Автор: Денис Аветисян
Исследователи представили систему JAEGER, позволяющую моделям искусственного интеллекта лучше ориентироваться и взаимодействовать с виртуальными пространствами, используя объёмное аудио и видео.
Пока крипто-инвесторы ловят иксы и ликвидации, мы тут скучно изучаем отчетность и ждем дивиденды. Если тебе близка эта скука, добро пожаловать.
Купить акции "голубых фишек"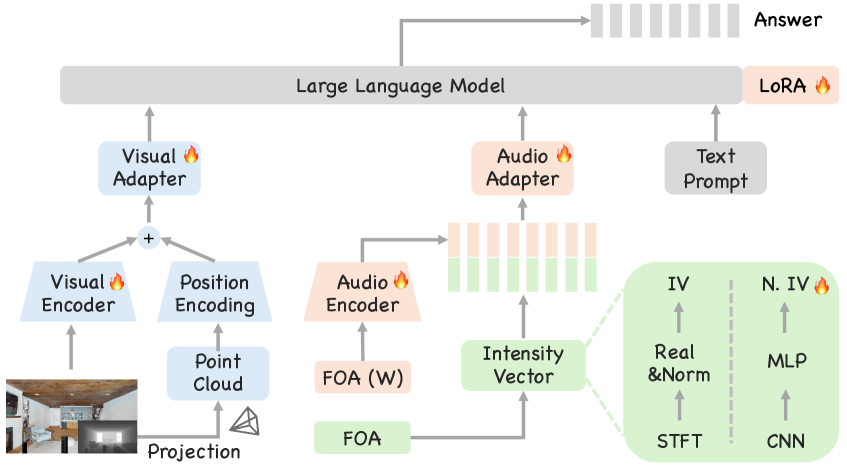
JAEGER объединяет трёхмерное восприятие звука и изображения с большими языковыми моделями для повышения точности пространственного рассуждения в симулированных физических средах.
helpСовременные аудиовизуальные большие языковые модели (AV-LLM) преимущественно ограничены двухмерным восприятием, что препятствует надежной локализации источников и пространственному рассуждению в сложных трехмерных средах. В данной работе представлена система ‘JAEGER: Joint 3D Audio-Visual Grounding and Reasoning in Simulated Physical Environments’ — фреймворк, расширяющий возможности AV-LLM за счет интеграции RGB-D данных и многоканального звука для совместного пространственного обоснования и рассуждений. Ключевым вкладом является нейронный вектор интенсивности (Neural IV) — обучаемое представление пространственного звука, повышающее точность оценки направления на источник, даже в сложных акустических условиях. Не откроет ли это путь к созданию более интеллектуальных и адаптивных систем искусственного интеллекта, способных эффективно взаимодействовать с физическим миром?
Шёпот Пространства: Вызовы Трёхмерного Звука
Точное воссоздание пространственного звука требует не просто записи аудиосигналов, но и полноценного захвата и представления трехмерных звуковых ландшафтов. Однако, существующие методы, применяемые в этой области, часто оказываются недостаточными для достижения реалистичного звучания. Традиционные подходы сталкиваются с трудностями при моделировании сложных акустических сцен, что приводит к потере пространственной информации и снижению эффекта погружения. Проблема заключается в том, что стандартные техники не всегда способны адекватно передать нюансы отражений, дифракции и других явлений, формирующих восприятие звука в реальном пространстве. Это требует разработки новых, более совершенных методов захвата и обработки звука, способных точно воспроизводить все особенности трехмерного звукового окружения.
Традиционные методы, такие как Ambisonics первого порядка (FOA), несмотря на свою широкую распространенность, зачастую оказываются недостаточно точными для создания по-настоящему реалистичных и захватывающих звуковых ландшафтов. Хотя FOA и позволяет передать общее направление звука, его ограниченное разрешение не способно адекватно воспроизвести сложные отражения, дифракцию и другие тонкости, определяющие восприятие звука в реальном пространстве. В результате, прослушивание с использованием FOA может ощущаться несколько размытым или неестественным, особенно в сценариях с большим количеством источников звука или сложной акустической обстановкой. Это подчеркивает необходимость разработки более продвинутых технологий, способных улавливать и воспроизводить звук с большей детализацией и точностью, чтобы обеспечить подлинный эффект присутствия.
