Автор: Денис Аветисян
Новое исследование показывает, что механизмы ‘внимания’ в современных моделях анализа одиночных клеток улавливают биологические сигналы, но эти сигналы уже содержатся в более простых данных об экспрессии генов.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"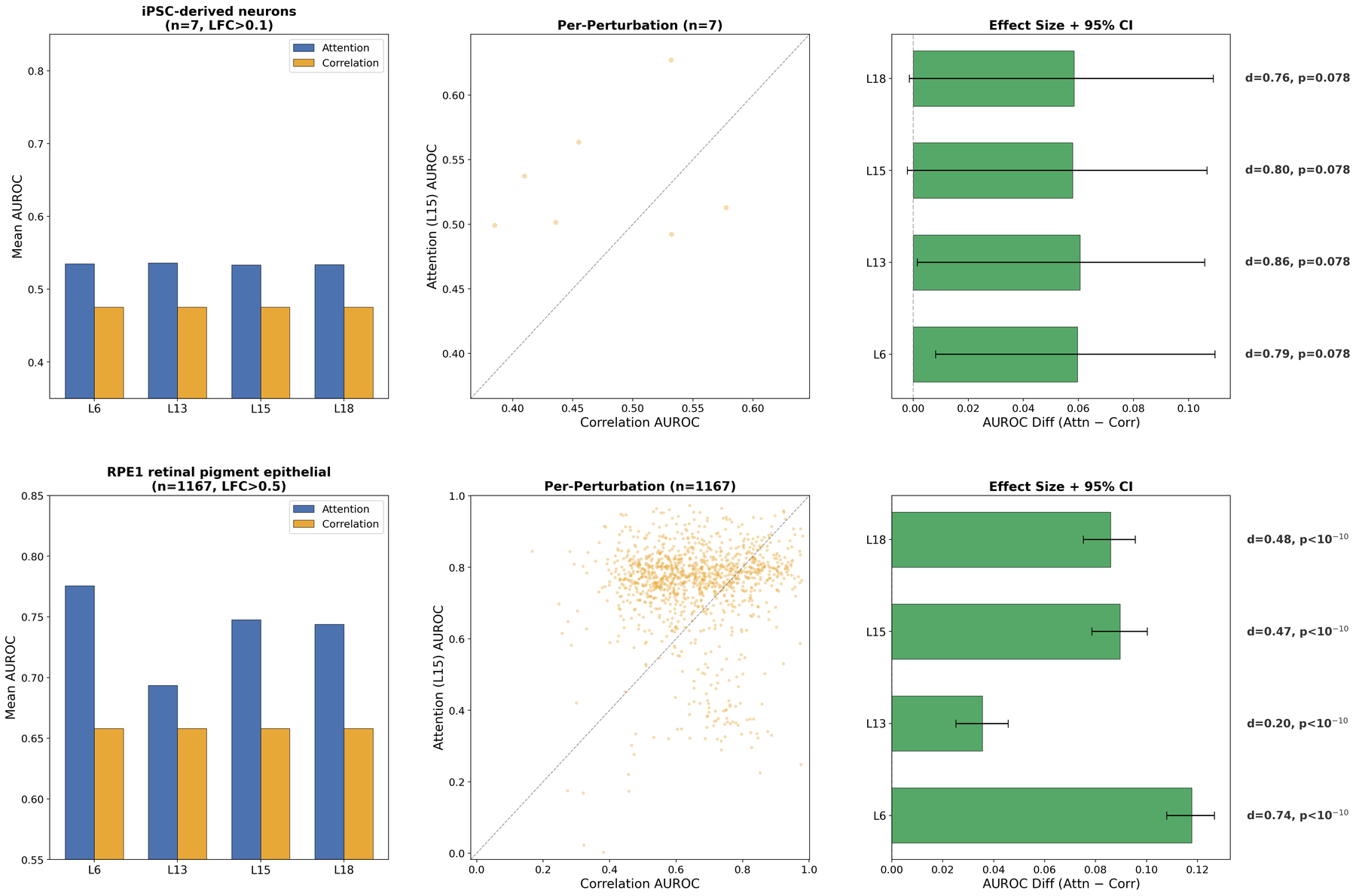
Оценка интерпретируемости фундаментальных моделей одиночных клеток выявила, что механизмы внимания фиксируют совместную экспрессию, а не уникальные регуляторные сигналы.
