Автор: Денис Аветисян
Новое исследование показывает, что вдохновленные когнитивными процессами токены позволяют мультимодальным моделям преодолеть эгоцентрическую предвзятость и лучше понимать пространственные отношения.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"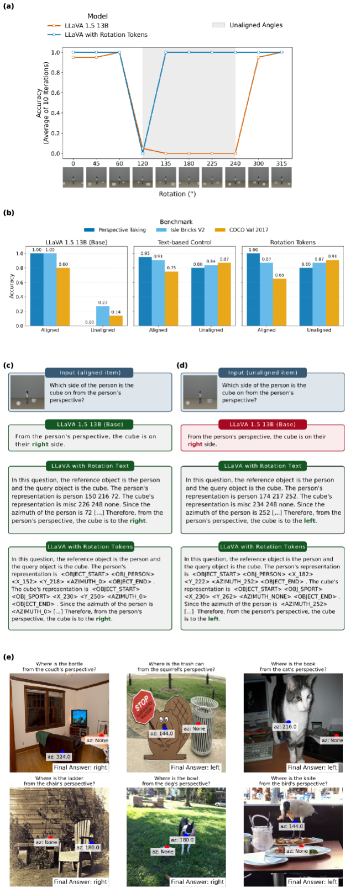
Внедрение пространственно структурированных токенов в мультимодальные языковые модели значительно улучшает их способность к визуальной перспективе и преодолению эгоцентрической предвзятости.
Несмотря на успехи в семантической обработке визуально-языковых задач, мультимодальные языковые модели демонстрируют ограниченные возможности в пространственном мышлении, особенно когда требуется принятие перспективы другого наблюдателя. В работе ‘Cognitively-Inspired Tokens Overcome Egocentric Bias in Multimodal Models’ предложен подход, вдохновленный когнитивными механизмами человека, с использованием специализированных токенов, кодирующих ориентацию в пространстве посредством телесных сигналов или абстрактных представлений, поддерживающих ментальный поворот. Интеграция этих токенов в LLaVA-1.5-13B позволила добиться значительного улучшения результатов в задачах, требующих визуальное принятие перспективы, демонстрируя преодоление присущей моделям эгоцентрической предвзятости. Может ли прямое внедрение когнитивно обоснованных пространственных структур в токенное пространство стать универсальным механизмом для достижения более человекоподобного пространственного мышления в мультимодальных моделях?
Понимание Перспективы: Преодоление Эгоцентричного Видения
Современные мультимодальные языковые модели (MLM) зачастую испытывают трудности с пониманием визуальной перспективы — способности представить себе, как выглядит сцена с точки зрения другого наблюдателя. Исследования показывают, что эти модели склонны к выраженному эгоцентризму, интерпретируя изображения преимущественно с собственной, фиксированной позиции. Данная особенность ограничивает их возможности в решении задач, требующих понимания пространственных отношений и альтернативных точек зрения, что негативно сказывается на эффективности применения в таких областях, как робототехника, навигация и анализ изображений с разных ракурсов. Проблема заключается не просто в распознавании объектов, а в способности моделировать изменение визуальной картины в зависимости от позиции наблюдателя.
Ограничение в способности к пониманию сцен с разных точек зрения существенно влияет на применимость мультимодальных языковых моделей в реальном мире. Например, для автономных систем навигации, робототехники или даже анализа медицинских изображений, крайне важно не просто распознавать объекты, но и предсказывать, как они выглядят и взаимодействуют с окружением с позиции другого наблюдателя. Неспособность учитывать альтернативные перспективы может привести к неверной интерпретации информации, ошибочным решениям и, как следствие, к неэффективной или даже опасной работе этих систем. Поэтому развитие способности к пониманию перспектив является ключевой задачей для создания действительно интеллектуальных и надежных искусственных систем.
Эффективное восприятие перспективы выходит далеко за рамки простой идентификации объектов на изображении. Для полноценного понимания сцены необходимо учитывать сложные пространственные взаимосвязи между элементами и способность мысленно представить себе эту же сцену с различных точек зрения. Исследования показывают, что модели, способные лишь распознавать объекты, испытывают трудности при решении задач, требующих понимания того, как меняется вид объектов при изменении позиции наблюдателя. Понимание перспективы подразумевает не просто «видение», а активное построение ментальной модели пространства, учитывающей взаимное расположение объектов и их относительные размеры, что позволяет предсказывать, как сцена будет выглядеть с любой другой позиции. Таким образом, способность к восприятию перспективы является ключевым элементом для создания искусственного интеллекта, способного полноценно взаимодействовать с окружающим миром.
