
Кажется, общепринято считать, что запуск ИИ локально на персональном компьютере требует более мощного оборудования. Хотя в этом есть доля правды, как и в случае с играми, всё зависит от степени. Вы можете запускать аналогичные ИИ-приложения на Steam Deck так же, как и на ПК, оснащённом RTX 5090, хотя опыт может быть не идентичным. Однако, по-настоящему важно, чтобы ИИ-задачи всё ещё могли быть выполнены эффективно, независимо от различий в оборудовании.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"Стоит отметить, что даже при экспериментировании с локальными инструментами искусственного интеллекта, такими как запуск языковых моделей вроде Ollama, вам не обязательно требуется высокопроизводительная видеокарта с большим объемом видеопамяти для начала работы. Хотя наличие такой конфигурации, безусловно, было бы полезным, это не является абсолютной необходимостью.
Пример: Несмотря на относительно устаревшие характеристики, такие как процессор AMD Ryzen 5 2500U, 8 ГБ оперативной памяти и отсутствие выделенной графики, мой семилетний Huawei MateBook D все еще работает. Он может запускать Ollama и загружать некоторые большие языковые модели (LLM), что делает его пригодным для использования.
Есть ограничения при запуске ИИ на устаревшем оборудовании
В плане текущих приложений искусственного интеллекта, игровая индустрия представляется идеальным примером для сравнения. Чтобы в полной мере оценить новейший, востребованный контент, требуется мощное оборудование. Однако, насладиться множеством недавних игр возможно и на менее продвинутых и менее мощных системах, включая те, которые используют только интегрированную графику.
Как сторонний наблюдатель, я хотел бы отметить, что использование устаревшего или менее мощного оборудования может не обеспечить той же плавности, на которую вы рассчитываете. Вместо того чтобы стремиться к частоте не менее 144 кадров в секунду (FPS), вы можете обнаружить, что оседаете около 30 FPS. Однако достижение этой цели возможно, но требует компромиссов. Вам, возможно, придется снизить настройки графики, отключить трассировку лучей и, возможно, уменьшить разрешение, чтобы оптимизировать производительность.
Как и в случае с искусственным интеллектом, вы не будете генерировать огромные объемы данных быстрыми темпами и не будете постоянно использовать самые последние и масштабные модели.
Хотя существует множество небольших моделей, доступных для экспериментов даже на устаревшем оборудовании, я могу поручиться за их эффективность. Если ваша видеокарта подходит, она будет использована. Однако, если у вас её нет, будьте уверены, мне всё же удалось добиться определённого успеха.
