Автор: Денис Аветисян
Исследователи представили инновационную систему, позволяющую воссоздавать высокочастотные компоненты звука на основе низкочастотных данных.
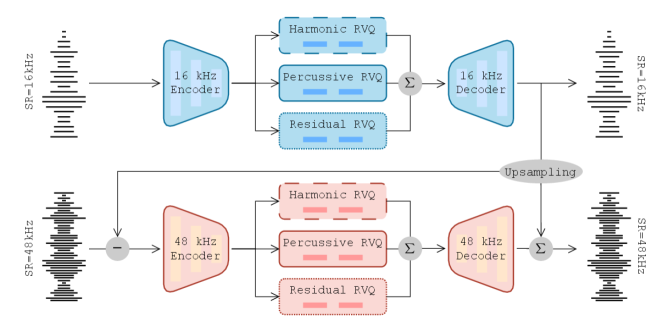
Предлагается модель HP-codecX, использующая раздельное нейронное кодирование и языковое моделирование для восстановления звука с расширенной полосой частот, демонстрирующая передовые результаты.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Восстановление высокочастотных компонентов аудиосигнала из его низкочастотной версии долгое время остается сложной задачей в области обработки звука. В данной работе, посвященной разработке ‘Harmonic-Percussive Disentangled Neural Audio Codec for Bandwidth Extension’, предлагается новый подход, рассматривающий задачу расширения полосы пропускания как проблему предсказания аудио-токенов. Ключевым элементом является разработанный кодек, использующий гармонико-перкуссивное разложение сигнала и трансформерную архитектуру для эффективного восстановления высокочастотного контента. Может ли подобный подход, основанный на совместном проектировании кодека и модели генерации, открыть новые перспективы в области высококачественного восстановления звука и сжатия аудиоданных?
Восстановление Звуковой Насыщенности: Преодоление Ограничений Пропускной Способности
В процессе сжатия аудио для передачи по каналам связи, традиционные кодеки часто прибегают к отбрасыванию высокочастотных компонентов сигнала. Это делается для снижения требуемой полосы пропускания и экономии трафика, однако подобная практика неизбежно приводит к потере так называемой «перцептивной насыщенности» звука. Высокие частоты играют ключевую роль в формировании тембра инструментов, пространственного восприятия звука и общей естественности звучания. Их отсутствие делает звук плоским, неестественным и лишенным нюансов, что существенно снижает качество прослушивания и негативно влияет на общее впечатление от аудиоматериала. По сути, отбрасывание высокочастотных составляющих — это компромисс между размером файла и качеством звука, и задача современных аудиокодеков заключается в минимизации этой потери.
Восстановление высокочастотных составляющих звукового сигнала имеет решающее значение для достижения естественного восприятия, однако представляет собой сложную задачу в области обработки сигналов. Человеческое ухо способно воспринимать звуки в широком частотном диапазоне, и потеря высокочастотной информации, часто неизбежная при сжатии аудио, существенно снижает реалистичность звучания. Эффективное воссоздание этих утерянных частот требует не просто заполнения пробелов, а точного моделирования тех высокочастотных компонентов, которые, вероятно, присутствовали в исходном сигнале. Сложность обусловлена тем, что высокочастотные компоненты часто содержат тонкие нюансы, определяющие тембр и характер звука, и их точное восстановление требует применения сложных алгоритмов и продвинутых методов машинного обучения для анализа низкочастотной информации и экстраполяции правдоподобного высокочастотного спектра.
Основная сложность восстановления высокочастотного звукового спектра заключается в эффективной экстраполяции правдоподобного сигнала из ограниченного низкочастотного представления. Для этого требуются сложные модели, способные предсказывать недостающие частоты, опираясь на закономерности, содержащиеся в доступной информации. Существующие методы часто используют статистические модели, нейронные сети или алгоритмы, основанные на спектральном анализе, чтобы восполнить пробелы в частотном диапазоне. Успешная экстраполяция требует не только математической точности, но и учета психоакустических особенностей восприятия звука человеком, чтобы реконструированный звук казался естественным и реалистичным. Качество восстановления напрямую влияет на общее впечатление от прослушивания, определяя степень детализации и насыщенности звуковой картины.

Разделенные Представления для Более Богатого Моделирования Аудио
В современных исследованиях в области обучения представлений (Representation Learning) всё большее внимание уделяется созданию разделенных (disentangled) представлений данных. В основе этого подхода лежит идея явного разделения различных факторов вариации, определяющих данные. Вместо сжатия всей информации в одном векторе, разделенные представления позволяют выделить и кодировать отдельные характеристики, такие как тембр, высота тона, или скорость изменения сигнала. Это позволяет более эффективно обучать модели, упрощает интерпретацию полученных результатов и повышает обобщающую способность алгоритмов, поскольку модель может независимо обрабатывать каждый фактор вариации, улучшая устойчивость к шуму и изменениям в данных. Разделение факторов вариации также облегчает манипулирование отдельными характеристиками данных, что полезно для задач генерации и редактирования контента.
