Автор: Денис Аветисян
Новая модель искусственного интеллекта способна реконструировать и редактировать 3D-сцены, используя процедурную генерацию и визуальное подтверждение.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"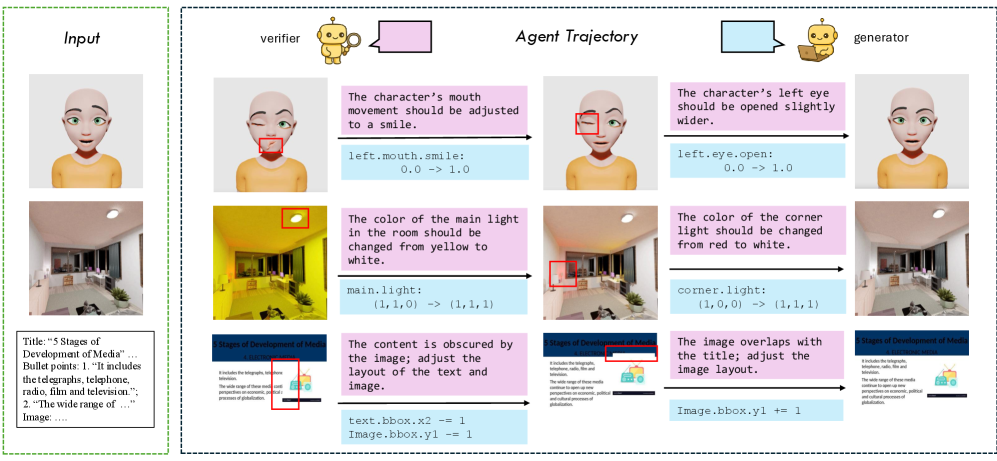
Представлен VIGA — агент на основе большой языковой модели, применяющий итеративное уточнение для реконструкции 3D-сцен и генерации кода.
Восстановление изображения как редактируемой графической программы остается сложной задачей компьютерного зрения, несмотря на успехи в области больших мультимодальных моделей. В работе ‘Vision-as-Inverse-Graphics Agent via Interleaved Multimodal Reasoning’ представлен агент VIGA, использующий итеративное чередование генерации кода, рендеринга и визуальной верификации для реконструкции и редактирования 3D-сцен. Предложенный подход демонстрирует значительное улучшение результатов в задачах процедурной генерации, превосходя существующие решения на BlenderGym и SlideBench. Сможет ли VIGA стать унифицированной платформой для оценки и развития возможностей различных фундаментальных мультимодальных моделей в контексте интерактивного графического моделирования?
Математическая Элегантность Виртуальных Миров: От Задачи к Решению
Создание трехмерных сцен традиционно представляет собой трудоемкий процесс, требующий от специалистов глубоких знаний и специализированных навыков. Моделирование объектов, текстурирование, настройка освещения и анимация — каждый из этих этапов может занять значительное время и ресурсы. В отличие от фотографии, где изображение фиксируется мгновенно, создание полноценной 3D-сцены требует ручной работы и точного управления каждым элементом. Это ограничивает возможности быстрого прототипирования и массового производства контента, а также предъявляет высокие требования к квалификации специалистов, что существенно увеличивает стоимость разработки. В результате, создание детализированных и реалистичных 3D-миров остается сложной задачей, требующей значительных инвестиций времени и ресурсов.
Идея “Видение как обратная графика” представляет собой давно существующую, но особенно привлекательную альтернативу традиционным, трудоемким методам создания трехмерного контента. Вместо ручного моделирования объектов и сцен, данная концепция стремится к автоматическому воссозданию виртуальных миров непосредственно из визуальной информации. Представьте, что компьютер, получив изображение, способен не просто его распознать, но и реконструировать всю сцену, включая геометрию, материалы и освещение, фактически “обращая” процесс рендеринга. Такой подход обещает радикально упростить процесс создания контента, делая его доступным для более широкого круга пользователей и открывая новые возможности для интерактивных приложений и виртуальной реальности.