Проще говоря, мне удалось загрузить модель с приблизительно 1 миллиардом параметров, часто называемые ‘1b моделями’, на старый ноутбук с Fedora 42. Этот конкретный ноутбук официально не поддерживает APU (ускоренный процессорный блок) под Windows 11, но поскольку он обычно работает на Linux на старом оборудовании, я делаю это и в этом случае.
Ollama работает на различных операционных системах, включая Mac, Windows и Linux. Это означает, что её можно использовать независимо от вашей текущей системы. Даже старые модели Mac могут быть совместимы с ней.
Итак, насколько это ‘удобно’?
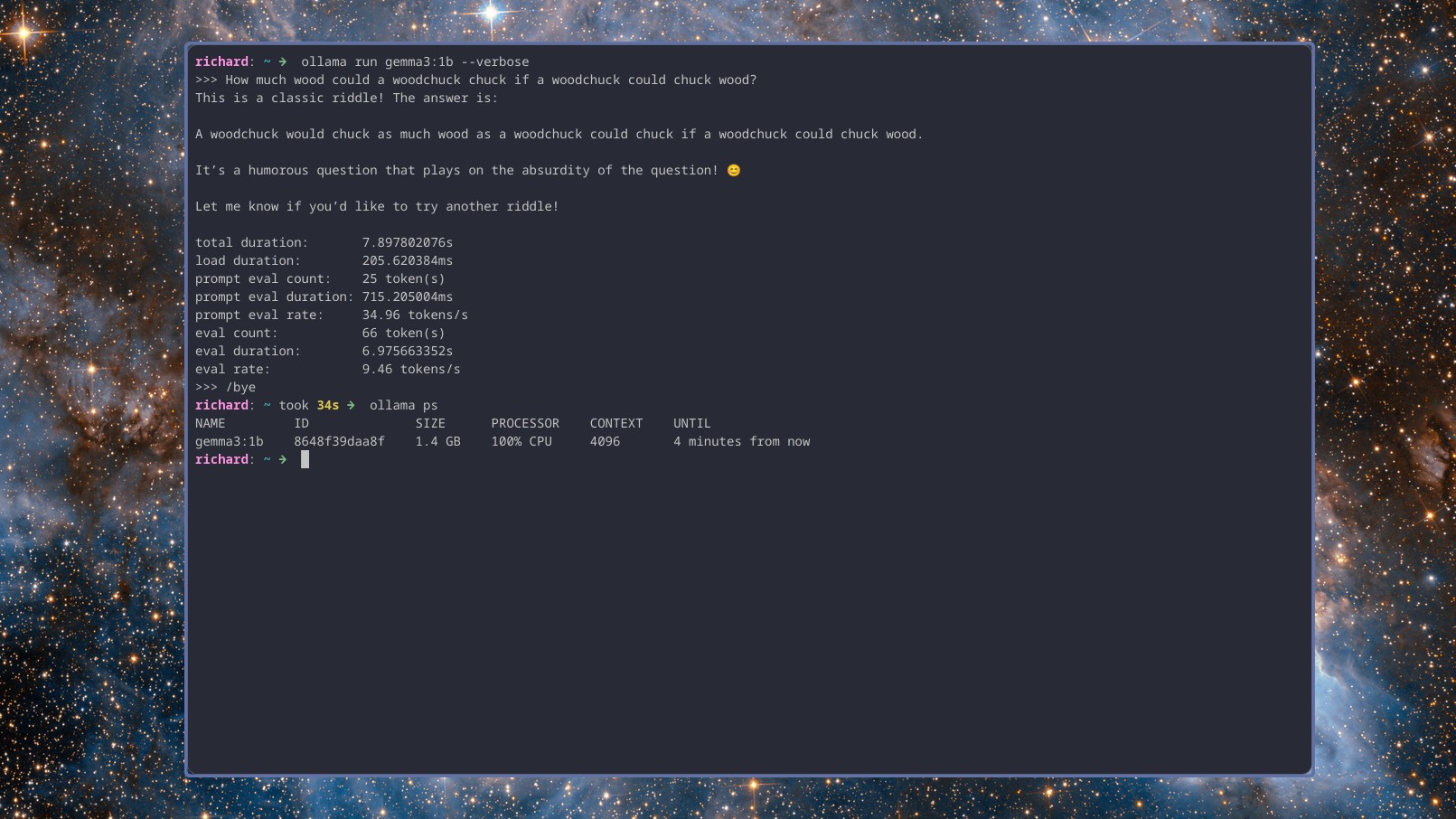
На этом конкретном ноутбуке я не экспериментировал с моделями, превышающими 1 миллиард параметров. Честно говоря, я считаю, что инвестирование времени в такие эксперименты может быть невыгодным. Однако недавно я протестировал три модели 1b: gemma3:1b, llama3.2:1b и deepseek-r1:1.5b. Интересно, что все они демонстрируют сопоставимую производительность. Для этих языковых моделей используется контекстное окно 4k. Учитывая полученные результаты, я не решаюсь пробовать что-либо с большим контекстным окном.
Для начала мой старый фаворит:
Сколько дров мог бы забросить сурок, если бы сурок мог бросать дрова?
Вот две модели, Gemma 3 и Llama 3.2, которые обеспечивают краткие и быстрые ответы, в среднем около 10 ответов в секунду. С другой стороны, Deepseek r1, известная своими способностями к рассуждениям, тратит некоторое время на обдумывание, прежде чем предоставить ответ, работая со скоростью около 8 токенов в секунду.
Однако они могут быть не слишком быстрыми, но они функциональны. Примечательно, что все они генерируют ответы гораздо быстрее, чем я могу печатать или даже придумывать (и, безусловно, быстрее, чем я мог бы вводить текст вручную), учитывая длину контекста 4k.
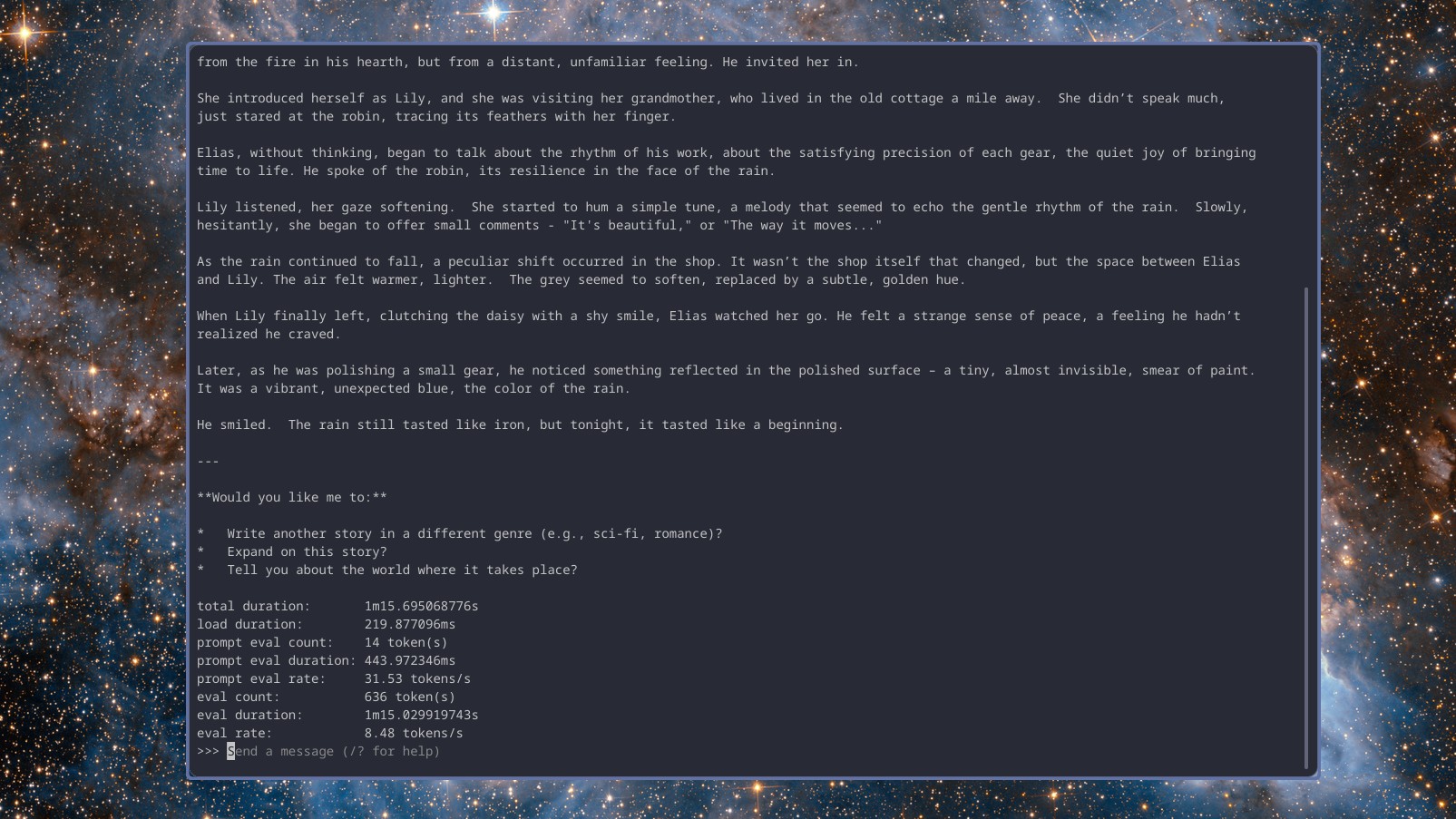
Проще говоря, во втором тесте были задействованы более сложные задачи. Я попросил каждую модель создать базовый сценарий PowerShell, который мог бы извлекать необработанное содержимое текстовых файлов из репозитория GitHub, а также задавать вопросы для подтверждения удовлетворенности результатами, тем самым повышая качество сценария.
В данном случае я ещё не подтвердил, верны ли результаты. Однако моя главная задача здесь — оценить, насколько эффективно и быстро модели могут справиться с поставленной проблемой.