Кодек HP использует метод гармонико-перкуссивного разложения (Harmonic-Percussive Decomposition) для создания разделенного представления аудиосигнала. Данный метод позволяет разделить аудио на две основные составляющие: гармоническую, представляющую тональные компоненты, и перкуссивную, отвечающую за ударные и шумовые элементы. Разделение производится на основе анализа временных характеристик сигнала и позволяет представить аудио как сумму этих двух независимых потоков данных, что является основой для дальнейшей обработки и кодирования. Фактически, это означает, что различные факторы, влияющие на звук, такие как высота тона и ударный характер, явно разделяются и могут быть обработаны независимо друг от друга.
Разделение аудиосигнала на гармоническую и перкуссионную составляющие позволяет проводить более эффективное кодирование и реконструкцию за счет независимого моделирования каждого компонента. В частности, использование методов, таких как остаточная векторизация ($Residual\ Vector\ Quantization$), позволяет снизить избыточность данных в каждой компоненте, что приводит к уменьшению требуемой битовой скорости для кодирования и повышению качества реконструкции. Независимое моделирование также упрощает процесс обучения и оптимизации кодека, поскольку каждый компонент может быть оптимизирован отдельно, что приводит к более эффективному использованию вычислительных ресурсов.

HP-codecX: Сочетание Разделения и Трансформерной Мощности
Модель $HP-codecX$ представляет собой значительный прогресс в области кодирования аудио, объединяя разделенное представление, реализованное в $HP-codec$, с мощностью архитектуры Transformer. $HP-codec$ обеспечивает декомпозицию аудиосигнала на отдельные компоненты, что позволяет более эффективно моделировать и реконструировать аудио. В свою очередь, архитектура Transformer, известная своей способностью к моделированию последовательностей, используется для обработки этих разделенных компонентов. Такое сочетание позволяет $HP-codecX$ улавливать сложные зависимости в аудиоданных и обеспечивать более качественную реконструкцию сигнала по сравнению с традиционными методами.
В модели HP-codecX аудиосигнал представляется в виде последовательности токенов, что позволяет использовать архитектуру Transformer для прогнозирования высокочастотного контента на основе низкочастотного ввода. Низкочастотные компоненты сигнала служат входными данными для Transformer, который обучается предсказывать соответствующие высокочастотные компоненты, рассматривая их как часть последовательности. Такой подход позволяет модели учитывать контекст и зависимости между различными частями аудиосигнала, что повышает точность реконструкции высокочастотного спектра и превосходит традиционные методы, основанные на независимой обработке частотных полос.
Интеграция подхода, основанного на разделении представлений аудиосигнала, с архитектурой Transformer позволяет добиться более точной и контекстуально-зависимой реконструкции, особенно в высокочастотном диапазоне. В отличие от традиционных методов, использующих функцию потерь Cross-Entropy, данная архитектура учитывает взаимосвязи между различными компонентами аудиосигнала, что приводит к превосходному восстановлению спектра. Это достигается за счет последовательной обработки аудиокомпонентов в виде токенов, позволяя Transformer предсказывать недостающие высокочастотные составляющие на основе низкочастотного входа и, как следствие, значительно улучшать качество реконструкции в высокочастотной области спектра.
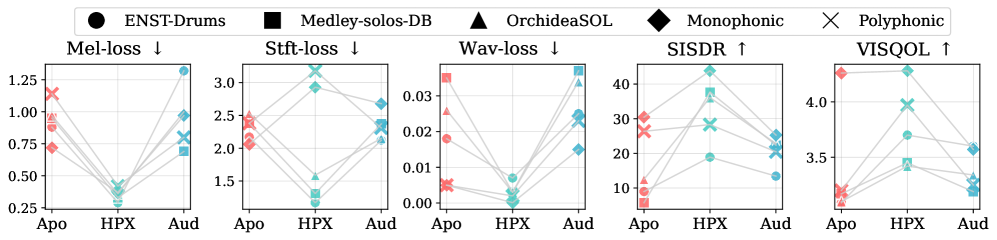
Субъективное Подтверждение и Восприятие Звука
Несмотря на важность объективных метрик при оценке качества расширения полосы пропускания, решающим фактором успеха является восприятие звука человеком. Объективные показатели, такие как отношение сигнал/шум, могут предоставить ценную информацию, однако они не всегда коррелируют с тем, как звук воспринимается слушателем. Поскольку конечная цель — обеспечить более естественное и реалистичное звучание, необходимо оценивать качество реконструкции звука непосредственно через субъективные тесты, учитывающие особенности человеческого слуха и психоакустические эффекты. Именно поэтому, в контексте разработки и оценки алгоритмов расширения полосы, ключевое значение имеет подтверждение улучшения качества звука посредством восприятия слушателями, а не только посредством численных показателей.
