Автор: Денис Аветисян
Новый подход к объединению изображений и текста позволяет моделям лучше понимать мир вокруг нас.
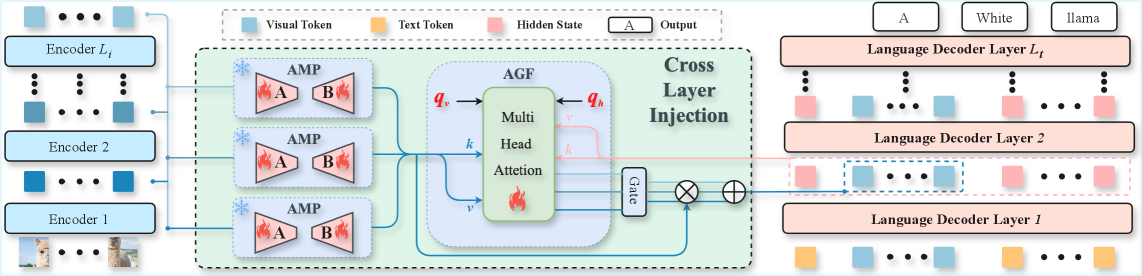
Предложена методика динамической кросс-слойной инъекции для глубокого слияния визуальных и языковых признаков, повышающая эффективность мультимодального анализа.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Несмотря на успехи моделей, объединяющих зрение и язык, часто наблюдается узкое место, обусловленное асимметричной связью между визуальным энкодером и большой языковой моделью. В статье ‘From One-to-One to Many-to-Many: Dynamic Cross-Layer Injection for Deep Vision-Language Fusion’ предложен новый фреймворк — Cross-Layer Injection (CLI), обеспечивающий динамическое и адаптивное слияние иерархических визуальных признаков. CLI позволяет языковой модели получать доступ к полному спектру визуальной информации, что значительно улучшает мультимодальное рассуждение и производительность. Способно ли данное решение открыть новые горизонты в понимании сложных визуальных сцен и контекстуализации информации?
Преодолевая Границы: Ограничения Существующих Подходов
Современные модели, объединяющие зрение и язык, зачастую сталкиваются с ограничениями из-за жесткого сопоставления слоев при обработке визуальной информации. Такой подход, при котором слои, отвечающие за обработку изображения, напрямую связываются с языковыми слоями, не позволяет модели динамически адаптироваться к различным визуальным сценариям и эффективно выделять наиболее релевантные признаки. Жесткая структура препятствует глубокому взаимопроникновению визуальных и лингвистических представлений, что негативно сказывается на способности модели к комплексному мультимодальному рассуждению и затрудняет выполнение задач, требующих понимания контекста и нюансов визуальной информации. В результате, способность модели генерировать осмысленные и точные ответы на вопросы, связанные с изображениями, существенно ограничивается.
Существующие методы объединения визуальной и языковой информации, такие как Shallow-Layer Injection (SLI) и DeepStack, хоть и позволяют производить начальное слияние данных, демонстрируют ограниченную способность к динамической приоритизации релевантных визуальных признаков. Эти подходы, как правило, обрабатывают все визуальные элементы одинаково, не учитывая, какие из них наиболее важны для конкретной задачи или вопроса. В результате, модели испытывают трудности в ситуациях, требующих тонкого мультимодального рассуждения, поскольку не могут эффективно фокусироваться на ключевых аспектах изображения. Отсутствие гибкости в выделении значимых визуальных деталей ограничивает их производительность и препятствует развитию более естественного и контекстуально-зависимого взаимодействия человека и машины.
Ограничения существующих моделей, объединяющих зрение и язык, особенно заметны при решении задач, требующих тонкого мультимодального рассуждения и практического ведения диалога. Неспособность динамически оценивать релевантность визуальных признаков приводит к снижению эффективности при анализе сложных сцен или интерпретации неоднозначных запросов. Например, модель может испытывать затруднения при ответе на вопрос, требующий понимания скрытого смысла изображения или сопоставления визуальной информации с контекстом беседы. В результате, подобные системы часто демонстрируют ограниченные возможности в реальных сценариях, где требуется не просто распознавание объектов, но и глубокое понимание взаимосвязей между визуальным контентом и лингвистическими данными, что препятствует созданию по-настоящему интеллектуальных и адаптивных систем.
