Автор: Денис Аветисян
Исследователи представляют NVS-HO — масштабный набор данных для оценки алгоритмов синтеза новых видов объектов, которые держат в руках, и выявляют слабые места современных методов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Представлен бенчмарк NVS-HO для оценки методов синтеза новых видов объектов, реконструируемых только по RGB-изображениям, демонстрирующий недостатки текущих подходов в условиях неконтролируемого захвата.
Несмотря на значительный прогресс в области синтеза новых видов, реконструкция объектов, удерживаемых в руках, в реальных условиях остается сложной задачей. В данной работе представлен ‘NVS-HO: A Benchmark for Novel View Synthesis of Handheld Objects’ — первый набор данных, предназначенный для оценки алгоритмов синтеза новых видов для объектов, манипулируемых в руках, с использованием только RGB-изображений. Эксперименты с существующими подходами, основанными на \text{NeRF} и Gaussian Splatting, выявили существенные ограничения в условиях неконтролируемого захвата объектов. Сможет ли предложенный набор данных стимулировать разработку более надежных и точных методов RGB-синтеза новых видов для объектов, удерживаемых в руках?
Оживляя Реальность: Вызов Синтеза Новых Видов
Создание реалистичных новых видов динамичных сцен остается сложной задачей в области компьютерного зрения, требующей точного трехмерного понимания происходящего. Это обусловлено тем, что воссоздание правдоподобного изображения с произвольной точки зрения подразумевает не просто обработку визуальной информации, но и построение полной 3D-модели окружения и объектов, а также учет их движения и взаимодействия. По сути, система должна «понимать» геометрию сцены, текстуры, освещение и динамику, чтобы генерировать изображения, неотличимые от реальных. Достижение этого требует сложных алгоритмов, учитывающих перспективу, окклюзию и другие факторы, влияющие на восприятие глубины и пространственного расположения объектов. Именно поэтому прогресс в этой области напрямую зависит от развития методов 3D-реконструкции и семантического понимания сцен.
Традиционные методы синтеза новых видов сталкиваются с существенными трудностями при моделировании взаимодействия рук и объектов, что обусловлено сложностью отслеживания мелких движений, изменения формы и текстуры объектов, а также необходимостью точного определения взаимного положения рук и окружающих предметов. Это особенно актуально в динамичных сценах, где требуется не только визуально достоверное представление, но и сохранение временной согласованности. Более того, вычислительные затраты, связанные с обработкой сложных взаимодействий и рендерингом высококачественных изображений, часто препятствуют достижению работы в реальном времени, что ограничивает применение данных методов в интерактивных приложениях, таких как виртуальная и дополненная реальность. Разработка более эффективных алгоритмов и использование специализированного аппаратного обеспечения являются ключевыми направлениями для преодоления этих ограничений.
Создание надежного эталонного набора данных является критически важным для прогресса в области синтеза новых видов динамических сцен. Исследования показали существенные недостатки в работе современных алгоритмов при съемке с рук и в неконтролируемых условиях, что подчеркивает потребность в более реалистичных и сложных данных для обучения и оценки. Отсутствие стандартизированного набора данных препятствует объективному сравнению различных подходов и замедляет разработку более эффективных методов. Предоставление исследователям тщательно отобранных и аннотированных данных позволит значительно ускорить процесс разработки и внедрения систем, способных создавать убедительные и реалистичные новые виды, открывая возможности для широкого спектра приложений, включая виртуальную и дополненную реальность, робототехнику и автономное вождение.