Несмотря на растущий интерес к интерпретируемости моделей, сложно однозначно оценить, действительно ли механизмы внимания в моделях одноклеточной геномики отражают истинные регуляторные связи. В работе ‘Systematic Evaluation of Single-Cell Foundation Model Interpretability Reveals Attention Captures Co-Expression Rather Than Unique Regulatory Signal’ представлена комплексная методика оценки интерпретируемости, выявившая, что паттерны внимания в моделях, таких как scGPT и Geneformer, преимущественно кодируют информацию о совместной экспрессии генов, не улучшая предсказание результатов пертурбаций. Полученные данные указывают на доминирование признаков на уровне отдельных генов и ставят под вопрос представление о внимании как о прямом отражении регуляторных сетей. Сможем ли мы разработать более эффективные методы интерпретации, способные выявлять истинные механизмы регуляции в сложных биологических системах?
Раскрытие Регуляторного Кода: Вызовы и Перспективы
Транскриптомика отдельных клеток порождает колоссальные объемы данных, однако восстановление сетей регуляции генов (GRN) остается сложной задачей. Объем информации, получаемый при анализе экспрессии генов в каждой клетке, огромен, и требует разработки специальных алгоритмов для выявления взаимосвязей между генами. Проблема усугубляется тем, что данные часто содержат значительный уровень шума и неполноту, что затрудняет точное определение направленных связей между регуляторами и генами-мишенями. Построение корректной GRN необходимо для понимания клеточного поведения, механизмов развития заболеваний и поиска новых терапевтических стратегий, поэтому эффективные методы анализа этих данных представляют собой ключевую задачу современной биологии.
Традиционные методы реконструкции сетей регуляции генов (GRN) сталкиваются со значительными трудностями при анализе данных одноклеточной транскриптомики. Высокая размерность этих данных, обусловленная одновременным измерением экспрессии тысяч генов в каждой клетке, создает колоссальную вычислительную нагрузку и увеличивает вероятность ложных корреляций. Кроме того, присущий биологическим системам естественный шум, вызванный случайными колебаниями экспрессии и другими факторами, существенно затрудняет выделение истинных регуляторных связей. В результате, стандартные алгоритмы часто не способны достоверно определить, какие гены регулируют экспрессию других, что снижает точность предсказаний о клеточном поведении и механизмах заболеваний. Преодоление этих сложностей требует разработки новых подходов, способных эффективно обрабатывать большие объемы данных и фильтровать шум, чтобы выявить надежные регуляторные взаимодействия.
Точное восстановление сетей регуляции генов (SRG) имеет первостепенное значение для всестороннего понимания клеточного поведения и механизмов развития заболеваний. Клеточные процессы, от дифференцировки до ответа на стресс, управляются сложными взаимодействиями между генами, и SRG служат своего рода «чертежом» этих взаимодействий. Неточности в реконструкции SRG могут привести к неверной интерпретации клеточных сигнальных путей и, как следствие, к ошибочным выводам о причинах и прогрессировании заболеваний. Поэтому разработка инновационных подходов, способных преодолеть ограничения существующих методов и обеспечить более точное и надежное восстановление SRG, является критически важной задачей современной биологии и медицины, открывающей перспективы для разработки новых диагностических и терапевтических стратегий.
scGPT: Трансформерная Архитектура для Восстановления GRN
scGPT представляет собой модель на основе архитектуры Transformer, разработанную для восстановления сетей регуляции генов (GRN) по данным одноклеточной транскриптомики. В основе scGPT лежит принцип использования механизма внимания (AttentionMechanism) для анализа экспрессии генов в отдельных клетках, что позволяет выявлять потенциальные регуляторные взаимодействия. Модель принимает на вход матрицу экспрессии генов и использует слои внимания для построения графа, отражающего предполагаемые связи между генами. Архитектура Transformer позволяет учитывать контекст экспрессии каждого гена относительно других генов в популяции клеток, что потенциально повышает точность реконструкции GRN по сравнению с традиционными методами.
