Автор: Денис Аветисян
Исследователи предлагают инновационную систему, использующую диффузионные модели и геометрические признаки для генерации высококачественных изображений из ограниченного числа исходных данных.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"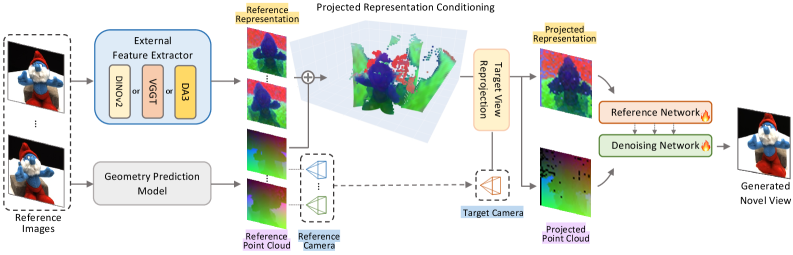
Предлагаемый метод объединяет возможности реконструкции и заполнения недостающих фрагментов, используя VGGT-представление для обеспечения согласованности и детализации.
Воссоздание реалистичных видов с новых точек обзора остается сложной задачей при ограниченном количестве исходных изображений. В работе ‘Projected Representation Conditioning for High-fidelity Novel View Synthesis’ предложен новый подход к синтезу новых видов, использующий диффузионные модели и внешние визуальные представления для повышения геометрической согласованности. Ключевым нововведением является механизм внедрения внешних признаков VGGT в процесс диффузии, что позволяет эффективно комбинировать реконструкцию и заполнение недостающих областей. Способно ли данное решение открыть новые горизонты в задачах виртуальной реальности и роботизированной навигации, требующих генерации высококачественных изображений из разреженных наборов данных?
Задача Нового Видения: Ключ к Реалистичной Реконструкции
Создание фотореалистичных изображений сцены с новых, ранее не виденных точек обзора остается центральной задачей в области компьютерного зрения. Для достижения этой цели требуется не только точное воссоздание геометрии трехмерного пространства, но и передача мельчайших деталей текстур, отражений и освещения. Достижение высокого уровня реализма подразумевает, что синтезированное изображение должно быть практически неотличимо от фотографии, сделанной реальной камерой. Эта задача осложняется необходимостью учета сложных оптических эффектов, таких как глубина резкости, размытие в движении и взаимодействие света с различными поверхностями. Успешное решение этой проблемы открывает широкие возможности для создания иммерсивных виртуальных сред, реалистичных симуляций и продвинутых систем машинного зрения.
Существующие методы синтеза новых видов зачастую демонстрируют ограниченные возможности при экстраполяции на ранее не встречавшиеся углы обзора, что приводит к искажениям и нереалистичным изображениям. Особенно сложной задачей является поддержание визуальной согласованности между несколькими сгенерированными видами — объекты могут незначительно смещаться, меняться в размере или форме, что нарушает ощущение целостности сцены. Эта проблема усугубляется при работе со сложными сценами, содержащими множество деталей и отражающих поверхностей, где даже небольшие ошибки в реконструкции геометрии или текстуры могут приводить к заметным артефактам и снижению качества визуализации. Поэтому разработка алгоритмов, способных к обобщению и обеспечению согласованности, остается ключевой задачей в области компьютерного зрения.
Современные методы синтеза новых видов сцен часто характеризуются высокой вычислительной сложностью и потребностью в огромных объемах обучающих данных. Для достижения реалистичных результатов, алгоритмы нуждаются в обработке больших массивов изображений и геометрических данных, что требует значительных вычислительных ресурсов и времени. Обучение моделей, способных генерировать правдоподобные виды, зачастую требует использования тысяч или даже миллионов изображений, что создает серьезные трудности при сборе и аннотации данных. Это особенно актуально для приложений, требующих работы в реальном времени или на устройствах с ограниченными ресурсами, поскольку вычислительная нагрузка может стать непреодолимым препятствием для практического применения. Поиск более эффективных алгоритмов и методов обучения, способных обойтись меньшим количеством данных и вычислительных затрат, является ключевой задачей в данной области исследований.
