Автор: Денис Аветисян
Новый подход позволяет моделям лучше понимать изображения, динамически выбирая оптимальные слои для анализа в зависимости от сложности запроса.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"
Исследование демонстрирует, что выборочное использование слоев больших визуально-языковых моделей улучшает точность визуального обоснования и ответов на вопросы.
Несмотря на значительные успехи больших мультимодальных моделей в понимании изображений и текста, фиксированное количество визуальных токенов часто приводит к потере деталей и галлюцинациям. В работе ‘Beyond Static Cropping: Layer-Adaptive Visual Localization and Decoding Enhancement’ предложен новый подход, основанный на динамическом выборе слоев нейронной сети для визуальной локализации и декодирования. Авторы показали, что оптимальный слой для обработки визуальной информации зависит от сложности запроса, и предложили метод LASER, позволяющий адаптировать процесс к конкретной задаче. Может ли подобный адаптивный подход стать ключом к более надежному и точному визуальному мышлению у искусственного интеллекта?
Визуальное «Бутылочное Горлышко»: Ограничение Масштабных Моделей
Крупномасштабные модели, объединяющие зрение и язык (LVLM), сталкиваются с существенным ограничением, известным как “узкое место визуальных токенов”. Суть проблемы заключается в необходимости уменьшать размер изображений для обработки, что приводит к сжатию богатых визуальных данных до ограниченного числа токенов — дискретных единиц информации. Этот процесс неизбежно влечет за собой потерю детализации и тонких визуальных признаков, необходимых для точного анализа и глубокого понимания изображений. В результате, модели испытывают трудности в задачах, требующих внимательного рассмотрения мелких деталей и сложных визуальных взаимосвязей, что негативно сказывается на их общей производительности и способности к логическим выводам на основе визуальной информации.
Процесс сжатия визуальной информации, неизбежный при работе с большими языковыми моделями, приводит к потере ценных деталей и нюансов. Изначально богатый визуальный сигнал, содержащий тонкие различия в текстурах, формах и освещении, преобразуется в ограниченное число токенов, что фактически стирает важные доказательства. В результате, способность модели к точному рассуждению и глубокому пониманию изображений значительно снижается, поскольку она лишается возможности учитывать критически важные детали при ответе на сложные вопросы или выполнении аналитических задач. Потеря столь тонкой визуальной информации, подобно удалению ключевых фрагментов из пазла, препятствует формированию полной и корректной картины происходящего на изображении.
Вследствие сужения визуальной информации, большие визуально-языковые модели (LVLM) испытывают трудности при решении задач, требующих детального анализа изображений. Это особенно заметно при обработке сложных запросов, где необходимо учитывать мельчайшие визуальные детали и их взаимосвязи. Потеря тонких визуальных свидетельств приводит к снижению точности ответов и затрудняет понимание контекста, что напрямую влияет на способность модели к решению задач, требующих высокой степени визуальной проницательности, например, в областях диагностики, детальной инспекции или точной идентификации объектов на изображениях.