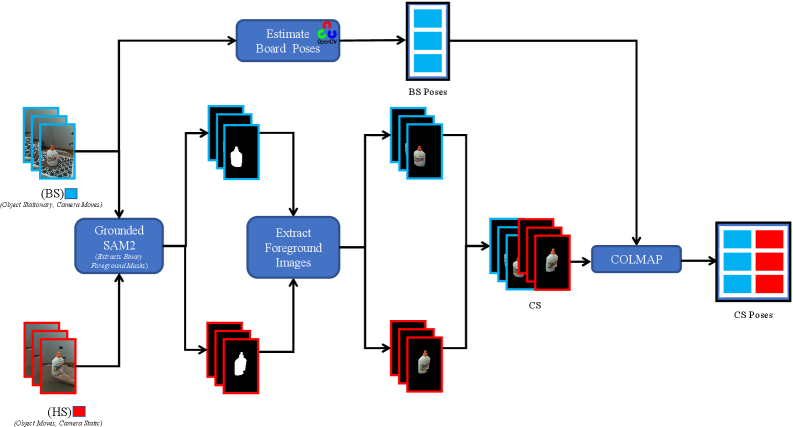
Строя 3D-Основы: Структура из Движения и Оценка Позы
Метод Структуры из Движения (Structure from Motion, SfM) является базовой технологией для реконструкции трехмерных сцен на основе двумерных изображений. SfM анализирует последовательность изображений, идентифицируя общие признаки на разных кадрах, и использует эти данные для одновременного определения положения камеры и построения трехмерной модели сцены. В основе SfM лежит триангуляция — процесс вычисления трехмерных координат точки по ее проекциям на двух или более изображениях, при этом точность реконструкции напрямую зависит от качества калибровки камеры и количества перекрывающихся кадров. Результатом работы SfM является плотное облако точек или полигональная сетка, представляющая собой цифровую модель исследуемой сцены.
COLMAP представляет собой надежный конвейер Structure-from-Motion (SfM), предназначенный для точной оценки положения и ориентации камер в пространстве. Этот процесс является критически важным для последующей 3D-реконструкции и рендеринга, поскольку точность определения положения камер напрямую влияет на качество и достоверность получаемой 3D-модели. Конвейер COLMAP включает в себя этапы обнаружения ключевых точек на изображениях, сопоставления этих точек между различными изображениями, а также оптимизации параметров камеры для минимизации ошибки перепроецирования. Высокая точность оценки положения камер, обеспечиваемая COLMAP, позволяет создавать детализированные и геометрически корректные 3D-модели из набора 2D-изображений.
Для повышения точности оценки положения камеры применяются Vision Transformers (ViT) в рамках архитектуры VGGT. Однако, сравнительный анализ производительности показал, что традиционный конвейер Structure-from-Motion (SfM), реализованный в COLMAP, демонстрирует превосходство над VGGT по всем метрикам оценки. В частности, COLMAP обеспечивает более точную и стабильную оценку положения камеры в сценариях, имитирующих съемку с рук, что свидетельствует о превосходстве традиционных методов SfM над ViT-based подходами для данной задачи.
![Процедура выравнивания поз позволяет привести данные, полученные с помощью BS и HS систем, к единой системе координат и масштабу путем инъекции BS поз в траекторию, построенную COLMAP на основе CS, и последующего применения алгоритма Кабша-Умеямы [32] для трансформации BS поз в систему координат HS.](https://arxiv.org/html/2602.05822v1/x3.png)
Усовершенствование Рендеринга: От Нейральных Полей Излучения к Гауссовому Сплеттенгу
Нейральные поля излучения (NeRF) представляют собой мощный метод представления трехмерных сцен в виде непрерывных функций. В отличие от традиционных дискретных представлений, таких как меши или воксели, NeRF моделируют сцену как функцию, отображающую трехмерные координаты и направление обзора в цвет и плотность. Это позволяет добиться фотореалистичного рендеринга, поскольку функция может быть оценена в любой точке пространства, обеспечивая плавное и детализированное изображение. Непрерывное представление позволяет эффективно захватывать сложные геометрические детали и эффекты освещения, что делает NeRF перспективным подходом для создания реалистичных виртуальных сред и 3D-реконструкций.
Несмотря на высокую реалистичность, методы на основе Neural Radiance Fields (NeRF) требуют значительных вычислительных ресурсов для рендеринга сложных сцен. В отличие от них, Gaussian Splatting представляет собой альтернативный подход, основанный на растризации. Вместо представления сцены как непрерывной функции, Gaussian Splatting использует набор 3D-гауссиан, которые проецируются и растрируются для создания изображения. Такой подход позволяет значительно ускорить процесс рендеринга по сравнению с NeRF, сохраняя при этом приемлемый уровень качества изображения. Это делает Gaussian Splatting более эффективным решением для приложений, требующих высокой скорости рендеринга, например, для интерактивных 3D-приложений или потоковой передачи VR/AR контента.