Существующие методы пространственного аудио, несмотря на свою распространенность, часто оказываются неспособными достоверно воспроизвести звуковую картину в сложных сценах. Проблемы возникают при моделировании реалистичных отражений, дифракции и окклюзии звука, особенно в помещениях с неровными поверхностями или в открытом пространстве с большим количеством препятствий. Это приводит к ощущению неестественности и снижает эффект погружения. В связи с этим, возникает потребность в разработке более усовершенствованных техник, способных учитывать сложные акустические явления и обеспечивать высокоточное воссоздание звуковой среды. Новые подходы включают в себя использование методов трассировки лучей, волновых уравнений и машинного обучения для моделирования распространения звука и создания убедительных, реалистичных звуковых ландшафтов.
Для достоверного моделирования пространственного звука недостаточно просто зафиксировать звуковые волны; необходимо глубокое понимание их взаимосвязи с трехмерным окружением. Исследования показывают, что реалистичное восприятие звука напрямую зависит от акустических свойств пространства — размеров помещений, материалов поверхностей, наличия препятствий и отражающих элементов. Звук, распространяясь в пространстве, претерпевает изменения, обусловленные этими факторами, формируя уникальную звуковую картину. Таким образом, точное воссоздание звуковой сцены требует не только записи звука, но и детального анализа и моделирования акустического поведения пространства, что позволяет создать эффект полного погружения и достоверного присутствия.
JAEGER: Раскрытие Трёхмерного Аудио-Визуального Разума
JAEGER представляет собой комплексный метод совместного 3D аудио-визуального рассуждения и привязки к пространству, использующий возможности больших аудио-визуальных языковых моделей (AV-LLM). В отличие от традиционных подходов, JAEGER интегрирует аудио- и визуальные данные для создания целостного представления сцены, что позволяет модели не только идентифицировать объекты, но и понимать их пространственные отношения и источники звука. Использование AV-LLM позволяет JAEGER эффективно обрабатывать сложные взаимосвязи между аудио- и визуальной информацией, что приводит к более точному определению местоположения источников звука и улучшенному пониманию происходящего в сцене. Данный подход позволяет модели выполнять задачи, требующие одновременного анализа как звуковых, так и визуальных данных, например, определение объекта, издающего звук, или понимание контекста звукового события в визуальной сцене.
JAEGER использует данные RGB-D (цвет и глубина) для формирования детального представления сцены, что позволяет устанавливать связь между звуками и конкретными объектами и их местоположениями в пространстве. Получаемая информация о глубине позволяет точно определить трехмерную структуру окружения, а данные RGB обеспечивают визуальную идентификацию объектов. Сочетание этих двух типов данных позволяет системе JAEGER не только обнаруживать звуковые события, но и соотносить их с визуальными элементами сцены, что необходимо для точной локализации источников звука и понимания происходящих событий. Это обеспечивает основу для совместного аудиовизуального рассуждения и определения местоположения звуков в трехмерном пространстве.
Ключевым нововведением в JAEGER является Neural Intensity Vector (NIV) — обучаемое представление, улучшающее информацию о направлении и локализацию звука. NIV опирается на концепцию First-Order Ambisonics (FOA), но расширяет ее возможности за счет обучения. В отличие от фиксированных весов FOA, NIV позволяет модели адаптировать представление звукового поля для повышения точности определения направления на звук и его источника. Это достигается путем обучения весов, которые оптимально кодируют информацию о направлении звука, что приводит к более надежной локализации в сложных акустических условиях.
В ходе симуляций многопользовательских аудиовизуальных сред, JAEGER демонстрирует практически безошибочную точность (99.2%) в совместном аудиовизуальном рассуждении. Данный результат подтверждает эффективность предложенного подхода в решении сложных задач пространственного анализа и позволяет надежно соотносить звуковые события с соответствующими объектами и локациями в трехмерной среде. Высокая точность указывает на способность JAEGER эффективно интегрировать аудио- и визуальную информацию для точного понимания и интерпретации происходящего в динамических и сложных сценах.