Для реализации концепции «Зрение как обратная графика» необходима система, способная преобразовывать визуальную информацию в символьные, исполняемые инструкции. Эта система должна не просто распознавать объекты на изображении, но и понимать их свойства, взаимосвязи и физические характеристики, чтобы воссоздать полноценную 3D-сцену. Фактически, речь идет о создании «цифрового двойника» реального мира, где каждый элемент представлен в виде набора параметров и алгоритмов, позволяющих манипулировать им и интегрировать в виртуальную среду. Достижение этой цели требует объединения передовых методов компьютерного зрения, машинного обучения и алгоритмической геометрии, чтобы обеспечить точное и эффективное преобразование восприятия в исполняемый код, открывая новые возможности для автоматизированного создания контента и интерактивных приложений.
VIGA: Агент Процедурной Реконструкции Сцен
VIGA представляет собой программного агента, предназначенного для реконструкции сцен путем итеративной генерации и уточнения кода. В процессе работы, агент последовательно создает программный код, описывающий сцену, а затем выполняет его для получения визуального результата. Основываясь на анализе полученного изображения, VIGA вносит изменения в код, стремясь к более точному воссозданию исходной сцены. Этот цикл генерации, выполнения и уточнения повторяется до достижения желаемого уровня соответствия между реконструированной и исходной сценой. Таким образом, VIGA использует подход, основанный на постоянном совершенствовании кода посредством его непосредственного выполнения и оценки результатов.
В основе работы VIGA лежит метод “Анализ посредством синтеза”, предполагающий итеративное построение и исполнение кода, описывающего сцену. Результаты исполнения оцениваются с использованием метрик соответствия целевому изображению или описанию. Эта оценка служит сигналом для дальнейшей корректировки кода — параметров, структуры или логики — в процессе оптимизации. По сути, VIGA постоянно генерирует, проверяет и улучшает код сцены, пока не достигнет удовлетворительного результата, что позволяет эффективно исследовать пространство возможных конфигураций сцены, опираясь на фактическое исполнение и обратную связь.
Основой функционирования VIGA является замкнутая система, базирующаяся на непосредственном выполнении сгенерированного кода. Такой подход позволяет агенту эффективно исследовать пространство возможных конфигураций сцены, поскольку каждая итерация включает в себя выполнение кода, оценку результатов и корректировку кода на основе этой оценки. Это обеспечивает систематический поиск оптимальной конфигурации, позволяя VIGA преодолевать сложность задачи реконструкции сцены за счет постоянной обратной связи и уточнения на основе фактических результатов выполнения кода, а не только на основе статического анализа или предположений.
В основе работы VIGA лежит использование предварительно обученных мультимодальных моделей (Foundation VLMs) для интерпретации визуальных данных и последующего формирования кода. Эти модели позволяют VIGA анализировать входные изображения и извлекать из них семантическую информацию о сценах. Полученные данные используются для генерации программного кода, описывающего геометрию, текстуры и другие характеристики сцены. В процессе итеративной реконструкции, Foundation VLMs служат ключевым звеном, связывающим визуальное восприятие с генерацией и уточнением кода, обеспечивая соответствие между реконструируемой сценой и исходным визуальным входом.