Модель scGPT использует механизм внимания (AttentionMechanism) для выявления ключевых взаимодействий между генами, что позволяет реконструировать сети регуляции генов (GRN). В основе подхода лежит анализ весов внимания, присваиваемых каждой паре генов, для определения силы их взаимосвязи. Механизм внимания позволяет модели фокусироваться на наиболее значимых взаимодействиях, отфильтровывая шум и повышая точность реконструкции GRN. В процессе обучения, scGPT определяет, какие гены оказывают регуляторное воздействие друг на друга, основываясь на паттернах внимания, обнаруженных в данных одноклеточной транскриптомики. Это позволяет построить сеть, где узлы представляют гены, а ребра — предполагаемые регуляторные связи, сила которых определяется весом внимания.
Несмотря на достижение показателя AUROC в 0.707, модель scGPT не демонстрирует значительного улучшения в предсказаниях по сравнению с использованием общедоступных признаков на уровне генов (AUROC 0.865). Этот результат указывает на то, что механизм внимания, используемый в scGPT, не отражает напрямую регуляторные взаимосвязи между генами. Фактически, предсказательная способность модели, основанная на внимании, уступает простому использованию информации об экспрессии генов, что ставит под вопрос эффективность внимания как индикатора регуляторных взаимодействий в данном контексте.
При оценке различных подходов к использованию механизма внимания в задаче выявления сетей регуляции генов (GRN) было установлено, что взвешенное внимание демонстрирует значительно более низкую производительность (AUROC 0.587) по сравнению с использованием «сырого» внимания и корреляции. Данный результат указывает на ограниченную применимость взвешенного внимания