При оценке производительности JAEGER, медианная ошибка определения направления прихода звука (DoA) для одиночных источников звука составила 2.21°. Этот показатель сопоставим с результатами, полученными с использованием baseline модели BAT. Точность определения DoA является ключевым показателем эффективности систем пространственного аудирования, и достигнутый JAEGER уровень указывает на его способность точно локализовать источники звука в пространстве, не уступая существующим решениям. Данный результат был получен при использовании стандартных метрик и протоколов оценки, обеспечивающих сопоставимость с другими системами.
В сложных сценариях с перекрывающимися источниками звука, система JAEGER демонстрирует превосходство над базовым алгоритмом BAT в определении направления на источник звука (Direction of Arrival, DoA). В частности, JAEGER снижает медианную ошибку DoA с 19.09° до 13.13°. Данное улучшение свидетельствует о более эффективной способности системы разделять и локализовать несколько источников звука в условиях акустических помех, что критически важно для приложений, требующих точной пространственной ориентации на звук.
В ходе оценки JAEGER продемонстрировал конкурентоспособные результаты в задачах 3D-локализации объектов. Средний показатель 3D Intersection over Union (IoU) составил 0.32, что свидетельствует о точности определения пространственного перекрытия между предсказанными и реальными границами объектов. Дополнительно, JAEGER достиг средней ошибки визуальной локализации в 0.16 метра, указывая на высокую точность определения местоположения объектов в трехмерном пространстве. Эти метрики подтверждают способность JAEGER эффективно интегрировать аудиовизуальную информацию для точной локализации и понимания сцены.

SpatialSceneQA: Платформа для Развития Пространственного Слуха
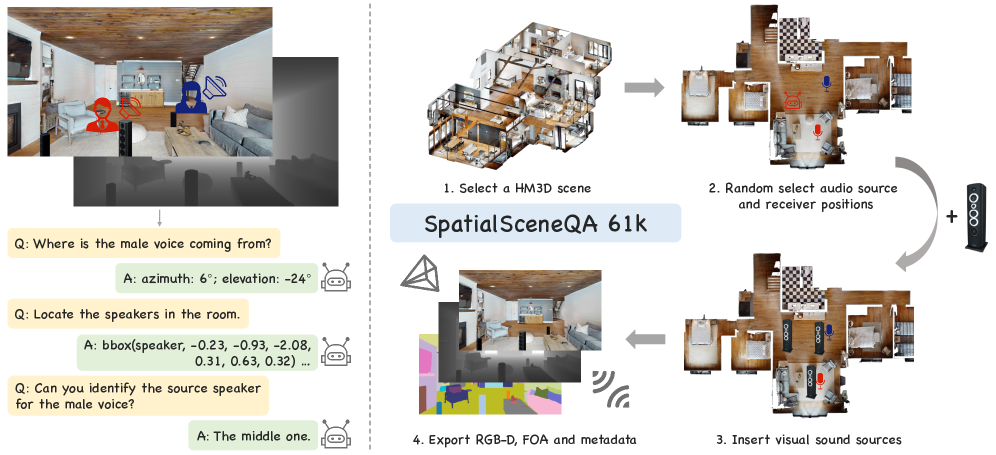
Набор данных SpatialSceneQA был разработан для оценки и стимулирования прогресса в области трехмерного аудио-визуального рассуждения. Его создание обусловлено необходимостью в стандартизированном бенчмарке, позволяющем объективно измерять и сравнивать производительность алгоритмов, способных интегрировать визуальную и звуковую информацию для понимания пространственной среды. Данный набор данных предназначен для поддержки исследований в области робототехники, компьютерного зрения и искусственного интеллекта, где понимание пространственного контекста звуковых событий имеет ключевое значение.