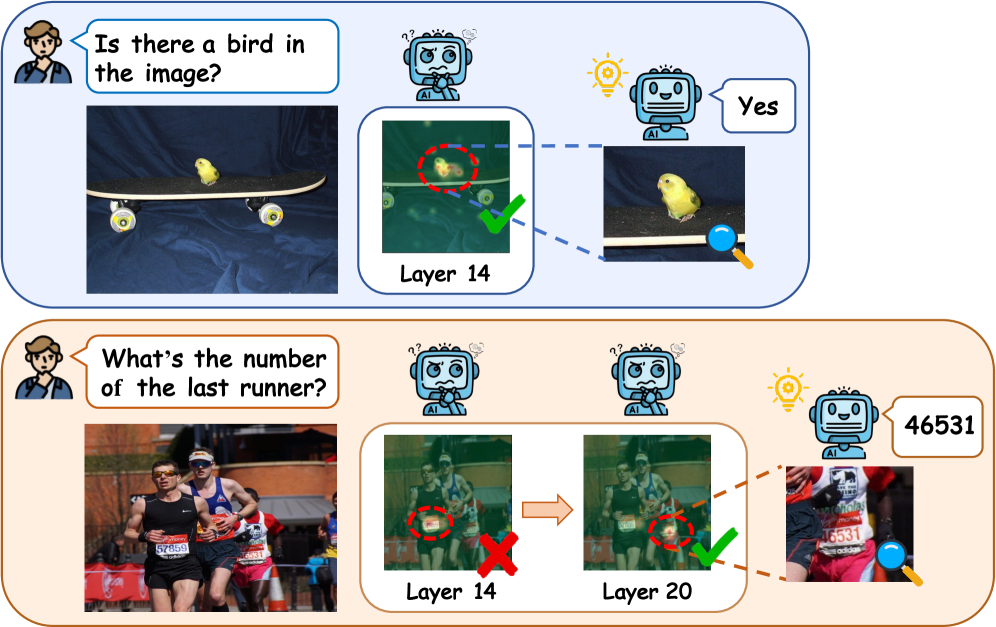
Внимание к Деталям: Визуальная Локация на Основе Внимания
Методы, такие как ‘Фиксированное Внимание’ (Fixed-Layer Attention) и ‘Контрастное Внимание’ (Contrastive Attention), совершенствуют методы визуальной локации, управляемой вниманием. Оба подхода используют карты внимания для выделения релевантных областей изображения, позволяя моделям фокусироваться на наиболее важных визуальных признаках. ‘Фиксированное Внимание’ обычно реализуется как набор предопределенных слоев, обрабатывающих признаки изображения для генерации карты внимания, в то время как ‘Контрастное Внимание’ использует механизмы сравнения признаков для выявления наиболее отличительных областей, которые, вероятно, соответствуют целевому объекту. Оба метода направлены на повышение точности определения местоположения объектов на изображении за счет улучшения процесса фокусировки внимания модели.
Методы, использующие карты внимания (attention maps), позволяют моделям визуальной локализации концентрироваться на наиболее значимых областях изображения. Карты внимания представляют собой весовые коэффициенты, присваиваемые различным участкам изображения, указывающие на их релевантность для поставленной задачи. Более высокие веса соответствуют областям, которые модель считает наиболее важными для определения местоположения объекта или сцены. Использование карт внимания позволяет отфильтровать отвлекающие факторы и повысить точность локализации, поскольку модель фокусируется исключительно на визуальных признаках, имеющих наибольшее значение для решения задачи. Это особенно полезно в сложных сценах с множеством объектов или при наличии шума и помех.
Оценка предложенных методов внимания проводилась на наборе данных RefCOCO, что позволило продемонстрировать повышение точности визуального обоснования и локализации. Эксперименты показали, что использование карт внимания для выделения релевантных областей изображения значительно улучшает способность моделей к точному определению местоположения объектов, описанных в текстовых запросах. На RefCOCO наблюдалось увеличение метрик, характеризующих успешность визуального обоснования, подтверждающих эффективность предложенных подходов в задачах, требующих сопоставления текста и изображения.