Архитектура и Ключевые Компоненты VIGA
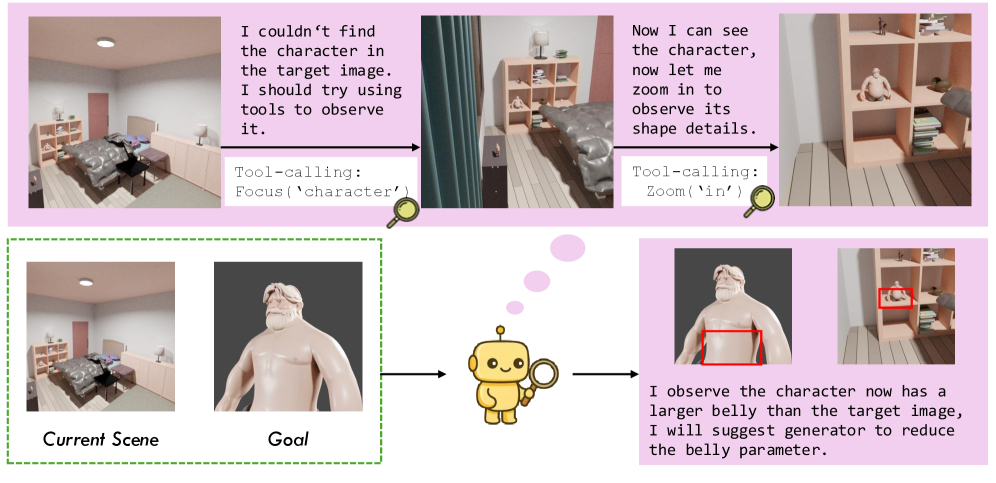
Генератор VIGA отвечает за синтез кода, необходимого для создания или модификации сцен. Этот код может включать инструкции для добавления объектов, изменения их свойств или выполнения других действий, влияющих на визуальное представление сцены. После генерации кода, его выполняет система рендеринга, результатом которой является новая или измененная сцена. Компонент Верификатор (Verifier) оценивает результат, сравнивая его с заданными критериями или ожидаемыми результатами, и предоставляет обратную связь Генератору для итеративного улучшения процесса создания сцен. Этот цикл генерации и верификации позволяет VIGA автоматически создавать и редактировать сцены в соответствии с заданными параметрами.
Оба основных компонента VIGA — Генератор и Верификатор — используют единую Библиотеку Навыков (Skill Library). Эта библиотека представляет собой набор инструментов, обеспечивающих выполнение кода и инспекцию сцен. Инструменты включают в себя функции для анализа синтаксиса и семантики кода, а также для визуальной оценки изменений в сцене. Библиотека Навыков предоставляет унифицированный интерфейс для взаимодействия с различными типами кода и сцен, упрощая процесс создания и проверки. Функциональность библиотеки постоянно расширяется для поддержки новых типов задач и форматов данных, обеспечивая гибкость и масштабируемость системы.
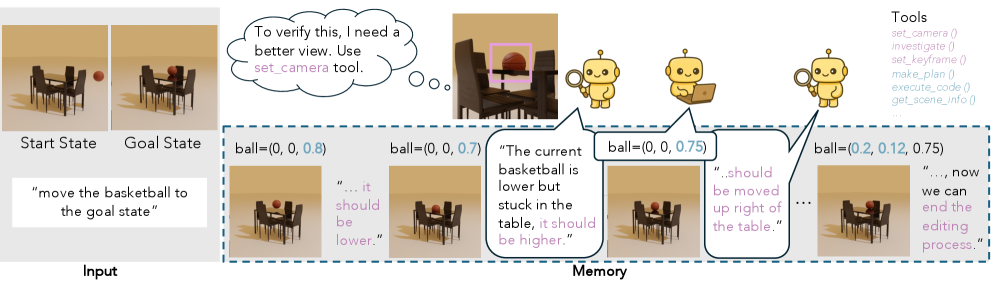
Память контекста в VIGA представляет собой динамически обновляемый архив, хранящий как предыдущие версии сгенерированного кода, так и соответствующие отрендеренные сцены. Это позволяет системе учитывать историю своих действий при планировании дальнейших шагов, что критически важно для задач, требующих долгосрочного планирования и последовательного достижения целей. Сохранение как кода, так и визуальных результатов обеспечивает возможность анализа причинно-следственных связей между действиями и их последствиями, улучшая способность системы к самокоррекции и оптимизации стратегий генерации сцен.
В основе работы VIGA лежит переплетенное мультимодальное рассуждение, объединяющее визуальное восприятие и символьное рассуждение над кодом. Это означает, что система способна анализировать как визуальные данные, полученные из сцены, так и структуру и логику программного кода, используемого для ее создания. Процесс предполагает итеративный обмен информацией между этими двумя модальностями: визуальный анализ может направлять процесс генерации или модификации кода, а анализ кода, в свою очередь, позволяет предсказывать и оценивать изменения в визуальном представлении. Такое взаимодействие позволяет VIGA эффективно решать задачи, требующие понимания взаимосвязи между кодом и его визуальным результатом, например, автоматическую генерацию и редактирование сцен на основе текстовых инструкций или визуальных примеров.