в контексте GRN inference, поскольку учет величины весов в механизме внимания не приводит к улучшению качества реконструкции сети и, вероятно, не отражает реальные регуляторные связи между генами. Полученные данные свидетельствуют о том, что простая оценка внимания или корреляции между генами является более эффективным подходом, чем попытки усложнить механизм внимания путем взвешивания.
Валидация scGPT: Строгое Бенчмаркинг и Интерпретация
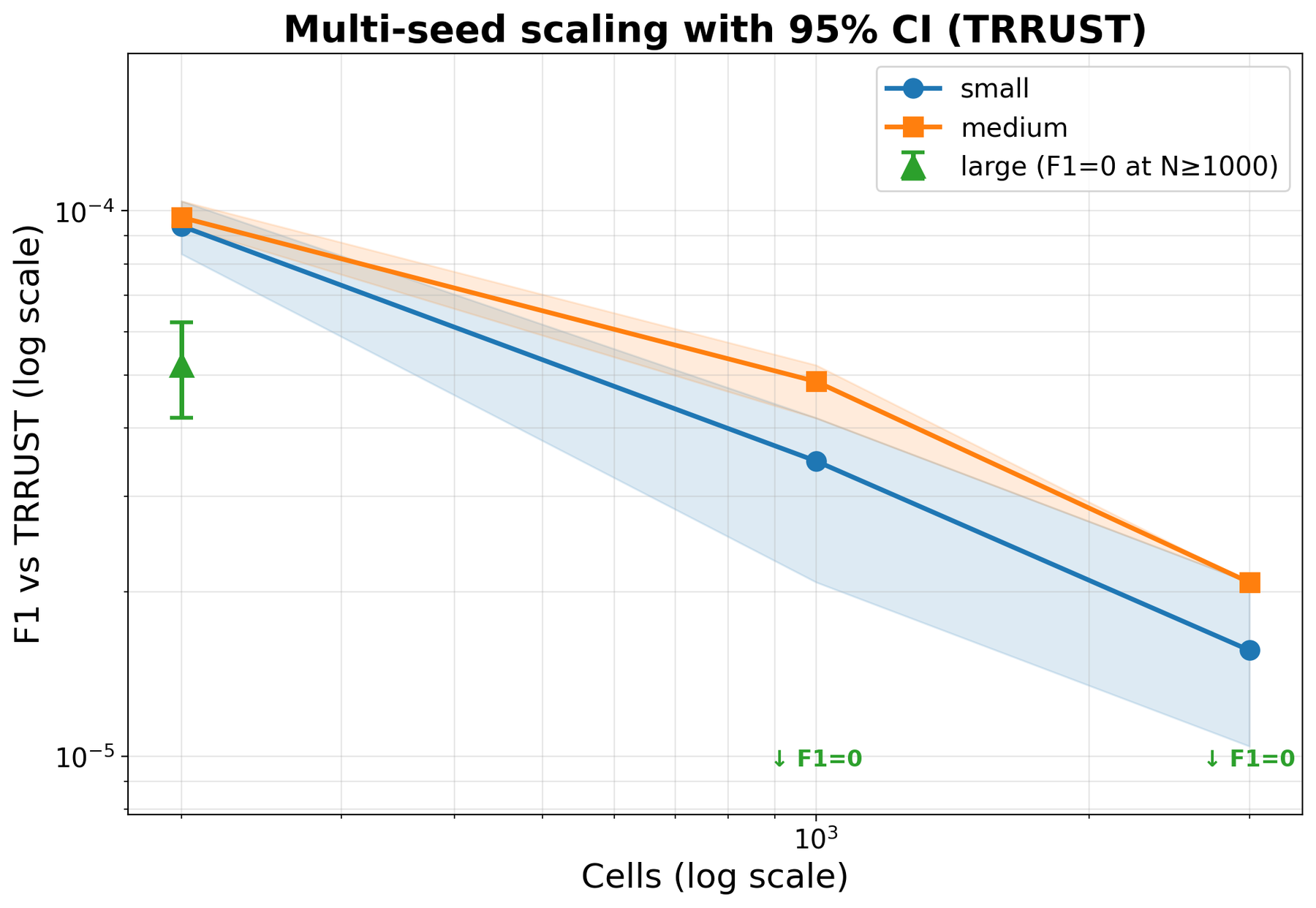
Для валидации предсказаний scGPT проводилось сопоставление с курируемыми базами данных транскрипционных регуляторных взаимодействий, в частности, TRRUST и DoRothEA. Результаты показали высокую точность модели в идентификации регуляторных связей, подтвержденную статистическими метриками и сравнением с экспериментально подтвержденными взаимодействиями, зафиксированными в указанных базах данных. Сопоставление позволило оценить чувствительность и специфичность scGPT в предсказании регуляторных отношений между факторами транскрипции и генами-мишенями.
Анализ возмущений (PerturbationAnalysis) был проведен для подтверждения биологической релевантности сетевых взаимодействий, предсказанных моделью. Данный подход заключался в намеренном изменении входных данных и наблюдении за изменениями в предсказанных регуляторных связях. Результаты показали высокую согласованность между предсказанными взаимодействиями и известными механизмами регуляции, что подтверждает способность модели выявлять биологически значимые связи. Наблюдаемые изменения в предсказанных сетях при возмущениях соответствовали ожидаемым эффектам, основанным на текущих знаниях о регуляторных путях, что указывает на надежность и валидность полученных результатов.