Кодирование Перспективы: Токены для Пространственного Рассуждения
Представление точки зрения и ориентации объектов в виде токенов — дискретных единиц информации — является ключевым подходом в задачах пространственного рассуждения для языковых моделей. Вместо обработки непрерывных значений, таких как углы или координаты, информация о положении и ориентации кодируется в виде отдельных символов или чисел, которые могут быть обработаны архитектурами, основанными на трансформерах. Этот подход позволяет модели воспринимать и манипулировать пространственными отношениями, представляя их в формате, пригодном для обработки нейронными сетями. Использование токенов упрощает процесс обучения и повышает эффективность модели при решении задач, требующих понимания пространственного контекста.
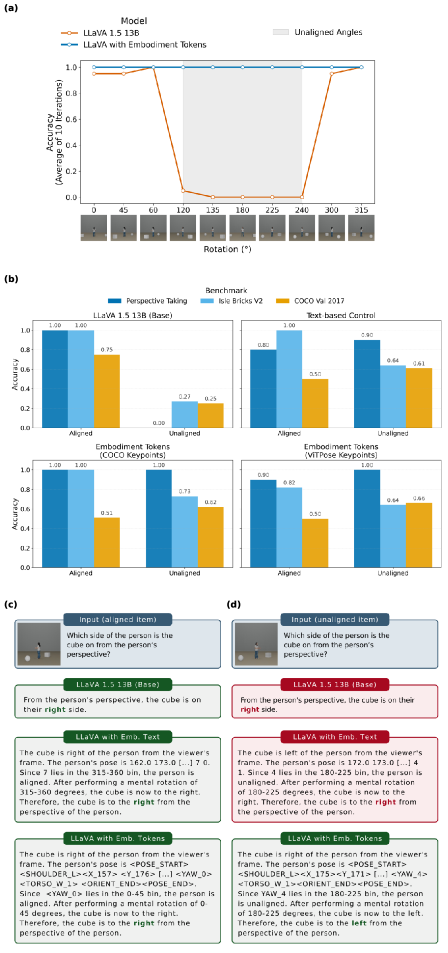
Для точного представления пространственного контекста используются токены, кодирующие информацию о положении и ориентации. Токены воплощения (Embodiment Tokens) фиксируют ключевые точки тела и рыскание (yaw), определяя позу агента. Токены вращения (Rotation Tokens) кодируют координаты объектов и азимут, позволяя модели учитывать их положение и ориентацию в пространстве. Комбинация этих типов токенов обеспечивает детальное представление сцены, необходимое для задач пространственного рассуждения и навигации.
Метод OrientAnything играет ключевую роль в извлечении значений азимута из изображений, что необходимо для создания точных Rotation Tokens для различных сцен. Этот метод позволяет определять угол поворота объекта относительно направления на север, основываясь на визуальной информации. Полученные значения азимута кодируются в Rotation Tokens, представляя собой дискретные единицы данных, которые отражают ориентацию объекта в пространстве. Точность извлечения азимута напрямую влияет на способность модели понимать и манипулировать пространственными отношениями в сложных визуальных сценах, обеспечивая корректную интерпретацию ориентации объектов.
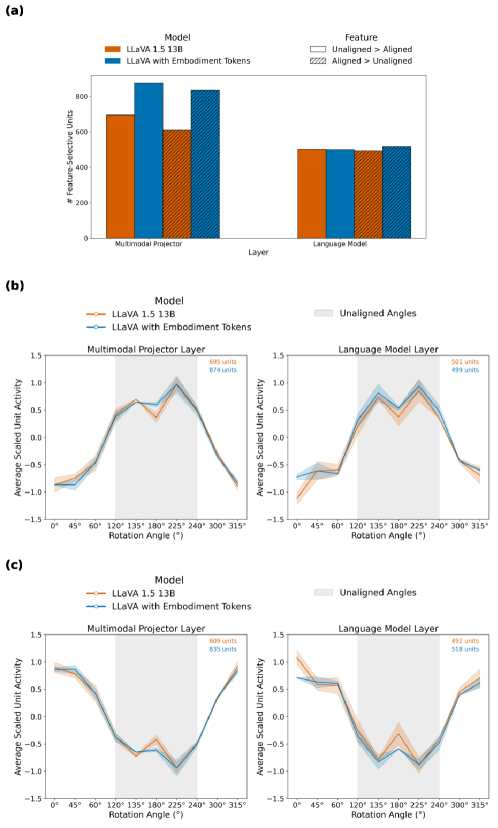
Токены, представляющие перспективу и ориентацию объектов, разработаны с учетом совместимости с архитектурами Transformer. Это позволяет языковым моделям обрабатывать дискретные единицы информации о пространственных отношениях, таких как положение и азимут объектов, как последовательности. Использование токенов в Transformer-моделях обеспечивает возможность анализа и манипулирования этими отношениями посредством механизмов внимания, что позволяет модели «понимать» и использовать информацию о пространственном контексте для решения различных задач, связанных с визуальным рассуждением и навигацией.