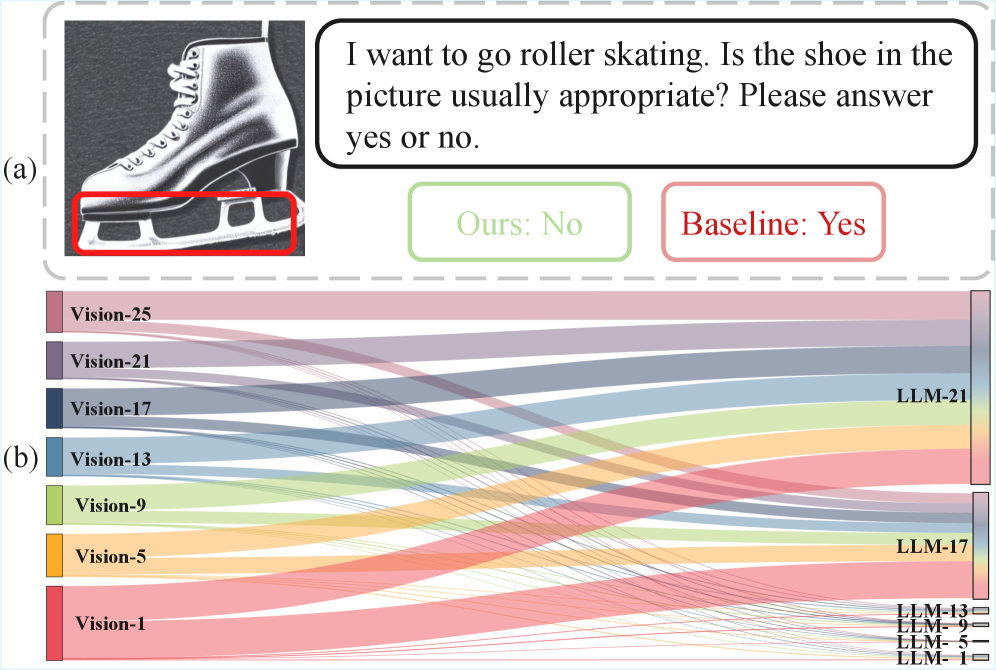
Кросс-слойная Инъекция: Рамка Динамического Слияния
Механизм кросс-слойной инъекции (CLI) позволяет языковой модели получать доступ и использовать визуальные признаки, извлеченные из различных слоев визуального энкодера. В отличие от традиционных подходов, использующих только признаки из финального слоя, CLI интегрирует информацию с нескольких уровней абстракции. Это способствует формированию более богатых и детализированных представлений, поскольку признаки из ранних слоев содержат низкоуровневую информацию (например, края, текстуры), а признаки из более поздних слоев — высокоуровневые семантические представления. Использование признаков с разных слоев позволяет модели учитывать как детали, так и общую структуру изображения, что потенциально улучшает качество генерации текста и понимания визуального контента.
В основе Cross-Layer Injection (CLI) лежат два ключевых компонента — Adaptive Multi-Projection (AMP) и Adaptive Gating Fusion (AGF), которые совместно обеспечивают селективную интеграцию визуальной информации. AMP использует технологию Low-Rank Adaptation (LoRA) для эффективной адаптации многоуровневых визуальных признаков к языковому пространству, минимизируя вычислительные затраты. AGF, в свою очередь, выступает в роли интеллектуального регулятора, динамически контролируя поток информации от различных слоев визуального энкодера к языковой модели. Этот механизм позволяет модели фокусироваться на наиболее релевантных визуальных аспектах, игнорируя несущественные детали и, таким образом, повышая качество генерируемого текста.