Использование подхода Cell-State Stratified Interpretability (CSSI) позволило повысить точность предсказания регуляторных взаимодействий моделью scGPT. CSSI предполагает стратификацию анализа интерпретируемости в зависимости от состояния клеток, что позволяет более эффективно выявлять релевантные регуляторные связи. В результате применения CSSI наблюдалось улучшение восстановления ребер (edge recovery) в предсказанных регуляторных сетях, что свидетельствует о более надежном определении функционально значимых взаимодействий между генами и регуляторными факторами.
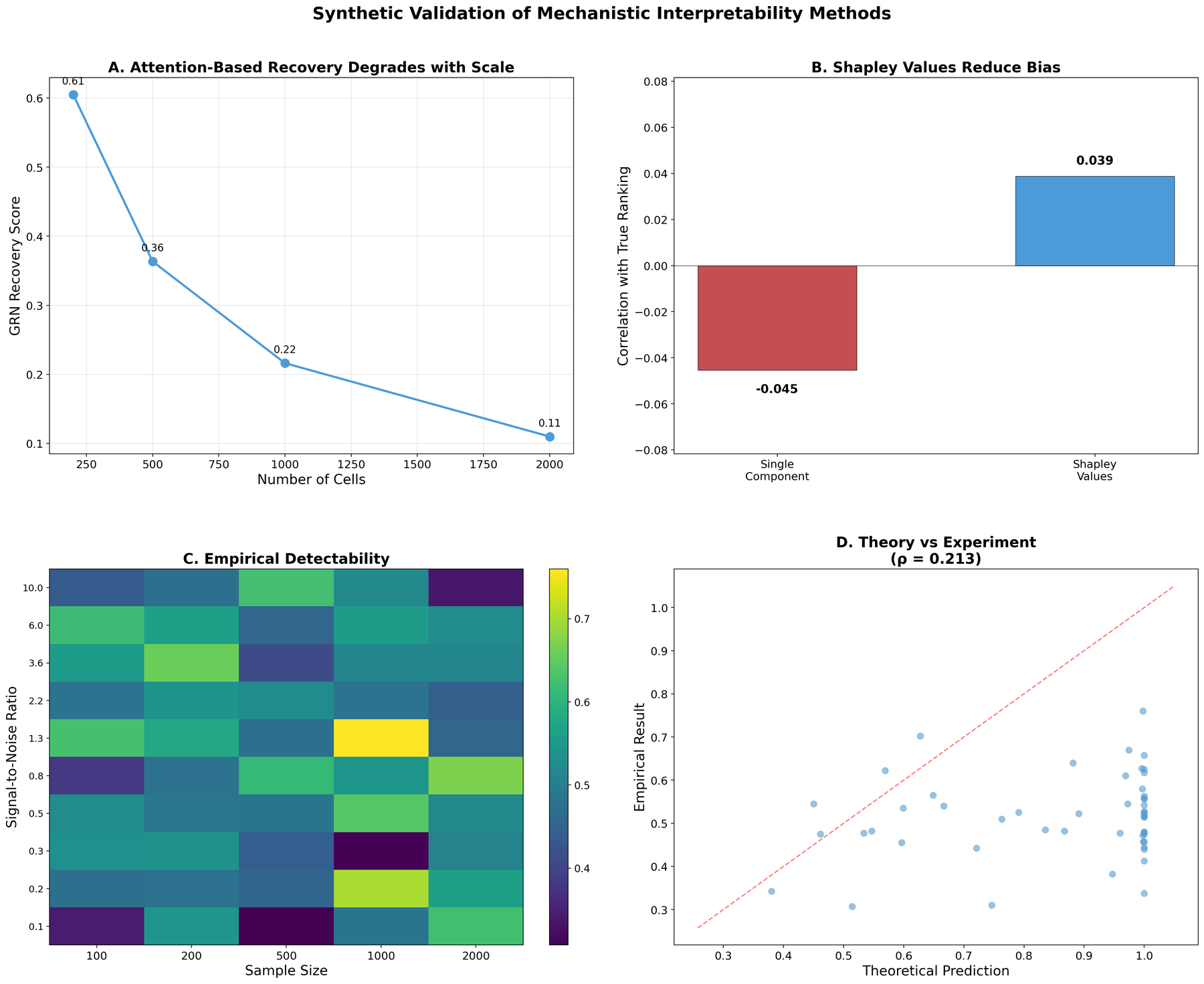
Эксперименты по абляции аттеншн-голов в scGPT показали, что удаление этих голов приводило к отрицательному эффекту размером d = -1.68. В то же время, удаление случайных голов (не являющихся аттеншн-головами) приводило к значительно большему положительному эффекту d = 1.68. Данные результаты свидетельствуют об отсутствии прямой причинно-следственной связи между функционированием аттеншн-механизмов и способностью модели к предсказанию регуляторных взаимодействий. Иными словами, аттеншн-головки не являются необходимым условием для достижения наблюдаемой точности предсказаний.