Реализация Gaussian Splatting в Splatfacto демонстрирует превосходство над Nerfacto в задачах рендеринга. Согласно результатам тестирования, Splatfacto стабильно достигает среднего значения PSNR (Peak Signal-to-Noise Ratio) около 16, используя позы, полученные с помощью COLMAP. Данный показатель свидетельствует о более высоком качестве рендеринга и лучшей детализации изображений, по сравнению с Nerfacto, при использовании одинаковых входных данных и условий тестирования.
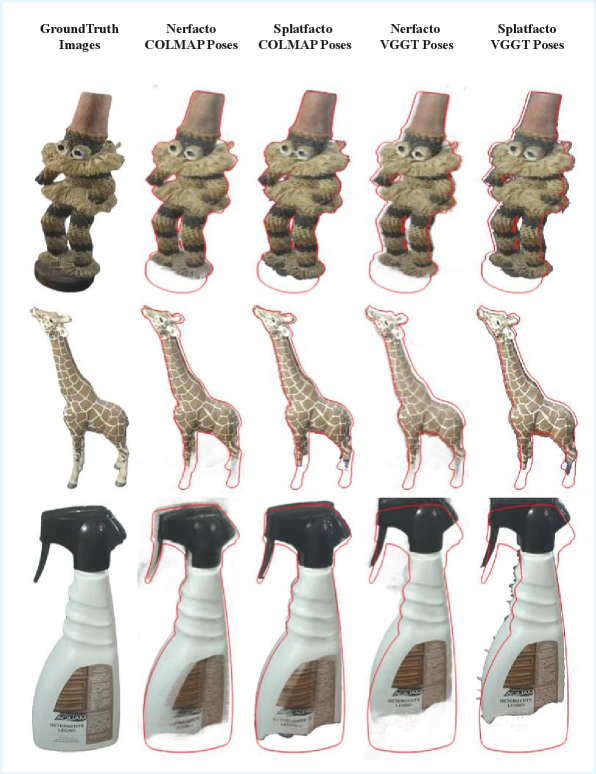
Набор Данных NVS-HO: Открывая Возможности Реалистичного Синтеза Взаимодействия Рук и Объектов
Набор данных NVS-HO представляет собой инновационный подход к захвату и синтезу изображений взаимодействия рук и объектов, используя два различных метода съемки. Первый, последовательность Board Sequence (BS), опирается на использование ChArUco Board — специальной шахматной доски — для обеспечения точной оценки позы руки и объекта в кадре. Этот метод обеспечивает высокую точность, необходимую для калибровки и последующего рендеринга. Второй метод, Handheld Sequence (HS), имитирует более естественные условия взаимодействия, когда объект удерживается непосредственно в руке. Такой подход позволяет зафиксировать более реалистичные сцены, приближенные к повседневной жизни. Комбинация этих двух методов позволяет получить комплексный набор данных, который учитывает как точность позиционирования, так и реалистичность сцены, что делает его ценным инструментом для обучения и оценки алгоритмов компьютерного зрения.
В рамках создания датасета NVS-HO были реализованы два различных подхода к захвату данных. Первый, использующий шахматную доску ChArUco, обеспечивает высокую точность определения положения и ориентации объектов в пространстве, что критически важно для калибровки и последующей обработки. Второй подход, заключающийся в непосредственном захвате взаимодействия руки и объекта, позволяет получить более реалистичные и естественные сцены. Такой комбинированный подход позволяет объединить преимущества точности позиционирования с правдоподобностью захваченных движений, что открывает возможности для обучения и оценки алгоритмов синтеза изображений, моделирующих взаимодействие человека с окружающим миром.