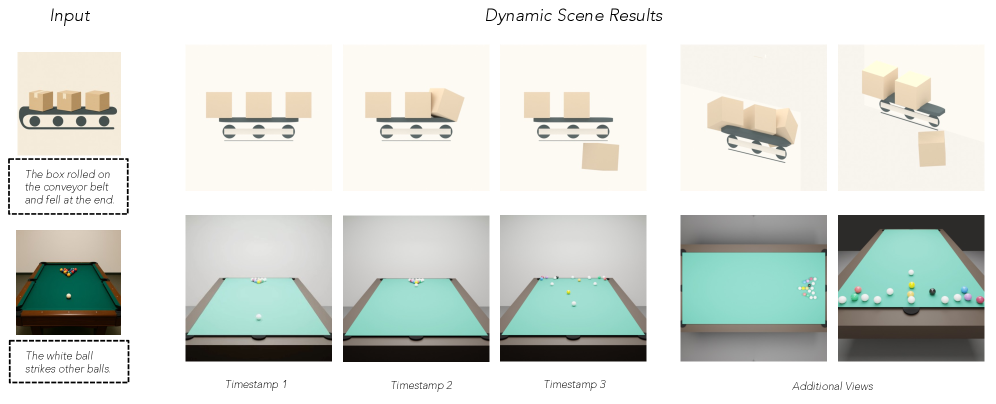
Оценка VIGA: Производительность и Возможности
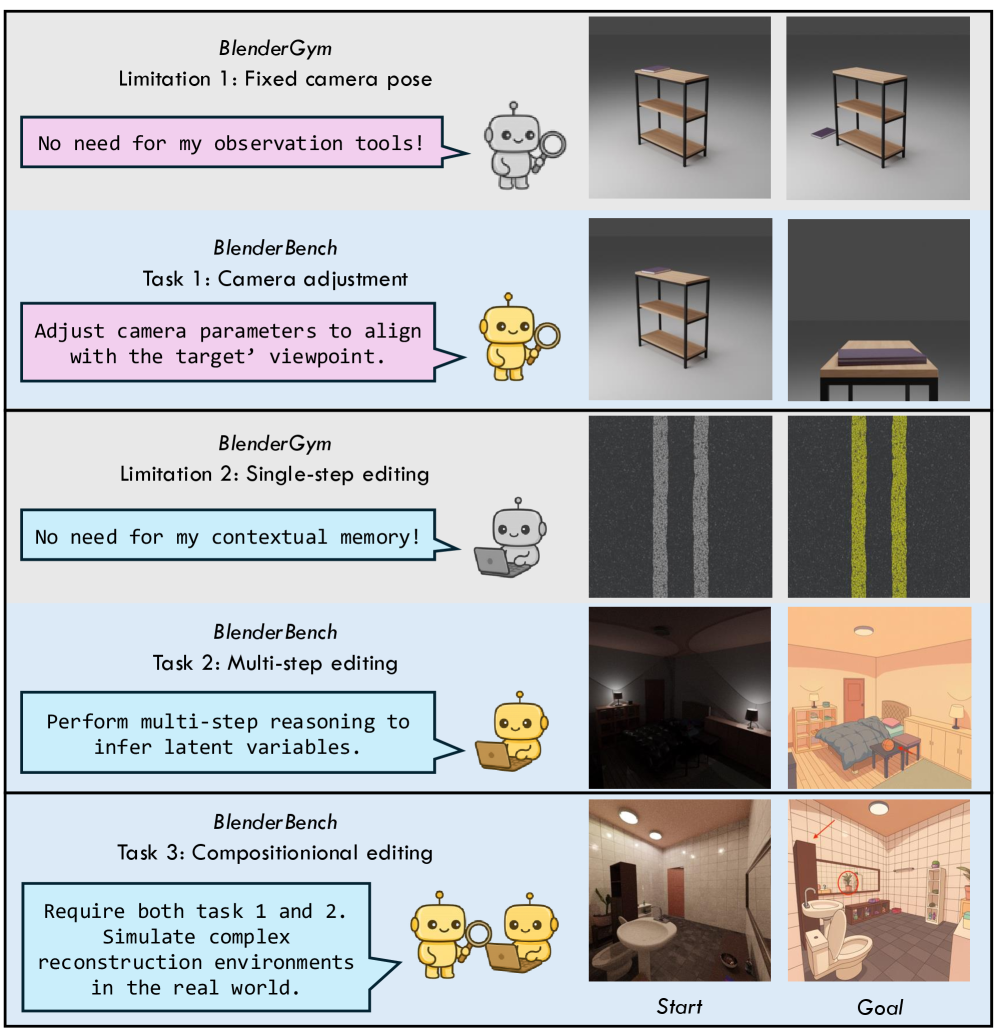
Для всесторонней оценки возможностей VIGA использовался набор бенчмарков, отличающихся возрастающей сложностью. Начальный этап тестирования проходил на BlenderGym и SlideBench, представляющих собой относительно простые сценарии для проверки базовых функций и скорости работы системы. Однако, ключевым этапом стало тестирование на BlenderBench — комплексном бенчмарке, требующем от VIGA решения сложных задач по процедурной генерации сцен, манипулированию объектами и композиции изображения. Использование именно таких бенчмарков позволило точно оценить способность VIGA справляться с реальными задачами в области создания 3D-контента и продемонстрировать существенные улучшения по сравнению с существующими решениями.
