, основанный на проверке моделей и генерации визуальных рутин, позволяет убедиться в соответствии содержимого изображения запросу на естественном языке. Если система держится на костылях, значит, мы переусложнили её, и данная работа предлагает элегантную альтернативу традиционным методам, основанным на эмбеддингах. Блез Паскаль однажды сказал: «Всякое великое дело начинается с простоты». Эта простота и ясность структуры, где поведение системы определяется её компонентами, особенно заметна в предлагаемом подходе к визуальному поиску.
Куда Далее?
Представленный подход, опираясь на формальную верификацию визуальных рутин, несомненно, открывает новые горизонты в области поиска изображений. Однако, следует признать, что кажущаяся элегантность формализации неизбежно наталкивается на сложность реального мира. Каждая оптимизация, каждое уточнение визуальной рутины, порождает новые точки напряжения, новые области, требующие проверки и адаптации. Архитектура системы определяется её поведением во времени, и совершенствование одной части не гарантирует стабильности целого.
Будущие исследования, вероятно, будут сосредоточены на преодолении разрыва между строгостью формальной логики и нечёткостью естественного языка. Необходимо разработать более гибкие механизмы представления знаний, способные учитывать контекст и неоднозначность запросов. Кроме того, представляется важным исследовать возможности автоматической генерации и верификации визуальных рутин, минимизируя ручной труд и повышая масштабируемость системы.
В конечном итоге, успех данного направления зависит не только от технических инноваций, но и от философского осмысления самой задачи поиска. Действительно ли поиск изображения — это поиск точного соответствия запросу, или это процесс интерпретации и построения смысловых связей? Ответ на этот вопрос определит вектор развития исследований в ближайшем будущем.
Оригинал статьи: https://arxiv.org/pdf/2602.17386.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Неважно, на что вы фотографируете!
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Лучшие смартфоны. Что купить в апреле 2026.
- Infinix Note 40 Pro+ выставлен на обзор
- TCL NxtPaper 70 Pro ОБЗОР: объёмный накопитель, удобный сенсор отпечатков, большой аккумулятор
- Что такое ISO в фотоаппарате
- Данные и интеллект: новый взгляд на анализ информации
- Технологии и вера: новый взгляд на инклюзивный дизайн
2026-02-22 02:06