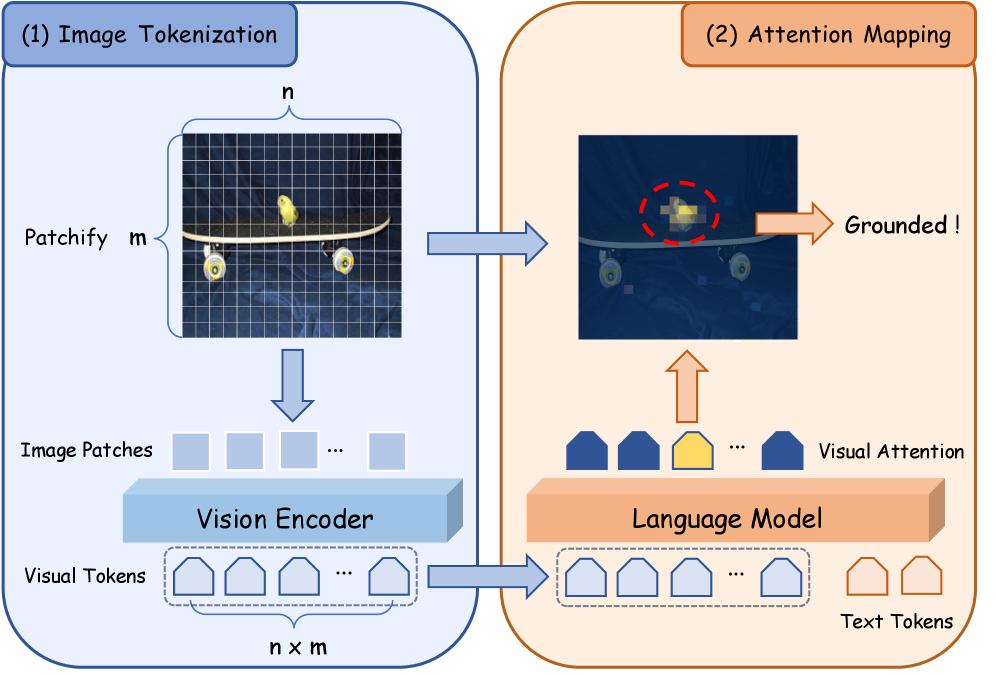
LASER: Новая Архитектура для Улучшенного Визуального Рассуждения
Фреймворк LASER представляет собой решение, не требующее обучения, для улучшения визуальной локализации и декодирования, ориентированное на запрос. В его основе лежит механизм контрастного внимания, позволяющий выделять и усиливать визуальные сигналы, релевантные заданному запросу. Этот подход позволяет модели более эффективно фокусироваться на значимых областях изображения, не требуя дополнительной настройки или обучения с использованием размеченных данных. LASER обеспечивает улучшение производительности за счет оптимизации процесса внимания, направляя ресурсы модели на наиболее информативные части визуального ввода.
Механизм контрастивного внимания в LASER позволяет эффективно выделять и усиливать визуальные сигналы, релевантные запросу, что способствует улучшению фокусировки модели. Этот процесс заключается в сопоставлении визуальных токенов с запросом и выделении тех, которые демонстрируют наибольшую степень соответствия. Усиление этих релевантных сигналов достигается путем подавления менее значимых, что приводит к более четкому представлению ключевой визуальной информации. В результате, модель LASER способна более точно идентифицировать и локализовать объекты, соответствующие заданному запросу, повышая общую производительность в задачах визуального рассуждения.
Метод ‘Уточнение Области’ (Region Refinement) расширяет возможности LASER за счет смягчения проблемы нехватки визуальных токенов. Это достигается путем повышения эффективности обработки визуальной информации, что приводит к улучшению производительности в задачах, требующих детального визуального анализа. Экспериментальные данные показывают, что применение данного метода приводит к более высокой степени визуального обоснования (visual grounding), подтвержденной повышенным коэффициентом агрегации внимания (Attention Aggregation Ratio) по сравнению с использованием стандартного внимания (Raw Attention) и относительного внимания (Relative Attention).