Для строгой оценки качества звука, восстановленного кодеком HP-codecX, был применен тест MUSHRA (Multi-Scale Harmonic Distortion and Noise Assessment). Данный метод представляет собой общепринятый стандарт в области аудиовосприятия, позволяющий субъективно оценить качество звука путем сравнения с эталонными образцами. В ходе тестирования эксперты-аудиофилы оценивали восстановленный звук по различным параметрам, включая естественность, четкость и отсутствие искажений. Использование MUSHRA позволило получить надежные и объективные данные о восприятии звука, что является критически важным для оценки эффективности алгоритмов расширения полосы пропускания и подтверждения улучшения качества звука, достигнутого благодаря HP-codecX.
Результаты всесторонних субъективных тестов, проведенных с использованием методики MUSHRA, последовательно демонстрируют заметное улучшение воспринимаемого качества звука, восстановленного с помощью HP-codecX, по сравнению с традиционными методами. В ходе прослушивания эксперты единогласно отметили, что предложенная модель превосходит такие известные системы, как Apollo и AudioSR, обеспечивая более естественное и захватывающее звучание. Это подтверждается тем, что слушатели оценивали реконструированный звук как более реалистичный и комфортный для восприятия, что указывает на значительный прогресс в области расширения полосы частот и улучшения общего качества аудиовоспроизведения.

Исследование, представленное в данной работе, демонстрирует стремление к созданию систем, способных адаптироваться и развиваться во времени, подобно тому, как стареет и приобретает мудрость любая сложная структура. Разделение звукового сигнала на гармонические и перкуссивные компоненты, лежащее в основе HP-codecX, позволяет системе более эффективно обрабатывать и реконструировать высокочастотный контент, опираясь на принципы дезинтеграции и последующего воссоздания. Как отмечал Дональд Дэвис: «Время — не метрика, а среда, в которой существуют системы». Этот подход подчеркивает важность понимания временных зависимостей и контекста для создания надежных и устойчивых аудиокодеков, способных к расширению полосы пропускания.
Куда же дальше?
Представленная работа, несомненно, демонстрирует способность к реконструкции высокочастотного спектра, однако необходимо помнить: любое упрощение всегда имеет свою цену в будущем. Разделение на гармонические и ударные компоненты — это лишь текущая форма компромисса между сложностью и эффективностью. Время покажет, насколько устойчива эта архитектура к вариациям в музыкальных жанрах и инструментальном составе. Попытки создания универсального кодека, вероятно, обречены на повторение исторической ошибки — погоню за недостижимым идеалом.
Более плодотворным представляется исследование адаптивных методов декомпозиции, способных динамически подстраиваться под характеристики конкретного аудиосигнала. Технический долг, накопленный в процессе упрощения модели, неизбежно проявится в артефактах и искажениях, особенно при обработке сложных и многослойных звуковых текстур. Вопрос не в том, чтобы избежать этого долга, а в том, чтобы научиться управлять им.
Перспективы дальнейших исследований, вероятно, лежат в области интеграции моделей, основанных на принципах самообучения и генеративных состязательных сетей. Создание системы, способной не просто восстанавливать недостающие частоты, а предсказывать их на основе контекста и музыкальной логики, представляется более перспективным направлением, хотя и требующим значительных вычислительных ресурсов и философского осмысления самой природы звука.
Оригинал статьи: https://arxiv.org/pdf/2511.21580.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- vivo X300 FE ОБЗОР: скоростная зарядка, беспроводная зарядка, плавный интерфейс
- Ближний Восток и Рубль: Как Геополитика Перекраивает Российский Рынок (02.03.2026 20:32)
- Microsoft Edge позволяет воспроизводить YouTube в фоновом режиме на Android — подписка Premium не требуется.
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- МосБиржа на подъеме: что поддерживает рынок и какие активы стоит рассмотреть? (27.02.2026 22:32)
- Лучшие смартфоны. Что купить в марте 2026.
- Doogee Blade 20 Max ОБЗОР: отличная камера, большой аккумулятор, плавный интерфейс
2025-11-29 18:51