Адаптивная мульти-проекция (AMP) использует метод Low-Rank Adaptation (LoRA) для эффективной адаптации многоуровневых визуальных признаков к языковому пространству. LoRA позволяет снизить вычислительные затраты и количество обучаемых параметров за счет введения низкоранговых матриц, модифицирующих веса предобученной модели. Одновременно с этим, адаптивное управление потоком информации осуществляется посредством адаптивного гейтинга (AGF), который динамически определяет значимость каждого визуального признака, способствуя интеграции только релевантной информации в языковую модель. AGF использует гейты, обученные определять, какие визуальные признаки наиболее важны для конкретной входной последовательности, тем самым улучшая качество и точность модели.

Эмпирическая Проверка: Оценка Производительности CLI
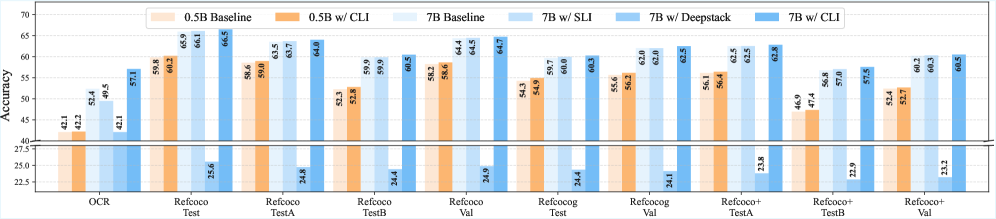
Оценка CLI проводилась с использованием архитектур LLaVA-OneVision и LLaVA-1.5, что позволило продемонстрировать её универсальность и способность к адаптации к различным визуальным языковым моделям (VLM). Результаты показали, что CLI успешно функционирует и обеспечивает стабильную производительность вне зависимости от конкретной базовой архитектуры VLM, подтверждая её применимость в широком спектре систем, использующих мультимодальные модели. Это указывает на то, что CLI не привязана к специфическим особенностям отдельных VLM и может быть легко интегрирована в существующие и будущие мультимодальные решения.
В ходе оценки производительности CLI на задаче многомодального рассуждения (MME) было зафиксировано значительное превосходство над базовыми методами. В частности, при использовании архитектуры LLaVA-OV-7B, CLI продемонстрировала прирост производительности в 3.3% по сравнению с альтернативными подходами. Данный результат подтверждает повышенную способность CLI эффективно решать сложные задачи, требующие интеграции и анализа информации из различных модальностей.
Результаты тестирования CLI на наборах данных LLaVA-in-the-Wild и OCR-Bench демонстрируют значительное улучшение производительности по сравнению с базовыми моделями. На LLaVA-in-the-Wild наблюдается прирост в 6.5% при использовании LLaVA-OV-7B, а на OCR-Bench — 4.7% с той же архитектурой. Эти показатели свидетельствуют о потенциале CLI для использования в практических приложениях, требующих обработки реальных изображений и оптического распознавания символов, что делает его перспективным компонентом для систем разговорного искусственного интеллекта.
К Адаптивному Мультимодальному Интеллекту: Взгляд в Будущее
Способность CLIP к динамическому объединению визуальной информации открывает новую эру адаптивности в области визуально-языковых моделей (VLM). В отличие от традиционных подходов, основанных на жестких, заранее определенных соответствиях между визуальными и текстовыми данными, данная методика позволяет модели гибко адаптироваться к различным типам визуального контента и контексту. Вместо того, чтобы полагаться на фиксированные шаблоны, модель способна извлекать наиболее релевантную информацию из изображения и эффективно интегрировать ее с текстовым запросом, что значительно повышает точность и надежность работы в сложных сценариях. Такая динамическая интеграция позволяет VLM лучше понимать визуальные нюансы и контекст, что особенно важно для задач, требующих глубокого анализа и рассуждений.