![Обучение и оценка проводились с использованием данных, варьирующих ориентацию аватара ([0°-360°]), кодирующих как ключевые точки тела и ориентацию (<span class="katex-eq" data-katex-display="false"> ext{yaw}</span>), так и координаты объектов и их азимут, при этом обучение последовательно переходило от генерации отдельных токенов к логическому выводу и прямому предоставлению ответов, увеличивая долю сложных задач с каждой эпохой.](https://arxiv.org/html/2601.16378v1/x1.png)
Обучение Пространственному Рассуждению: Последовательная Методика
В качестве базовой модели для адаптации и улучшения способностей к принятию перспективы был использован LLaVA 1.5 13B. Для эффективной тонкой настройки и снижения вычислительных затрат применена методика LoRA (Low-Rank Adaptation). LoRA позволяет оптимизировать модель, изменяя лишь небольшое количество параметров, что существенно сокращает время обучения и требования к памяти, сохраняя при этом высокую производительность в задачах, связанных с пониманием и моделированием различных точек зрения.
Обучение с использованием метода Curriculum Learning осуществлялось последовательно, начиная с задач генерации базовых токенов и постепенно переходя к более сложным задачам, требующим рассуждений о преобразованиях точки зрения. Данный подход позволил модели постепенно осваивать необходимые навыки, начиная с простых операций и заканчивая комплексным анализом изменений перспективы. Последовательное усложнение задач обучения способствовало повышению эффективности и точности модели при решении задач, связанных с определением и анализом изменений в перспективе, и позволило добиться значительных улучшений в способности модели к рассуждениям о преобразованиях точки зрения.
Метод побуждения “Цепочка рассуждений” (Chain-of-Thought Prompting) предполагает, что модель явно формулирует ход своих рассуждений перед предоставлением окончательного ответа. Это достигается путем включения в запрос подсказок, стимулирующих последовательное изложение логических шагов, что позволяет не только улучшить точность прогнозов, но и повысить прозрачность процесса принятия решений моделью. Явное представление рассуждений облегчает анализ ошибок и выявление слабых мест в логике модели, способствуя более эффективной отладке и совершенствованию.
Оценка модели на эталонных наборах данных, таких как 3DSRBench, Perspective-Taking Benchmark и Isle Bricks V2, продемонстрировала существенное улучшение в понимании перспективы второго уровня (Level 2 VPT). В частности, на несовпадающих элементах (unaligned items) эталонного набора Perspective-Taking Benchmark модель достигла 100% точности. Это свидетельствует о способности модели корректно интерпретировать сцены и объекты с разных точек зрения, даже когда эти точки зрения не соответствуют стандартным канонам или ожиданиям. Улучшения наблюдались и на других эталонных наборах, подтверждая обобщающую способность модели в задачах, связанных с пониманием перспективы.
В ходе экспериментов было установлено, что добавление токенов, обозначающих вращение, привело к значительному улучшению точности модели на различных наборах данных. В частности, на наборе Isle Bricks V2 (несовпадающие элементы) точность увеличилась на 59.1%, на валидационном наборе COCO (несовпадающие элементы) — на 77.1%, а на 3DSRBench — на 21.1%. Данные результаты демонстрируют способность модели обобщать знания и успешно применять полученные навыки к задачам, включающим негуманоидные ориентиры и перспективу.
При использовании на Perspective-Taking Benchmark (для несовмещенных элементов) модель продемонстрировала улучшение точности на 30% по сравнению с базовой моделью. Это улучшение было достигнуто за счет внедрения токенов, обозначающих вращение, что позволило модели более эффективно обрабатывать задачи, связанные с изменением точки зрения и пониманием пространственных отношений. Внедрение этих токенов способствовало более точному анализу визуальной информации и, как следствие, более надежным ответам в задачах, требующих учета перспективы.
Расширяя Горизонты: Применение и Будущие Направления
Модель LLaVA Aurora, в сочетании с методами, такими как Абстрактное Изменение Перспективы (APC), значительно расширяет возможности обработки визуальной информации и рассуждений о перспективе. Данный подход позволяет модели не просто идентифицировать объекты на изображении, но и понимать их взаимосвязь в пространстве, а также прогнозировать, как эти отношения изменятся при смене точки зрения. Подобное улучшение способности к визуальному мышлению открывает новые горизонты для создания систем, способных к более комплексному анализу изображений и, как следствие, к более естественному и интуитивно понятному взаимодействию с окружающим миром.