Создание новых видов изображения сцены играет ключевую роль в развитии таких передовых технологий, как виртуальная и дополненная реальность, а также робототехника. Высококачественный синтез новых видов позволяет пользователям полностью погрузиться в виртуальные миры, обеспечивая реалистичное восприятие окружения и взаимодействие с ним. В робототехнике эта возможность критически важна для навигации в сложных условиях, распознавания объектов и планирования действий, позволяя роботам эффективно ориентироваться и адаптироваться к изменяющейся среде. Эффективность алгоритмов синтеза новых видов напрямую влияет на производительность систем виртуальной реальности и на автономность роботов, поэтому постоянное совершенствование этих технологий является приоритетной задачей для исследователей и разработчиков.

ReNoV: Принцип Извлечения и Обработки Признаков
ReNoV использует предварительно обученные визуальные модели-основы, такие как CLIP и DINO, для извлечения многовидовых признаков. Эти модели, обученные на масштабных наборах данных изображений и текста, позволяют эффективно захватывать как геометрическую информацию (форму и положение объектов в пространстве), так и семантическую (содержание и контекст изображения). Извлеченные признаки представляют собой векторные представления, кодирующие визуальные характеристики, и используются в дальнейших этапах обработки для реконструкции и анализа сцены. Использование предварительно обученных моделей позволяет значительно повысить качество и эффективность работы системы, избегая необходимости обучения с нуля.
Проекционное кондиционирование представлений является ключевым компонентом системы и обеспечивает геометрическое преобразование признаков из опорных видов в целевой вид. Этот процесс включает в себя вычисление трансформации, соответствующей изменению перспективы между опорным и целевым видами, и применение этой трансформации к векторам признаков. Это позволяет системе эффективно сопоставлять признаки, извлеченные из разных точек обзора, и, как следствие, повышает точность реконструкции трехмерной сцены. Использование геометрических преобразований гарантирует сохранение пространственной информации и согласованность между различными представлениями сцены.
В ReNoV для выравнивания геометрии активно используются представления в виде облаков точек. Облака точек предоставляют плотное и точное описание трехмерной структуры сцены, что позволяет эффективно сопоставлять и выравнивать данные из различных точек обзора. Использование облаков точек позволяет ReNoV учитывать мелкие геометрические детали и обеспечивать высокую точность реконструкции, особенно в сложных сценах с большим количеством объектов и текстур. Для обработки облаков точек применяются специализированные алгоритмы, оптимизированные для повышения эффективности и снижения вычислительных затрат.
Механизм внимания в ReNoV объединяет признаки, извлеченные из опорных и целевых видов, для повышения детализации и согласованности реконструируемой сцены. Он позволяет модели динамически взвешивать вклад каждого признака из каждого вида, фокусируясь на наиболее релевантных областях. В частности, механизм внимания вычисляет веса, определяющие важность каждого признака в зависимости от его взаимосвязи с другими признаками, что позволяет эффективно подавлять шум и выделять значимые детали. Этот процесс улучшает качество реконструкции, особенно в областях с недостаточной информацией или сложной геометрией, обеспечивая более точное и связное представление сцены.

Базовые Модели Извлечения Признаков: Основа Точной Реконструкции
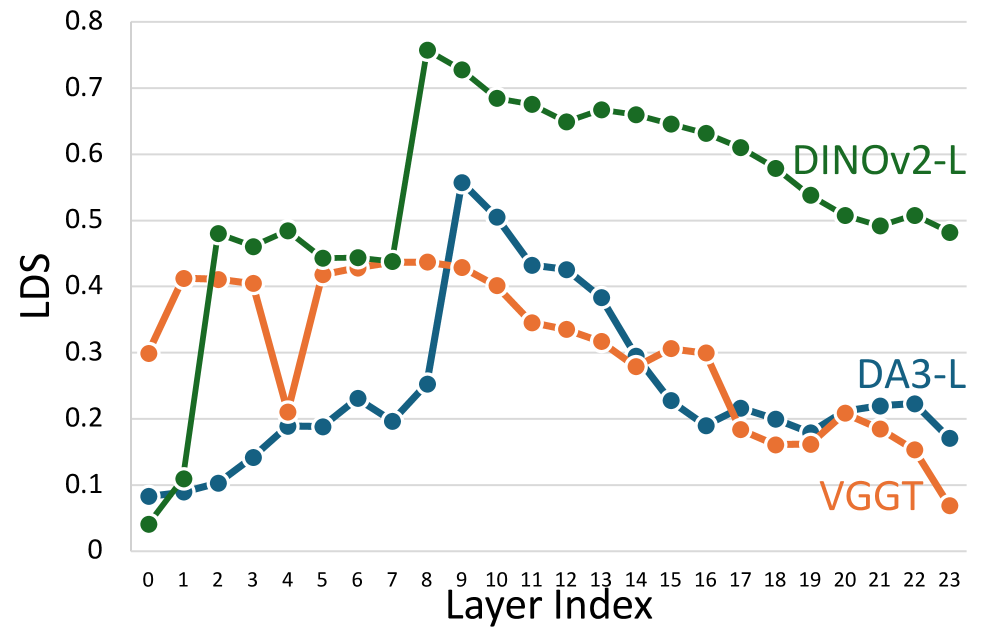
В ReNoV для извлечения многовидовых признаков используются модели DepthAnythingV3 и VGGT, что позволяет объединить их сильные стороны в задачах реконструкции геометрии сцены. DepthAnythingV3 специализируется на точной оценке глубины, обеспечивая детальное представление трехмерной структуры. VGGT, в свою очередь, обеспечивает робастные признаки, полезные для установления соответствий между различными точками зрения. Комбинированное использование этих моделей позволяет ReNoV эффективно захватывать и представлять геометрию сцены, что является критически важным для синтеза новых видов.