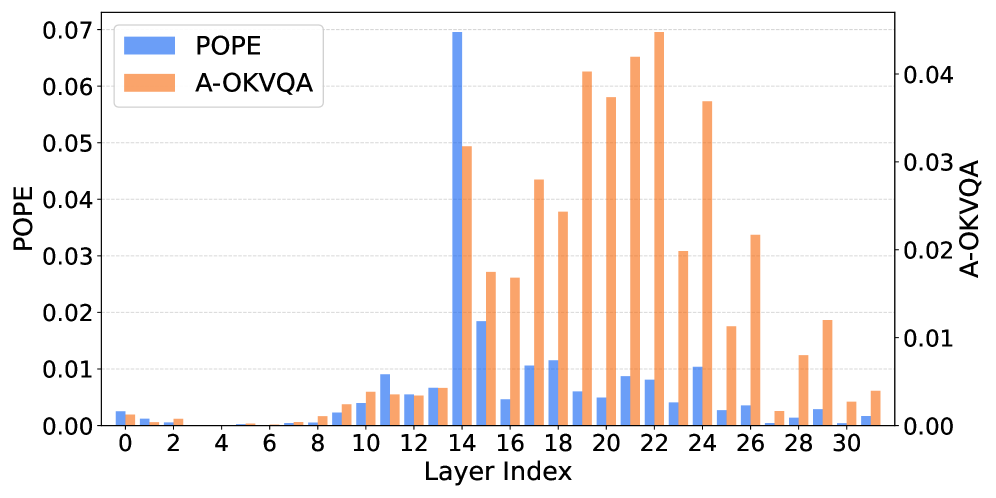
Надёжность и Обобщение: Проверка Эффективности LASER
Оценка модели LASER проводилась на разнообразных наборах данных, включая ‘POPE’, ‘TextVQA’ и ‘A-OKVQA’, что позволило продемонстрировать её превосходство над существующими подходами в задачах, связанных с визуальным поиском, логическим выводом и использованием внешних знаний. Особенно заметны улучшения в предотвращении “галлюцинаций” объектов — то есть, когда модель ошибочно идентифицирует несуществующие элементы на изображении. Результаты показывают, что LASER не только точнее распознает объекты, но и надежнее интерпретирует визуальную информацию в контексте текстовых запросов, что делает её перспективным решением для широкого спектра приложений, требующих комплексного понимания изображений и текста.
Несмотря на значительные улучшения в производительности, внедрение LASER сопряжено с умеренным увеличением вычислительных затрат. Эксперименты показали, что время обработки данных для модели LLaVA-1.5 увеличивается на 33.33%, а для Qwen-VL — на 43.06%. Данный прирост вычислительной нагрузки обусловлен динамическим выбором слоев, позволяющим модели адаптироваться к сложности запроса, однако требует дополнительных ресурсов для анализа и обработки информации на каждом этапе. Несмотря на это, разработчики подчеркивают, что полученные преимущества в точности и понимании визуального контента оправдывают умеренное увеличение времени обработки.
Особенностью архитектуры LASER является нестатичный выбор слоев нейронной сети. Анализ показывает, что наиболее глубокий, четырнадцатый слой, активируется лишь в 32.55% случаев. Этот динамический подход к выбору слоев подчеркивает способность LASER адаптироваться к различной сложности запросов. Вместо фиксированного использования всех слоев, система оценивает каждый запрос и активирует только те слои, которые необходимы для эффективного решения задачи, что обеспечивает оптимальное использование вычислительных ресурсов и повышает общую производительность модели при решении разнообразных задач визуального мышления.