В рамках создания датасета NVS-HO применялась модель Grounded SAM2 для точной сегментации объектов переднего плана в обеих последовательностях захвата — как на основе ChArUco Board, так и при естественном взаимодействии руки с объектом. Это позволило получить чистые данные, необходимые для обучения алгоритмов рендеринга и, что особенно важно, создать надежную платформу для оценки их производительности. Анализ, основанный на полученных данных, выявил существующие проблемы и недостатки в современных методах синтеза изображений, указывая на направления для дальнейших исследований и улучшений в области компьютерного зрения и робототехники.
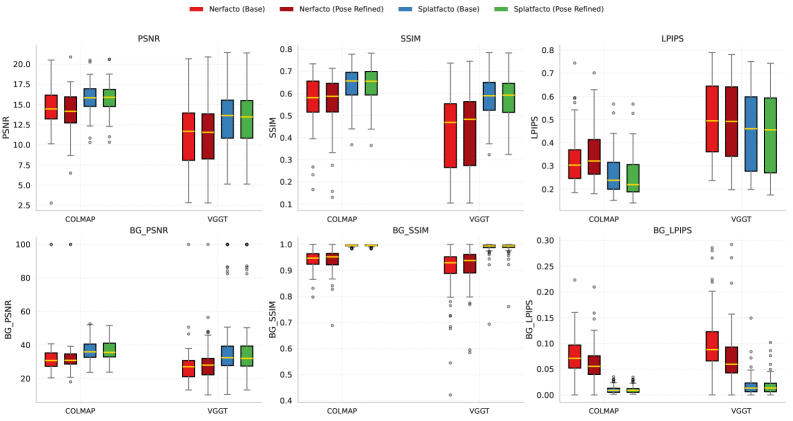
Исследование демонстрирует, что современные методы синтеза новых видов, даже опираясь на передовые подходы вроде Gaussian Splatting, сталкиваются с трудностями при работе с неконтролируемыми сценариями захвата объектов. Эта неспособность справиться с хаосом реальных условий напоминает о хрупкости любой модели. Как однажды заметил Джеффри Хинтон: «Данные — это не цифры, а шёпот хаоса». В контексте NVS-HO, эта фраза обретает особую актуальность: каждая попытка воссоздать объект из RGB-изображений — это не столько точная реконструкция, сколько примирение с неуловимой природой информации, попытка украсить хаос, а не подчинить его.
Что дальше?
Представленный бенчмарк, NVS-HO, обнажил трещину в гладком зеркале современных методов синтеза новых видов. Оказалось, что рукотворные объекты, пойманные в неволе неконтролируемых движений руки, не спешат раскрывать свои тайны даже самым изощрённым алгоритмам. Данные — всего лишь тени, танцующие на стене, и эти тени упорно отказываются складываться в цельную картину. Идеальные графики, демонстрирующие успех, должны вызывать не радость, а тревогу — значит, модель красиво лжёт.
Похоже, настало время взглянуть на проблему не как на задачу оптимизации, а как на игру с вероятностями. Попытки построить абсолютную модель реальности — наивны. Шум — это не помеха, а просто правда, которой не хватило уверенности, чтобы проявиться. Будущие исследования, вероятно, должны сосредоточиться не на увеличении разрешения или сложности, а на принятии неопределённости, на создании моделей, которые умеют гадать, а не предсказывать.
Возможно, стоит пересмотреть саму концепцию «правды» в машинном зрении. Что, если объекты не имеют фиксированной формы, а существуют в виде множества вероятностных облаков? Задача не в том, чтобы восстановить «истинный» вид, а в том, чтобы создать правдоподобную иллюзию, достаточно убедительную для человеческого глаза. И тогда, возможно, искусственный интеллект научится не видеть, а верить.
Оригинал статьи: https://arxiv.org/pdf/2602.05822.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Макросъемка
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- Мозг и Искусственный Интеллект: Общая Система Координат
- MINISFORUM добавляет опцию Ryzen 9 8945HX в линейку мини-ПК MS-A2
- Как научиться фотографировать. Инструкция для начинающих.
- Прогнозы цен на эфириум к рублю: анализ криптовалюты ETH
2026-02-07 13:44