Модели DepthAnythingV3 и VGGT построены на основе фреймворка самообучения DINOv2, что значительно повышает их способность к обобщению и адаптации к новым, ранее не встречавшимся точкам обзора. DINOv2 использует подход самоконтролируемого обучения, позволяющий моделям извлекать полезные признаки из немаркированных данных, что особенно важно для задач, требующих понимания геометрии сцены и устойчивости к изменениям перспективы. Использование DINOv2 в качестве основы обеспечивает более эффективное обучение и лучшую производительность при синтезе новых видов, так как модели уже обладают предварительным пониманием визуальных признаков и пространственных отношений.
Модели DepthAnythingV3 и VGGT предоставляют надежные признаки, необходимые для установления точной геометрической соответствия между различными видами сцены. Эти признаки, полученные на основе анализа глубины и визуальных характеристик, позволяют алгоритму идентифицировать одни и те же точки и поверхности на разных изображениях. Высокая точность геометрической соответствия критически важна для построения согласованных и реалистичных новых видов, так как позволяет правильно спроецировать информацию из исходных изображений в целевое изображение. Надежность признаков, предоставляемых DepthAnythingV3 и VGGT, обеспечивает устойчивость алгоритма к изменениям освещения, перспективы и другим факторам, влияющим на качество визуальных данных.
Использование предварительно обученных моделей DepthAnythingV3 и VGGT значительно сокращает объем необходимых данных и вычислительных ресурсов для обучения системы ReNoV. Вместо обучения с нуля, система использует знания, полученные моделями на больших наборах данных, что позволяет достичь высокой производительности в задаче синтеза новых видов с минимальным количеством дополнительных тренировочных данных. Это существенно ускоряет процесс обучения и снижает затраты, делая возможным эффективное создание новых видов из различных точек обзора.
Оценка Эффективности и Валидация: Подтверждение Превосходства ReNoV
Исследования показали, что ReNoV демонстрирует превосходные результаты при генерации новых видов изображений на двух ключевых бенчмарках — DTU Dataset и RealEstate10K. В ходе сравнительного анализа ReNoV значительно превзошел существующие методы, такие как MVSplat, LucidDreamer, GenWarp и ViewCrafter, обеспечивая более высокое качество синтезированных изображений. Данное превосходство подтверждается как количественными показателями, включая улучшения в метриках PSNR, SSIM и LPIPS на датасете DTU, так и визуальной оценкой реалистичности и согласованности полученных результатов. Таким образом, ReNoV представляет собой значительный шаг вперед в области синтеза новых видов, открывая новые возможности для приложений в виртуальной и дополненной реальности, а также в робототехнике.
Исследования показали, что ReNoV демонстрирует превосходство над существующими методами генерации новых видов, включая такие известные подходы, как MVSplat, LucidDreamer, GenWarp и ViewCrafter. В ходе сравнительного анализа было установлено, что ReNoV обеспечивает более высокое качество синтезированных изображений, что подтверждается объективными метриками и визуальной оценкой. Преимущество ReNoV заключается в способности более точно воспроизводить детали и текстуры, а также создавать более реалистичные и согласованные виды, что делает его перспективным решением для широкого спектра приложений, требующих высококачественную 3D-реконструкцию и генерацию новых перспектив.