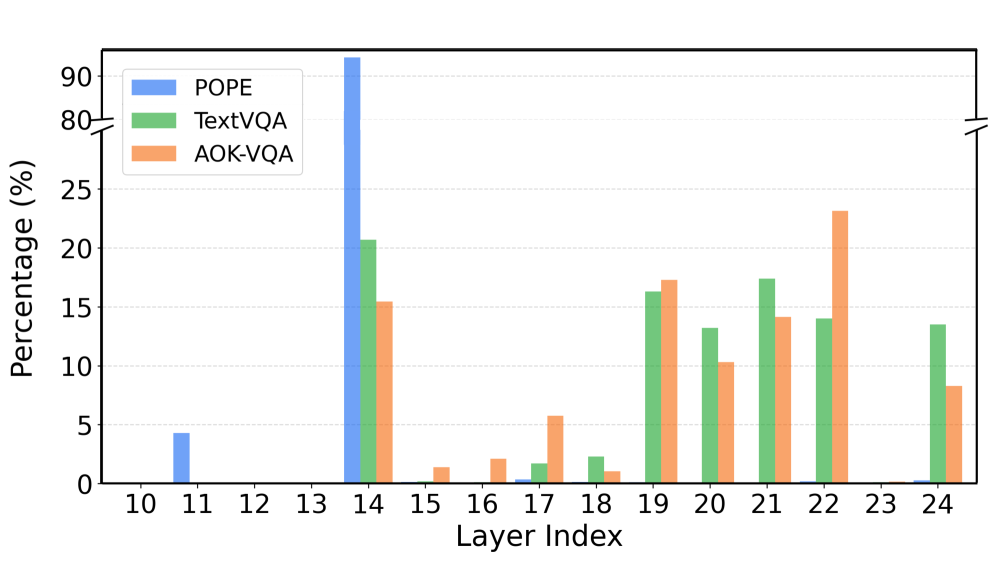
Исследование закономерностей в больших визуально-языковых моделях демонстрирует, что оптимальный слой для визуального определения зависит от сложности запроса. Подобно тому, как в биологических системах различные уровни обработки информации отвечают за разные задачи, так и в нейронных сетях выбор слоя играет критическую роль. Эндрю Ын однажды сказал: «Машинное обучение — это искусство превращения данных в знания». Эта фраза особенно актуальна в контексте данной работы, поскольку авторы предлагают метод динамического выбора слоев, позволяющий извлекать более точные знания из визуальной информации и улучшать ответы на вопросы. Это подтверждает идею о том, что понимание системы требует исследования её закономерностей, а визуальные данные раскрывают мир, если их интерпретировать через строгую логику и креативные гипотезы.
Что дальше?
Представленная работа, демонстрируя зависимость оптимального слоя в больших визуально-языковых моделях от сложности запроса, открывает любопытную перспективу. Однако, следует признать, что выбор «лучшего» слоя — это лишь частное решение в более общей проблеме понимания внутренней архитектуры этих моделей. Зависимость от сложности запроса — закономерность, безусловно, важная, но её количественная оценка и обобщение на другие задачи и архитектуры остаются открытыми вопросами. По сути, мы наблюдаем не столько «интеллект» модели, сколько её адаптацию к определенному набору стимулов.
Дальнейшие исследования, вероятно, будут направлены на разработку более гибких механизмов динамического выбора слоев, возможно, с использованием мета-обучения или обучения с подкреплением. Интересным направлением представляется изучение взаимодействия между слоями — не просто выбор одного, а комбинирование информации из нескольких слоев для достижения оптимального результата. Стоит также задуматься о том, как эти механизмы могут быть применены к другим модальностям, например, к аудио или тексту.
В конечном итоге, понимание того, как информация обрабатывается внутри этих сложных систем, требует не только совершенствования алгоритмов, но и развития более глубокой теоретической базы. Простое улучшение метрик производительности — это лишь поверхностный симптом; истинное понимание — это исследование закономерностей, лежащих в основе визуального и языкового восприятия.
Оригинал статьи: https://arxiv.org/pdf/2602.04304.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Рынок в ожидании ставки: что ждет рубль, нефть и акции? (20.03.2026 01:32)
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- СПБ Биржа: «Газпром» в фаворе, «Т-техно» под давлением, дефицит юаней тревожит инвесторов (22.03.2026 22:33)
- Искусственные мозговые сигналы: новый горизонт интерфейсов «мозг-компьютер»
- vivo S50 Pro mini ОБЗОР: объёмный накопитель, портретная/зум камера, большой аккумулятор
- Макросъемка
- Cubot Note 60 ОБЗОР: плавный интерфейс, большой аккумулятор
- Российский рынок: между ростом потребления газа, неопределенностью ФРС и лидерством «РусГидро» (24.12.2025 02:32)
- Космос в деталях: Навигация по астрономическим данным на иммерсивных дисплеях
- Infinix GT 20 Pro ОБЗОР: замедленная съёмка видео, тонкие рамки, большой аккумулятор
2026-02-06 04:08