Набор данных SpatialSceneQA состоит из высококачественных RGB-D сцен, объединенных с пространственным аудио и точными 3D аннотациями, что обеспечивает комплексную платформу для оценки и сравнения моделей пространственного аудио-визуального рассуждения. Каждая сцена содержит информацию о цвете (RGB), глубине (D) и пространственном расположении объектов, а также соответствующее звуковое сопровождение, смоделированное с учетом геометрии сцены. Предоставленные 3D аннотации включают в себя точные координаты и размеры объектов, что позволяет проводить детальный анализ взаимосвязи между визуальными и звуковыми элементами в пространстве. Такая структура позволяет оценивать способность моделей к пониманию и интерпретации пространственных отношений, что необходимо для создания реалистичных и интерактивных мультимедийных приложений.
Для создания реалистичных сцен и звукового сопровождения в наборе данных SpatialSceneQA используются передовые симуляторы, такие как Habitat-Sim и SoundSpaces 2.0. Habitat-Sim обеспечивает фотореалистичную визуализацию и взаимодействие со средой, в то время как SoundSpaces 2.0 специализируется на моделировании распространения звука в трехмерном пространстве. Для рендеринга сложных сцен и оптимизации процесса используется фреймворк Hunyuan3D-1.0, позволяющий эффективно генерировать высококачественные визуальные данные и интегрировать их с пространственным звуком, что необходимо для точной оценки алгоритмов 3D аудио-визуального рассуждения.
Набор данных SpatialSceneQA обеспечивает генерацию реалистичных бинауральных сигналов, что позволяет моделировать пространственное восприятие звука. Для этого используются Head-Related Transfer Functions (HRTF) — функции, описывающие, как звук изменяется при прохождении от источника к барабанной перепонке слушателя. Применение HRTF позволяет учитывать дифракцию, отражения и другие акустические эффекты, влияющие на локализацию звука в трехмерном пространстве. Генерация бинауральных сигналов в SpatialSceneQA позволяет создавать реалистичные звуковые сцены, необходимые для обучения и оценки алгоритмов 3D аудио-визуального рассуждения.
Взгляд в Будущее: От Реализма к Новым Горизонтам
Система JAEGER, в сочетании с набором данных SpatialSceneQA, открывает новые возможности для создания более реалистичных и захватывающих виртуальных и дополненных реальностей. Точное позиционирование звука в трехмерном пространстве значительно повышает ощущение присутствия пользователя, позволяя ему естественным образом ориентироваться и взаимодействовать с цифровой средой. Это достигается благодаря способности системы моделировать акустические характеристики пространства, создавая звуковую картину, соответствующую визуальному окружению. В результате, взаимодействие с виртуальным миром становится более интуитивным и убедительным, что способствует более глубокому вовлечению и повышению эффективности обучения, развлечений и других приложений, использующих технологии виртуальной и дополненной реальности.
Точное определение местоположения звуковых источников в трехмерном пространстве открывает новые горизонты для развития робототехники, автономной навигации и вспомогательных технологий. Возможность надежно соотносить звуковой сигнал с конкретным объектом или местоположением позволяет роботам более эффективно ориентироваться в окружающей среде, распознавать опасности и взаимодействовать с объектами. В сфере автономной навигации, это обеспечивает более точное определение местоположения и построение карт местности, даже в сложных условиях. Вспомогательные технологии, в свою очередь, получают возможность создавать более интуитивные и эффективные системы для людей с ограниченными возможностями, например, системы навигации для слабовидящих или устройства, предупреждающие о приближающихся объектах на основе анализа звука. Таким образом, точное звуковое позиционирование становится ключевым элементом для создания более интеллектуальных и адаптивных систем, улучшающих качество жизни и расширяющих возможности взаимодействия человека с окружающим миром.
В основе JAEGER лежит использование предварительно обученных моделей, таких как Qwen2.5-Omni, что позволяет значительно сократить время и вычислительные затраты на обучение. Вместо обучения с нуля, система применяет технику LoRA (Low-Rank Adaptation), эффективно адаптируя существующие знания модели к конкретной задаче пространственной привязки звука. Такой подход не только ускоряет процесс обучения, но и позволяет развертывать систему на менее мощном оборудовании, делая её доступной для широкого спектра приложений, от виртуальной и дополненной реальности до робототехники и автономной навигации. Использование предварительно обученных моделей и LoRA является ключевым фактором эффективности и практичности JAEGER.