Исследования показывают, что внедрение динамического объединения визуальной информации значительно повышает эффективность визуальных языковых моделей в задачах, требующих сложного логического мышления. В частности, наблюдается существенное улучшение результатов в областях, таких как ответы на вопросы по изображениям и понимание сцен, достигающее в среднем +7.5% для модели LLaVA-1.5-7B и +8.6% для LLaVA-1.5. Данный прирост производительности указывает на способность системы более эффективно обрабатывать и интерпретировать визуальные данные, что позволяет ей решать более сложные задачи и приближает ее к человеческому уровню понимания.
Концепция динамической интеграции визуальной и лингвистической информации, реализуемая через CLI, открывает перспективы создания искусственного интеллекта, способного к более тонкому и осмысленному взаимодействию с окружающим миром. В отличие от традиционных систем, где визуальные данные обрабатываются по жестким шаблонам, CLI позволяет модели адаптировать способ восприятия изображения в зависимости от контекста и запроса. Такой подход имитирует когнитивные процессы человека, где понимание визуальной информации тесно связано с языком и предыдущим опытом. В результате, системы, использующие CLI, демонстрируют повышенную способность к решению сложных задач, требующих не просто распознавания объектов, но и понимания их взаимосвязей и контекста, приближая искусственный интеллект к уровню человеческого понимания.

Исследование демонстрирует стремление к усложнению архитектур ради небольшого прироста производительности. Предложенный метод динамической кросс-слойной инъекции (CLI) — это, по сути, ещё один способ заставить модель «видеть» больше связей, что неизбежно приведёт к увеличению вычислительной нагрузки и, как следствие, к новым трудностям в эксплуатации. Как точно подметила Фэй-Фэй Ли: «Искусственный интеллект должен служить людям, а не наоборот». Данная работа, несмотря на техническую изысканность, лишь подтверждает закономерность: стремление к глубокому слиянию визуальных и языковых представлений неизбежно порождает новые «костыли», требующие постоянной поддержки и оптимизации. В конечном итоге, архитектура неизбежно превратится в анекдот, когда продшн найдёт способ сломать даже самую элегантную теорию.
Что дальше?
Предложенная в данной работе схема динамической кросс-слойной инъекции (CLI) несомненно, представляет собой элегантный способ заставить визуальные и языковые представления «разговаривать» друг с другом. Однако, как показывает опыт, любая абстракция рано или поздно встретится с жестокой реальностью продакшена. Вопрос не в том, улучшит ли CLI показатели на текущих бенчмарках, а в том, как эта архитектура поведет себя при столкновении с данными, которые не укладываются в аккуратные датасеты. Неизбежно возникнут случаи, когда адаптивные гейты будут пропускать шум, а иерархическое слияние обернется каскадом ошибок.
Более того, успех CLI, как и любого подобного решения, напрямую зависит от масштабируемости. С ростом моделей и объемов данных вычислительные затраты на динамическую инъекцию могут стать непомерными. Поэтому, в ближайшем будущем, вероятно, наблюдается смещение фокуса на поиск более эффективных методов слияния, возможно, жертвующих частью гибкости ради скорости и экономии ресурсов. Всё, что можно задеплоить — однажды упадёт, и CLI не станет исключением.
В конечном счёте, настоящая задача заключается не в создании более сложных архитектур, а в понимании того, как визуальные и языковые представления действительно взаимодействуют в человеческом мозгу. Пока мы продолжаем строить красивые, но хрупкие модели, проблема мультимодального рассуждения останется открытой. И, конечно, каждая «революционная» технология станет новым видом техдолга.
Оригинал статьи: https://arxiv.org/pdf/2601.10710.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Лучшие смартфоны. Что купить в марте 2026.
- Новые смартфоны. Что купить в марте 2026.
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Неважно, на что вы фотографируете!
- Российский рынок: Нефть, геополитика и лидерство «Сбербанка» (11.03.2026 13:32)
- Realme 9 ОБЗОР: чёткое изображение, лёгкий, высокая автономность
- Infinix Note 60 Ultra ОБЗОР: скоростная зарядка, объёмный накопитель, отличная камера
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
2026-01-19 03:25