Успешное тестирование разработанного подхода на общедоступном наборе данных COCO подтверждает его способность к обобщению и применению к реальным, неидеализированным изображениям. Этот набор данных, содержащий широкий спектр сцен и объектов, представляет собой сложную задачу для систем компьютерного зрения. Достижение высоких результатов на COCO свидетельствует о том, что модель не просто “запоминает” обучающие примеры, но и способна извлекать существенные признаки и применять полученные знания к новым, ранее не встречавшимся визуальным данным. Это открывает перспективы для надежного функционирования системы в разнообразных и непредсказуемых условиях реального мира, обеспечивая более точную и адекватную интерпретацию визуальной информации.
Развитие моделей визуального мышления, таких как LLaVA Aurora, открывает новые перспективы для взаимодействия человека с технологиями в различных сферах. В робототехнике это позволяет создавать более адаптивные и интуитивно понятные системы, способные ориентироваться в сложном окружении и взаимодействовать с объектами, основываясь на визуальном восприятии. В области дополненной реальности, эти достижения способствуют созданию более реалистичных и отзывчивых интерфейсов, где виртуальные объекты гармонично интегрируются с реальным миром. Виртуальные помощники, оснащенные подобными возможностями, смогут не только понимать голосовые команды, но и интерпретировать визуальную информацию, предоставляя более контекстуальную и полезную помощь пользователям, что значительно улучшит естественность и эффективность взаимодействия.
В дальнейшем исследования будут сосредоточены на разработке более эффективных способов представления визуальной информации в виде токенов, что позволит снизить вычислительные затраты и повысить скорость обработки изображений. Параллельно планируется изучение возможностей интеграции концепций воплощенного интеллекта — то есть, обучения модели взаимодействию с виртуальным миром — для достижения более глубокого и реалистичного понимания пространственных отношений. Такой подход позволит не просто распознавать объекты на изображении, но и предсказывать их поведение, а также понимать их взаимосвязь в контексте окружающей среды, открывая перспективы для создания более интеллектуальных и адаптивных систем искусственного зрения.
Исследование демонстрирует, что внедрение пространственно структурированных токенов, вдохновленных когнитивными процессами человека, существенно улучшает способность мультимодальных языковых моделей к преодолению эгоцентричной предвзятости. Этот подход позволяет моделям более эффективно решать задачи визуальной перспективы, что подчеркивает важность учета пространственных отношений в обработке визуальной информации. Как однажды заметила Фэй-Фэй Ли: «Искусственный интеллект должен помогать людям, а не заменять их». Это особенно актуально в контексте данного исследования, поскольку улучшение способности моделей к пониманию перспективы открывает новые возможности для создания более интуитивно понятных и полезных систем взаимодействия человека и компьютера.
Что дальше?
Исследование закономерностей, лежащих в основе пространственного мышления, неизбежно сталкивается с вопросом: достаточно ли лишь “токенов”, имитирующих когнитивные процессы, для создания истинного понимания? Представленные результаты демонстрируют значительное улучшение в преодолении эгоцентрической предвзятости, однако, визуальное восприятие — это не только обработка пространственных отношений. Необходимо исследовать, как подобные модели справляются с динамическими сценами, меняющимися точками зрения и неполной информацией — условиями, в которых человеческий мозг преуспевает, а искусственные системы пока демонстрируют хрупкость.
Следующим этапом представляется не просто увеличение количества “токенов-вложений”, но и разработка архитектур, способных к абстрактному мышлению о пространстве. Можно ли создать модель, которая не просто “видит” поворот объекта, но и понимает его значение в контексте более сложной задачи? Ключевым представляется переход от пассивного представления пространственных данных к активному построению внутренних моделей мира, способных к прогнозированию и планированию.
В конечном счёте, вопрос заключается не в том, чтобы научить машину “видеть как человек”, а в том, чтобы понять, что значит “видеть” вообще. Изучение того, как модели используют и интерпретируют пространственную информацию, может пролить свет не только на природу искусственного интеллекта, но и на механизмы человеческого познания.
Оригинал статьи: https://arxiv.org/pdf/2601.16378.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- vivo iQOO Z10x ОБЗОР: яркий экран, удобный сенсор отпечатков, объёмный накопитель
- Лучшие смартфоны. Что купить в марте 2026.
- Новые смартфоны. Что купить в марте 2026.
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Нефть и бриллианты лидируют: обзор воскресных торгов на «СПБ Бирже» (08.03.2026 16:32)
- Неважно, на что вы фотографируете!
- Российский рынок: Нефть, геополитика и лидерство «Сбербанка» (11.03.2026 13:32)
- Infinix Note 60 Ultra ОБЗОР: скоростная зарядка, объёмный накопитель, отличная камера
- Realme 9 ОБЗОР: чёткое изображение, лёгкий, высокая автономность
- Руководство по Stellaris — Полное прохождение на 100%
2026-01-26 20:43