Результаты исследований демонстрируют, что разработанный подход ReNoV, основанный на работе с признаками сцены, эффективно преодолевает ограничения, свойственные предыдущим методам синтеза новых видов. В частности, ReNoV обеспечивает создание более реалистичных и согласованных изображений, что подтверждается улучшением ключевых метрик качества — PSNR, SSIM и LPIPS — на стандартном наборе данных DTU. Полученные данные свидетельствуют о том, что фокусировка на извлечении и обработке признаков позволяет ReNoV более точно реконструировать геометрию и текстуры объектов, что приводит к более убедительным и правдоподобным новым видам сцены.
Возможность синтеза высококачественных новых видов открывает значительные перспективы для широкого спектра приложений. В частности, в виртуальной и дополненной реальности это позволяет создавать более реалистичные и захватывающие пользовательские опыты, преодолевая ограничения, связанные с фиксированными точками обзора. В сфере робототехники, генерирование новых видов помогает роботам лучше понимать окружающую среду, обеспечивая более точную навигацию и взаимодействие с объектами, даже в условиях ограниченной видимости или меняющейся обстановки. Таким образом, разработка методов, позволяющих создавать правдоподобные и детализированные виды, является ключевым шагом к развитию более совершенных и функциональных систем в этих областях.

Исследование, представленное в статье, стремится к созданию высококачественных синтезированных изображений из разреженных входных данных, что требует глубокого понимания геометрических и семантических взаимосвязей. В этом контексте, слова Яна ЛеКуна приобретают особое значение: «Машинное обучение — это просто поиск инвариантов». Действительно, успешная реализация подхода, основанного на диффузионных моделях и VGGT-представлениях, требует выявления и использования этих самых инвариантов — устойчивых характеристик объектов и сцены, которые остаются неизменными при изменении точки обзора. Способность модели корректно экстраполировать и реконструировать недостающие части изображения напрямую зависит от эффективности поиска и применения этих инвариантных признаков, что подтверждает математическую элегантность предложенного решения.
Что Дальше?
Представленный подход, безусловно, демонстрирует потенциал диффузионных моделей в синтезе новых видов, однако, как и любое решение, оно лишь отодвигает проблему, а не устраняет её. Акцент на VGGT признаках, хотя и оправдан с точки зрения семантической информации, неизбежно накладывает ограничения на обобщающую способность. Истинная элегантность заключалась бы в алгоритме, инвариантном к выбору представления, не требующем ручной настройки признаков. Вопрос масштабируемости при увеличении разрешений и плотности входных данных остаётся открытым — асимптотическая устойчивость требует более глубокого анализа.
Будущие исследования, вероятно, будут сосредоточены на интеграции геометрических примитивов непосредственно в процесс диффузии, позволяя модели «понимать» структуру сцены, а не просто реконструировать её на основе признаков. Варьирование и закрашивание, хоть и эффективно, остаются эвристическими методами. Необходима более строгая математическая формулировка, гарантирующая консистентность между разными видами, основанная на принципах проективной геометрии и теории информации.
В конечном счете, подлинный прогресс заключается не в увеличении количества пикселей, а в создании алгоритмов, способных к абстракции и обобщению, — в поиске минимально достаточного набора принципов, определяющих визуальный мир. Реальная сложность заключается не в кодировании деталей, а в выявлении фундаментальных закономерностей.
Оригинал статьи: https://arxiv.org/pdf/2602.12003.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Нейросети как посредники: этика и границы взаимодействия с разумом
- Как самому почистить матрицу. Продолжение.
- OnePlus Nord 6 ОБЗОР: чёткое изображение, замедленная съёмка видео, скоростная зарядка
- Неважно, на что вы фотографируете!
- MSI Katana 17 HX B14WGK ОБЗОР
- vivo iQOO Z11 Turbo ОБЗОР: огромный накопитель, отличная камера, много памяти
- Калькулятор глубины резкости. Как рассчитать ГРИП.
- Что такое глубина резкости в фотографии?
- Макросъемка
- Российский рынок: Рубль, ДВМП и рекордный рост рублевых вкладов – что ждет инвесторов? (28.03.2026 11:32)
2026-02-14 20:52