Для оценки качества генерируемых изображений и соответствия запросам пользователя применялись метрики, позволяющие количественно измерить как визуальную достоверность, так и семантическую согласованность. Photometric Loss оценивает разницу между сгенерированным изображением и целевым, отражая степень реалистичности и точности цветопередачи. В свою очередь, Negative-CLIP Score измеряет степень соответствия между текстом запроса и визуальным содержанием изображения, определяя, насколько хорошо сгенерированное изображение отражает задуманную концепцию. Комбинация этих метрик позволяет комплексно оценить производительность системы, выявляя не только визуальные дефекты, но и смысловые несоответствия, что критически важно для создания убедительного и релевантного контента.
В ходе оценки на бенчмарке BlenderBench, система VIGA продемонстрировала впечатляющий прирост в 124.70% в среднем, что свидетельствует о значительном прогрессе в области процедурной генерации сцен. Этот результат указывает на способность VIGA эффективно автоматизировать сложные процессы создания трехмерного контента, превосходя существующие подходы в создании детализированных и реалистичных виртуальных сред. Повышение производительности особенно заметно в задачах, требующих генерации сложных сцен с множеством объектов и текстур, что подтверждает потенциал VIGA для ускорения и оптимизации рабочего процесса в сфере 3D-дизайна и разработки.
В ходе тестирования на бенчмарке SlideBench система VIGA продемонстрировала пятикратное увеличение общего результата при использовании модели Qwen. Этот значительный прогресс указывает на высокую эффективность VIGA в решении задач, связанных с манипулированием изображениями и сценами, требующих точного следования инструкциям и понимания семантического содержания. Улучшение производительности на SlideBench подтверждает способность VIGA к выполнению сложных визуальных операций и свидетельствует о перспективности подхода, основанного на использовании кодирующих агентов для автоматизации процесса создания и редактирования 3D-контента.
В ходе тестирования на платформе BlenderGym, система VIGA продемонстрировала значительный прогресс в задачах, связанных с материалами, достигнув улучшения на 67.90%. Этот результат был получен благодаря использованию модели GPT-4o, которая позволила более эффективно управлять параметрами материалов и текстур в трехмерных сценах. Подобное повышение производительности указывает на способность VIGA автоматизировать сложные процессы создания и редактирования материалов, что открывает новые возможности для ускорения и упрощения рабочих процессов в области 3D-графики и дизайна.
Исследования показали, что VIGA, в сочетании с моделью Qwen, демонстрирует впечатляющий прирост в 251.56% по показателю VLM (Visual Language Model) в задаче 3 BlenderBench, посвященной композиционной правке. Это означает, что система значительно превосходит существующие подходы в понимании и реализации сложных инструкций по изменению сцены, касающихся компоновки объектов и их взаиморасположения. Улучшение VLM свидетельствует о способности VIGA не только генерировать визуально правдоподобные изображения, но и точно интерпретировать текстовые запросы, касающиеся композиции, что открывает новые возможности для автоматизированного создания и редактирования 3D-контента.