Дальнейшие исследования направлены на значительное расширение обучающего набора данных JAEGER, что позволит модели лучше обобщать информацию и адаптироваться к более широкому спектру акустических сцен. Особое внимание уделяется повышению устойчивости метода к шумам и вариациям в записи, а также к различным типам акустических сред. Помимо этого, планируется изучение новых областей применения, включая, например, создание более реалистичных симуляторов для обучения роботов, разработку систем помощи людям с нарушениями зрения и слуха, а также улучшение качества звука в виртуальной и дополненной реальности, что откроет возможности для создания принципиально новых интерактивных приложений и сервисов.
Работа, представленная в статье, демонстрирует стремление обуздать хаос восприятия, интегрируя аудио и визуальные данные в трёхмерном пространстве. Это напоминает попытку расшифровать шёпот, исходящий из неструктурированной реальности. Авторы, по сути, учат машину не просто видеть и слышать, а понимать где именно происходит событие, что требует от модели способности к пространственному мышлению. Янн Лекун однажды заметил: «Машинное обучение — это, по сути, построение моделей, которые могут делать прогнозы на основе данных». Именно это и делает JAEGER — строит модель мира, способную предсказывать взаимосвязи между звуком, изображением и положением объектов в пространстве, хотя и в симулированной среде. Шум в данных неизбежен, но предложенный подход к интеграции многоканального аудио и данных о глубине, похоже, пытается вычленить правду из этого хаоса.
Что дальше?
Представленная работа, безусловно, добавляет ещё один слой иллюзий в мир, где всё, что можно посчитать, вызывает подозрение. Интеграция трёхмерной информации и многоканального аудио — это, конечно, шаг вперёд, но остаётся вопрос: насколько глубоко мы способны обмануть себя, создавая модели, способные «рассуждать» в симуляциях? Ведь любое «понимание», рождённое в цифровом мире, — это всего лишь эхо, а не истинное отражение хаоса.
Следующим логичным шагом представляется не столько улучшение точности модели, сколько исследование её границ. Что произойдёт, когда JAEGER столкнётся с реальностью, где шум превосходит сигнал, а объекты не подчиняются законам физики, заложенным в симуляцию? Скорее всего, модель выдаст элегантный, но бесполезный ответ. И это, возможно, будет самым честным результатом.
В конечном счёте, истинный прогресс заключается не в создании более сложных моделей, а в признании их ограниченности. Если гипотеза подтвердилась — значит, мы не искали достаточно глубоко. Следует помнить, что любое «понимание», полученное от подобных систем, — это лишь временное затишье перед новым витком неопределённости. И в этом, пожалуй, и заключается вся прелесть.
Оригинал статьи: https://arxiv.org/pdf/2602.18527.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Смотрите также:
- Неважно, на что вы фотографируете!
- Что такое Bazzite и лучше ли она, чем Windows для PC-гейминга? Я установил этот набирающий популярность дистрибутив Linux, чтобы проверить это самостоятельно.
- Санкционный удар по России: Минфин США расширяет список ограничений – что ждет экономику? (25.02.2026 05:32)
- Личные банкротства и онлайн-табак: что ждет потребительский сектор в 2026 году (22.02.2026 10:33)
- Восстановление 3D и спектрального изображения растений с помощью нейронных сетей
- Doogee Blade 20 Max ОБЗОР: отличная камера, большой аккумулятор, плавный интерфейс
- Рейтинг лучших скам-проектов
- Cubot X100 ОБЗОР: отличная камера, удобный сенсор отпечатков, плавный интерфейс
- МосБиржа в ожидании прорыва: Анализ рынка, рубля и инфляционных рисков (16.02.2026 23:32)
- Как установить Virtualbox на Windows 11 для бесплатных виртуальных машин
2026-02-26 17:21