Gemma 3 предоставила всесторонний анализ сценария, отвечая на вопросы по инструкции, и справилась с этой задачей почти с 9 словами в секунду. DeepSeek r1, хотя и немного медленнее — около 7,5 слов в секунду, — не задавала вопросов. Llama 3.2 выдавала результаты, сопоставимые с Gemma 3, также со скоростью почти 9 слов в секунду.
Кстати, важно отметить, что вся операция выполнялась от батарей, используя оптимизированную стратегию энергопотребления. Когда эти устройства подключались к внешнему источнику питания, скорость генерации токенов в секунду почти удваивалась, а время, необходимое для завершения задачи, сокращалось примерно вдвое.
Этот аспект кажется мне более захватывающим. С ноутбуком, работающим от батареи, вы все еще можете выполнять задачи, будь то на улице или дома/в офисе, даже если ваше оборудование относительно старое.
Эта задача была полностью выполнена только с использованием процессора и памяти компьютера, без какой-либо дополнительной поддержки графического процессора ноутбука (iGPU). Ноутбук выделяет несколько гигабайт оперативной памяти для iGPU, но даже этого недостаточно для совместимости с Ollama. Быстрая команда ps для Ollama показывает 100% загрузку процессора.
https://www.youtube.com/watch?v=o1sN1lB76EA
Вы можете работать с этими компактными языковыми моделями, и стоит отметить, что для этого не нужно инвестировать в дорогостоящее высокопроизводительное оборудование; вместо этого вы можете экспериментировать, включать их в свой рабочий процесс и даже приобретать новые навыки — и все это при сохранении контроля над расходами.
На YouTube несложно найти создателей контента, использующих искусственный интеллект на Raspberry Pi или домашних серверах, собранных из относительно доступного и сейчас недорогого старого оборудования. С ноутбуком средней ценовой категории, но уже не новым, вы даже можете начать свое собственное путешествие в мир искусственного интеллекта.
Это не ChatGPT, но кое-что похожее. Даже старый компьютер может стать компьютером с искусственным интеллектом.
Смотрите также
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Российская экономика: замедление, дивиденды и ожидания снижения ставки ЦБ (02.04.2026 00:32)
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- Неважно, на что вы фотографируете!
- Honor X80i ОБЗОР: плавный интерфейс, большой аккумулятор, объёмный накопитель
- Лучшие смартфоны. Что купить в апреле 2026.
- Что такое ISO в фотоаппарате
- Infinix Note 40 Pro+ выставлен на обзор
- Рекомендации нового поколения: объединяя визуальное и текстовое
2025-08-13 14:14