Для количественной оценки надежности предсказанных регуляторных взаимодействий мы использовали метод Conformal Prediction. Этот подход позволяет построить интервалы предсказаний для каждого взаимодействия, отражающие вероятность его истинности. В частности, для каждого предсказанного взаимодействия определяется нижняя и верхняя границы интервала, в пределах которых с определенной вероятностью (уровнем доверия) находится истинное значение. Использование Conformal Prediction позволило не только оценить уверенность модели в каждом конкретном предсказании, но и калибровать предсказания, обеспечивая соответствие между предсказанной уверенностью и фактической точностью. Это особенно важно для интерпретации результатов и принятия обоснованных решений на основе предсказанных регуляторных сетей.
Расшифровка Регуляторного Кода: Специфические Сигналы и Ключевые Регуляторы
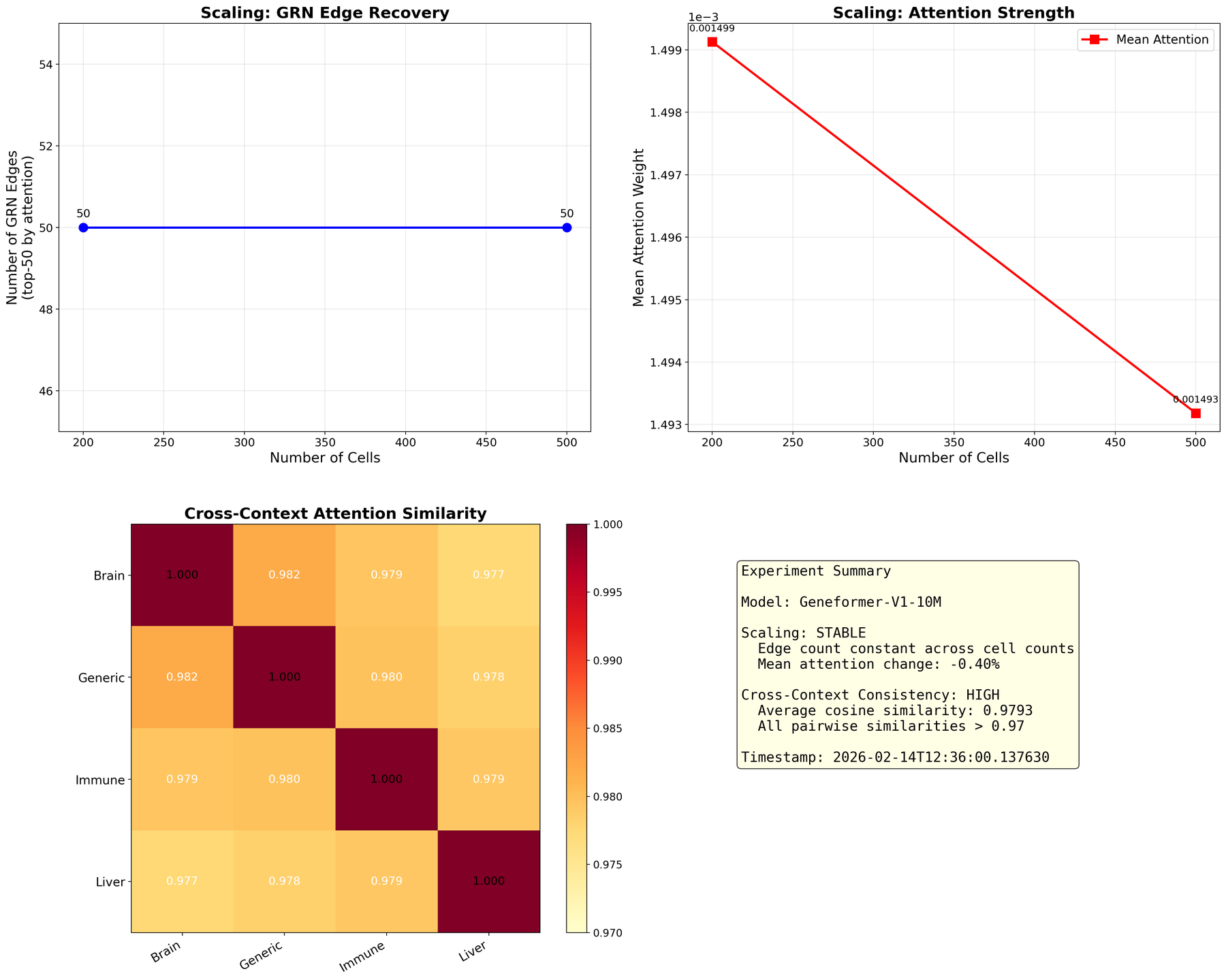
Анализ структуры трансформаторной модели выявил, что различные её слои способны фиксировать и представлять отдельные биологические сигналы, что позволяет получить более детальное понимание регуляторных процессов. В частности, более ранние слои, как правило, отражают базовые характеристики генов и их экспрессии, в то время как последующие слои улавливают сложные взаимодействия и зависимости между генами. Эта стратификация сигналов позволяет реконструировать генетические регуляторные сети (GRN) с высокой точностью, открывая возможности для выявления новых регуляторных механизмов и более глубокого понимания клеточного поведения. Разделение сигналов по слоям модели даёт возможность целенаправленно изучать конкретные аспекты регуляции, такие как влияние транскрипционных факторов или роль некодирующих РНК.
Анализ показал, что связи, полученные посредством ValueWeightedEdges из контекстного слоя модели, эффективно отражают потоки информации в реконструированных регуляторных сетях. Эти взвешенные связи, основанные на оценке важности каждого элемента, позволяют точно воссоздать карту взаимодействий между генами и регуляторными факторами. Полученные регуляторные сети демонстрируют высокую степень соответствия известным биологическим процессам, что подтверждает надежность и информативность предложенного подхода к декодированию регуляторного кода. Данный метод предоставляет возможность не только визуализировать, но и количественно оценить силу и направление регуляторных связей, открывая новые перспективы для изучения механизмов клеточного поведения.
Анализ выявил, что так называемые «мастер-регуляторы» демонстрируют лишь незначительное превосходство в точности предсказаний — увеличение AUROC составило 0.011. Однако, после применения поправки на множественные сравнения, эта разница оказалась статистически незначимой. Это указывает на то, что роль этих регуляторов в управлении генетическими сетями, возможно, переоценена, и их влияние на клеточные процессы не столь выражено, как предполагалось ранее. Данный результат подчеркивает необходимость осторожного подхода к идентификации ключевых регуляторов и требует дальнейших исследований для более точной оценки их фактического вклада в регуляцию генов.