Исследования демонстрируют, что VIGA успешно справляется со сложными манипуляциями в 3D-сценах, включая точную настройку параметров камеры и композиционное редактирование. Система способна не только изменять положение и ориентацию камеры для достижения желаемого ракурса, но и перекомпоновывать объекты в сцене, изменяя их расположение и взаимосвязи для создания визуально гармоничных и семантически корректных изображений. Такая способность к комплексному управлению сценой открывает новые возможности для автоматизации процесса создания 3D-контента, позволяя генерировать сложные визуальные решения с высокой степенью детализации и художественной выразительности. Подобные достижения подтверждают потенциал кодирующих агентов в сфере автоматизированного 3D-моделирования и дизайна.
Успех VIGA демонстрирует перспективность применения кодирующих агентов для автоматизации создания 3D-контента. Данная система, способная генерировать и редактировать сложные сцены посредством программного кода, открывает новые возможности для автоматизации трудоемких процессов в компьютерной графике. Результаты, полученные на бенчмарках BlenderGym, SlideBench и BlenderBench, показывают значительное улучшение качества и семантической согласованности генерируемых изображений, а также способность VIGA эффективно выполнять сложные манипуляции со сценами, включая настройку камеры и композиционное редактирование. Это свидетельствует о том, что кодирующие агенты могут стать мощным инструментом для дизайнеров и художников, позволяя им автоматизировать рутинные задачи и сосредоточиться на творческих аспектах своей работы, а также существенно ускорить процесс создания 3D-контента.
Исследование демонстрирует стремление к математической чистоте в подходе к реконструкции 3D-сцен. VIGA, представленный в статье, не просто стремится «работать на тестах», но и использует итеративный процесс генерации кода и визуальной верификации для достижения высокой точности. Этот подход к процедурной генерации, основанный на принципах обратной графики, подчеркивает важность доказательства корректности алгоритма. Как однажды заметил Эндрю Ын: «Мы должны стремиться к созданию систем, которые не просто решают задачу, но и объясняют, почему они это делают». Эта цитата прекрасно иллюстрирует философию, лежащую в основе VIGA — стремление к прозрачности и обоснованности в процессе реконструкции 3D-мира.
Куда Ведет Этот Путь?
Без четкого определения задачи, любое решение — лишь шум, и представленная работа не является исключением. Хотя агент VIGA демонстрирует впечатляющие результаты в процедурной генерации, фундаментальный вопрос о критериях “корректности” реконструкции трехмерной сцены остается открытым. Достаточно ли визуального соответствия тестовому набору, или же требуется доказательная гарантия соответствия исходному, неизвестному распределению? Просто “работает на тестах” — недостаточное условие для истинного прогресса.
Следующим логичным шагом представляется разработка формальной метрики, позволяющей оценивать не просто визуальное сходство, а семантическую достоверность сгенерированной сцены. Необходимо исследовать возможность интеграции формальных методов верификации кода и процедурной генерации, чтобы обеспечить доказуемость результатов, а не полагаться на эмпирические наблюдения. Иначе, мы рискуем построить сложный аппарат, производящий лишь правдоподобные иллюзии.
Более того, представляется важным преодолеть зависимость от больших языковых моделей, чья внутренняя работа остается непрозрачной. Истинная элегантность алгоритма проявляется в его математической чистоте, а не в способности аппроксимировать неизвестные функции. В конечном счете, задача реконструкции трехмерной сцены — это задача логического вывода, требующая точных определений и формальных доказательств.
Оригинал статьи: https://arxiv.org/pdf/2601.11109.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Деформация сеток: новый подход на основе нейронных операторов
- Новые смартфоны. Что купить в марте 2026.
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Российский рынок акций: нефть, ставки и дивиденды: что ждет инвесторов в ближайшее время? (05.03.2026 16:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Лучшие смартфоны. Что купить в марте 2026.
- Oppo Reno15 ОБЗОР: отличная камера, много памяти, скоростная зарядка
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- vivo V70 ОБЗОР: современный дизайн, портретная/зум камера, высокая автономность
2026-01-20 12:30