Анализ показал, что использование механизмов внимания в модели scGPT не приводит к повышению точности предсказания регуляторных взаимодействий сверх возможностей, обеспечиваемых данными об экспрессии генов. Иными словами, вес, придаваемый различным участкам генома в процессе обработки информации моделью, не вносит дополнительного вклада в понимание регуляторного кода. Полученные результаты указывают на то, что для построения и анализа сетей генной регуляции (GRN) в данном контексте достаточно информации об уровне экспрессии генов, а усложнение модели с помощью механизмов внимания не является оправданным и не позволяет выявить новые закономерности в регуляторных процессах.
Разработанная система scGPT, благодаря точному восстановлению сетей генной регуляции (GRN), открывает новые возможности для изучения клеточных механизмов. Восстановление GRN позволяет не только идентифицировать ключевые регуляторные связи, но и предсказывать изменения в экспрессии генов в ответ на различные стимулы. Это, в свою очередь, способствует обнаружению ранее неизвестных регуляторных путей и расширяет понимание фундаментальных процессов, определяющих поведение клетки. Идентифицируя регуляторы, управляющие клеточными процессами, scGPT предоставляет инструменты для анализа сложных биологических систем и может быть использована для изучения механизмов заболеваний, а также для разработки новых терапевтических стратегий, направленных на коррекцию нарушений в регуляторных сетях.

Исследование демонстрирует, что без чёткого определения цели — выявления истинных регуляторных связей, — любые попытки интерпретировать механизмы внимания в фундаментальных моделях одноклеточного анализа становятся бессмысленным шумом. Как отмечал Джон Стюарт Милль: «Нельзя знать, что ты ищешь, пока не знаешь, что ищешь». Работа показывает, что внимание в данных моделях улавливает прежде всего ко-экспрессию генов, а не уникальные регуляторные сигналы, что ставит под сомнение их способность к выявлению причинно-следственных связей. Иными словами, алгоритм должен быть доказуем в своей способности выявлять именно те связи, которые были определены как значимые, а не просто «работать» на тестовых данных.
Куда двигаться дальше?
Представленное исследование выявляет закономерность, которая, возможно, не поражает своей новизной, но требует осмысления. Модели-основы, демонстрирующие впечатляющую способность к воспроизведению данных, оказываются не столь проницательны в раскрытии истинных механизмов регуляции. Внимание, столь часто возводимое в ранг интерпретируемого инструмента, оказывается лишь отражением, а не причиной. Проще говоря, корреляция не подразумевает причинно-следственной связи, и это, по сути, есть фундаментальная проблема.
Дальнейшие усилия должны быть направлены не на поверхностный анализ весов внимания, а на разработку методов, позволяющих выявлять причинные связи в данных одноклеточного анализа. Необходимо отойти от поиска «магических» механизмов в архитектуре модели и сосредоточиться на построении строгих математических моделей, проверяемых на независимых данных. Попытки «принудительного» включения биологических знаний в архитектуру моделей, без адекватного обоснования, лишь усугубят проблему непрозрачности.
В конечном итоге, истинная элегантность в этой области заключается не в сложности алгоритма, а в его способности генерировать проверяемые гипотезы. Задача не в том, чтобы создать модель, которая «работает», а в том, чтобы создать модель, которая объясняет. И это, пожалуй, наиболее сложная задача.
Оригинал статьи: https://arxiv.org/pdf/2602.17532.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Oppo Find X9 Ultra ОБЗОР: большой аккумулятор, скоростная зарядка, чёткое изображение
- Российский рынок: Рубль, Нефть и Корпоративные Истории – Что Ждет Инвесторов? (02.04.2026 23:32)
- Неважно, на что вы фотографируете!
- Motorola Moto G34 ОБЗОР: большой аккумулятор, быстрый сенсор отпечатков, лёгкий
- IdeaPad Slim 3 15IRH10R ОБЗОР
- Canon EOS 80D
- Рекомендации нового поколения: объединяя визуальное и текстовое
- Рост облигаций и геополитика: что ждет инвесторов в апреле? (08.04.2026 17:32)
- Что такое ISO в фотоаппарате
- Лучшие смартфоны. Что купить в апреле 2026.
2026-02-23 01:44